






 本文详细介绍了运用CNN-LSTM神经网络模型预测瓦斯浓度的步骤,包括数据集获取、预处理、时间序列处理、数据集划分、模型构建与训练等。通过结合多站点多传感器数据,提取空间和时序特征,调整模型参数防止过拟合,最终实现对瓦斯浓度的准确预测,并使用评估指标判断模型优势。
本文详细介绍了运用CNN-LSTM神经网络模型预测瓦斯浓度的步骤,包括数据集获取、预处理、时间序列处理、数据集划分、模型构建与训练等。通过结合多站点多传感器数据,提取空间和时序特征,调整模型参数防止过拟合,最终实现对瓦斯浓度的准确预测,并使用评估指标判断模型优势。
前言
本文详细展示CNN-LSTM神经网络模型的运用,具体步骤如下:数据集获取、数据预处理、时间序列处理、数据集划分、CNN-LSTM模型的构建和训练以及瓦斯浓度的预测。
通过构建CNN-LSTM神经网络模型,结合多站点多传感器数据,提取数据特征的空间关系以及进行时序处理,从而对瓦斯浓度做出预测。在数据清洗过程中,对原数据使用pandas技术进行处理,提取所需列存入新的文件,去除异常值的同时也保留了所需要的含有时间序列和空间序列的数据,再对含有时间序列和空间序列的数据进行处理以及设置瓦斯浓度为标签数据,然后对数据进行了分类,包括训练集,验证集以及测试集。在网络模型中先运用CNN卷积神经网络对特征之间所存在的空间关系进行提取,然后在卷积神经网络后通过添加LSTM长短时记忆模型来对时间序列进行处理,并且使用全连接层学习输入特征与输出存在的非线性关系。在CNN-LSTM神经网络模型中不断对参数进行调整,防止出现过拟合现象,以此提高预测的精度,从而能够更准确地对瓦斯浓度进行预测
一、数据集获取
选择MM264瓦斯浓度数据作为REAL值。
经过清洗后的数据集信息如下表1所示:
表1所需要的数据集(前五行)
| 序号 | year | month | day | hour | minute |
| 1 | 2014 | 3 | 2 | 0 | 0 |
| 2 | 2014 | 3 | 2 | 0 | 25 |
| 3 | 2014 | 3 | 2 | 0 | 50 |
| 4 | 2014 | 3 | 2 | 1 | 15 |
| 5 | 2014 | 3 | 2 | 1 | 40 |
| second | TP1711 | RH1712 | BA1713 | REAL | |
| 0 | 27.3 | 54 | 1096.7 | 0.1 | |
| 0 | 27.2 | 55 | 1097.4 | 0.2 | |
| 0 | 27.2 | 54 | 1097.8 | 0.1 | |
| 0 | 27.2 | 54 | 1097 | 0.2 | |
| 0 | 27.2 | 54 | 1097.5 | 0.1 |
经过清洗后的数据集包含年份、月份、日期、时分秒、温度、湿度、气压以及设置为真实值REAL的瓦斯浓度数据MM264。
1.深度学习依赖展示:
import numpy as np
import pandas as pd
import tensorflow as tf
import datetime
import csv
import matplotlib.pyplot as plt
from tensorflow import keras
from tensorflow.keras import layers
from sklearn.preprocessing import StandardScaler
from collections import deque
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
2.获取所需数据集代码
前五行:
# 数据库获取
filepath = r'C:\Users\hmzjb\PycharmProjects\pythonProject7\CNN-LSTM\processData\try111.csv'
dataset = pd.read_csv(filepath)
print(dataset.head()) # 查看前五行数据
前五行数据如图1所示
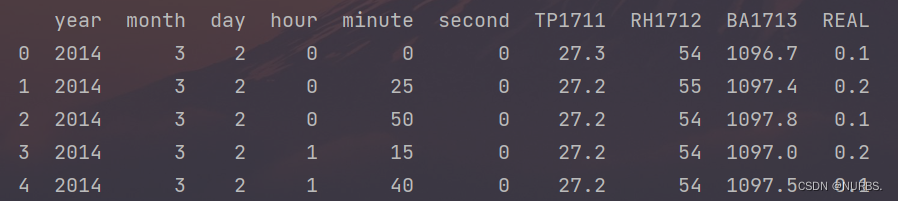
图1 前五行数据展示
对瓦数浓度数据(REAL)、温度、湿度,气压等数据进行可视化处理,设置一张含有四个板块的画布,分别将数据以图表的形式展示出来。
3.特征可视化具体代码及参数
如下:
# 指定绘图风格
plt.style.use('fivethirtyeight')
#设置画布,2行2列的画图窗口,第一行画x1和x2,第二行画x3和x4
fig, ((x1, x2), (x3, x4)) = plt.subplots(2, 2, figsize=(20, 10))
