






本文是一个最近看 YOLO 的随笔,只是想简单地比较各个版本的 YOLO 有什么不同,并且没有认真研究各个版本对loss的改进(后续有时间会加上)。
本文攥写时间短,没有校对过。可能存在笔误、描述不准确、重要内容缺失,希望大家能指出,我会随时修改补充
概况
| 时间 | 版本 | 主要内容 | 作者 |
| 2015 | v1 | Joseph Redmon & Ali Farhadi | |
| 2016 | v2 | 加入batch normalization, anchor boxes和dimension clusters. | Joseph Redmon & Ali Farhadi |
| 2018 | v3 | 更高效的骨干网络、引入spatial pyramid和PAN | Joseph Redmon & Ali Farhadi |
| 2020 | v4 | Mosaic 数据增强、new loss、SPP模块、CSP模块、Mish激活函数、CmBN归一化 | Alexey Bochkovskiy |
| 2020 | v5 | 灵活的配置参数、超参优化策略、focus结构 | |
| 2021 | x | Decoupled Head、anchor free | 旷视 |
| 2022 | v6 | 引入RepConv,量化相关内容,Loss | 美团 |
| 2022 | v7 | Efficient Layer Aggregation Network (ELAN)模块,MP模块 | Alexey Bochkovskiy & 台湾中央研究院 |
| v8 | C2f模块 | Ultralytics | |
| 2024 | v9 | 加入Programmable Gradient Information (PGI) and Generalized Efficient Layer Aggregation Network (GELAN) | |
| 2024 | v10 | Dual label assignments、整体高效的网络设计、空间-通道解耦下采样 | 清华 |

上图来自于YOLOv8详解 【网络结构+代码+实操】-CSDN博客
内容
v1-v5
对1-5非常好的总结:https://zhuanlan.zhihu.com/p/186014243
v1
YOLO是一种one stage的方法,即输入图像,直接输出位置和类别(two stage算法中经典的方式:先识别位置,再识别类别)。其利用anchor box将分类与目标定位结合
流程
-
resize图像
-
经过CNN网络
-
进行非极大值抑制处理
-
设置一个 Score 的阈值,一个 IOU 的阈值(overlap);
-
对于每类对象,遍历属于该类的所有候选框,
-
过滤掉 Score 低于 Score 阈值的候选
-
找到剩下的候选框中最大 Score 对应的候选框,添加到输出列表;
-
进一步计算剩下的候选框与 ii 中输出列表中每个候选框的 IOU,若该 IOU 大于设置的 IOU 阈值,将该候选框过滤掉(大于一定阈值,代表重叠度比较高),否则加入输出列表中
-
最后输出列表中的候选框即为图片中该类对象预测的所有边界框
-
-
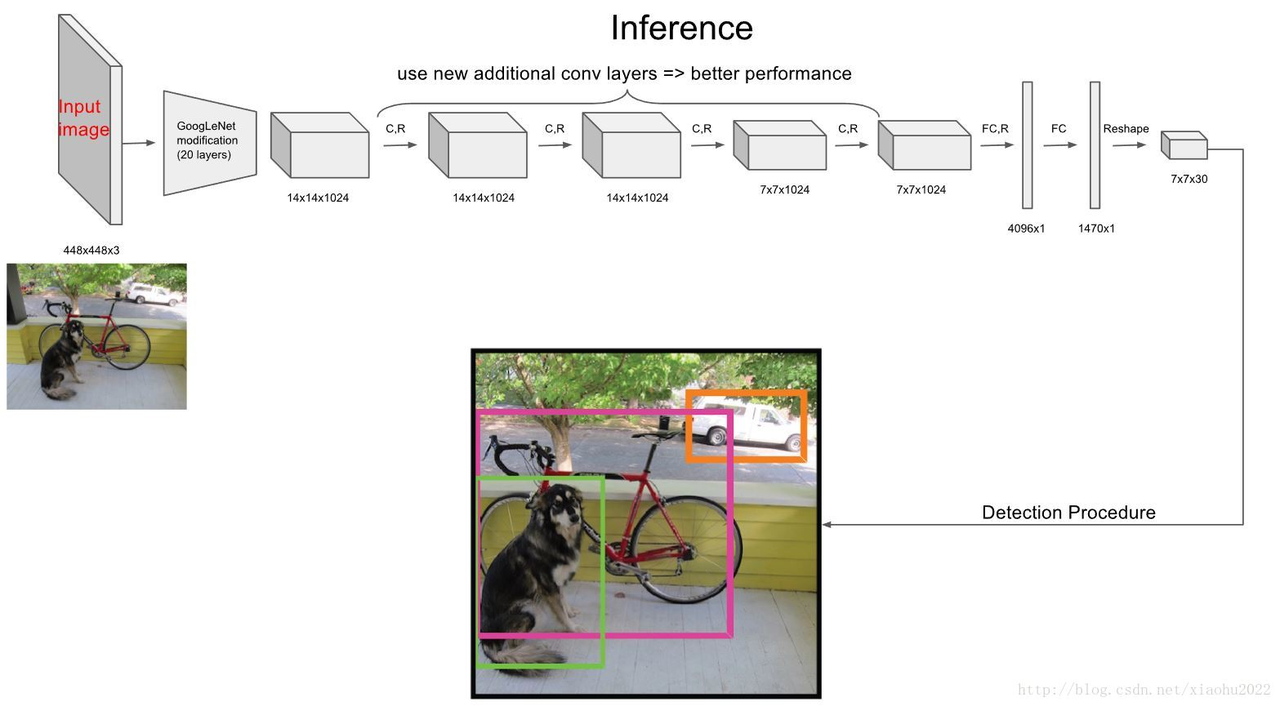
网络输出
对于网络的输出,我们可以这样理解,30=20+2+4x2,其中20指的是类别数,即20个类别的概率,2指的是两个目标框的置信度,然后每个通道预测2个目标框,所以就是两个(x,y,w,h)即8个元素。那么网格划分是怎么体现的呢?可以看到最后的输出为7x7x30,特征图的尺寸是7x7,那么根据卷积网络的特点,输出特征图上的每一个像素点都应该对应着输入特征图的一个区域,也就是这个像素点的感受野,那么在最后一层卷积层输出特征图上,也是如此,所以我们可以认为是将原图划分成了7X7的网格区域,每个网格预测20个类别的概率,目标框置信度以及两个目标框信息,其中每个目标的中心位置都会转换至网格区域内。
损失函数
如上图所示,损失函数分为坐标预测、含有物体的边界框的 confidence 预测、不含有物体的边界框的 confidence 预测、分类预测四个部分。
由于不同大小的边界框对预测偏差的敏感度不同,小的边界框对预测偏差的敏感度更大。为了均衡不同尺寸边界框对预测偏差的敏感度的差异。作者巧妙的对边界框的 w,h 取均值再求 L2 loss. YOLO 中更重视坐标预测,赋予坐标损失更大的权重,记为 coord,在 pascal voc 训练中 coodd=5 ,classification error 部分的权重取 1。
某边界框的置信度定义为:某边界框的 confidence = 该边界框存在某类对象的概率 pr (object)* 该边界框与该对象的 ground truth 的 IOU 值 ,若该边界框存在某个对象 pr (object)=1 ,否则 pr (object)=0 。由于一幅图中大部分网格中是没有物体的,这些网格中的边界框的 confidence 置为 0,相比于有物体的网格,这些不包含物体的网格更多,对梯度更新的贡献更大,会导致网络不稳定。为了平衡上述问题,YOLO 损失函数中对没有物体的边界框的 confidence error 赋予较小的权重,记为 noobj,对有物体的边界框的 confidence error 赋予较大的权重。在 pascal VOC 训练中 noobj=0.5 ,有物体的边界框的 confidence error 的权重设为 1.
