






安装python环境
个人建议不要选最新版本的 安装之后在命令行下输入 python查看python版本
安装python编译器pycharm
目前安装的是2021.3专业版
永久破解方法(仅限2021.3)
- File->Setting->editor->font 设置字体字号大小
- File->Setting->editor->File and Code Templates 设置新建python文件时的模板
- 右击文件->Refactor->Rename->Refactor
基础语法
注释
单行注释:#或者CTRL+/
多行注释:’’’ 注释内容’’’
格式化输出
# -*- coding = utf-8 -*-
# @Time : 2022/1/13 9:45
# @Author : qiliang
# @File : demo1.py
# @Software: PyCharm
'''
132
'''
#这是我的第一个python程序
print("hello,world")
age=22
print("我的名字是:%s,我的国籍是:%s"%("dqf","中国"))
# 我的名字是:dqf,我的国籍是:中国
print("这是我的年龄:%d"%age)
# 这是我的年龄:22
print("aaa","bbb","ccc")
# aaa bbb ccc
print("www","baidu","com",sep='.')
# www.baidu.com
print("hello",end='')
print("world",end='\t')
print("python",end='\n')
print("end")
'''
helloworld python
end
'''
输入
password=input("请输入密码")
print("刚才输入的密码是:",password)
#默认输入的数据被认为是字符串
print(type(password))
#显示变量的类型
a=int(input())
#强制类型转换
- input()小括号放入的是提示信息
- input()在从键盘获取数据以后,会放入等号左边的变量中
- input()接受的输入必须是表达式
运算符
- *:返回两个数相乘的结果或者一个被重复若干次的字符串
- **:返回x的y次幂
- /:会保留小数
- //:整除 向下取整
条件判断
python指定任何非0和非空值为True
0或者None为False
if 判断语句1:
执行语句1
elif 判断语句2:
执行语句2
else:
执行语句3
课后作业:猜拳游戏
评论区别人的答案(没有运行过)
本人代码
# -*- coding = utf-8 -*-
# @Time : 2022/1/13 15:52
# @Author : qiliang
# @File : test.py
# @Software: PyCharm
import random
while True:
y = int(input("请输入:剪刀(0)、石头(1)、布(2):"))
if y != 0 and y != 1 and y != 2:
break
x = random.randint(0, 2)
if x == y:
print("平局")
elif x == 0:
if y == 2:
print("太可惜了,你输了")
if y == 1:
print("恭喜,你赢了")
elif x == 1:
if y == 0:
print("太可惜了,你输了")
if y == 2:
print("恭喜,你赢了")
elif x == 2:
if y == 1:
print("太可惜了,你输了")
if y == 0:
print("恭喜,你赢了")
flag = int(input("输入1表示继续,输入0表示退出游戏"))
if flag == 0:
break
循环语句
# -*- coding = utf-8 -*-
# @Time : 2022/1/13 17:10
# @Author : qiliang
# @File : demo2.py
# @Software: PyCharm
"""
for i in range(0, 100, 10): # for循环 range(起始值,结束值,自增值)
print(i)
"""
'''
name = "chengdu"
for x in name:
print(x, end="\t")
'''
a = ["aa", "bb", "cc", "dd"]
for i in range(len(a)):
print(i, a[i])
count = 1
while count < 5:
print(count, "小于5")
count += 1
else:
print(count, "大于等于5")
# python while可以跟else连用
for letter in 'Room':
if letter == '0':
pass
print('pass')
print(letter)
i = 0
while i < 10:
i += 1
print("-" * 30)
if i == 5:
break
print(i)
python里面while可以跟else连用
pass是空语句 一般用作占位语句 不做任何事情
a = 2
if a == 3:
pass
print(2)
print(5)
'''
输入5 而并没有输出2 个人理解直接跳过后面的语句
但是相比较continue而言 continue是跳过循环之后所有的语句
进入下一次循环 pass是跳过当前语句的执行语句
'''
课后作业:九九乘法表
来自b站评论区答案
本人代码
# -*- coding = utf-8 -*-
# @Time : 2022/1/13 15:52
# @Author : qiliang
# @File : test.py
# @Software: PyCharm
for x in range(1, 10):
for y in range(1, x + 1):
print("%d*%d=%d" % (x, y,x*y), end="\t")
print()
字符串
- python中的字符串可以使用单引号、双引号和三引号(三个单引号或三个双引号)括起来,使用反斜杠\转义特殊字符
- python3源码文件默认以UTF-8编码,所有字符串都是Unicode字符串
- 支持字符串拼接、截取等操作
# -*- coding = utf-8 -*-
# @Time : 2022/1/14 13:15
# @Author : qiliang
# @File : demo1.py
# @Software: PyCharm
'''
word = '字符串'
sentence = "这是一个句子"
paragraph = """这是一个段落
可以由多行组成
"""
print(word)
print(sentence)
print(paragraph)
'''
'''
#my_str = "I'm a student"
my_str = 'I\'m a student'
print(my_str)
'''
# my_str="Jason said \"I like you\""
'''
my_str = 'jason said "I like you" '
print(my_str)
'''
'''
str1 = "chengdu"
print(str1)
print(str1[0])
print(str1[0:6])
print(str1[1:7:2])
#[起始位置:结束位置:步长值]
#下标以0开始 结束位置-1
print(str1 + ",你好")
print(str1*3)
'''
print("hello\nchengdu")
#使用反斜杠,实现转义字符的功能
print(r"hello\nchengdu")
#在字符串前面加r,表示直接显示原始字符串,不进行转义
#hello\nchengdu
- 字符串可以切片 #[起始位置:结束位置:步长值]
- 下标以0开始 结束位置-1
- 在字符串前面加r,表示直接显示原始字符串,不进行转义(在进行爬取页面的时候会用到)
列表
- 列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)
- 列表可以使用+操作符进行拼接,*表示重复
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj)在列表末尾添加新的对象 |
| 2 | list.count(obj)统计某个元素在列表中出现的次数 |
| 3 | list.index(obj)从列表中找出某个值第一个匹配项的索引位置 |
| 4 | list.extend(seq)在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 5 | list.pop([index=-1])移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 6 | list.remove(obj)移除列表中某个值的第一个匹配项 |
