







视觉特征金字塔在广泛的应用中显示出其有效性和效率的优势。然而,现有的方法过分集中于层间特征交互,而忽略了层内特征规则,这在经验上被证明是有益的。
1.基于网络内特征金字塔的方法(是用适当的上下文信息为不同大小的每个目标分配感兴趣区域,并使这些目标能够在不同的特征层中被识别):
例如SSD和FFP
2.基于CNN主干方法:
- FPN提出了一种自上而下的层间特征交互机制
- 受非局部/自注意力机制的启发,用于空间特征调节的更精细的层内交互方法也应用于对象检测任务,例如非局部特征和GCNet。
- 基于上述两种交互机制,FPT进一步提出了层间跨层和层内跨空间特征调节方法,并取得了显著的性能。
缺点:上述方法基于CNN主干,而CNN主干受到固有的极限感受野的影响。
3.基于Transformer方法(将输入图像划分为不同的图像块,然后使用块之间基于多头注意力的特征交互来完成获取全局长距离相关性的目的。):
PVT和Swin transformer
缺点:尽管这些方法可以解决CNN中有限的感受野和局部上下文信息,但一个明显的缺点是它们的计算复杂性大。
是否有必要在所有层上使用Transformer编码?
浅层特征主要包含一些一般的目标特征模式,例如纹理、颜色和方向,这些通常不是全局的。相反,深度特征反映了目标特定信息,通常需要全局信息。因此,作者认为Transformer编码器在所有层中都是不必要的
提出了一种用于目标检测的集中式特征金字塔(CFP)网络,该网络基于全局显式集中式规则方案
具体而言,基于从CNN主干提取的视觉特征金字塔,首先提出了一种显式视觉中心方案:轻量级MLP架构来捕获长距离依赖 + 并行可学习视觉中心机制来聚合输入图像的局部关键区域。
考虑到最深的特征通常包含浅层特征中缺乏的最抽象的特征表示这一事实,基于所提出的规则方案,然后以自上而下的方式对提取的特征金字塔提出了全局集中的规则,其中从最深特征获得的空间显式视觉中心用于同时调节所有的前部浅特征。
CFP架构
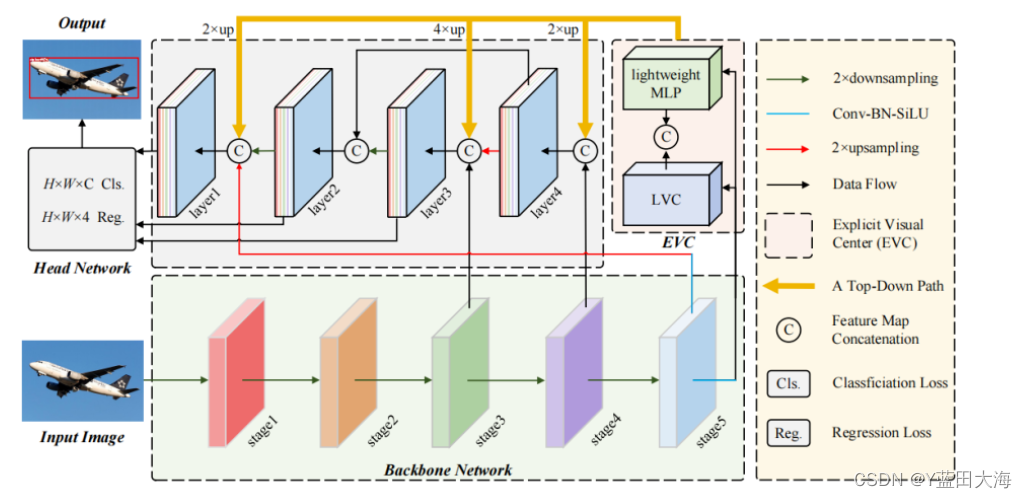
1. 输入