v2
YOLOv1 虽然检测速度快,但在定位方面不够准确,并且召回率较低。为了提升定位准确度,改善召回率,YOLOv2 在 YOLOv1 的基础上提出了几种改进策略
-
Batch Norm
-
Anchor box
-
v1 利用全连接层直接对边界框进行预测,导致丢失较多空间信息,定位不准。YOLOv2 去掉了 YOLOv1 中的全连接层,使用 Anchor Boxes 预测边界框
-
每个cell中有5个anchor box,并且每个框可以预测不同的类别
-
-
Dimension Clusters
-
使用k-means聚类算法对训练集做了聚类分析,尝试找到合适尺寸的Anchor box们
-
v3
v2对于小目标的检测仍然不太行
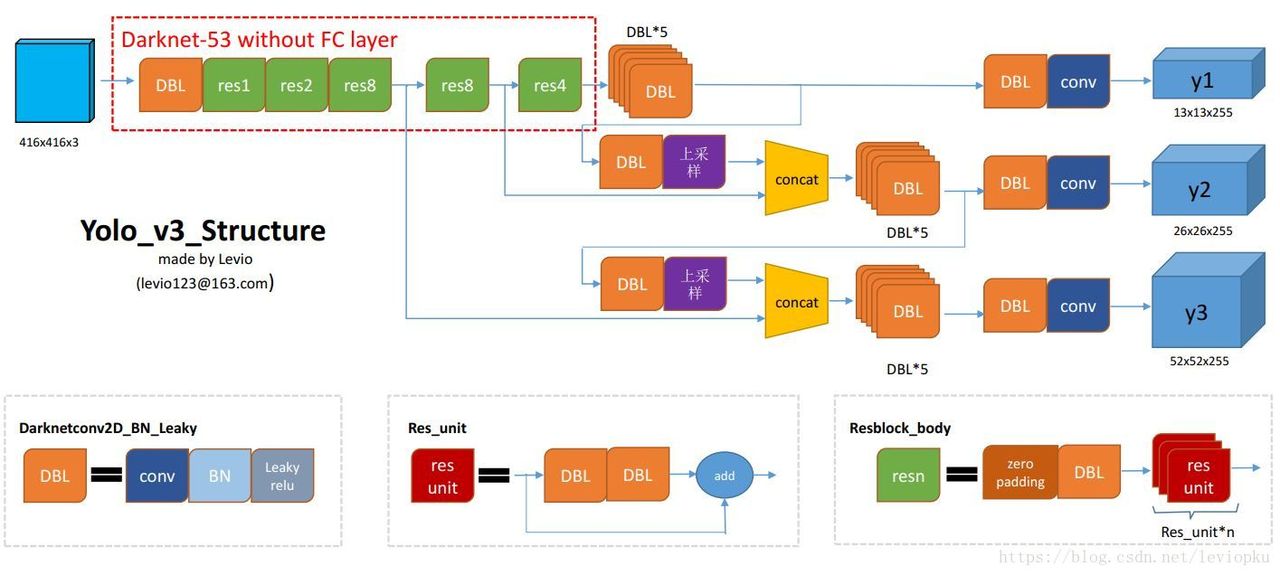
新网络结构
设计了新的网络结构。
值得注意的是,新的网络中没有Pooling Layer了,用的是conv(stride = 2)进行下采样
融合 FPN
借鉴了 FPN 的思想,从不同尺度提取特征。使用PAN结构融合不同尺度间的信息。
更多anchor box
用维度聚类的思想聚类出 9 种尺度的 anchor box,将 9 种尺度的 anchor box 均匀的分配给 3 种尺度的特征图。
v3 一共9个box,每个特征有3个box
v3 tiny 6个box,每个特征有2个box
v3检测头对不同尺度的特征图,分成了3部分:
-
13*13*3*(4+1+80)
-
26*26*3*(4+1+80)
-
52*52*3*(4+1+80)
预测的框更多更全面了,并且针对对不同尺度。
分类时255是怎么来的:3*(5+80)。80表示80个种类,5表示位置信息和置信度,3表示要输出3个prediction。
v4
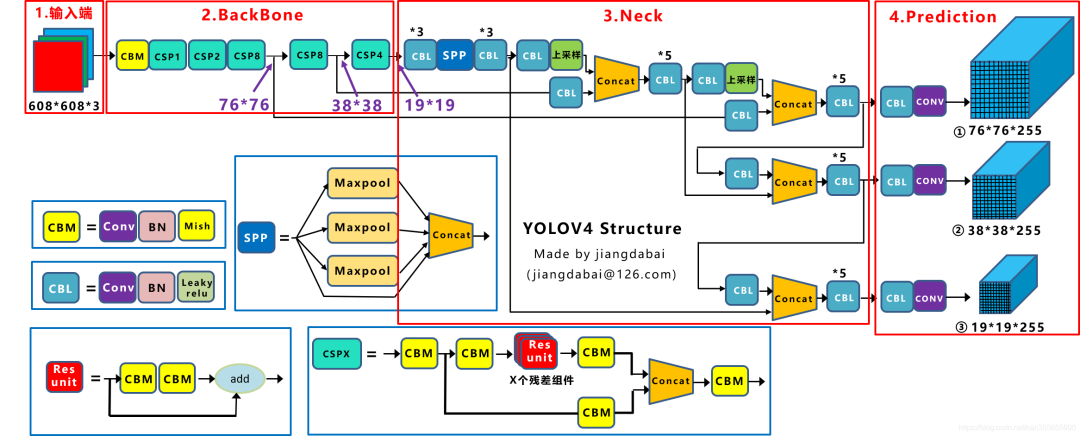 主要贡献
主要贡献
Bag of Freebies:指那些不增加模型复杂度,也不增加推理的计算量的训练方法技巧,来提高模型的准确度
Bag-of-Specials:指那些增加少许模型复杂度或计算量的训练技巧,但可以显著提高模型的准确度
验证了最先进的 Bag-of-Freebies 和 Bag-of-Specials 方法在训练期间的影响
BoF指的是
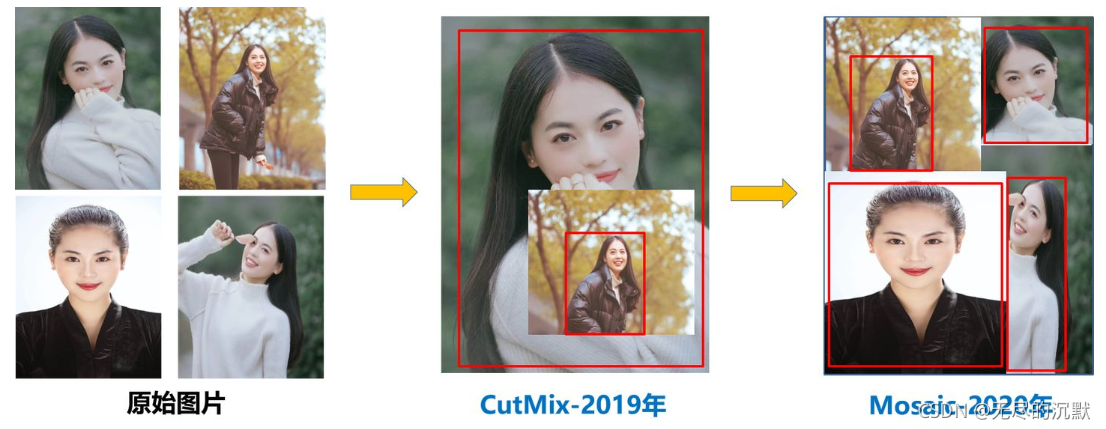
1)数据增强:图像几何变换(随机缩放,裁剪,旋转),Cutmix,Mosaic等
2)网络正则化:Dropout,Dropblock等
3) 损失函数的设计:边界框回归的损失函数的改进 CIOU
BoS指的是
1)增大模型感受野:SPP、ASPP等
2)引入注意力机制:SE、SAM
3)特征集成:PAN,BiFPN
4)激活函数改进:Swish、Mish
5)后处理方法改进:soft NMS、DIoU NMS
改进
想读懂YOLOV4,你需要先了解下列技术(二) - 作业部落 Cmd Markdown 编辑阅读器
部分位置使用了Mish激活函数
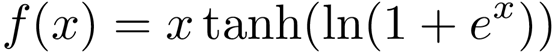
SPP模块:stride为1,size不一样的maxpooling,然后concat在一起。融合了不同尺寸的信息
CSPX模块:像普通的ResUnit,但是shortcut还是计算了。所以是更复杂、信息更丰富
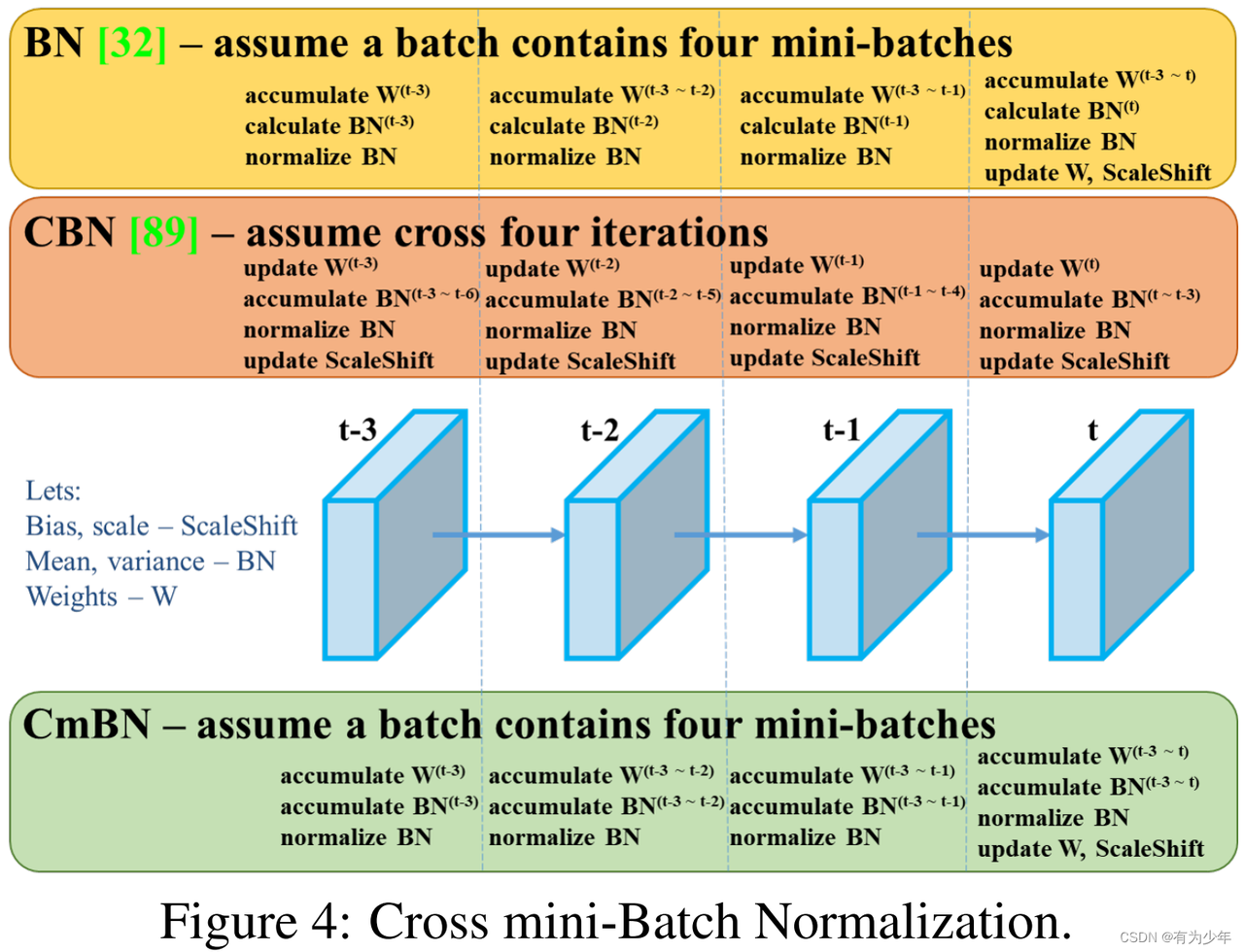
CmBN
CmBN是CBN的改进
CBN就是考虑前n个mini batch中的BN的量(所以该mini batch不一定是同一个batch)
CmBN就只考虑同一个batch中的前n个mini batch的BN的量(所以该mini batch一定是同一个batch中的!)