| 7 | list.reverse()反向列表中元素 |
| 8 | list.sort( key=None, reverse=False)reverse – 排序规则,reverse = True 降序, reverse = False 升序(默认)。 |
| 9 | list.clear()清空列表 |
| 10 | list.copy()返回复制后的新列表。 |
a = [1, 2]
b = [3, 4]
a.append(b)
print(a)
# [1, 2, [3, 4]]
a = [1, 2]
a.extend(b)
print(a)
# [1, 2, 3, 4]
#append将列表作为一个元素 加入到a列表中
#extend 将b列表中的每一个元素,逐一追加到a列表中 a+b在这里也是一样的效果
a=[0,1,2]
a.insert(1,3)
print(a)
#第一个参数是要插入的下标 从0开始 第二个是插入的值
del a[2] #在指定位置删除一个元素
a.pop() #弹出末尾最后一个元素
a.remove(2) #直接删除指定内容的元素
mylist=["a","b","c","d","e"]
print(mylist.index("a",1,4))
#可以查找指定下标范围对的元素,并返回找到对应数据的下标 如果没有找到 则报ValueError错误
print(mylist.index("a",1,3)
#范围区间,左闭右开
a = [1, 2, 3]
b = a
这种方式复制 当b的值更改时 a的值也会更改
b=a[:] 或者 b=a.copy()
print(id(b),id(a))发现他们的id值不一样
这里分享一个python创建二维列表的方法 借鉴来的
python 创建二维列表,将需要的参数写入 cols 和 rows 即可
list_2d = [[0 for col in range(cols)] for row in range(rows)]
拓展知识点
列表推导式书写形式:
[表达式 for 变量 in 列表]
或者
[表达式 for 变量 in 列表 if 条件]
#!/usr/bin/python
# -*- coding: utf-8 -*-
li = [1,2,3,4,5,6,7,8,9]
print ([x**2 for x in li])
print ([x**2 for x in li if x>5])
print (dict([(x,x*10) for x in li]))
print ([ (x, y) for x in range(10) if x % 2 if x > 3 for y in range(10) if y > 7 if y != 8 ])
vec=[2,4,6]
vec2=[4,3,-9]
sq = [vec[i]+vec2[i] for i in range(len(vec))]
print (sq)
print ([x*y for x in [1,2,3] for y in [1,2,3]])
testList = [1,2,3,4]
def mul2(x):
return x*2
print ([mul2(i) for i in testList])
[1, 4, 9, 16, 25, 36, 49, 64, 81]
[36, 49, 64, 81]
{1: 10, 2: 20, 3: 30, 4: 40, 5: 50, 6: 60, 7: 70, 8: 80, 9: 90}
[(5, 9), (7, 9), (9, 9)]
[6, 7, -3]
[1, 2, 3, 2, 4, 6, 3, 6, 9]
[2, 4, 6, 8]
课后作业:购买商品
# -*- coding = utf-8 -*-
# @Time : 2022/1/15 14:03
# @Author : qiliang
# @File : demo3.py
# @Software: PyCharm
products = [["iphone", 6888], ["MacPro", 14800], ["小米6", 2499], ["Coffee", 31], ["Book", 60], ["Nike", 699]]
print("----商品列表----")
i = 0
for product in products:
print(i, product[0], product[1], sep="\t")
product.insert(0, i)
i += 1
buycar = []
while (True):
x = input("请输入要购买的商品编号")
if x == 'q':
break
elif int(x) < 0 or int(x) > 5 or x.isalnum() == False:
print("请输入正确的商品编号")
else:
index = int(x)
for product in products:
if index in product:
buycar.append(product)
break
s = 0
for product in buycar:
print(product[0], product[1], product[2], sep="\t")
s += product[2]
print("您一共购买了%d件商品,总价为%d" % (len(buycar), s))
元组(Tuple)
- tuple与list相似,不同之处在于tuple的元素不能修改。tuple写在小括号李,元素之间用逗号隔开。
- 元组的元素不可变,但可以包含对象
注意:定义只有一个元素的tuple时,必须加逗号
# -*- coding = utf-8 -*-
# @Time : 2022/1/15 15:18
# @Author : qiliang
# @File : demo4.py
# @Software: PyCharm
"""
tup1 =()#创建空的元组
print(type(tup1))
#<class 'tuple'>
tup2 =(50)
print(type(tup2))
#<class 'int'>
tup2=(50,)
#<class 'tuple'>
"""
'''
tup1=("abc","def",2000,2022)
print(tup1[0])
print(tup1[-1])#最后一个元素
print(tup1[1:5])#左闭右开
'''
'''
tup1=(12,34,56)
tup1[0]=100
#报错 元组元素不能修改
'''
'''
# 增
tup1 = (12, 34, 56)
tup2 = ("abc", "xyz")
print(tup2 + tup1)
'''
#删
tup1=(12,34,56)
print(tup1)
del tup1
print("删除后:")
print(tup1)
#name 'tup1' is not defined
#不能删除某一个元素 但是可以删除整个元组
| 操作名称 | 操作方法 |
|---|---|
| 获取元组长度 | len() |
| 获取元组元素最大值 | max() |
| 获取元组元素最小值 | min() |
| 其他类型对象转换成元组 | tuple() |
a=[1,2,3]
b=tuple(a)
(1,2,3)
字典(dict)
- 字典时无序的对象集合,使用键-值(key-value)存储,具有极快的查找速度。
- 键(key)必须使用不可变类型
- 同一个字典中,键(key)必须是唯一的。
info = {"name": "吴彦祖", "age": 19}
print(info["name"])
print(info["age"])
#print(info["gender"])
# 访问字典元素必须用键来进行访问
#如果直接访问了字典里面没有的键 会报KeyError错
#print(info.get("gender"))
#使用get方法,没有找到对应的键,默认返回:None
print(info.get("gender","m"))
#没有找到时默认返回 m
可以通过 字典名[“键名”]访问字典 但是当键不存在时会报错
也可以通过 字典名.get(“键名”)
#info = {"name": "吴彦祖", "age": 19}
#增
# newId =input("请输入新的学号")
# info["id"]=newId
# print(info["id"])
#删
#print("删除前:%s"%info["name"])
#del info["name"]
#print("删除前:%s"%info["name"])
#删除了指定键值对以后,再次访问会报错
#print("删除前:%s"%info)
#del info
#print("删除后:%s"%info)
#删除整个字典 再访问会报错
#【clear】清空