# REAL列
x1.plot(dataset['REAL'],color='red')
# 设置x轴y轴标签和title标题
x1.set_xlabel('');x1.set_ylabel('GAS');x1.set_title('REAL')
# TP1711温度列
x2.plot(dataset['TP1711'],color='blue')
# 设置x轴y轴标签和title标题
x2.set_xlabel('');x2.set_ylabel('Temperature');x2.set_title('TP1711')
# RH1712湿度列
x3.plot(dataset['RH1712'],color='purple')
# 设置x轴y轴标签和title标题
x3.set_xlabel('');x3.set_ylabel('Humidity');x3.set_title('RH1712')
# BA1713气压列
x4.plot(dataset['BA1713'],color='pink')
# 设置x轴y轴标签和title标题
x4.set_xlabel('');x4.set_ylabel('Pressure');x4.set_title('BA1713')
# 轻量化布局调整绘图
fig.patch.set_facecolor('xkcd:mint green')
plt.tight_layout(pad=2)
plt.show()
所绘制的图表如下图2所示:
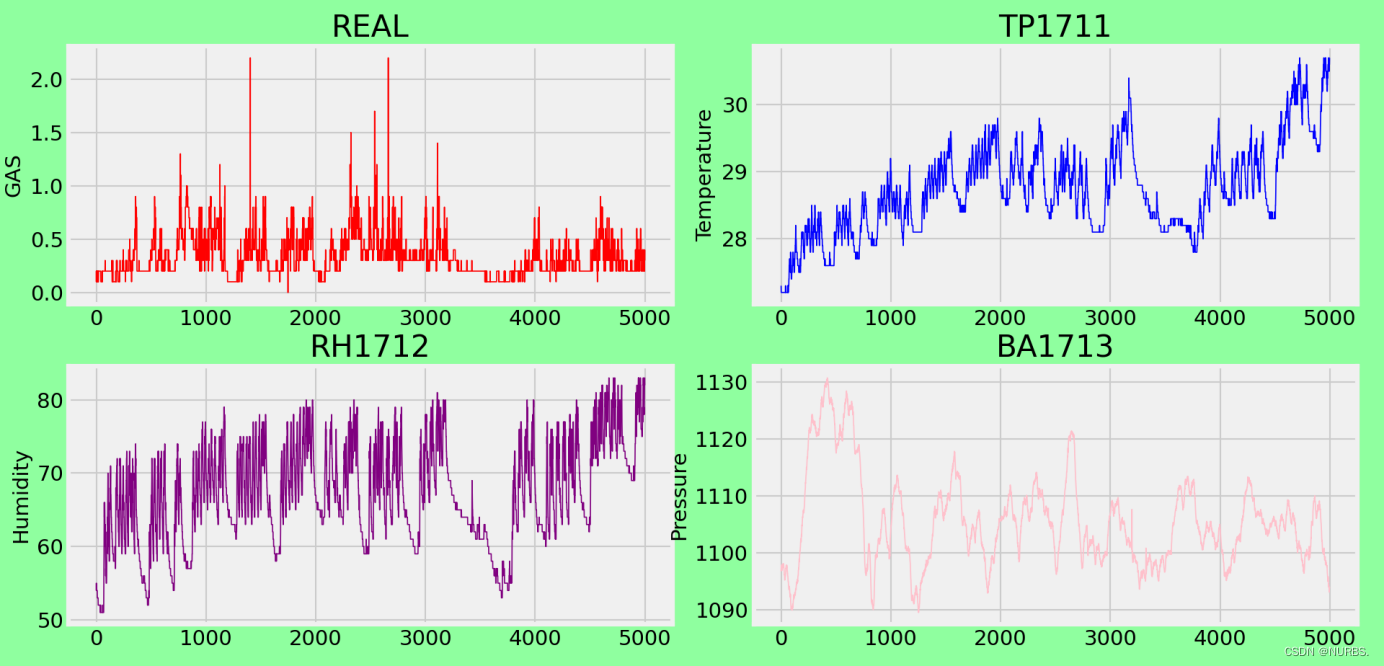
图2 数据可视化图表
二、数据预处理
分析数据集如图1所示,数据前六列为时间数据,后续进行特征选择的时候不需要时间,即可先对时间数据进行处理,将时间数据由字符串变为datatime的类型。
1.时间序列数据处理过程的具体操作
如下:
# 将数据中的时间数据组合并转换成datetime数据
# 提取数据中的时间信息
years = dataset['year']
months = dataset['month']
days = dataset['day']
hours = dataset['hour']
minutes = dataset['minute']
seconds = dataset['second']
dates = [] # 存放组合后的时间信息
# 遍历一一对应的年月日信息
for year, month, day,hour,minute,second in zip(years, months, days,hours,minutes,seconds):
# 时间数据之间使用字符串拼接在一起
date = str(year) + '-' + str(month) + '-' + str(day) +'-'+ str(hour) +'-'+ str(minute) +'-'+ str(second)
# 将每个时间(字符串类型)保存
dates.append(date)
#字符串类型的时间转为datetime类型的时间
times = []
# 遍历所有的字符串类型的时间
for date in dates:
# 转为datetime类型
time = datetime.datetime.strptime(date, '%Y-%m-%d-%H-%M-%S')
# 逐一保存转变类型后的时间数据
times.append(time)
# 查看转换后的时间数据
print(times[:3])
转换成datatime类型后的时间数据如下图3所示:

图3 转换成datatime类型后的时间数据
2.特征数据预处理代码
如下:
#特征数据预处理
# 从第7列开始选择特征
feats = dataset.iloc[:, 6:]
# 增加四项特征列
print(feats.shape) # (5000,4)
#选择特征数据中的真实气体数据'REAL'在最后一秒的气体浓度数据作为标签数据
pre_seconds =1
targets = feats['REAL'].shift(-pre_seconds)
# 查看标签信息
print(targets.shape) # (5000,)
# 由于特征值最后一行对应的标签是空值nan,将最后一行特征及标签删除
feats = feats[:-pre_seconds]
targets = targets[:-pre_seconds]
print('feats.shape:', feats.shape, 'targets.shape:', targets.shape) # (4999,4) (4999,)
# 特征数据标准化处理
# 接收标准化方法
scaler = StandardScaler()