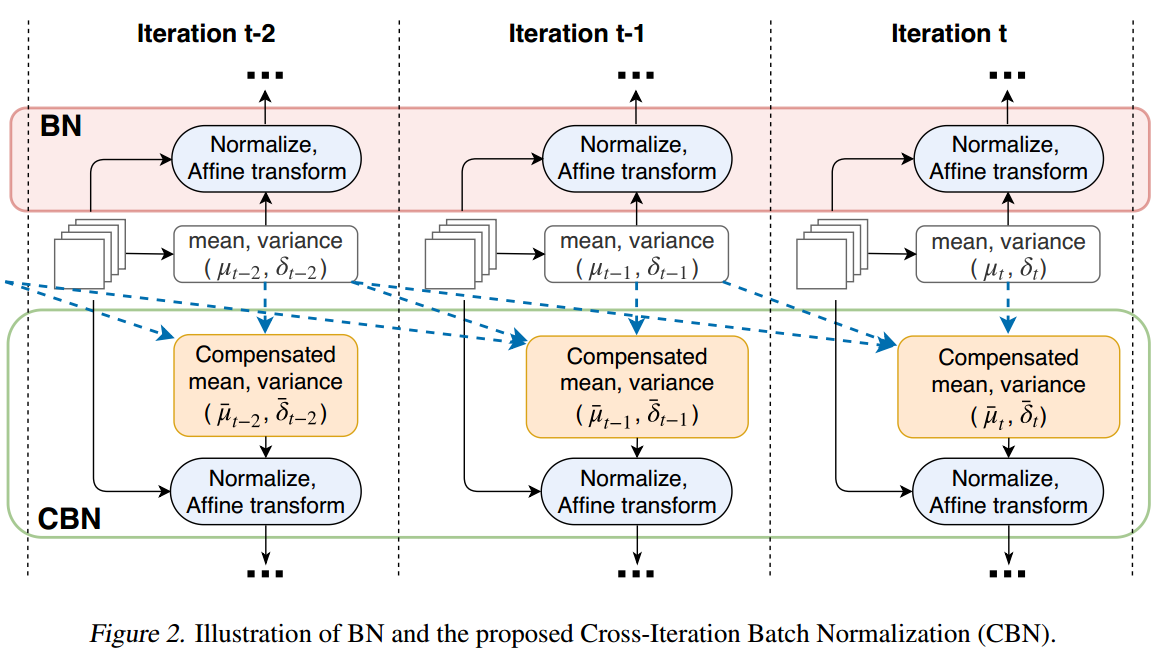
首先要看懂BN的流程,假设迭代4次算一个大batch,即batch/mini batch=4,accumulate 表示在第t时刻对梯度进行累积(梯度不清0的累加),calculate
表示计算第t时刻的BN统计量,主要是均值和方差,normalize BN表示BN的前向过程,也就是对当前输入数据应用BN技术,其计算包括2步:
注意此时是没有进行更新的,使用的是前面时刻梯度更新得到的值。橙色流程的意思其实就是前面提到的yolo中常用的变相扩大batch size做法,其网络前向batch/ mini batch次,然后再第N-1迭代时刻进行统一的梯度更新,包括更新权重W以及BN可学习参数
,可以看出其无法变相扩大batch大小,实现更加精确的batch维度统计,但是实际上用起来还是有点效果的,不然大家训练时候也就不会用了。最好的办法其实应该还是同步BN好用,跨卡统计batch参数,但是不是人人都有多卡的,所以CBN还是有用武之地的。
在理解了BN流程基础上,理解CBN就非常容易了,CBN由于在计算每个迭代时刻统计量时候会考虑前3个时刻的统计量,故变相实现了大batch,然后在每个mini batch内部,都是标准的BN操作即,1 计算BN统计量,2 应用BN,3 更新可学习参数和网络权重
而CmBN的做法和前面两个都不一样,其把大batch内部的4个mini batch当做一个整体,对外隔离,主要改变在于BN层的统计量计算方面,具体流程是:假设当前是第t次迭代时刻,也是mini-batch的起点,
(1) 在第t时刻开始进行梯度累加操作
(2) 在第t时刻开始进行BN统计量汇合操作,这个就是和CBN的区别,CBN在第t时刻,也会考虑前3个时刻的统计量进行汇合,而CmBN操作不会,其仅仅在mini batch内部进行汇合操作
