








词法分析(lexical analysis):是计算机科学中将字符序列转换为Token序列的过程。

需要识别的东西:
1.keywords:if,else,while / char,int / goto / printf
2.identifiers(标识符):变量/函数,如int a,int add(int a,int b)
3.literals(字面量):如int a=3;那么3就是一个数字字面量;printf(“Hello world!”),"Hello world!"就是一个字符串字面量。
4.operators:如+ - × ÷ ( ){ } [ ]…包括一些我们不需要的实际没有意义的字符:stop words(停用词),如//注释,space 空格,tab缩进,\n换行,没有实际含义
另外在C minus中不支持宏,不支持include,所以#也是stop words,遇到了直接忽略。

词法解析的方法:tokenize方法
tokenize方法:输入是源码的字符,输出token和token_value(是通过修改全局变量实现的输出,不是真的return了这个值,另外tokenize方法本身的函数返回是void类型)
关于变量/函数需要单独处理的问题:
变量/函数的声明/定义是在实际使用之前,因此需要单独有一个table存储事先声明的变量/函数,当使用的时候必须在table中读出该变量/函数的属性然后才能使用它。这个table就是symbol table。
symbol table只有在变量/函数、遇到关键字的时候用到,其他情况(如:乘法)不用。
变量分为两类:一个是key word他得值存储的就是key word具体的值,如果是变量或者自定义的东西,就把token定义为id。
或者更优化建立哈希表单独用数值存储key word。