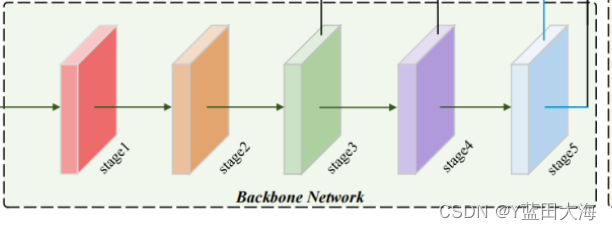
2.用于提取视觉特征金字塔的CNN主干
修改后的CSP v5,每层特征Xi(0,1,2,3,4) 分别为输入图像的1/2,1/4,1/8,1/16,1/32
3. 提出的显式视觉中心(EVC)
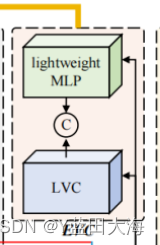
提出的EVC主要由两个并行连接的块组成,其中使用轻量级MLP来捕获顶级特征的全局长期依赖性(即全局信息)。同时,为了保留局部角区域(即,局部信息),提出在上实现可学习的视觉中心机制以聚集层内局部区域特征
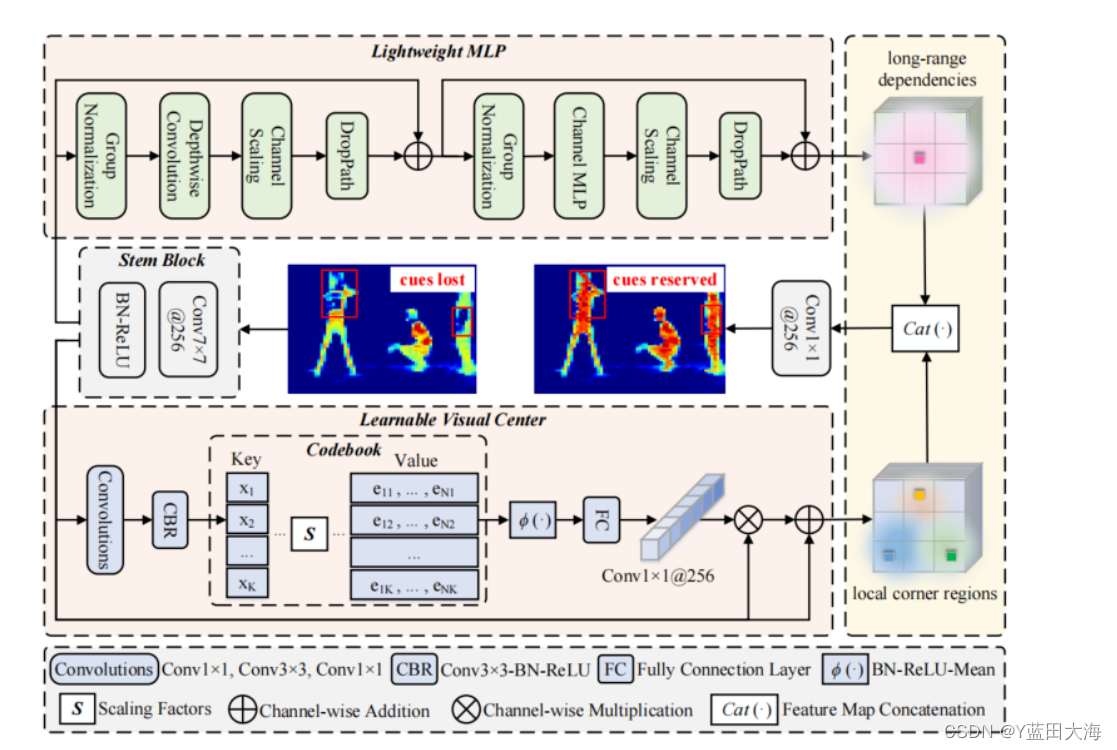
Stem块用于特征平滑,而不是直接在原始特征图上实现(通道大小为256的7×7卷积组成,随后是批处理归一化层和激活函数层):

MLP:
主要由两个残差模块组成:基于深度卷积的模块和基于通道MLP的模块,其中基于MLP的模块的输入是基于深度卷积模块的输出。这两个块之后都是通道缩放操作和DropPath操作,以提高特征泛化和鲁棒性能力。(下图旋转了,下半部分是左,上半部分为右,下半部分输出为上半部分输入)
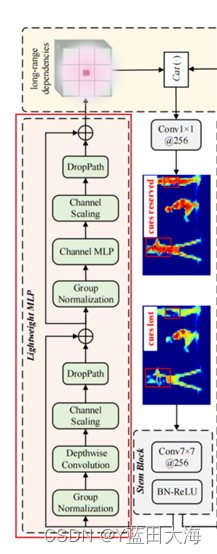
基于深度卷积的模块(下半部分):

基于 Channels MLP的模块(上半部分):

