







参考:Micha Gorelick, Ian Ozsvald. High Performance Python: Practical Performant Programming for Humans. Second Edition
关于该系列笔记的说明
在这个系列中,我会将学习Python高性能编程的知识笔记进行整理,作为云笔记放在这个专栏中。
整理的笔记中如果有错误和补充,欢迎修正和补充!
一、基础知识补充
1.1 高性能编程的概念
编程:将数据移动、运算后得到结果并输出的过程。
高性能编程:将编程实现的过程的时间耗费降低。
实现高性能编程的两种方式:
- 编写高效的代码
- 设计更优的算法
我们在这里主要关注如何编写高效的代码,也就是从计算机结构和编程语言特性出发。
1.2 计算机系统的基本元件概述
简单来讲,计算机系统可以分为三个模块:
- 计算单元(computing units),如CPU、GPU
- 存储单元(memory units),如固态硬盘、RAM、L1/L2缓存(CPU中的存储单元)
- 通讯层(Communications Layers),如总线(bus)/接口(interface)
1.2.1 计算单元
计算单元的作用:将接收的bits转化为其他的bits或是改变当前进程状态,简而言之——完成计算
计算单元的特征指标:
- 指令每时钟周期(Instructions per cycle, IPC):一个时钟周期内可以完成的操作数
- 时钟速度/频率(clock speed):一秒钟可以进行的时钟周期数
计算单元的重要特点:向量化(Vectorization),即一次性将多组数据提供给CPU并且每组数据都执行相同操作,从而使得在空间上并行。这样的一组指令集合也被称为单指令流多数据流(Single Instruction Multiple Data, SIMD)
由于物理限制,目前clock speed和IPC的增长趋缓(如下图所示),所以需要别的方法来提升运算速度:
- 超线程(Hyperthreading):添加第二个虚拟CPU进行运算
- 乱序执行(Out-of-order execution):当其他指令blocked时执行一些独立的、不依赖上一步结果的指令
- 多核架构:运算负荷量更大,也是目前电脑主流的设计方案(两核、四核等),但是要警惕阿姆达尔定律(Amdahl's Law)。任何一个并行计算的瓶颈总是由更小的串行任务决定。
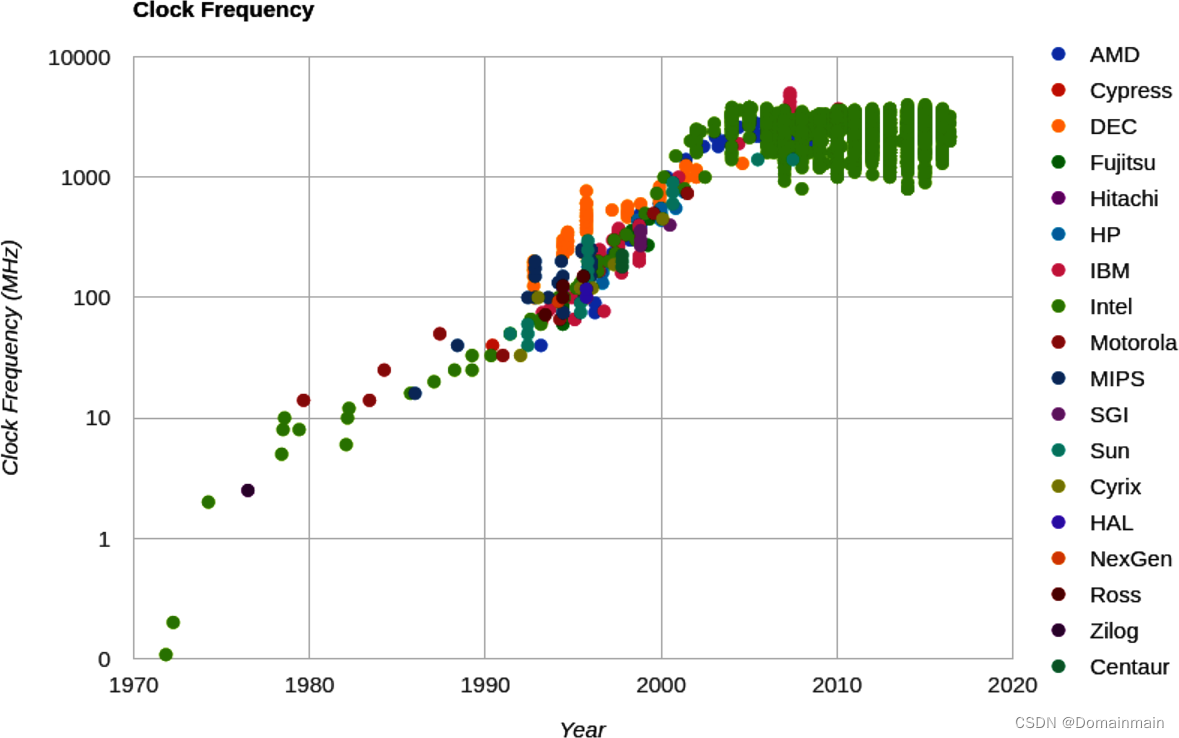
对于Python来说,由于存在全局解释锁(Global Interpreter Lock, GIL),会使得Python只能一次运行一条指令,与核的数量无关。不过有很多方法可以解决,比如multiprocessing库等。
1.2.2 存储单元
存储单元的作用:存储数据
存储单元的特征指标:
- 读取/写入数据的速度:与数据读取的方式有关,存储单元在读取大块数据的性能会好很多,类似于线性读取。
- 延迟(Latency):即存储单元寻找需要使用的数据的时间。
目前常见的几种存储单元以及它们的速度和载量如下:
- 旋转硬盘类(Spinning hard drive):长期存储用,甚至电脑关机也能保存,读写速度极慢但存储量大(~10T)