class:Num(Number,比如enum{A,B,C},这里的A,B,C就是number),Fun(函数),Sys(System Call,比如printf),Loc(局部变量),Glo(全局变量)
value是什么取决于class和type
符号表(Symbol table)除了上述的token、name、class、type、value属性外,还有Gclass、Gtype、Gvalue,单独的三个涉及到C语言的局部变量的遮蔽。
C语言的局部变量的遮蔽:
int a; //存储在Gclass、Gtype、Gvalue中
int func(){
int a; //存储在class、type、value
}
//func内外的两个a是的属性是不一样的,解析的过程中也是分开存储的
//当func函数运行结束之后,
//还要把原先a遮蔽的属性放在Gclass、Gtype、Gvalue中的,
//回写到class、type、value中,
//在func函数之外的a还是全局变量的a
//通过暂存Gclass、Gtype、Gvalue,能实现局部遮蔽的功能
tokenize代码阅读与如何实现与使用:
void tokenize() {
char* ch_ptr;
while((token = *src++)) { //token把源码中的字符取出,字符向后移动
if (token == '\n') line++; //如果是换行符,就把line++,在debug中使用的,没有实际含义,“第...行有语法错误”的line就是这样维护的
// skip marco
else if (token == '#') while (*src != 0 && *src != '\n') src++;
//遇到‘#’完全忽略,这里的处理可以把‘#’当成注释符号“//”使用
// handle symbol(处理符号)
else if ((token >= 'a' && token <= 'z') || (token >= 'A' && token <= 'Z') || (token == '_')) {
//符号由小写字母、大写字母、下划线开头
ch_ptr = src - 1;
while ((*src >= 'a' && *src <= 'z') || (*src >= 'A' && *src <= 'Z') || (*src >= '0' && *src <= '9') || (*src == '_'))
// use token store hash value 读出完整的identifier,并计算token的哈希值
token = token * 147 + *src++;
// keep hash
token = (token << 6) + (src - ch_ptr);
symbol_ptr = symbol_table;
// search same symbol in table看看当前的identifier是不是已经解析过了的
while(symbol_ptr[Token]) {
if (token == symbol_ptr[Hash] && !memcmp((char*)symbol_ptr[Name], ch_ptr, src - ch_ptr)) {
//一个一个的找,先比较哈希,再比较名字,如果找到了,那就直接返回找到的结果
//此外说明:在真正parse之前,会对所有keyword调用一边tokenize,
//也就是在执行parse方法时,所有的keyword都已经被存在了Symbol table中了
//所以如果遇到keyword一定能在Symbol table中找到,找到了就直接返回了
token = symbol_ptr[Token];
return;
}
symbol_ptr = symbol_ptr + SymSize;
}
// add new symbol
//如果identifier没有在当前的Symbol table中找到,那么就要新增一个符号
symbol_ptr[Name] = (int)ch_ptr; //新增符号的名字就是它的字符串
symbol_ptr[Hash] = token; //它的哈希就是刚刚算出来想映射但是没找到的哈希
token = symbol_ptr[Token] = Id; //它的token就是这个Id(就是单独的自定义的identifier的token类型)
//这时候还没有解析它的class,type,value,因为这时候还不知道他是啥
//比如int ans,我们这时候只读到了ans,并不知道ans是什么,具体ans是什么要放在语法分析才知道
return;
}
// handle number 处理数字
else if (token >= '0' && token <= '9') {
// 十进制的,DEC, ch_ptr with 1 - 9
if ((token_val = token - '0'))
while (*src >= '0' && *src <= '9') token_val = token_val * 10 + *src++ - '0';
//十六进制的,HEX, ch_ptr with 0x
else if (*src == 'x' || *src == 'X')
while ((token = *++src) && ((token >= '0' && token <= '9') || (token >= 'a' && token <= 'f')
|| (token >= 'A' && token <= 'F')))
// COOL!
token_val = token_val * 16 + (token & 0xF) + (token >= 'A' ? 9 : 0);
// 八进制的,OCT, start with 0
else while (*src >= '0' && *src <= '7') token_val = token_val * 8 + *src++ - '0';
token = Num;
return;
}
// handle string & char 处理字符串或者字符
//以 双引号" 或者 单引号' 开头
else if (token == '"' || token == '\'') {
ch_ptr = data;
while (*src != 0 && *src != token) {
if ((token_val = *src++) == '\\') {
// only support escape char '\n'
if ((token_val = *src++) == 'n') token_val = '\n';
}
// store string to data segment 把数值存到data区
if (token == '"') *data++ = token_val;
}
src++;
if (token == '"') token_val = (int)ch_ptr; //如果token就是双引号"的话,那么token_val就等于它的ASCII码
// single char is Num
else token = Num;
return;
}
// handle comments or divide 处理注释或者除号
else if (token == '/') {
if (*src == '/') {
// skip comments 跳过注释
while (*src != 0 && *src != '\n') src++;
} else {
// divide 除号
token = Div;
return;
}
}
// handle all kinds of operators, copy from c4.
else if (token == '=') {if (*src == '=') {src++; token = Eq;} else token = Assign; return;}
else if (token == '+') {if (*src == '+') {src++; token = Inc;} else token = Add; return;}
// ↑ 如果两个加号:token中是第一个加号,*src = '+'是第二个加号,那就是自增,token=Inc
//如果只有一个+,那就是加号token = Add
else if (token == '-') {if (*src == '-') {src++; token = Dec;} else token = Sub; return;}
else if (token == '!') {if (*src == '=') {src++; token = Ne;} return;}
else if (token == '<') {if (*src == '=') {src++; token = Le;} else if (*src == '<') {src++; token = Shl;} else token = Lt; return;}
else if (token == '>') {if (*src == '=') {src++; token = Ge;} else if (*src == '>') {src++; token = Shr;} else token = Gt; return;}
else if (token == '|') {if (*src == '|') {src++; token = Lor;} else token = Or; return;}
else if (token == '&') {if (*src == '&') {src++; token = Land;} else token = And; return;}
else if (token == '^') {token = Xor; return;}
else if (token == '%') {token = Mod; return;}
else if (token == '*') {token = Mul; return;}
else if (token == '[') {token = Brak; return;}
else if (token == '?') {token = Cond; return;}
else if (token == '~' || token == ';' || token == '{' || token == '}' || token == '(' || token == ')' || token == ']' || token == ',' || token == ':') return;
}
}
----------------------------------------------------------------------------------------------------------------
举个例子:
symbol table中一开始存储了char,int,return的token
keyword关键字的name就是对应的字符。

