






网上都没有人仔细讲一讲 Double Binary Tree 具体怎么操作的,我来简单讲解一下。具体的细节大家还是需要去看代码。
本文还汇总了各种Reduce方法,只想看 Double Binary Tree 可以直接跳转
目录
Recursive Halving and Doubling
一些参考连接:
NVIDIA NCCL 源码学习(十二)- double binary tree-CSDN博客
https://zhuanlan.zhihu.com/p/79030485
Massively Scale Your Deep Learning Training with NCCL 2.4 | NVIDIA Technical Blog
前置知识
Allreduce 操作现在是分布式训练中不可或缺的一步操作。Allreduce 操作可以分解为 Reduce 和 Broadcast 两个操作,所以绝大部分算法中只需要分别考虑这两个操作怎么进行的即可。
Reduce 和 Broadcast 的传输时间都是几乎一样的(所以在计算时间时能看到很多系数2,只是Reduce 在不考虑别的优化情况(如pingpong)下会多出一个计算的时间)
以深度学习模型训练中的数据并行为例需要对梯度进行AllReduce操作(因为要汇总梯度,再在所以设备上同步)。Reduce 就是将所有GPUs上的梯度相加求均值,Broadcast 就是分发给所有 GPUs 同步参数。
图中实线是实际发生了通信;虚线是示意,并没有实际通信。
公式中使用的变量

Reduce + Broadcast
直接reduce汇总在一个节点上,再由该节点 Broadcast