# print("清空前:%s"%info)
# info.clear()
# print("清空后:%s"%info)
# 清空前:{'name': '吴彦祖', 'age': 19}
# 清空后:{}
#改
'''
info = {"name": "吴彦祖", "age": 19}
info["age"]=22
print(info["age"])
'''
#查
info = {"name": "吴彦祖", "age": 19}
print(info.keys())
#得到所有键 (列表)
#dict_keys(['name', 'age'])
print(info.values())
#得到所有值(列表)
#dict_values(['吴彦祖', 19])
print(info.items())
#得到所有项(列表),每个键值对是一个元组
#dict_items([('name', '吴彦祖'), ('age', 19)])
print(info)
#{'name': '吴彦祖', 'age': 19}
#遍历所有的键
for key in info.keys():
print(key, end="\t")
print()
#遍历所有的值
for value in info.values():
print(value,end="\t")
print()
for key,value in info.items():
print("key=%s,value=%s"%(key,value))
mylist =["a","b","c","d"]
for i,x in enumerate(mylist):
print(i,x)
#用枚举函数,同时拿到列表中的下标和元素内容
'''
0 a
1 b
2 c
3 d
'''
mylist =[“a”,“b”,“c”,“d”]
for i,x in enumerate(mylist):
print(i,x)
#用枚举函数,同时拿到列表中的下标和元素内容
‘’’
0 a
1 b
2 c
3 d
‘’’
| 操作名称 | 操作方法 | 举例 |
|---|---|---|
| 获取字典长度 | len() | |
| 获取最大的key max() | ||
| 获取字典最小的key | min() | |
| 其他类型对象转换成字典 | dict() | dict([(1,2),(2,3)]) |
| 操作名称 | 操作方法 | 举例 |
|---|---|---|
| 字典元素的删除 | 通过key删除 | del dict1[‘小李’] |
| 字典元素的弹出 | 通过pop方法 | dict.pop(“小李”) |
| 判断key是否存在 | in | “key” in dict1 |
| 合并字典 | update | dict1.update(dict2) |
| 把两个列表转为一个字典 | dict+zip方法 | dict(zip(list1,list2)) |
| 把一个嵌套列表转为字典 | dict方法 | dict2=dict([[‘key1’,'value1]]) |
| 清除字典内的元素 | clear方法 | dict1.clear() |
集合
- set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key
- set是无序的,重复元素在set中自动被过滤
s=set([1,2,3])
{1,2,3}
s=set ([1,1,2,2,3,3])
1,2,3
常用操作
| 操作名称 | 操作方法 | 举例 |
|---|---|---|
| 遍历集合 | 通过for循环 | for i in set1:print(i) |
| 更新集合 | update方法 | set1.update(set2) |
| 向集合添加新元素 | add方法 | set1.add(5) |
| 移除集合中的元素 | remove方法 | set1.remove(5) |
| 弹出元素 | pop方法 | val=set1.pop() |
| 清除元素 | clear方法 | set1.clear() |
| 删除集合 | del | del set1 |
数据结构小结
| 是否有序 | 是否可变类型 | |
|---|---|---|
| 列表[ ] | 有序 | 可变类型 |
| 元组( ) | 有序 | 不可变类型 |
| 字典{ } | 无序 | key不可变,value可变 |
| 集合([ ]) | 无序 | 可变类型(不重复) |
函数
- 可以返回多个值
'''
def printinfo():
print("-----------")
print("人生苦短,我用python")
print("------------")
print(printinfo())
'''
'''
def diivid(a, b):
shang = a / b
yushu = a % b
return shang, yushu
sh, yu = diivid(5, 2)
print(sh, yu)
def fun1():
print("-"*20)
def fun2():
a=int(input("请输入要打印的行数"))
while a>0:
fun1()
a-=1
def fun3(a,b,c):
return a+b+c
def fun4(a,b,c):
return fun3(a,b,c)/3
fun2()
fun4(1,2,3)
'''
def test1():
a = 300
print("test1---修改前:a=%d" % a)
def test2():
a = 500
print("test2-----a=%d" % a)
文件
f = open("test.txt", "w")
#打开文件,w模式(写模式),问年不存在就新建
#默认是r模式
f.close()
常用访问模式
| 访问模式 | 说明 |
|---|---|
| r | 以只读方式打开文件,文件的指针将会放在文件的开头。这是默认模式 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件 |
f.readlines()一次性读取全部文件为列表,每行一个字符串元素
f.readline()一次读一行
f.read(num)读指定字符数 不指定默认读一行
'''
f = open("test.txt", "r")
content = f.read(5)
print(content)
content = f .read(5)
print(content)
f.close()
'''
'''
f = open("test.txt", "r")
content = f.readlines()
# 一次性读取全部文件为列表,每行一个字符串元素
# print(content)
for n, m in enumerate(content):
print(n, m)
f.close()
# 0 hello world
#
# 1 hello world
#
# 2 hello world
#
# 3 hello world
#
# 4 hello world
'''
f = open("test.txt", "r")
content = f.readline()
print("1:%s" % content)
content = f.readline()
print("2:%s" % content)
f.close()
文件重命名
os模块中的rename()可以完成对文件的重命名操作
rename(需要修改的文件名,新的文件名)
import os
os.rename("test.txt", "test1.txt")
文件删除
remove(待删除的文件名)
import os
os.remove("test1.txt")
创建文件夹
os.mkdir(“test”)
获取当前目录
os.getcwd()
改变默认目录
os.chdir("…/")
获取目录列表
os.listdir("./")
删除文件夹
os.rmkdir(“test”)
错误和异常
- 文件没找到属于IO异常(输入输出异常)
- 异常类型想要被捕获,需要一致
- 捕获多种异常用括号括起来 例如
- except(NameError,IOError)
#捕获异常
'''
try:
print("---test---1")
f = open("123.txt", "r")
#用只读模式打开一个不存在的文件报错
print("---test---2")
print(num)
#这句话没运行
except IOError:
#文件没找到属于 IO异常(输入输出异常)
pass
'''
'''
try:
print("---test---1")
f = open("123.txt", "w")
print("---test---2")
print(num)
except (NameError,IOError) as result:
print("产生错误了")
print(result)
'''
捕获所有异常使用 Exception
try:
print("---test---1")
f = open("123.txt", "w")