(3) 就是正常的应用BN,对输入进行变换输出即可
(4) 在mini batch的最后一个时刻,进行参数更新和可学习参数更新
可以明显发现CmBN是CBN的简化版本,其唯一差别就是在计算第t时刻的BN统计量时候,CBN会考虑前一个mini batch内部的统计量,而CmBN版本,所有计算都是在mini batch内部。我怀疑是为了减少内存消耗,提高训练速度,既然大家都是近似,差距应该不大,而且本身yolo训练时候,batch也不会特别小,不至于是1-2,所以CmBN的做法应该是为了yolov4专门设计的,属于实践性改进。
Mosaic数据增强
Loss改动
主要是对IoU部分的改动
v5
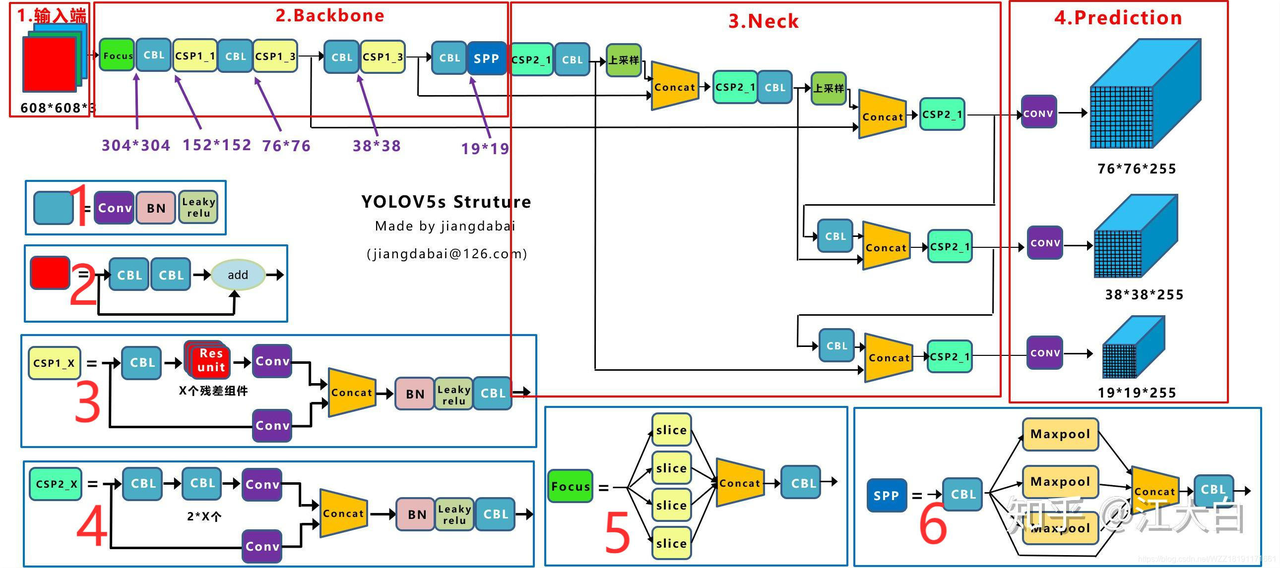
-
输入端:在模型训练阶段,提出了一些改进,主要包括Mosaic数据增强、自适应锚框计算(相当于anchor free了)、自适应图片缩放
-
引入了Focus模块
-
Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms
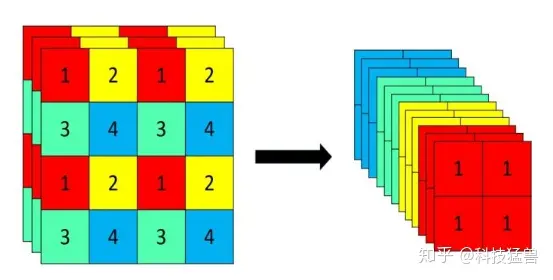
Focus的slice操作如下图所示
YOLOv5 Focus() Layer · ultralytics/yolov5 · Discussion #3181 · GitHub
Focus替换掉了更复杂的结构,实现了加速
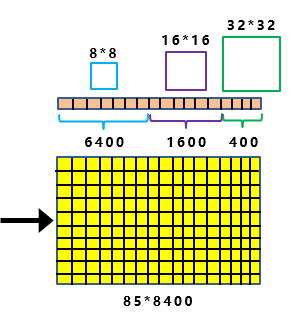
x
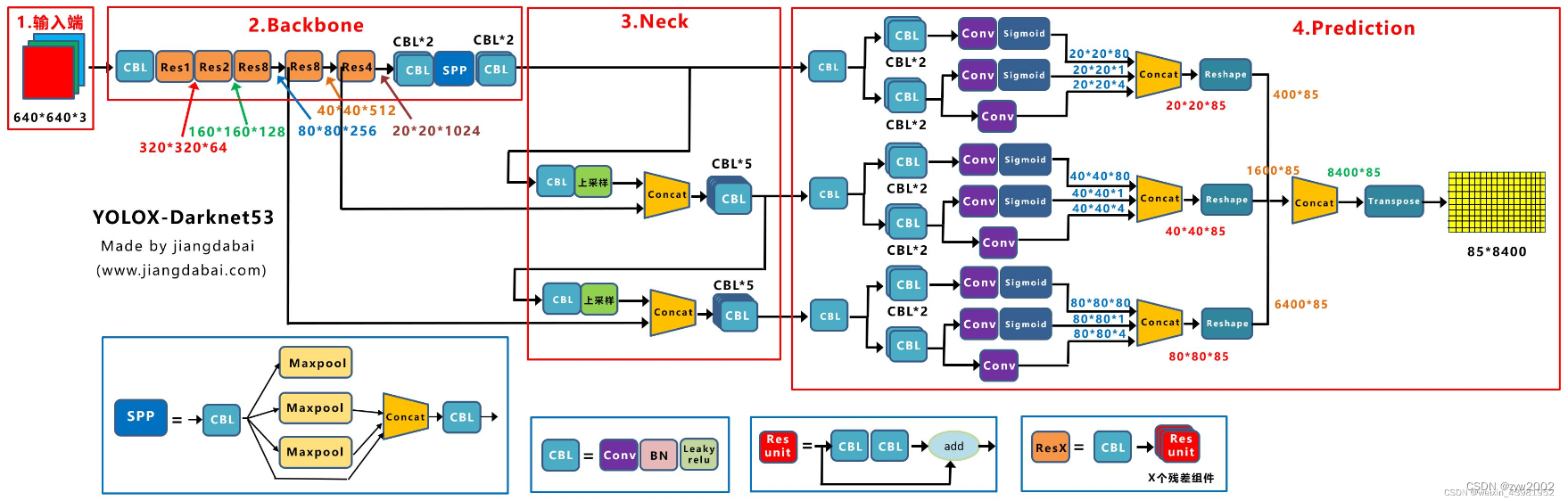
-
Decoupled Head:以前版本的Yolo中,类别、置信度、框都是一个网络预测。YoloX认为这些信息有一点差别,耦合在一起给网络的识别带来了不利影响。在YoloX中,使用不同的网络预测不同的信息。