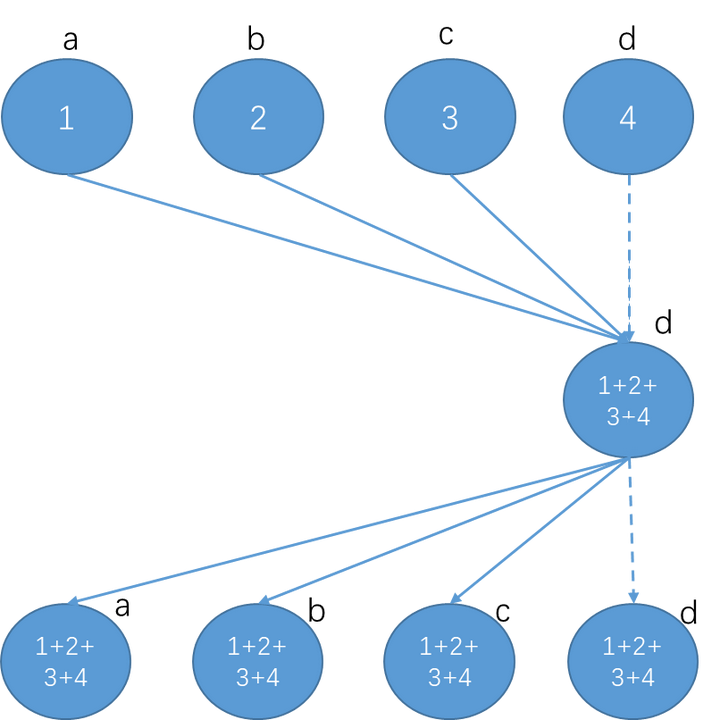
缺点:计算和传输的负荷全部都在d上,且随节点数线性增加啊
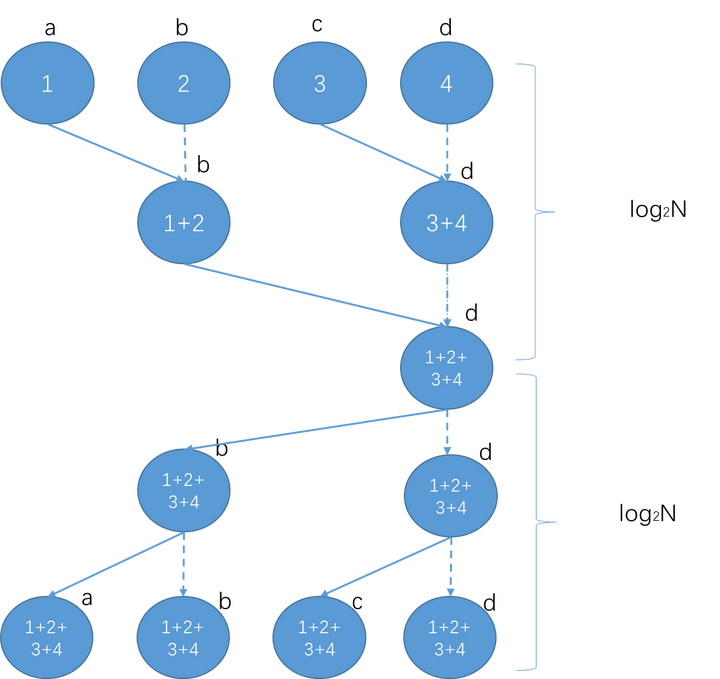
Recursive Halving and Doubling (Tree)
非常普通的树状,每次都会传输大小为S的数据,Reduce和Broadcast都需要次
缺点就是带宽利用不充分。比如Reduce时,叶节点只发送数据,不接收,因此只利用了带宽的一半。有一半的节点没有进行接收操作。比如图中第一步,a->b,c->d发送数据的时候,b和d节点的发送带宽没有被利用起来。同理,Broadcast时,叶节点只接收数据,不发送。
并且每一步都需要传输完整的数据块(如图的树是不好对数据分块的。比如d在接受c的第二块数据时,b同时传来了第一块数据,没有办法同时进行)
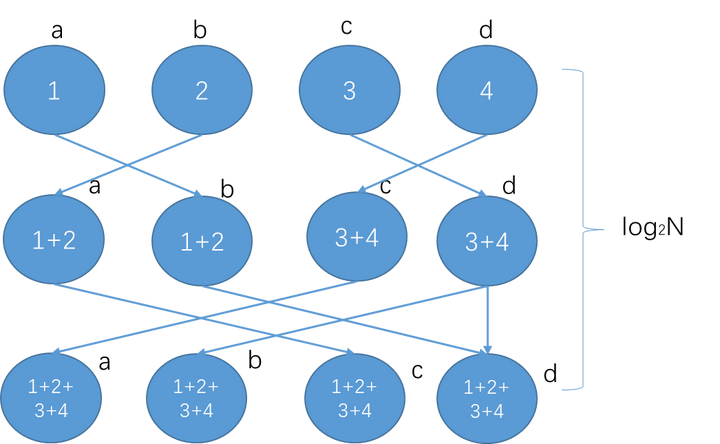
Butterfly
相当于传输和接收一起进行的tree。值得注意的是,该方法不需要再Broadcast了
充分利用了接收和发送的带宽
但是每一步都需要传输完整的数据块(和Tree一样不好切块)
Ring Reduce
RingReduce的讲解太多了,我就不仔细分析了
第一阶段reduce数据
第二阶段broadcast数据
两个阶段都需要进行次
分层Ring AllReduce
https://arxiv.org/pdf/1807.11205
组内reduce->组间AllRuduce->组内broadcast
n :组内的节点个数
m :组的个数
N=nm
第一阶段组内普通的reduce
论文中一共16个GPU,每个组4个,直接使用Reduce + Broadcast(组内节点少,带宽大)