print("---test---2")
print(num)
except Exception as result:
print("产生错误了")
print(result)
python爬虫
什么是爬虫
网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或者脚本。由于互联网数据的多样性和有限性,根据用户需求定向抓取相关网页并分析已成为如今主流的爬取策略
爬虫可以做什么
你可以爬取自己想看的视频和图片等等,只要你能通过浏览器访问的数据都可以通过爬虫爬取。
爬虫的本质是什么
模拟浏览器打开网页,获取网页中我们想要的那部分数据
基本流程
准备工作
通过浏览器查看分析目标网页,学习编程基础规范
获取数据
通过HTTP库向目标站点发起请求,请求可以包含额外的head等信息,如果服务器能正常响应,会得到一个Response,便是所要获取的页面内容。
解析内容
得到的内容可能是HTML,json等格式可以使用页面解析库、正则表达式等进行解析
保存数据
保存形式多样,可以存为文本,也可以保存到数据库,或者保存特定格式的文件
编码规范
- 一般Python程序第一行需要加入
#-*- coding: utf-8 -*- 或者#coding=utf-8
这样可以在代码中包含中文
- Python文件中可以加入main函数用于测试程序
if _name_== “_main_”:
- Python使用#添加注释,说明代码(段)的作用
_ _name ==main
if name == 'main’的作用:
一个python文件通常有两种使用方法,第一是作为脚本直接执行,第二是 import 到其他的 python 脚本中被调用(模块重用)执行。因此 if name == ‘main’: 的作用就是控制这两种情况执行代码的过程,在 if name == ‘main’: 下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行,而 import 到其他脚本中是不会被执行的。
引入模块
from test1 import t1
# 引入自定义模块
import sys
import os
# 引入系统模块
import re
#引入第三方模块
导入bs4或者其他模块:
有下列几种方法:
-
将光标移到引入的库然后alt+enter快捷键补齐缺失的库
-
点击pycharm下面Terminal ->local ->输入pip install bs4(库名) 或者在命令提示符窗口下进入pycharm安装路径 下scripts文件夹 输入pip install bs4

如果出现PyCharm:open Local Terminal_Failed to start [powershell.exe]
解决方法 -
File ->Setting ->Project:XXX->python interpreter ->点击+号搜索库名 install page
注意:以上操作记得把电脑上的VPN关掉不然可能下载不成功
import bs4 #网页解释
import re #正则表达式
import urllib #制定url,获取网页数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
构建流程
- 爬取网页
- 解析数据
- 保存数据
测试使用urllib
获取一个get请求
# 获取一个get请求
# response = urllib.request.urlopen("http://www.baidu.com")
# print(response.read().decode('utf-8'))
urlopen不带其他参数是get方式
从网页读取下来的数据直接输出可能是乱码 需要将编码变换成utf-8再输出
获取一个post请求
# 获取一个post请求
# import urllib.parse
# data=bytes(urllib.parse.urlencode({"hello":"world"}),encoding="utf-8")
# response = urllib.request.urlopen("http://httpbin.org/post",data=data)
# print(response.read().decode("utf-8"))
data的值是若干键值对 有时会向浏览器发送用户名或者密码
超时处理
# try:
#
# response = urllib.request.urlopen("http://httpbin.org/get",timeout=0.01)
#
# print(response.read().decode("utf-8"))
# except urllib.error.URLError as a:
# print("time out")
timeout是设置的时间 如果超时则会出现urllib.error.URLError
为了代码的健壮性需要处理错误
详细模拟浏览器发送请求
# url = "http://httpbin.org/post"
# headers = {
# "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4533.400"
# }
# #User-Agent headers是字典不是字符串 里面的元素是键值对 所以需要分开引用
# data = bytes(urllib.parse.urlencode({"name": "eric"}), encoding="utf-8")
# req = urllib.request.Request(url=url, data=data, headers=headers, method="POST")
#
# response = urllib.request.urlopen(req)
#
# print(response.read().decode("utf-8"))
User-Agent headers是字典不是字符串 里面的元素是键值对 所以需要分开引用
# response = urllib.request.urlopen("http://www.baidu.com")
#
# print(response.getheader("Server"))
#返回Response header中Server的值
一般情况下模拟浏览器
一般只需要模拟header部分就行了
url = "http://www.douban.com"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4533.400"
}
req = urllib.request.Request(url=url, headers=headers, method="POST")
response = urllib.request.urlopen(req)
print(response.read().decode("utf-8"))
通过对象封装url
使用的测试是网站是 http://httpbin.org 打不开建议换一个浏览器
BeatuifulSoup
BeautifulSoup4将复杂HTML文档转换成一个复杂的树形结构
每个结点都是python对象,所有对象可以归纳成4种
- Tag
- NavigableString
- BeautifulSoup
- Comment
from bs4 import BeautifulSoup
file = open("./baidu.html", "rb")
html = file.read().decode("utf-8")
bs = BeautifulSoup(html, "html.parser")
Tag
# 1.Tag 拿到它所找到的第一个标签
# print(type(bs.head))
NavigableString
# 2NavigableString 标签里的内容(字符串)
# print(type(bs.title.string))
bs.title.text的效果也是一样
# print(bs.a.attrs)
# 得到一个字典 里面是第一个a标签的键值对
BeautifulSoup
# 3.BeautifulSoup 表示整个文档
# print(bs.name)#[document]
# print(bs.attrs)#{}
Comment
# print(type(bs.a.string))
# 4.Comment 是一个特殊的NavigableString 输出的内容不包括注释符号
文档的遍历
# print(bs.head.contents)
#['\n', <meta charset="utf-8"/>, '\n', <title>百度一下,你就知道</title>, '\n']
# print(bs.head.contents[1])
#<meta charset="utf-8"/>
# 更多内容,搜索BeautifulSoup文档
这是Beautiful Soup 4 的中文文档.