上面的过程:
开始解析前的symbol table:
| token | name | class | type | value | Gclass | Gtype | Gvalue |
|---|---|---|---|---|---|---|---|
| char | “char” | - | - | - | - | - | - |
| int | “int” | - | - | - | - | - | - |
| return | “return” | - | - | - | - | - | - |
解析的过程执行后得到的symbol table(刚刚执行完char* a;时):
| token | name | class | type | value | Gclass | Gtype | Gvalue |
|---|---|---|---|---|---|---|---|
| char | “char” | - | - | - | - | - | - |
| int | “int” | - | - | - | - | - | - |
| return | “return” | - | - | - | - | - | - |
| Id | “a” | GLOC | PTR | 0 |
解析的过程执行后得到的symbol table(在add函数中的状态,此时外边有个指针类型a的全局变量,里面有个int类型a的局部变量):
| token | name | class | type | value | Gclass | Gtype | Gvalue |
|---|---|---|---|---|---|---|---|
| char | “char” | - | - | - | - | - | - |
| int | “int” | - | - | - | - | - | - |
| return | “return” | - | - | - | - | - | - |
| Id | “a” | LOC | INT | 0 | GLOC | PTR | 0 |
| Id | “add” | FUNC | INT | PC | |||
| Id | “b” | LOC | INT | 0 | |||
| Id | “ret” | LOC | INT | 0 |
"add"的地址就是目前生成代码的地址PC
上面的symbol table中:
token、name是通过词法分析得到的。
class、type 、value、Gclass、Gtype、Gvalue是通过语法分析得到的 。
注意:
1.解析的过程中符号 ; 等不会进symbol table,
2.但是运算符号 * 等等是自己有token的,会存在symbol table中。
3.注意正式解析函数之前,symbol table里面除了if/else/while/运算符/printf等的函数,还会预先存储main的函数和地址,因为那是程序的入口函数。通过symbol table 中main函数的value值记录的main的位置才能找到代码开始解析。
4.其他main函数之外的函数名都是在函数定义阶段写入的symbol table,就比如说(下面的代码)add函数等到token扫到他那里的时候,把它放进symbol table,并记录token为Id,name为add,然后把它解析到这里对应的code位置放进value。函数定义的时候关键是要存储函数的初始地址(也就是symbol table中对应的value的值)。剩下时候代码解析过程中遇到该函数的时候,就直接 call+函数地址 就行。
5.对于全局变量symbol table中记录的是data中该数据存储的对应位置,读该数据的时候直接IMM+data中的地址,就会把该全局变量的数据加载到C Minus唯一的通用寄存器ax中。
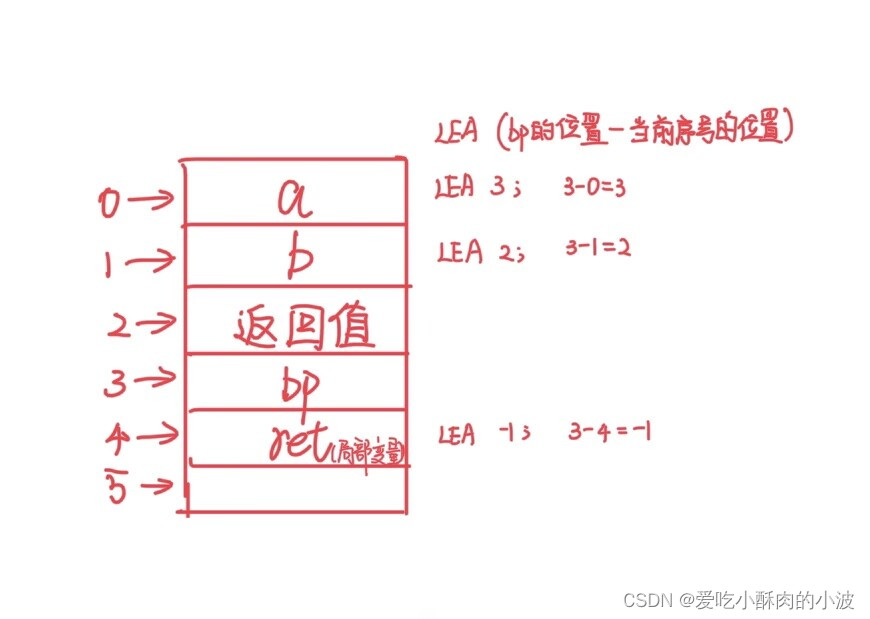
6.对于局部变量symbol table中记录的是该数据相对于函数栈底bp的位置的序号,就比如说(下面的代码)add函数中对应的局部变量ret用LEA -1调用,实际使用的时候LEA bp-序号,如下图所示原因:(图在代码的下面)。
//此代码对应“注意”的第4/6条
#include <stdio.h>
int add(int a, int b){
int ret;
ret = a + b;
return ret;
}
void cal(int a,int b){
int c;
int d;
int e;
}
int main(){
printf("%d + %d = %d\n", 1, 2, add(1, 2));
return 0;
}

















 3051
3051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