第二阶段组间Ring Reduce
第三阶段组内Broadcast
总的时间

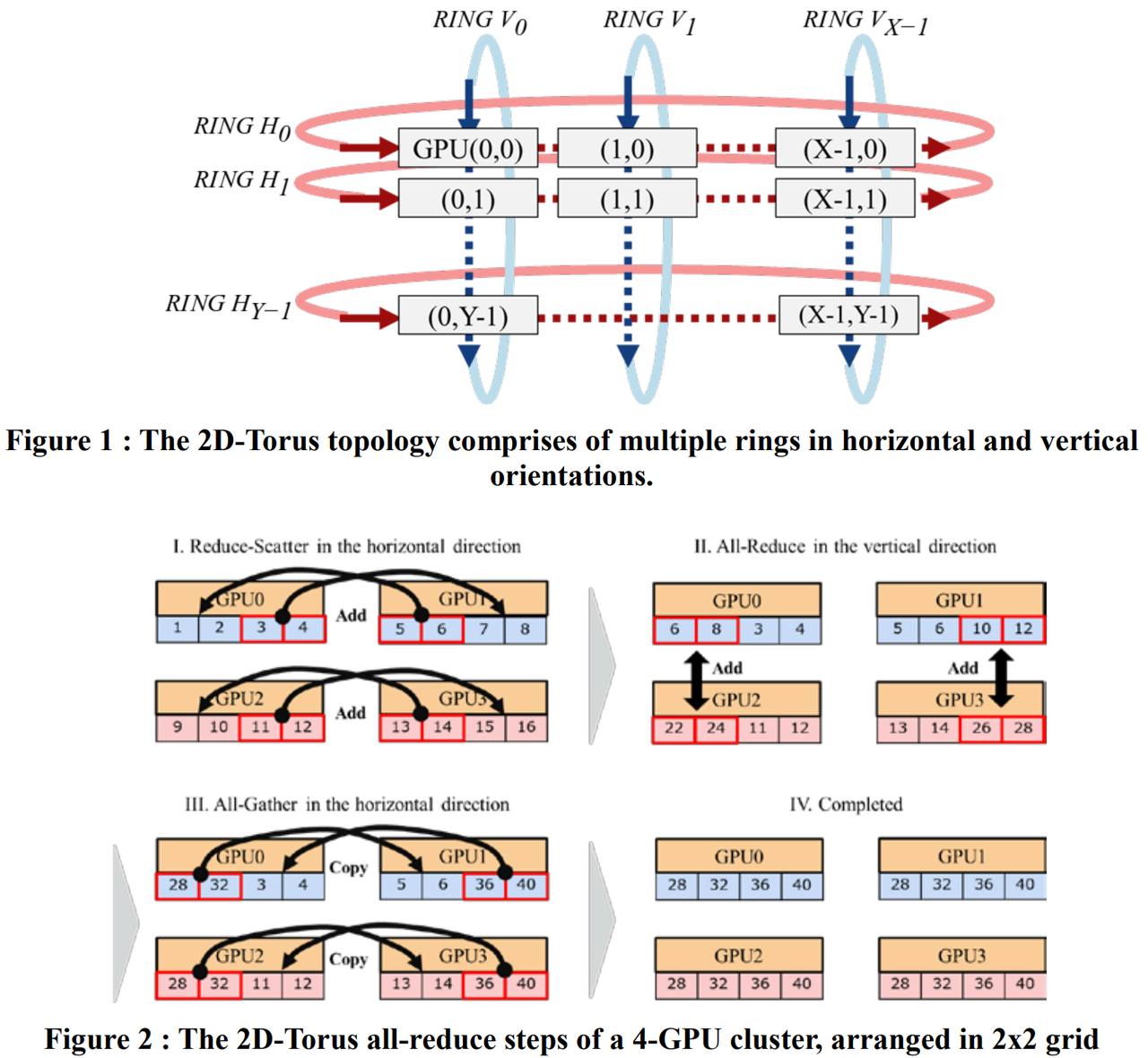
2D-Torus
https://arxiv.org/pdf/1811.05233
主要思想也是分层,是组内reduce->组间allreduce->组内broadcast。
相当于两个ring(组间ring,组内ring)
n :组内的节点个数
m :组的个数
N=nm
第一阶段scatter-reduce通信步数n-1
第二阶段allreduce是m个节点的RingReduce
第三阶段allgather通信步数n-1
整体耗时大概是
Double Binary Tree
基于 double binary tree 的 AllReduce
《Two-Tree Algorithms for Full BandwidthBroadcast, Reduction and Scan》
double binary tree 于 2009 年在 MPI 中引入,并随后在 NCCL2.4 中也引入了此实现:https://developer.nvidia.com/blog/massively-scale-deep-learning-training-nccl-2-4/
内容
基础知识
朴素的树状 Reduce 带宽利用不充分,broadcast时叶节点只接收数据,不发送。reduce时叶节点只发送数据,不接收。并且每一步都需要传输完整的数据块
Double Binary Tree 分别构造两棵树。Tree1和Tree2会同时运行!这样使得双向带宽能被同时利用