官方文档
原版文档
文档的搜索
find_all()
# 字符串过滤:会查找与字符串完全匹配的内容
# t_list=bs.find_all("a")
# print(t_list)
import re
# 正则表达式搜索:使用search()方法匹配内容
# t_list=bs.find_all(re.compile("a"))
# print(t_list)
# 方法 :传入一个函数(方法),根据函数的要求来搜索
# def name_is_exists(tag):
# return tag.has_attr("name")
#
# t_list=bs.find_all(name_is_exists)
#
# for item in t_list:
# print(item)
kwarys 参数
# t_list=bs.find_all(id="head")
# t_list=bs.find_all(class_=True)
# 因为class是python的关键字需要加下划线进行区分 bs4规定
# t_list=bs.find_all(href="http://news.baidu.com")
text参数
# t_list=bs.find_all(text="hao123")
# t_list = bs.find_all(text=["hao123", "地图", "贴吧"])
# t_list=bs.find_all(text=re.compile("\d"))
# 应用正则表达式来表达包含特定文本的内容(标签里的字符串)
limit参数
# t_list=bs.find_all("a",limit=3)
# for item in t_list:
# print(item)
css选择器
# t_list=bs.select('title')
# 通过标签来查找
# t_list=bs.select(".manav")
# 通过类名来查找 .代表类 #代表id
# t_list=bs.select("#u1")
#t_list = bs.select("a[class='bri']")
#通过属性来查找
#t_list=bs.select("head > title")
#通过子标签来查找
# t_list= bs.select(".manav ~ .bri")
#通过兄弟结点查找
# print(t_list[0].get_text())
# for item in t_list:
# print(item)
正则表达式
正则表达式常用的操作符(1)
| 操作符 | 说明 | 实例 |
|---|---|---|
| . | 表示任何单个字符 | |
| [ ] | 字符集,对单个字符给出取值范围 | [abc] 表示a、b、c,[a-z]表示a到z单个字符 |
| [^] | 非字符集 对单个字符给出排除范围 | [^abc]表示非a或b或c的单个字符 |
| * | 前一个字符0次或者无限次扩展 | abc* 表示ab adc abcc adccc等 |
| + | 前一个字符1次或者无限次扩展 | abc+ 表示 abc abcc abccc等 |
| ? | 前一个字符0次或者1次扩展 | abc? 表示ab 或者abc |
| | | 左右表达式任意一个 | abd|def表示abc、def |
| 操作符 | 说明 | 实例 |
|---|---|---|
| {m} | 扩展前一个字符m次 | ab{2}c表示abbc |
| {m,n} | 扩展前一个字符m至n次 | ab{1,2}c表示abc、abbc |
| ^ | 匹配字符串开头 | ^abc表示abc且在一个字符串的开头 |
| $ | 匹配字符串结尾 | abc$表示abc且在一个字符串的结尾 |
| () | 分组标记,内部只能用|操作符 | (abc)表示abc (abc|def)表示abc或者def |
| \d | 数字等价于[0-9] | |
| \w | 单词字符,等价于[A-Za-z0-9_] |
Re库主要函数
| 函数 | 说明 |
|---|---|
| re.search() | 在一个字符串中搜索匹配正则表达式的第一个位置 返回match对象 |
| re.match() | 从一个字符串的开始位置起匹配正则表达式,返回match对象 |
| re.findall() | 搜索字符串,以列表类型返回全部能匹配的字串 |
| re.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
| re.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象 |
| re.sub() | 在一个字符串中替换所有匹配正则表达式的字串 |
正则表达式可以包含一些可选标识符来控制匹配的模式,修饰符被被指定为一个可选的标志。多个标志可以按位OR(|)它们来指定,如果re.l | re.M 被设置成 l和M标志
| 修饰符 | 描述 |
|---|---|
| re.l | 使匹配对大小写不敏感 |
| re.L | 做本地化(locale -aware)匹配 |
| re.M | 多行匹配 影响 ^和% |
| re.S | 使.匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符 这个标志影响 \w \W \b \B |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 |
标签解析
Beautiful Soup
Beautiful Soup是一个库 提供一些简单的,python式的用来处理导航、搜索、修改分析树等功能,通过解析文档为用户提供需要抓取的数据、我们需要的每个电影都在一个<div>标签中,且每个div标签都有一个属性class=‘item’
soup =BeautifulSoup(html,“html.parser”)
创建BeautifulSoup对象,html为页面内容,html.parser是一种页面解析器
for item in soup.find_all (“div”,class=“item”)
找到能够完整提取出一个影片内容的项,即页面中所有样式是item类的div
正则提取
# 影片详情链接的规则
findLink = re.compile(r'<a href="(.*?)">')
# 影片图片的链接
findImageSrc = re.compile(r'<img.*src="(.*?)"', re.S)
# re.S让换行符包含在字符中
# 影片的片名
findTitle = re.compile(r'<span class="title">(.*)</span>')
# 影片的评分
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
# 找到评价人数
findJudge = re.compile(r'<span>(\d*)人评价</span>')
# 找到概况
findInq = re.compile(r'<span class="inq">(.*)</span>')
# 找到影片的相关内容
findBd = re.compile(r'<p class="">(.*?)</p', re.S)
# 创建正则表达式对象 表示规则(字符串的模式)
保存数据
Excel表格存储
利用python库xlwt将抽取的数据datalist写入Excel表格
# -*- coding = utf-8 -*-
# @Time : 2022/1/24 15:24
# @Author : qiliang
# @File : testXlwt.py
# @Software: PyCharm
import xlwt
workbook=xlwt.Workbook(encoding="utf-8")
#创建workbook对象
worksheet=workbook.add_sheet('sheet1')
#创建工作表
worksheet.write(0,0,"hello")
#写入数据 第一行参数行 第二个参数列 第三个参数内容
workbook.save('student.xls')
#保存数据表
完成豆瓣项目读取
# -*- coding = utf-8 -*-
# @Time : 2022/1/19 13:21
# @Author : qiliang
# @File : spider.py
# @Software: PyCharm
import re
import urllib.request
from bs4 import BeautifulSoup
import xlwt
def main():
baseurl = "https://movie.douban.com/top250?start="
# 爬取网页
datalist = getData(baseurl)
# 保存数据
savepath = r".\豆瓣电影Top250.xls"
saveData(datalist, savepath)
# saveData(savepath)
# askURL("https://movie.douban.com/top250?start=")
# 影片详情链接的规则
findLink = re.compile(r'<a href="(.*?)">')
# 影片图片的链接
findImageSrc = re.compile(r'<img.*src="(.*?)"', re.S)
# re.S让换行符包含在字符中
# 影片的片名
findTitle = re.compile(r'<span class="title">(.*)</span>')
# 影片的评分
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
# 找到评价人数
findJudge = re.compile(r'<span>(\d*)人评价</span>')
# 找到概况
findInq = re.compile(r'<span class="inq">(.*)</span>')
# 找到影片的相关内容
findBd = re.compile(r'<p class="">(.*?)</p', re.S)
# 创建正则表达式对象 表示规则(字符串的模式)
def getData(baseurl):
datalist = []
for i in range(0, 10):
url = baseurl + str(i * 25) # 调用获取页面信息的函数 10次
html = askURL(url) # 保存获取到的网页源码
# 逐一解析
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"):
# print(item) 测试查看电影item全部信息
data = [] # 保存一部电影的所有信息
item = str(item)
link = re.findall(findLink, item)[0]
data.append(link) # 添加链接
imgSrc = re.findall(findImageSrc, item)[0]
data.append(imgSrc) # 添加图片
title = re.findall(findTitle, item)
if len(title) == 2:
ctitle = title[0]
data.append(ctitle) # 添加中文名
otitle = title[1].replace("/", "") # 去掉无关的符号
data.append(otitle) # 添加外文名
else:
data.append(title[0])
data.append(' ')
rating = re.findall(findRating, item)[0]
data.append(rating) # 添加评分
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum) # 添加评价人数
inq = re.findall(findInq, item)
data.append(inq) # 添加概述
if len(inq) != 0:
inq = inq[0].replace("。", "") # 调试时出现错误
# 去掉句号
data.append(inq)
else:
data.append(" ") # 留空
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', " ", bd) # 去掉</br>
bd = re.sub("/", " ", bd)
data.append(bd.strip()) # 去掉前后的空格
datalist.append(data)
# re库通过正则表达式查找指定的字符串
return datalist
# 得到一个指定URL的网页内容
def askURL(url):
head = { # 模拟浏览器头部信息 ,向豆瓣服务器 发送消息
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4533.400"
} # 用户代理 表示告诉豆瓣服务器 我们是什么类型的机器 浏览器 (本质上是告诉浏览器 我们可以接受什么水平的文件内容)
request = urllib.request.Request(url=url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 爬取网页
# 逐一解析数据
# 保存数据
def saveData(datalist, savepath):
import xlwt
print("save...")