- 固态硬盘(Solid-state hard drive):相比于旋转硬盘读写速度更快,存储量更小(~1T)
- RAM(Random Access Memory):存储代码、变量数据,快速读写,存储量有限(~64G)
- L1/L2缓存:CPU读取数据之地,超快读写,极低存储量(MB级别)

为了更好地利用不同存储单元的特性,有一种分层存储的方式,即原始状态数据放在硬盘中,一部分放在RAM中,更小一部分放在L1/L2中。那么优化程序存储模式就是优化数据的摆放位置(哪一种存储单元)、摆放形式(线性读取)和转移次数。
1.2.3 通讯层
通讯层的作用:连接计算机的各个基本元件,并完成数据通信。通讯的模式有很多,但是可以统一称之为总线(bus)。
常见的总线:
- 前端总线(frontside bus):RAM与L1/L2缓存的连接,一般比较慢,而缓存到CPU的总线速度更快
- 外部总线(external bus):硬件设备与CPU、系统内存的连接
- PCI总线(Peripheral Component Interconnect bus):外围设备的连接总线,比如GPU,通常比较慢。GPU数据传输耗费大的问题往往使用异构计算的方式解决。
网络也是一种通讯元件,一个网络设备可以连接到存储设备,比如NAS(Network Attached Storage)设备。但是网络通讯相对于上述通讯会更加缓慢,这也是为什么大数据的转运不通过网络而是通过卡车托运。
总线最主要的性质就是速度,可以量化为:
- 带宽(bus width):在一次转运内能移动多少数据。带宽越大,向量化程度越高。
- 带频(bus frequency):每秒能完成多少次转运。带频越大,读取速度越快。
总线的带宽和带频可以通过物理主板上的芯片布局和连接线长短多少实现。
下图展现了常见接口的连接速度。
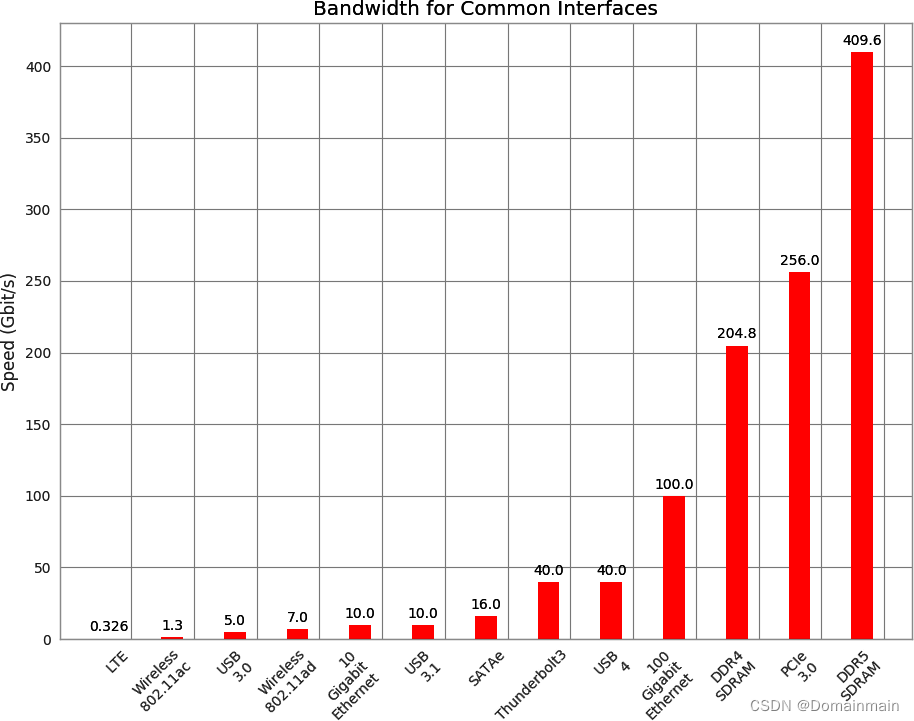
二、理解高性能编程
2.1 高性能编程的例子
下面是一段判断一个数是否为素数的Python代码:
import math
def check_prime(number):
sqrt_number = math.sqrt(number)
for i in range(2, int(sqrt_number) + 1):
if (number / i).is_integer():
return False
return True
print(f"check_prime(10000000) = {check_prime(10000000)}")
# check_prime(10000000) = False
print(f"check_prime(10000019) = {check_prime(10000019)}")
# check_prime(10000019) = True理想状态下,参数number的值被存储在RAM中,RAM将number的值传给CPU的缓存,CPU从缓存中读取值并进行平方根运算,得到的结果返回给RAM。对于循环体,每次循环都把一个i值传给CPU缓存,然后进行计算。
如果我们想要提升运算性能,我们或许可以在把number的值传给CPU缓存的同时,尽可能多的传入多个i的值。利用CPU的向量化特性,就可以同时判断多个“number-i”对,并且仅当存在True时才返回False。于是可以这样写:
import math
def check_prime(number):