-
Anchor Free:不使用先验框。使用下采样的次数来决定框的大小
-
SimOTA :为不同大小的目标动态匹配正样本。
v6
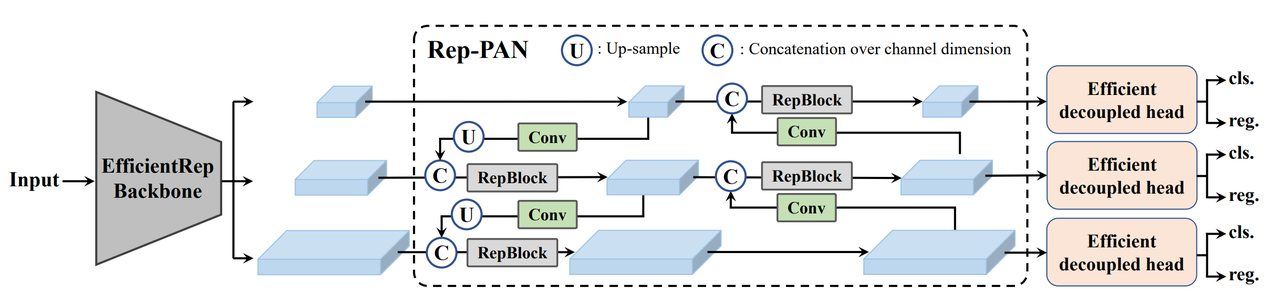
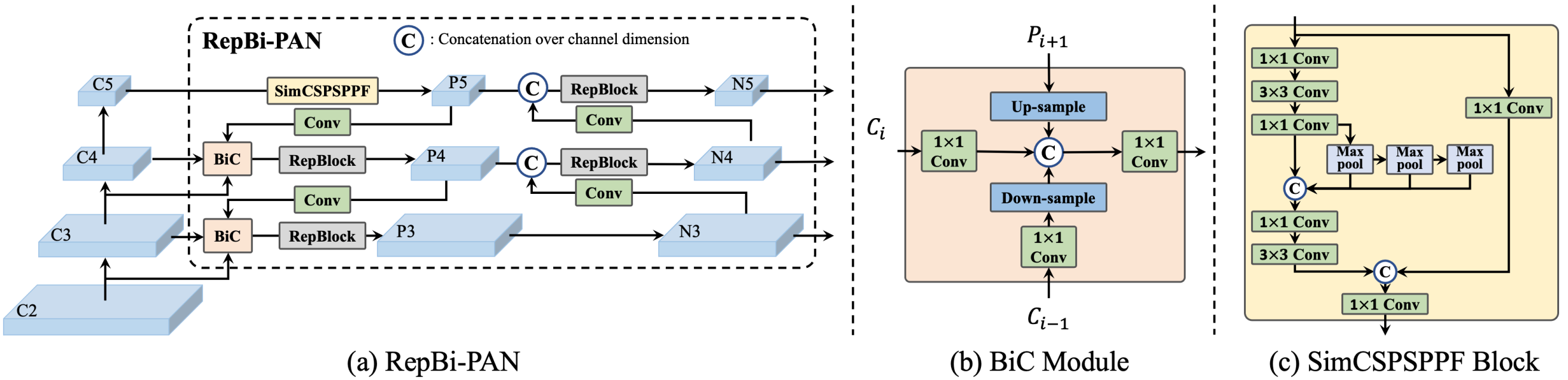
https://blog.csdn.net/qq_39707285/article/details/126869924
-
Backbone设计:多分支比单分支性能好但耗时增加,借鉴RepVGG思路提出EfficientRep。
-
Neck设计:借鉴YOLOv4/v5的PAN,提出了Rep-PAN,将PAN的CSPBlock替换为RepBlock(小型模型)或者CSPStackBlock(大型模型),可根据需求调整相应的宽度和深度。
-
Head设计:采用decoupled head。anchor free (anchor point-based (FCOS))
-
在RepConv/ReLU在YOLOv6-N/T/S/M中使用,得到更快的推理;在YOLOv6-L中使用Conv/SiLU组合加速训练并提高性能。
-
采用ATSS作为训练初期阶段的warm-up标签分配策略,之后使用TAL进行标签分配。
-
分类loss使用VariFocal Loss(VFL);对于框回归,YOLOv6-N和YOLOv 6-T使用SIoU Loss,其余使用GIoU Loss,另外YOLOv6-M/L中加入Dostronition Focal Loss(DFL);取消Object Loss。
-
更多的训练轮次能得到更好的收敛效果,所以训练周期采用400个epoch。
-