LCV
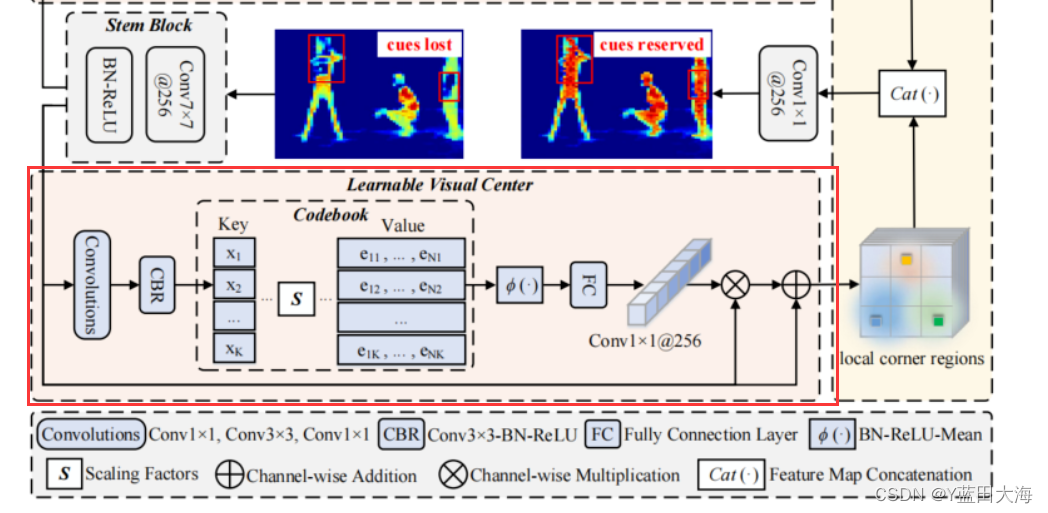
两个组件:

流程:
1.stem块的输出通过一组卷积层(由1×1卷积、3×3卷积和1×1卷积组成)的组合进行编码
2.编码特征由CBR块处理,CBR块由具有BN层的3×3卷积和ReLU激活函数组成。通过上述步骤,将处理后的编码的特征输入到Codebook中
3.Codebook
4.
4.提出的全局集中规则(GCR)
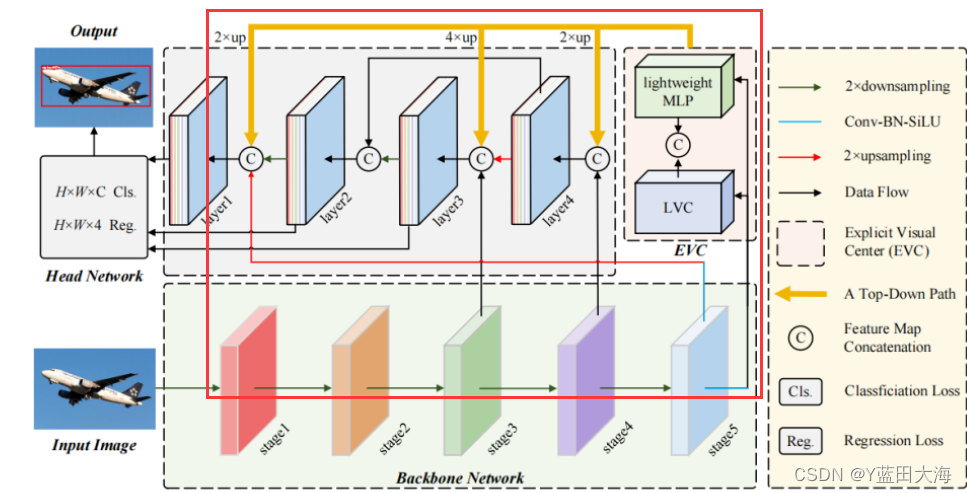
EVC(红框)是一种广义的层内特征调节方法,它不仅可以提取全局长距离相关性,而且可以尽可能地保留输入图像的局部角区域信息,这对于密集预测任务非常重要。然而,在特征金字塔的每个级别使用EVC将导致较大的计算开销。
为了提高层内特征调节的计算效率,作者进一步以自顶向下的方式提出了特征金字塔的GCR。具体而言,如图2所示,考虑到最深的特征通常包含浅层特征中缺乏的最抽象的特征表示,空间EVC首先在特征金字塔的顶层(即X4)上实现。然后,所获得的包括空间显式视觉中心的特征X被用于同时调节所有的正面浅特征(即X3,到X2)。
在实现中,在每个对应的低层特征上,将在深层中获得的特征上采样到与低层特征相同的空间尺度,然后沿着通道维度连接。基于此,通过1×1卷积将级联特征下采样为256的通道大小。通过这种方式能够在自上而下的路径中显式地增加特征金字塔的每一层的全局表示的空间权重,从而CFP可以有效地实现全方位但有区别的特征表示。
5.解耦head网络(由分类损失、回归损失和分割损失组成)
参考:















 4474
4474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