不难看出Tree1中的叶节点/中间节点,在Tree2中变成了中间节点/叶节点。这样就能保证所有节点既是叶节点也是中间节点,因此不会出现一棵树时的情况 (所以收发带宽都能用上)
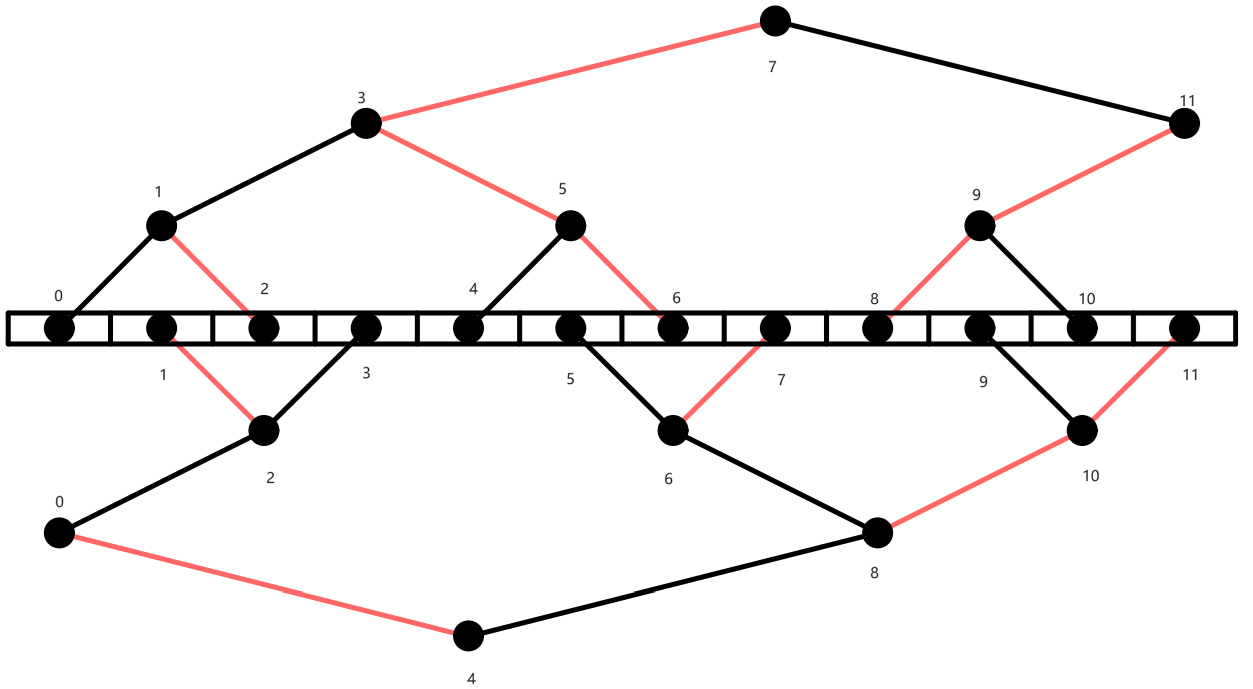
如图,将Tree1和Tree2的边按一定规律染成红色或者黑色(如上图),从而有如下很好的性质:
-
不会有节点在Tree1和Tree2中连到父节点的边的颜色相同,比如node0在Tree1中通过红色的边连到父节点,那Tree2中node0一定通过黑色的边连到父节点。
-
不会有节点连到子节点的边颜色相同,比如node3在Tree1中是中间节点,如果node3通过红色的边连到右子节点,那么node3一定通过黑色的边连到左子节点
根据上述性质,就有了两棵树的工作流程,在每一步中从父节点中收数据,并将上一步中收到的数据发送给他的一个子节点,比如在偶数步骤中使用红色边,奇数步骤中使用黑色边,这样的话在一个步骤中可以同时收发,从而利用了双向带宽。
操作
在每一个通信步中
Node x从两棵树中其中一个父节点接受数据;Node x给其作为中间节点的树中的一个子节点传输之前的数据(从哪个父节点和给哪个子节点都是一个固定好的schedule)
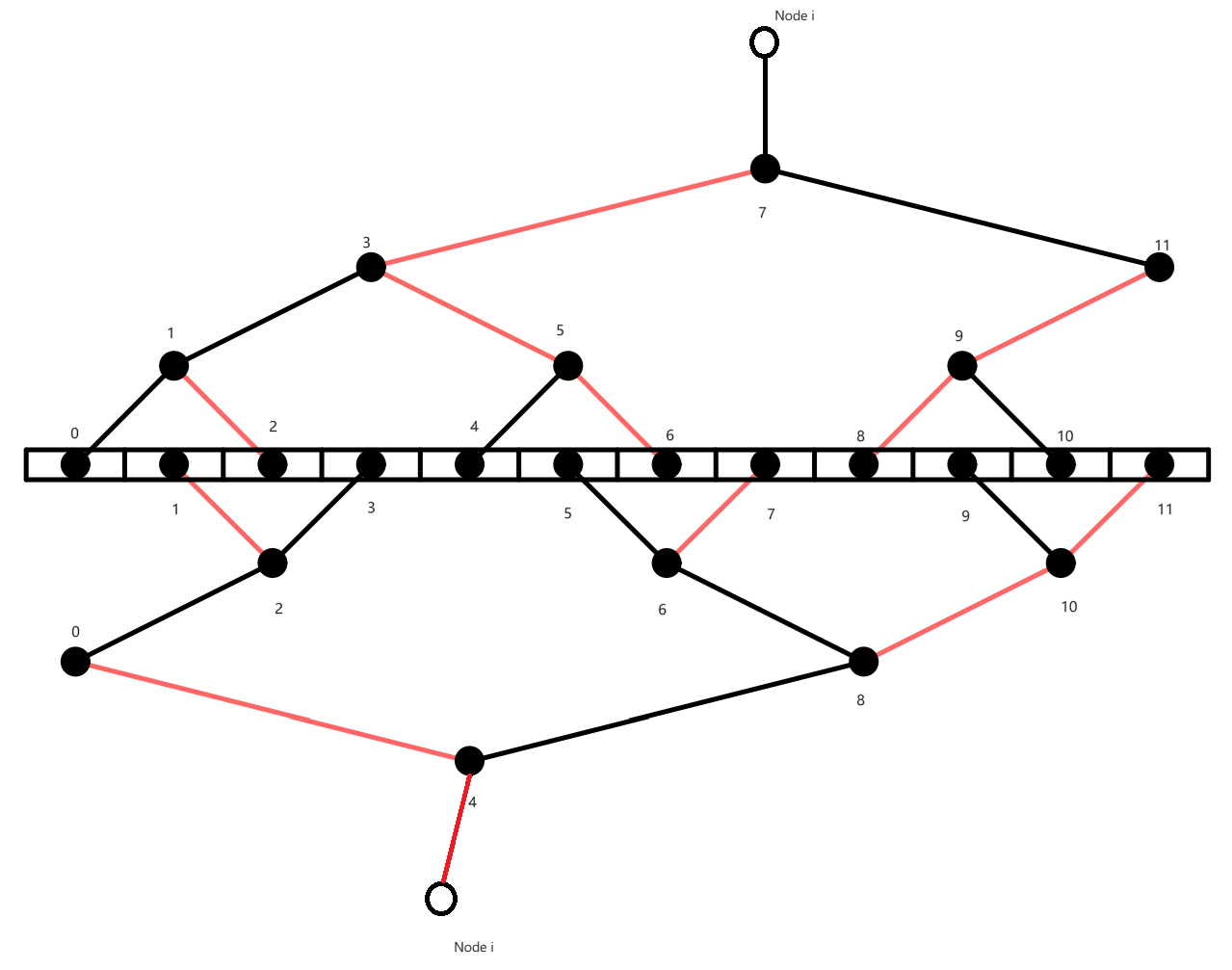
Broadcast(需要将node i的数据传输给所有的节点):
开始时,node i 的操作:
-
将node i 的数据分为两块,可以记为黑色数据和红色数据
-
第一时刻:node i 将黑色数据据沿着黑色边传递给子节点
-
第二时刻:node i 将红色数据据沿着红色边传递给子节点
任意时刻的所有节点(注意,需要对数据分块流水起来才有这个效果!):