推理时图片resize操作会在四周填充灰色的padding,这种操作有助于检测图像边缘目标,但会降低推理速度。发现这可能和训练时的Mosaic数据增强有关,实验结果表明,当在训练最后一轮关闭Mosaic(称为fade strategy),使用灰度边界填充会达到最佳效果。
-
训练后量化(post-training quantization, PTQ)和量化感知训练(quantization-aware training, QAT)。
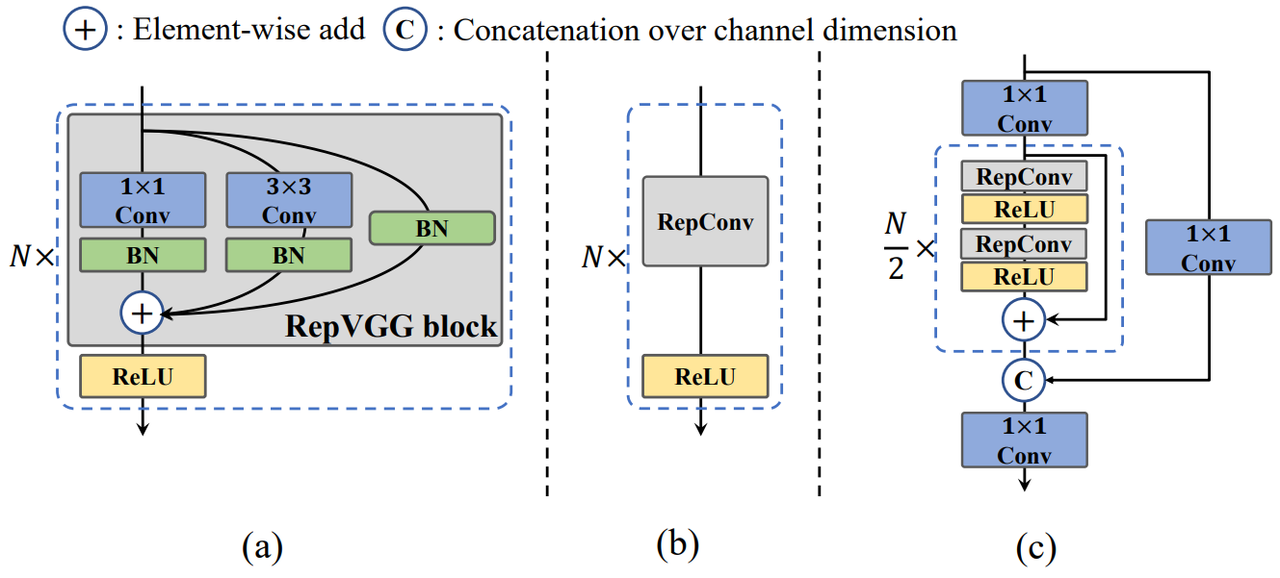
(a) RepBlock. (b) When infering, RepBlock is converted to RepConv. (c) CSPStackRep Block
Rep
训练时两个Conv和一个Identity,更复杂,更容易学习复杂的表征。推理时直接算子融合,提升了速度。相当于不影响推理的情况下,增加了训练时的复杂度,换来了更好的效果。
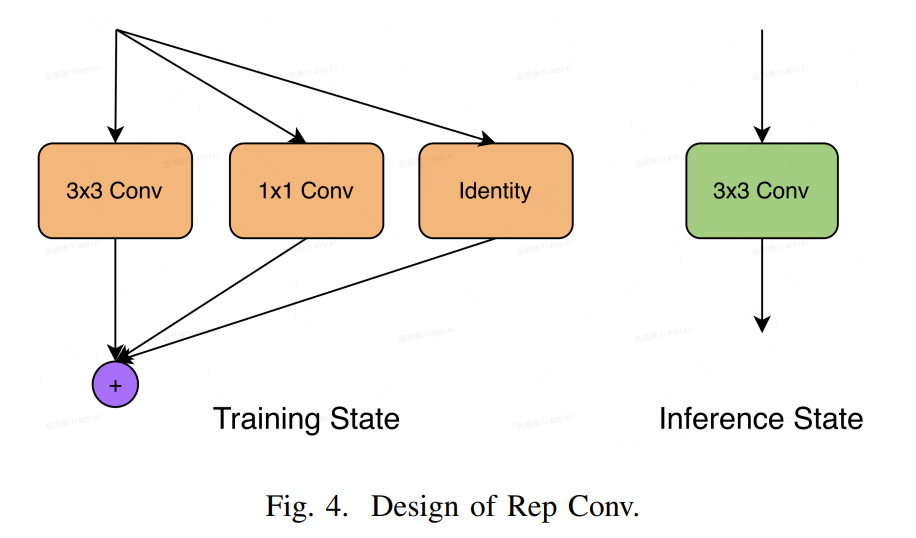 Rep Conv优势:
Rep Conv优势:
(1)当前大多数推理引擎都对Conv3*3做了加速
(2)当推理阶段使用的网络层类别比较少时,可以花费一些时间来完成这些模块的加速,是一种模型加速方案。
(3)去掉了残差,更快、内存需求更少
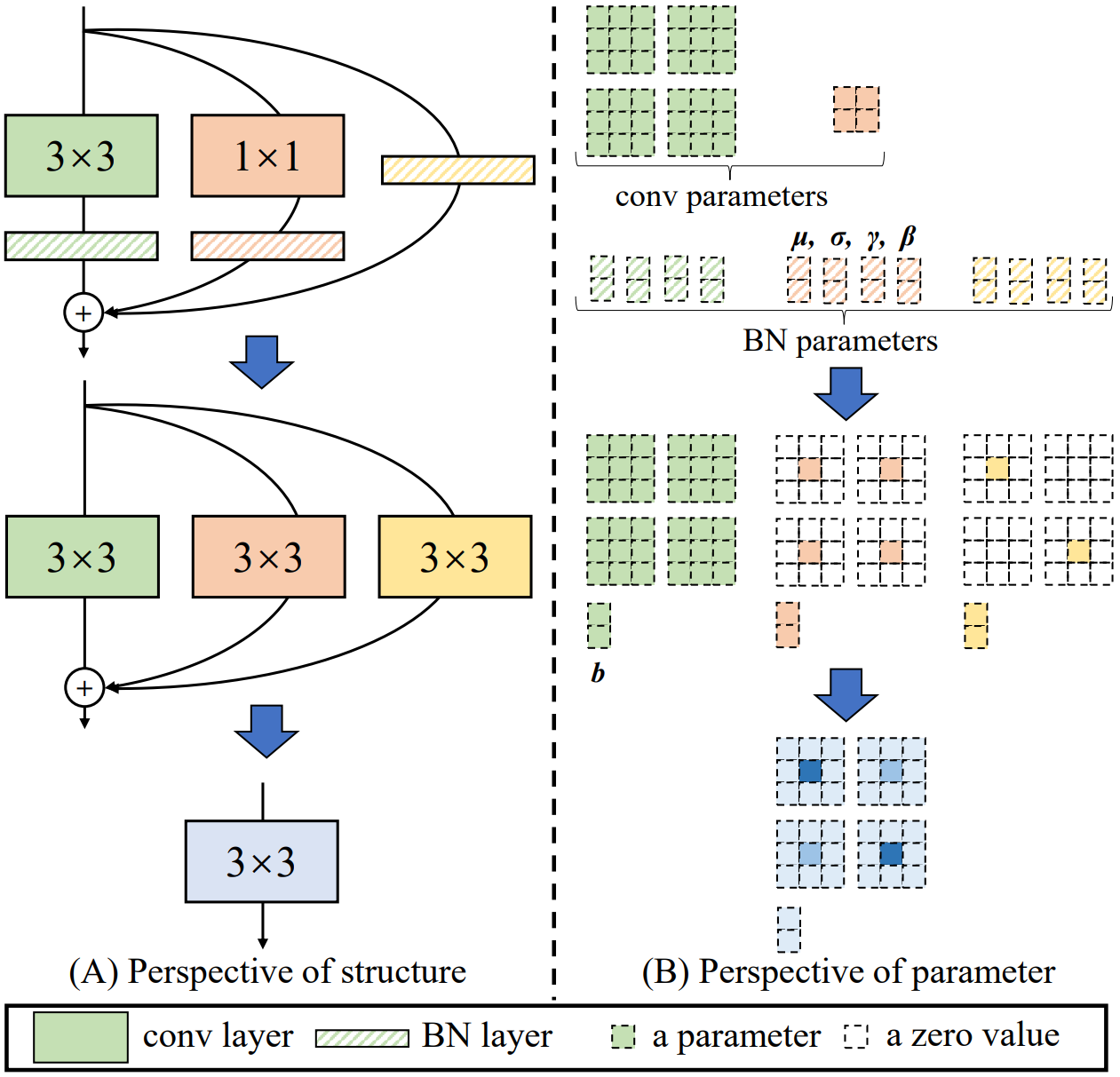
怎么在推理时融合算子:
-
通过下式将卷积层和BN层进行融合,得到1个3x3卷积,2个1x1卷积(identity can be viewed as 1×1 conv with an identity matrix as kernel.),3个bias
-
融合3个卷积。将三个bias相加;2个1x1做zero padding,然后和3x3相加
Head