book = xlwt.Workbook(encoding="utf-8", style_compression=0)
# 创建workbook对象
sheet = book.add_sheet('豆瓣电影top250', cell_overwrite_ok=True)
# 创建工作表
col = ('电影详情链接', '图片链接', '影片中文名', '影片外国名', '评分', '评价树', '概况', '相关信息')
for i in range(0, 8):
sheet.write(0, i, col[i]) # 列名
for i in range(0, 250):
print("第%d条" % (i+1))
data = datalist[i]
for j in range(0, 8):
sheet.write(i + 1, j, data[j]) # 调试时出现错误
# 数据 datalist是一个个列表
# 写入数据 第一行参数行 第二个参数列 第三个参数内容
book.save(savepath)
# 保存数据表
if __name__ == "__main__":
main()
print("爬取完毕")
保存数据到SQLlite
爬虫获取到的数据不仅可以保存到excel还可以保存到数据库
这里我们用到的数据库是SQLlite
测试sqllite
# -*- coding = utf-8 -*-
# @Time : 2022/1/24 16:44
# @Author : qiliang
# @File : testSqlite.py
# @Software: PyCharm
#1 连接数据库
#conn = sqlite3.connect("test.db")
#print("open database successfully)
#2 创建数据表
#
import sqlite3
#
# conn = sqlite3.connect("test.db")
# # 打开或创建数据库文件
# print("成功打开数据库")
# c = conn.cursor()
#
# sql = '''
# create table company
# (id int primary key not null,
# name text not null,
# age int not null,
# address char(50),
# salary real);
# '''
#
# c.execute(sql) # 执行sql语句
# conn.commit() # 提交数据库操作
# conn.close() # 关闭数据连接
# print("成功建表")
#3.插入数据
