




 提出一种基于LSTM网络的生命体征预测模型DeepSigns,旨在通过历史数据预测患者生命体征变化并评估健康状况,准确率超过80%。
提出一种基于LSTM网络的生命体征预测模型DeepSigns,旨在通过历史数据预测患者生命体征变化并评估健康状况,准确率超过80%。
文献来源:
Denise Bandeira da Silva, Diogo Schmidt, Cristiano André da Costa, Rodrigo da Rosa Righi, Björn Eskofier, DeepSigns: A predictive model based on Deep Learning for the early detection of patient health deterioration, Expert Systems with Applications, Volume 165, 2021, 113905, ISSN 0957-4174. 原文网站链接.
目录
引言与摘要解读
危重病人早期诊断依靠对不同医学变量的观测,如生命体征、实验室化验结果等等。重症病人在病情恶化之前往往有生命体征的变化,而检测这些变化对于诊断结果的预测十分重要,进而能够在第一时间开始患者护理工作。能够对患者后续健康状况预测的指标就被称为预后指标。
那我们容易知道,预后指标数量多,数据量很大,怎么办呢?
近年来,随着网络的发展和进步,使用电子化的手段对健康信息进行记录会非常方便,目前最广泛的应用就是:电子健康记录(Electronic Health Records)。这个记录的应用使得患者的相关数据能够方便使用,进而可以通过机器学习等方法进行信息抽提,从而支持医疗决策。
本篇文献就是要建立一个模型,能够预测患者病情,以便及时开展治疗工作。
正如题目所言,本文基于深度学习、递归神经网络以及长短期记忆神经网络,以期建立预测患者生命体征、并通过预后指标评估患者健康状况的模型。据文献所说,预测的准确性>80%!
背景与预备知识
在进行进一步的探究之前,我们需要以下预备知识:
-
临床决策支持系统(Clinical Decision Support Systems, CDSS):一般指凡能对临床决策提供支持的计算机系统,这个系统充分运用可供利用的、合适的计算机技术,针对半结构化或非结构化医学问题,通过人机交互方式改善和提高决策效率的系统。
-
作用:识别患者健康风险情况,及时提醒医疗团队采取行动
-
举例:脓毒症黄金时间
-
-
电子健康记录(Electronic Health Records, EHR):可以理解为患者的电子版病历本,包含患者的全方位医疗记录,利用其中的数据可以进行医疗评估等等。
-
预后指标(Prognostic indexes):通过收集患者的健康状况以及特定生理指标,进行推断和计算,最终得出一个判断依据(通常是一个数字),这个依据就能够对患者病情进行评估。
-
常见的预后指标:序贯器官衰竭评估评分(Sequential Organ Failure Assessment Score, SOFA)、早期预警评分(Early Warning Score, EWS)、简化急性生理学评分(Simplified Acute Physiology Score Ⅱ)、急性生理学与慢性健康评估Ⅱ(Acute Physiology And Chronic Health Evaluation, APACHE II)
-
模型的提出与架构
文献根据传统的检测住院患者恶化的模型,使用LSTM网络预测生命体征,并计算预后指数,结合CDSS预测患者的病情。其模型如下图所示:
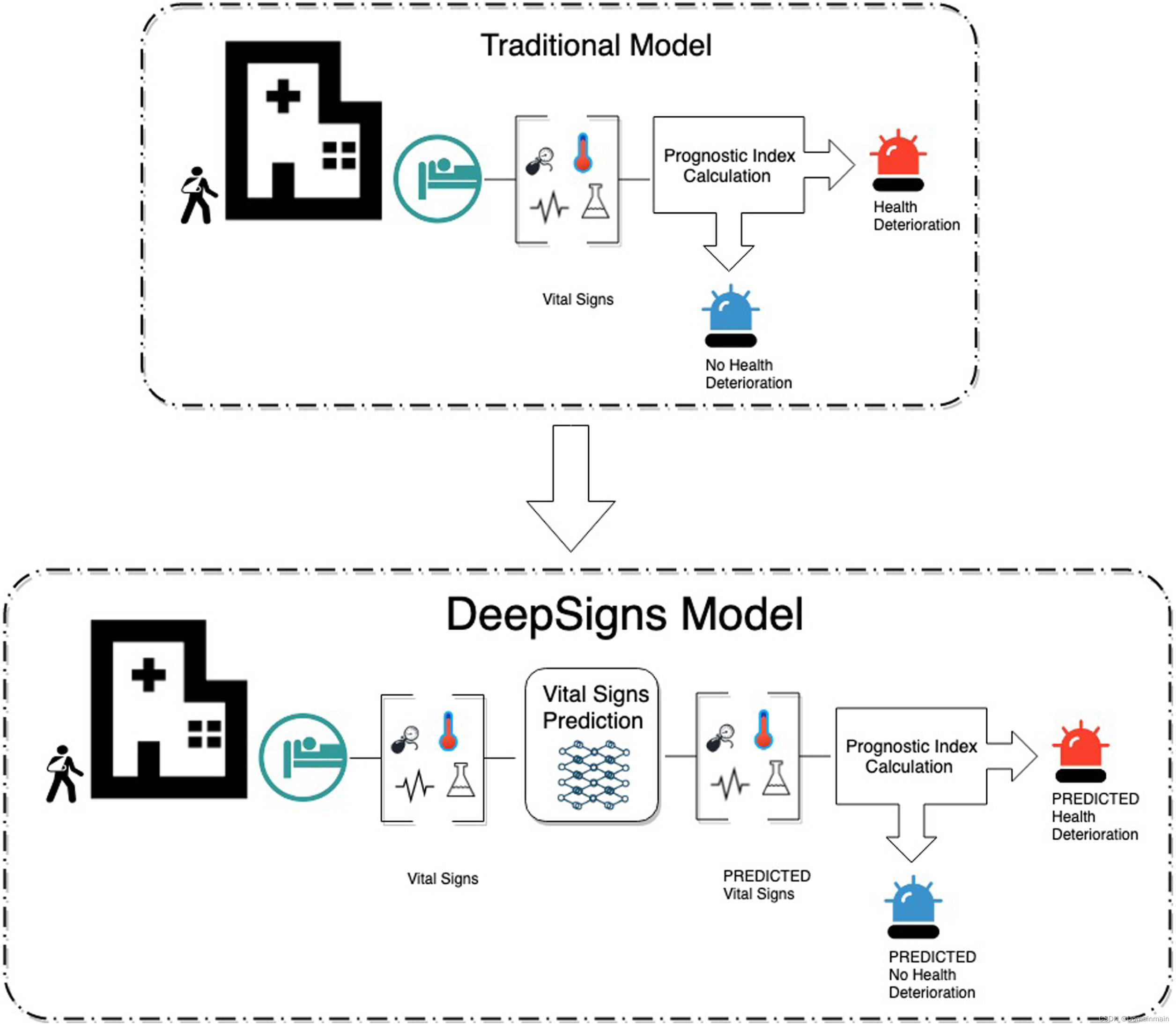
DeepSigns模型致力于通过检测到的患者生命体征,预测其后续的生命体征,结合预后指标的计算,从而得到患者的病情情况。
值得一提的是,本文采取的预后指标是上述提到的APACHE II,下图展示了APACHE II接受的生命体征和化验结果的输入:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