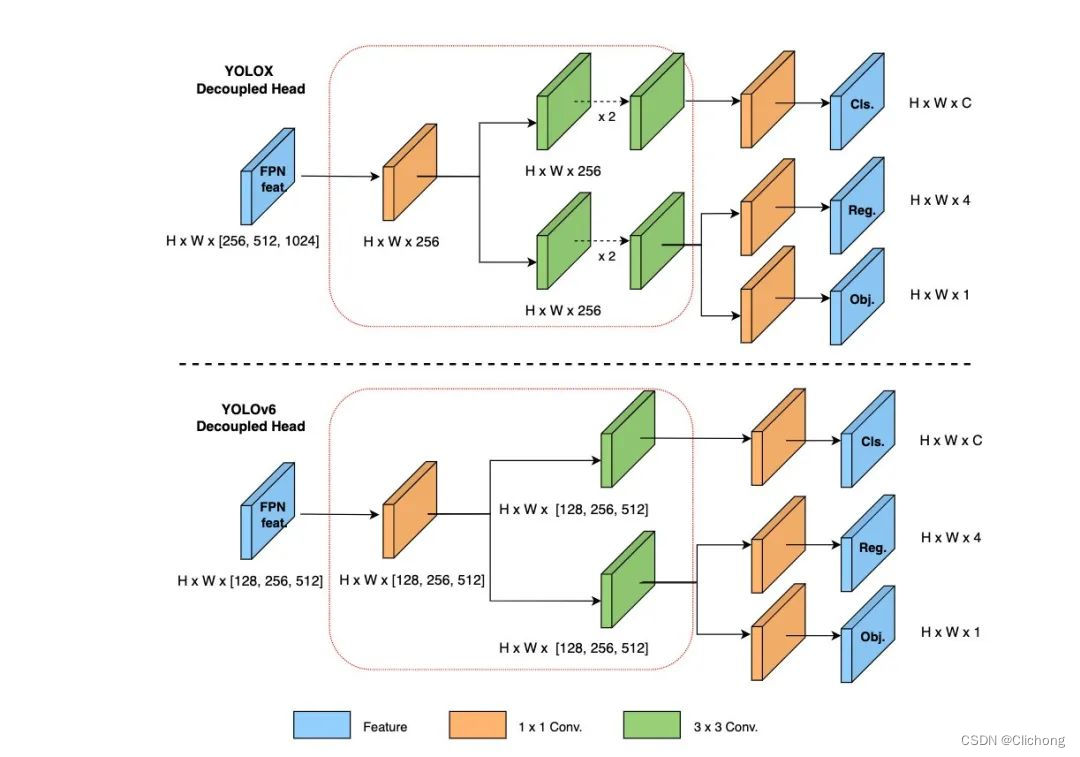
YOLOv5的检测头是一个耦合头,在分类和定位分支之间共享参数
在YOLOv6中,采用了一种混合通道(hybrid-channel)策略,以构建更高效的解耦头(就是使用不同的网络预测:类别、置信度、框)。具体而言,将中间3×3卷积层的数量减少到只有一个。head的宽度由backbone和neck的宽度乘数共同缩放。
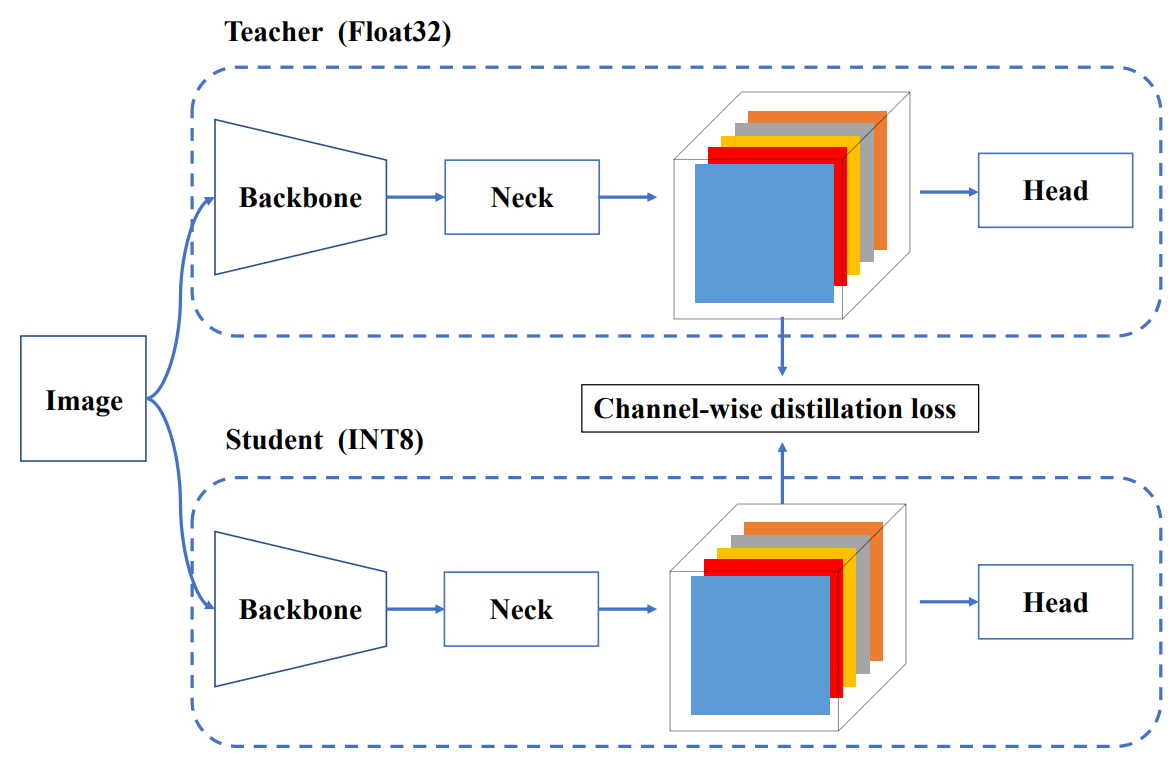
Quantization
v6是针对的工业界,所以会对量化部分比较看重
Quantization-aware Training with Channel-wise Distillation
v7
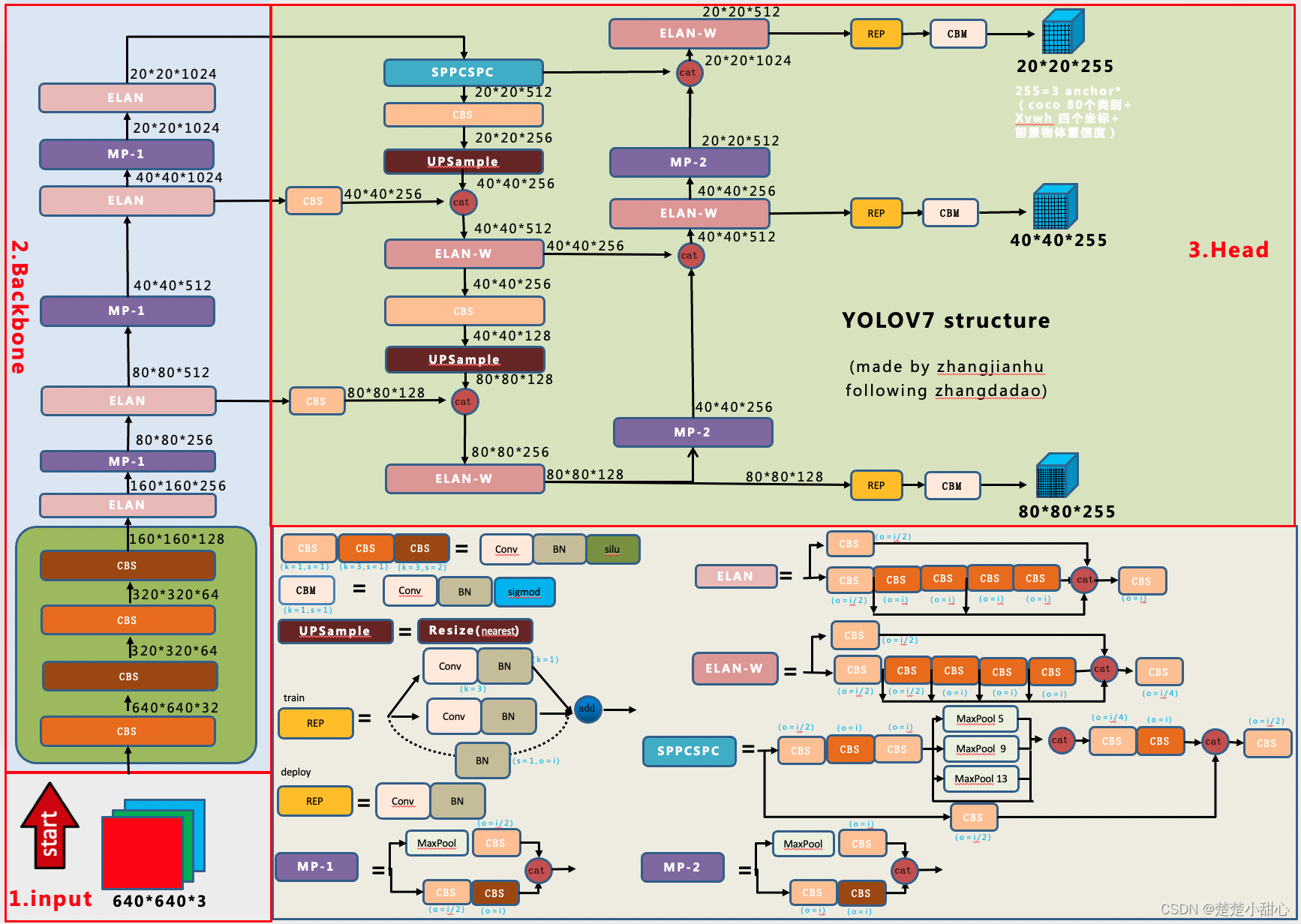
结构图
 内容
内容
使用 ELAN 和 MP 结构。ELAN可以带来更丰富的信息流。MP获取不同尺度上的信息流
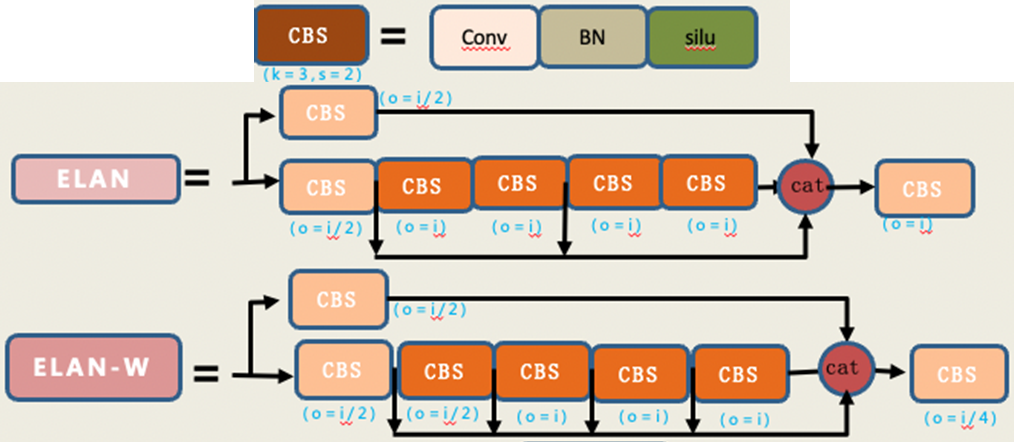
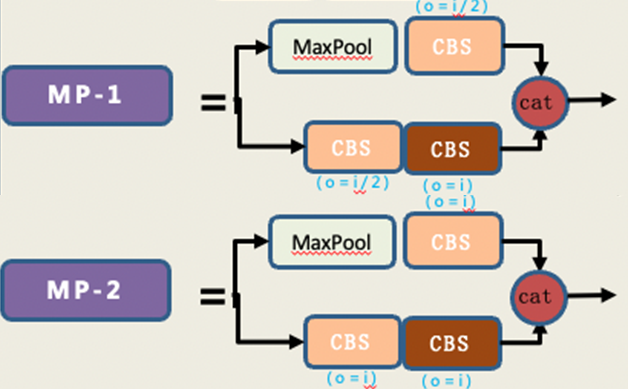
检测头整体结构和YOLOV5类似。但使用了Rep
使用了 Coarse for auxiliary and fine for lead loss 进行训练
v8
https://blog.csdn.net/zyw2002/article/details/128732494
结构图
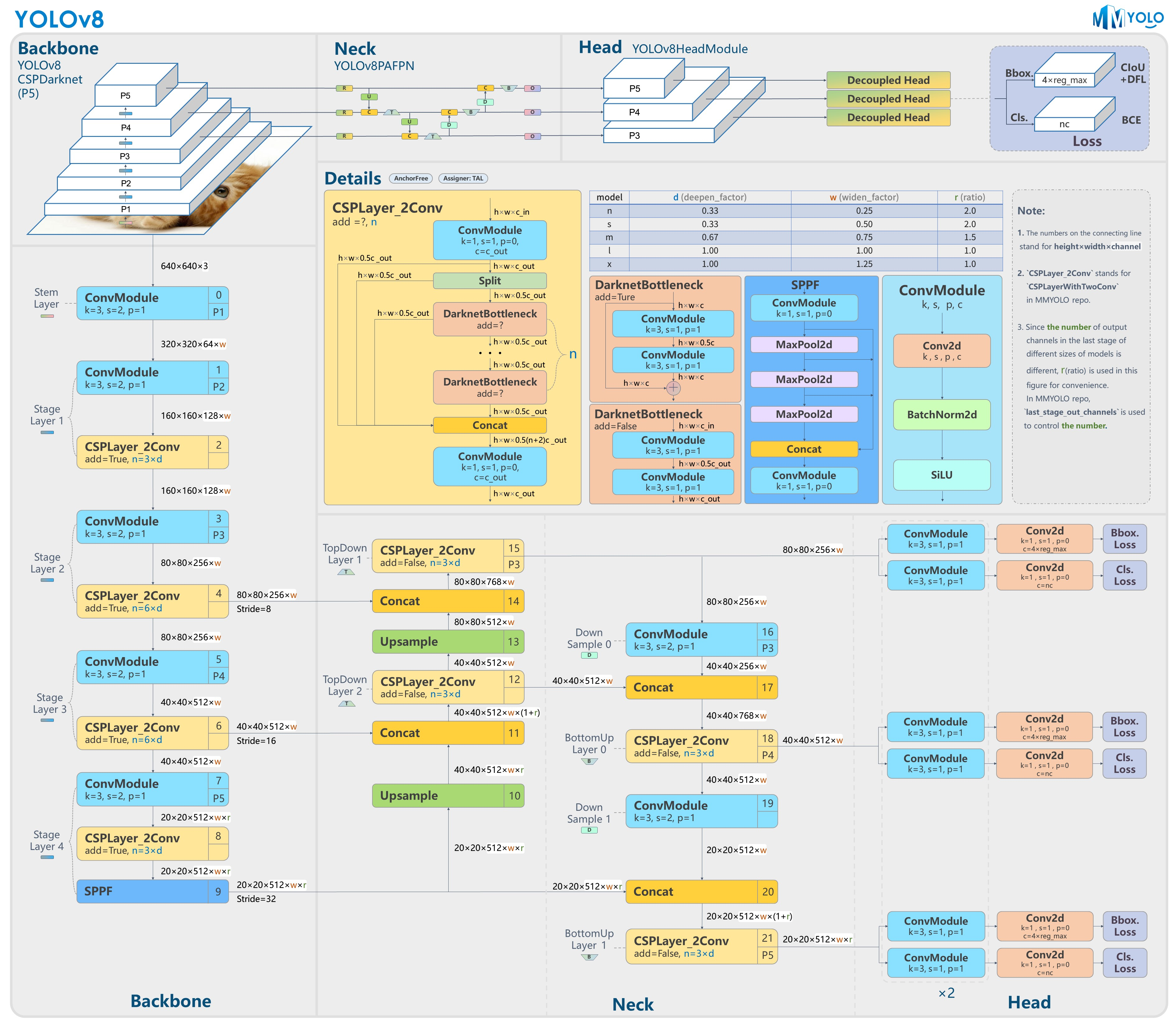
改进
backbone和neck与v5很相近
-
基本上都是一些细节上的变化
-
所有的 C3 模块换成梯度流更丰富的 C2f,结构如下所示,可以发现多了更多的跳层连接和额外的 Split 操作