#
# conn = sqlite3.connect("test.db")
# # 打开或创建数据库文件
# print("成功打开数据库")
# c = conn.cursor() #获取游标
# sql1 = '''
# insert into company(id,name,age,address,salary)
# values (1,'张三',32,'成都',8000);
#
# '''
# sql2='''
# insert into company(id,name,age,address,salary)
# values (2,'李四',30,'重庆',6000)
#
# '''
# c.execute(sql1) # 执行sql语句
# c.execute(sql2)
# conn.commit() # 提交数据库操作
# conn.close() # 关闭数据连接
# print("插入数据完毕")
#插入数据
conn = sqlite3.connect("test.db")
# 打开或创建数据库文件
print("成功打开数据库")
c = conn.cursor() # 获取游标
sql1 = '''
select id,name,age,address,salary from company
'''
cursor=c.execute(sql1) # 执行sql语句
for row in cursor :
print("id = ",row[0])
print("name = ",row[1])
print("age = ",row[2])
print("address = ",row[3])
print("salary = ",row[4],"\n")
conn.close() # 关闭数据连接
print("查询数据完毕")
当执行完创建语句左边会生成一个数据库文件
双击可以添加到右边的database 或者点击右边的+然后点击new 再选择sqllite
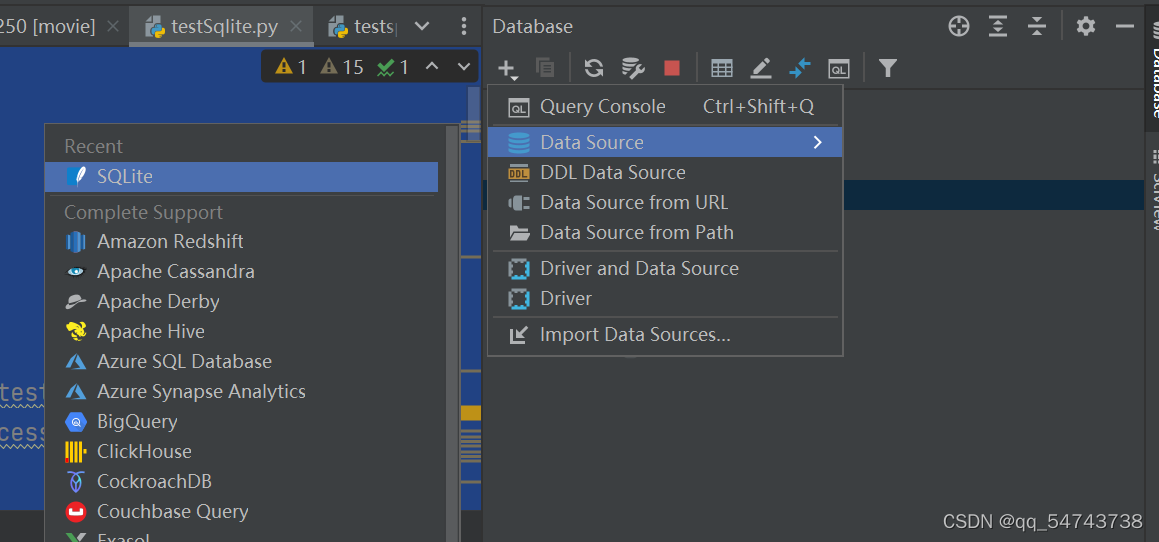
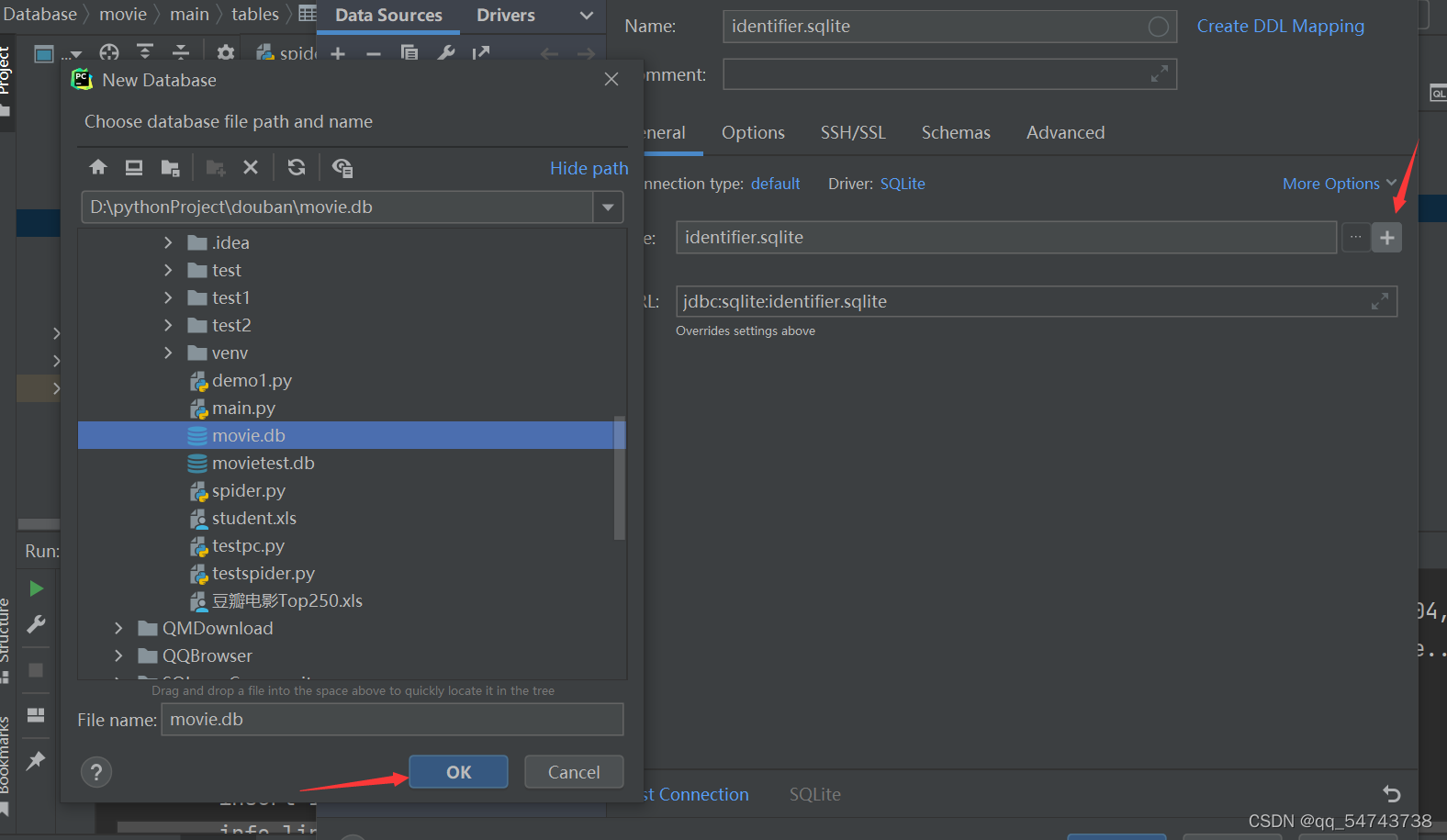
数据可视化
Flask入门
了解框架
Flask作为web框架,它的作用主要是为了开发web应用程序。
为什么要用web框架
web网站发展至今,特别是服务器端,涉及到的知识、内容非常广泛。这对程序员的要求会越来越高。如果采用成熟、稳健的框架、那么一些基础的工作,比如网络操作、数据库访问、会话管理等都可以让框架来处理,那么程序开发人员可以把精力放在具体的业务逻辑上面。使用web框架开发web应用程序可以降低开发难度,提高开发效率。
为什么要使用web框架:避免重复造轮子
补充Flask
导入Flask
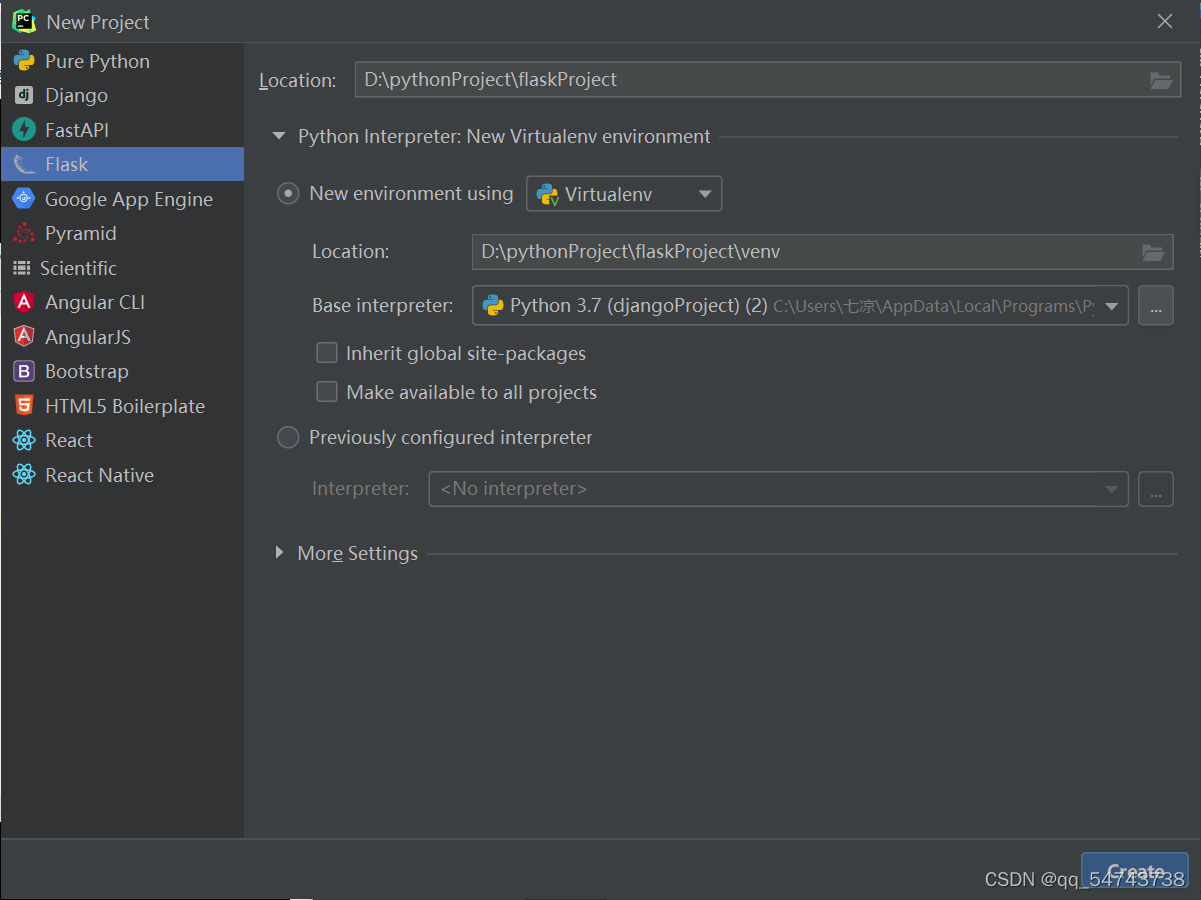
测试Flask
from flask import Flask,render_template
app = Flask(__name__)
#路由解析 通过用户访问的路径,匹配相应的函数
# @app.route('/')
# def hello_world(): # put application's code here
#
# return '你好,欢迎光临'
#debug模式开启
