






前言
当我们利用深度学习训练出我们的模型之后,下一步会做什么呢?无疑是去测试我们的模型,精度达到标准既可发布上线,那发布之后我们会发现的问题是->推理时间慢,那我们该怎么做呢?以下几个思路可供借鉴,这里以yolov5为例:
- 更改网络为轻量级,如YOLOv5s、YOLOv5n
- 通过技术手段进行模型加速,如tensorrt,openvino等
- 资金雄厚的情况下,可以考虑使用更高算力的卡
- 模型压缩
接下来,就给大家介绍下发现的一个用于模型压缩的工具–>PaddleSlim
一、环境搭建
该说不说,paddle的环境还是比较难搞的,感觉兼容性做的不是很好,为了让大家避开我踩过的坑,这里我建议直接去官网下最新的版本,但是一定要看你你安装的是GPU还是CPU,命令如下:
pip install paddlepaddle-gpu -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install paddleslim -i https://pypi.tuna.tsinghua.edu.cn/simple
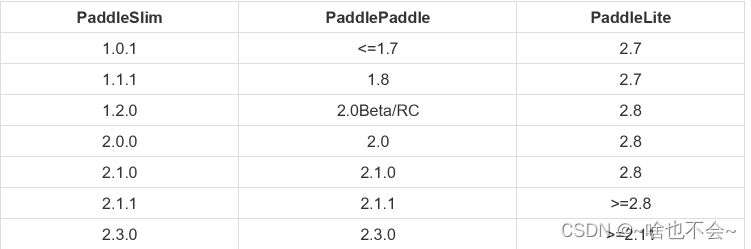
版本对照表如下,仅供参考:
最省事的还是docker安装paddle,会直接避开很多坑
安装完成后,验证是否安装成功:
- 验证paddl
import paddle
paddle.utils.run_check()
若出现
则证明安装成功
- 验证paddleslim
import paddleslim
一般情况下,导入没问题的话,基本就没有问题
二、代码拉取
拉取paddleslim的源码,链接如下:PaddleSlim
三、数据集准备
- 数据格式的话大体采用COCO格式,如下:

当然,如果我们也可以使用自己的数据集,但前提是数据摆放要和上边一致,然后修改paddleslim/example/auto_compression/pytorch_yolo_series/configs/yolov5s_qat_dis.yaml里的数据集路径即可,如:
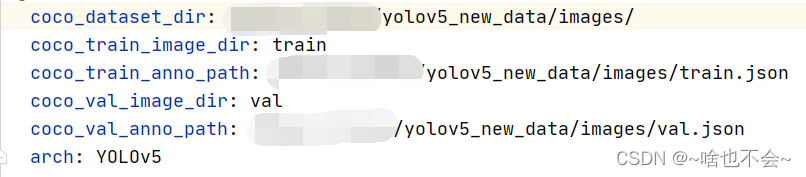
-无标注图片,直接传入脱氨文件夹,不支持评估模型MAP(官方文档中所说)
如果我们懒的去改数据格式或者去标注新数据,那就直接在yolov5s_qat_dis.yaml里修改image_path参数,如:

这里设置了之后就不用去管下边那个coco路径的设置了
四、模型准备
这里我们需要提前准备好要转换的pt模型,并提前转换为onnx或paddle的格式。需要注意的是:如果你项目的推理框架打算用paddle的话,那两种方案都可以,如果不打算用paddle的话,建议用onnx,压缩时会自动进行模型转换。我的推理框架用的是paddle,所以我就直接使用了提前住哪换好的paddle格式的模型。
- 转换onnx的话,可以在YOLOv5中利用exoport.py脚本进行住哪换,如:
python export.py --weights yolov5s.pt --include onnx
- 转换为paddle格式的话,可以参考我的另一篇博客:onnx2paddle,然后子啊yolov5s_qat_dis.yaml中指定模型路径,如下:

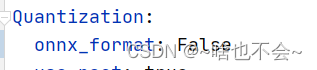
其次,由于我们不在需要onnx2paddle或者paddle2onnx这个过程,所以需要将onnx_format改为False,如下:
五、开始压缩
命令如下,这里只展示单卡训练的:
cd example/auto_compression/pytorch_yolo_series
CUDA_VISIBLE_DEVICES=0 python run.py --config_path=./configs/yolov5s_qat_dis.yaml --save_dir="./output"
详细训练参考链接如下:训练
六、结果对比
1、体积对比:
压缩前:
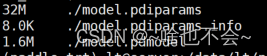
压缩后:

这里模型参数没减少的原因可以参考这个链接这里
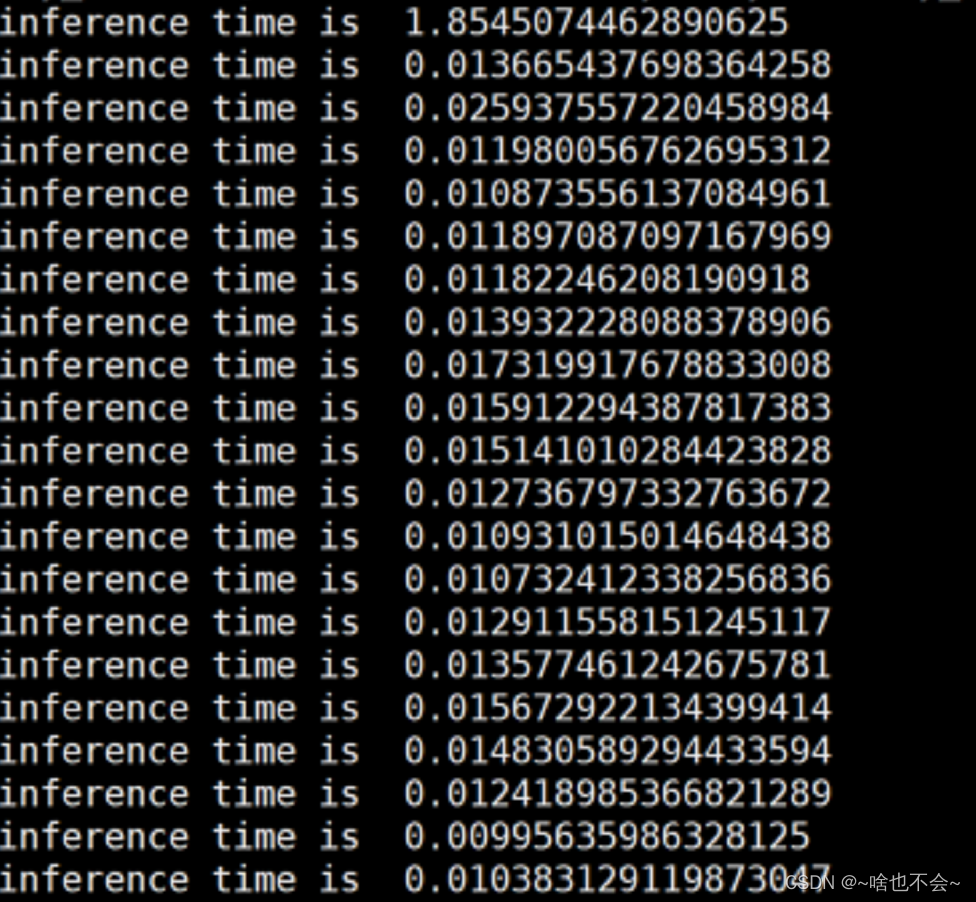
2、推理速度(3080Ti下未开trt)
压缩前:
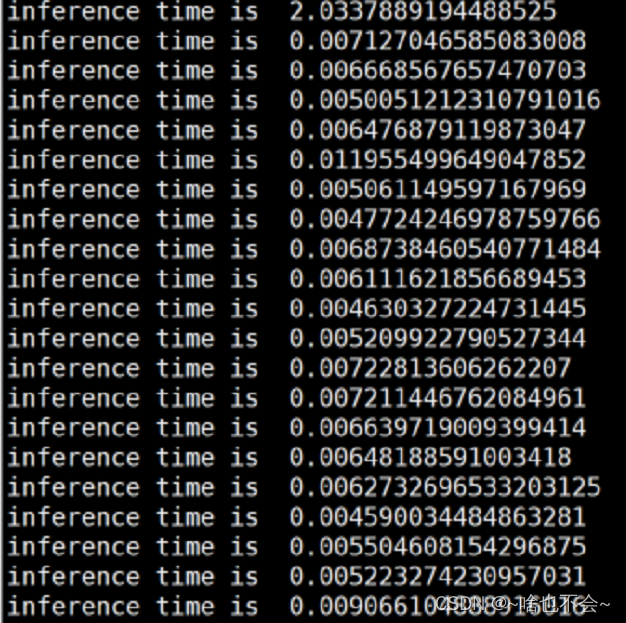
压缩后:
七、错误解决
在整个过程中,可能会遇到如下错误:

原因可能就是版本问题,这个问题折磨我好久,所以一定要注意版本。参考的解决连接如下:bug解决
验证这个问题是否解决最快的方式就是直接import paddleslim,如果没出这个错就说明解决了
总结
以上就是本篇的全部内容,欢迎大家指正问题。















 1228
1228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