head换成了解耦头,使用anchor free
v9
https://arxiv.org/pdf/2402.13616
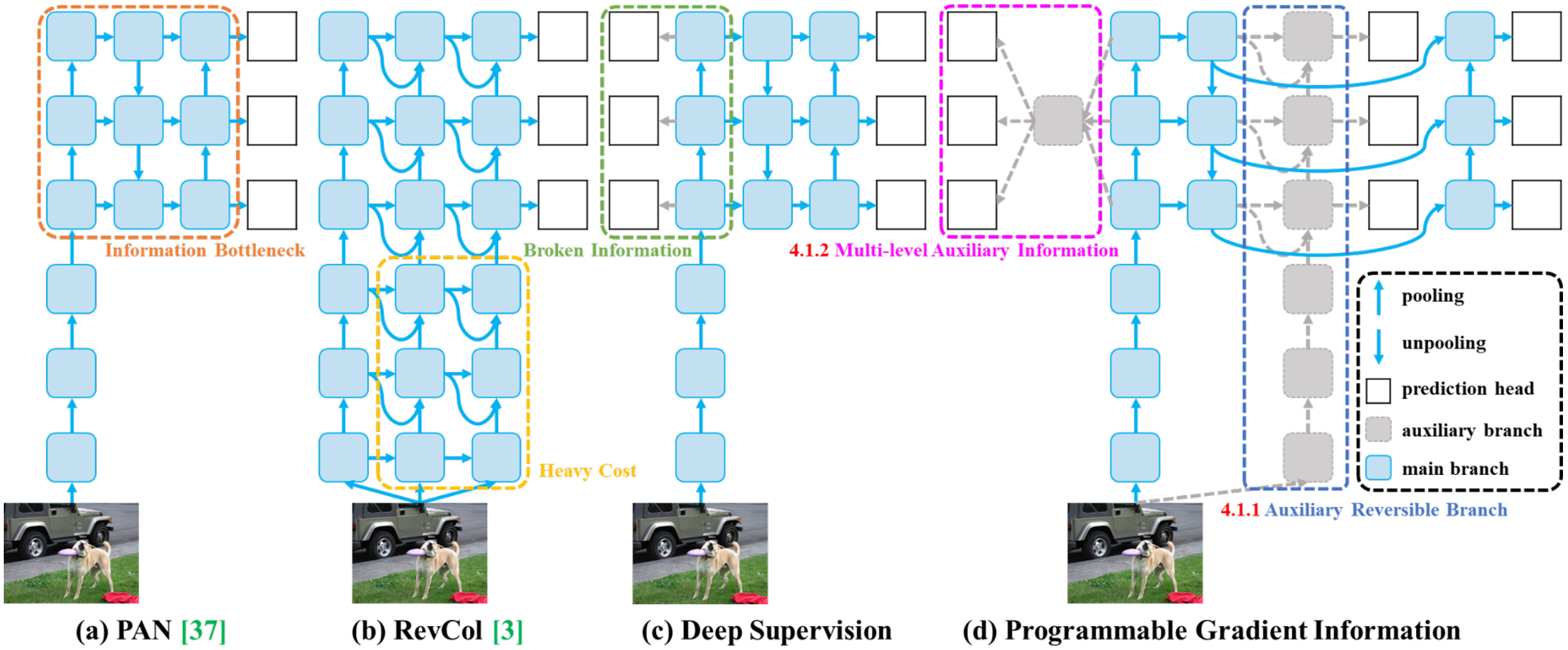
在YOLOv7的基础上,利用通用ELAN(GELAN)架构和可编程梯度信息(PGI)增强其功能。
CSPNet中可以使用任意模块,但信息流简单;ELAN中只使用了Conv,但信息流丰富。GELAN融合了上述两者中可以使用任意模块,能力更强
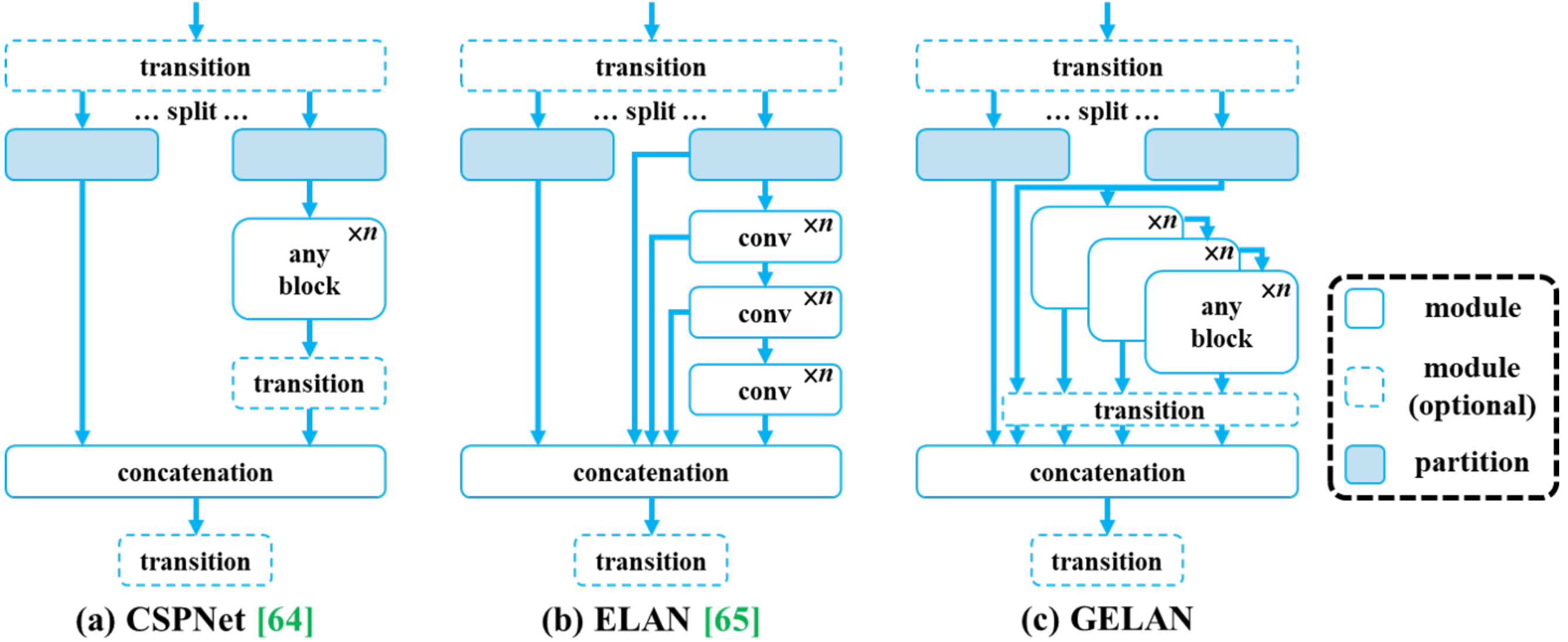
PGI理论上能够让训练更好,并且不会影响推理的效率
v10
-
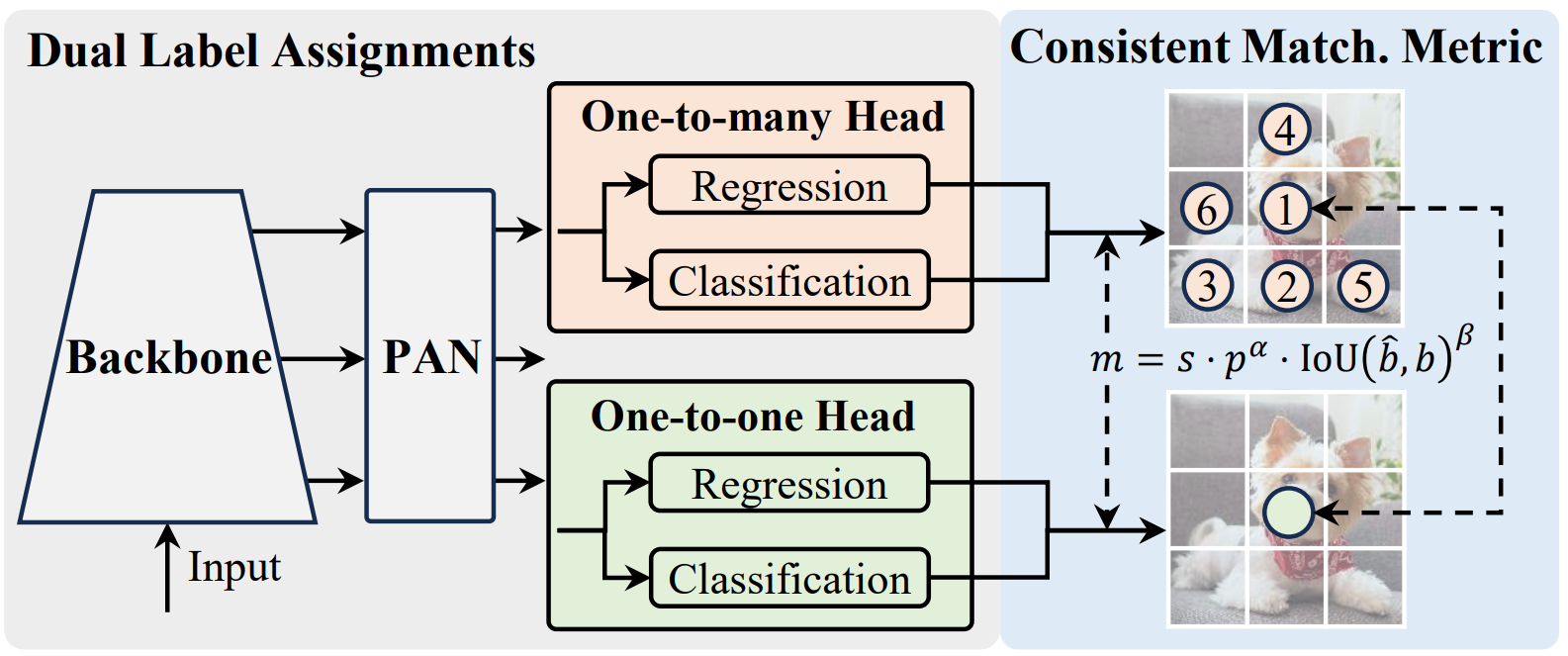
NMS-Free 训练: 使用 consistent dual assignments 替代 NMS 。(YOLO 面临一个 many-to-one 的窘境,即对于一个 GT 框来说,会存在多个正样本与之对应)。在训练过程中,两个 head 联合优化,以提供丰富的监督;在推理过程中,YOLOv10 会丢弃一对多 head 并利用一对一 head 做出预测。
-
整体的模型设计
-
轻量化的分类头
-
空间-通道解耦下采样: YOLO中一般使用stride为2的卷积下采样。v10中先point wise(空间) conv再接一个depth wise(通道) conv来下采样
-
基于秩的模块设计:根据模型不同阶段的冗余程度,调整网络模块,提高计算效率。
-
-
Enhanced Model Capabilities: 大尺寸的卷积和空间自注意力

















 590
590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