sqrt_number = math.sqrt(number)
numbers = range(2, int(sqrt_number)+1)
for i in range(0, len(numbers), 5):
# 下面这一行是非法的代码
result = (number / numbers[i:(i+5)]).is_integer()
if any(result):
return False
return True上述代码虽然是非法的,但的确是一种向量化的思想。正确的向量化书写会在后续深入学习。
2.2 基于Python的高性能编程的缺陷
Python的一个重要特点是:Python解释器会自动管理数组的存储空间分配、存储空间的布局、数据传送的序列等。实现这种自动控制的核心是Python的抽象层(Abstract Layer),这种设计使得Python开发者不必在乎具体的细节就能直接调用,仅仅只需关心上层算法的设计。
但是这样做也会有坏处。我们知道提升代码性能最主要的工作就是找到并分析运行速度慢的部分,比如下面两个代码就很容易看出区别:
def search_fast(haystack, needle):
for item in haystack:
if item == needle:
return True
return False
def search_fast(haystack, needle):
return_value = False
for item in haystack:
if item == needle:
return_value = True
return return_value显然,search_fast()函数由于跳过了不必要的步骤提早结束,所以虽然二者的时间复杂度都是O(n),但是search_fast()的运行速度一定更快。
但是,如果使用了一些衍生数据类型、Python特殊方法,以及第三方库,我们就不方便优化代码:
def search_unknown1(haystack, needle):
return any((item == needle for item in haystack))
def search_unknown2(haystack, needle):
return any([item == needle for item in haystack])这两段代码中我们就无法看出二者哪个的运行速度更快。
Python的抽象层有这样一些坏处:
- 无法实现向量化操作(需要借助如numpy包来实现)
- 通过调整L1/L2缓存中存放的数据来优化代码是失效的
- Python对象在内存当中的布局不是最优的,这主要归咎于Python自动分配和释放内存。
- Python是不编译的,而是解释执行,所以没办法通过编译器操作静态编译代码
- Python存在动态类型,代码功能可能会因为优化结果而变化
- GIL存在限制
尽管如此,我们仍然决定使用Python编写高性能代码,一是因为Python目前有很多高效的标准库和第三方库可以解决上述问题,二是作为Python的频繁使用者,我们也更希望能把自己的代码优化得更高效。















 3120
3120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