- 从黑色边的父节点接受黑色数据 i+1,沿黑色边给子节点传输黑色数据 i
- 从红色边的父节点接受红色数据 i+1,沿红色边给子节点传输红色数据 i
- 重复1和2
耗时
Reduce
reduce相当于就是反向的broadcast(子给父节点传数据)。假设node i需要汇聚所有节点的结果,Tree1把一半的的数据加上,同时Tree2 加另一半的数据
如果将数据切分为2k块
Broadcast
如果将数据切分为2k块
All
Reduce和Broadcast都最多需要执行2h+2k次,
将带入上式(这个值是论文中给的),可得:
普通的树耗时
因为充分利用了带宽,可以明显看到比普通的树在数据传输上耗时少很多(直接与卡的数量无关了)。计算的耗时也少了很多。
其它
基于 spanning tree 的 AllReduce
《Blink: Fast and Generic Collectives for Distributed ML》
2D-Mesh
TPU节点可以同时进行2路send和2路recv,而我们普通的服务器都是只有一张网卡,只能同时进行1路send和1路recv
在TPU上,耗时2*(m+n-2)*( α+S/B+S*C)。
BlueConnect (3D-Torus)
基于异构环境下、拓扑感知的 AllReduce 框架 BlueConnect
《BlueConnect: Decomposing All-Reduce for Deep Learning on Heterogeneous Network Hierarchy》

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