如果没开启debug模式不能实时刷新得到结果
需要点击关闭再点击运行 
开启debug模式:
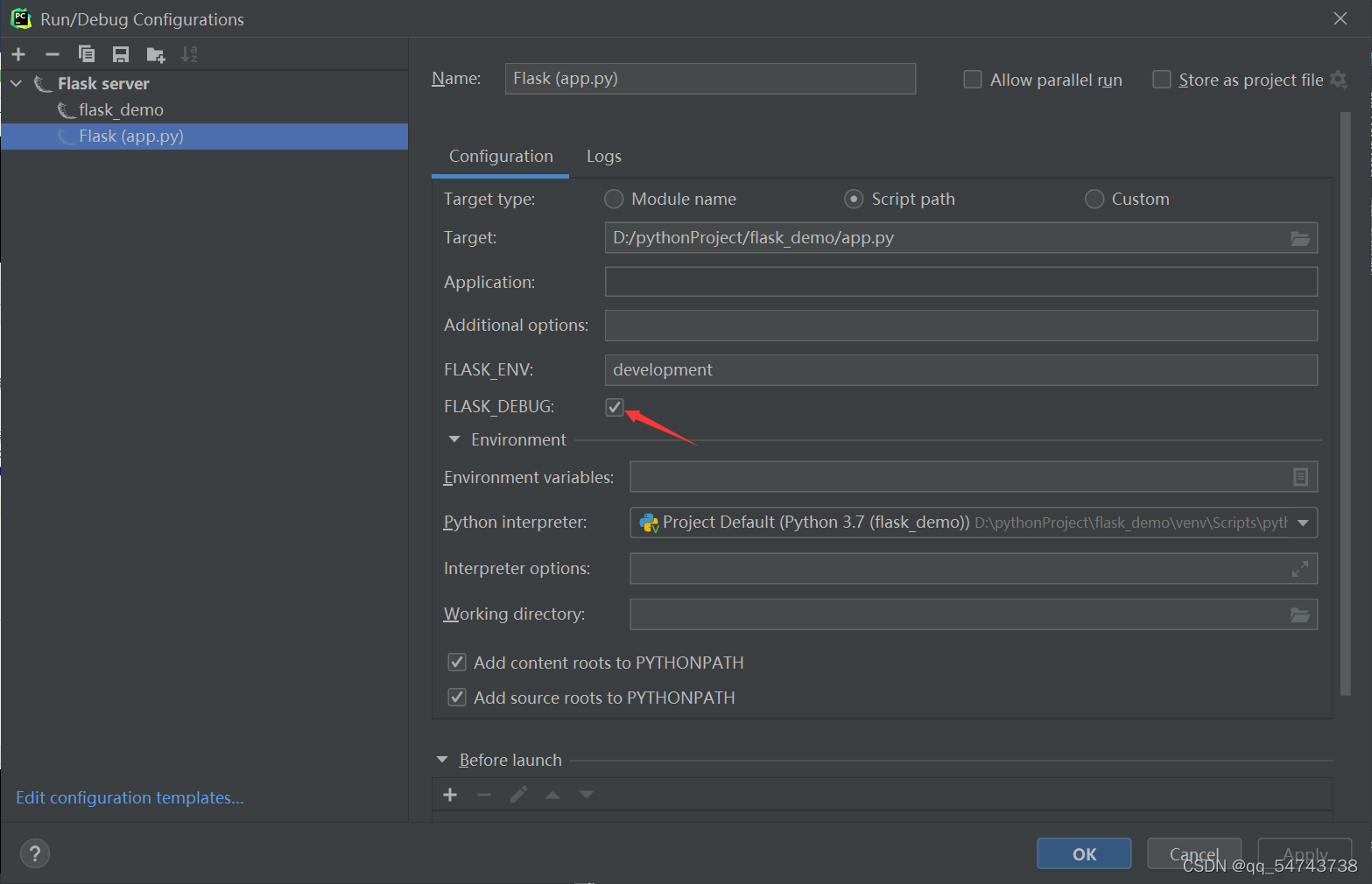
from flask import Flask, render_template, request
import datetime
app = Flask(__name__)
# 路由解析 通过用户访问的路径,匹配相应的函数
# @app.route('/')
# def hello_world(): # put application's code here
#
# return '你好,欢迎光临'
# debug模式开启
@app.route("/index")
def hello():
return "你好"
# 通过访问路径,获取用户的字符串参数
@app.route("/user/<int:id>")
def welcome(id):
return "你好,%d号的会员" % id
# 路由路径不能重复,用户通过唯一路径访问特定的函数
# 路由路径指的是route括号里面的内容
# @app.route("/")
# def index2():
# return render_template("index.html")
# 返回给用户渲染后网页文件
@app.route("/")
def index2():
time = datetime.date.today()
name = ["小张", "小王", "小赵"]
task = {"任务": "打扫卫生", "时间": "3小时"}
return render_template("index.html", var=time, list=name, task=task)
# 向页面传递一个变量
# {{ 变量名 }}可以获取服务器端传进来的值
# 表单提交
@app.route('/test/register')
def register():
return render_template("test/register.html")
# 接收表单的路由,需要指定methods为post
@app.route('/result', methods=['POST', 'GET'])
def result():
if request.method == 'POST':
result = request.form
return render_template("test/result.html", result=result)
if __name__ == '__main__':
app.run(debug=True)














 4673
4673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