# 对特征数据中所有的数值类型的数据进行标准化
feats.iloc[:, :] = scaler.fit_transform(feats.iloc[:, :])
# 展示标准化后的信息
print(feats)
前六列属于时间数据,从第七列开始选取数据列作为特征,共选取了四列。将REAL列的真实数据选最后连续一秒的浓度数据信息作为标签,即当最后一行数据被选择为标签后,这行数据对应的标签就为空值,需要将其删除掉。当选定特征和设置好标签后,为了减少误差提升训练速度和后续建立模型,需要对数据进行标准化处理。
特征列选取、标签信息、删除空值后的信息如下图4所示:

图4 特征列选取、标签信息、删除空值后的信息
标准化后的数据如下图5所示:
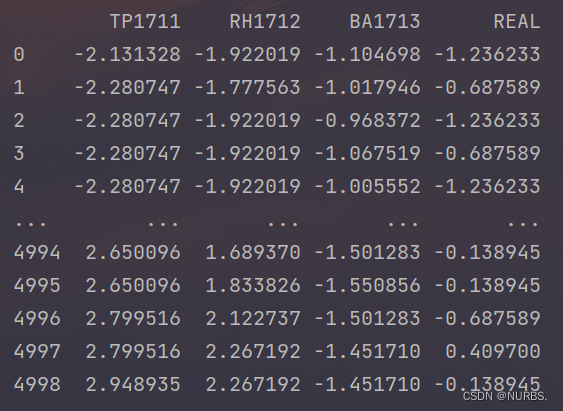
图5 标准化后的数据
三、时间序列处理
代码如下:
# 将特征数据从df类型转为numpy类型
feats = np.array(feats)
# 定义时间序列窗口是连续14秒的特征数据
max_series_seconds = 14
# 建立队列,队列的最大长度固定为14
deq = deque(maxlen=max_series_seconds) # 如果长度超出了14,先从队列头部开始删除
# 创建一个列表,保存处理后的特征序列
x = []
# 遍历每一行数据,包含4项特征
for i in feats:
# 将每一行数据存入队列中, numpy类型转为list类型
deq.append(list(i))
# 如果队列长度等于指定的序列长度,就保存这个序列
# 如果队列长度大于序列长度,队列会自动删除头端元素,在尾端追加新元素
if len(deq) == max_series_seconds:
# 保存每一组时间序列, 队列类型转为list类型
x.append(list(deq))
# 保存与特征对应的标签值
y = targets[max_series_seconds - 1:].values
# 保证序列长度和标签长度相同
print(len(x)) # 4983
print(len(y)) # 4983
# 将list类型转为numpy类型
x, y = np.array(x), np.array(y)
创建一个先进先出队列,长度为14,也就是说,时序的长度是14。若队列的长度大于14,那么队列会自动将头部的元素删除,将新元素追加到队列的尾部,组成一个新的序列[10]。
创建好队列后对每一行数据进行遍历,将每一行的数据存入队列中,在此过程中数据类型先由df类型转变为numpy类型,在保存序列时由numpy类型转为list类型,当完成序列的保存与特征对应的标签值后,数据由list类型再转变为numpy类型。
设置好的时间序列长度与标签长度需保持一致,代码运行结果表示两个长度均为4983。
四、数据集划分
数据集划分代码如下:
#数据集划分
total_num = len(x) # 序列总量
train_num = int(total_num*0.8) # 训练集占比
val_num = int(total_num*0.9) # 验证集占比
# 测试数据
x_train, y_train = x[:train_num], y[:train_num] # 训练集
x_val, y_val = x[train_num: val_num], y[train_num: val_num] # 验证集
x_test, y_test = x[val_num:], y[val_num:] # 测试集
# 构造数据集
batch_size =128 #每个批次包含信息
# 训练集
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_ds = train_ds.batch(batch_size).shuffle(10000)
# 验证集
val_ds = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_ds = val_ds.batch(batch_size)
# 测试集
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_ds = test_ds.batch(batch_size)
# 打印数据集信息
sample = next(iter(train_ds)) # 取出一个batch的数据
print('x_train.shape:', sample[0].shape) # (128, 14, 4)
print('y_train.shape:', sample[1].shape) # (128,)
对数据集进行划分。训练集的占比为前80%,验证集占比为80%—90%的数据区间,剩余的数据作为测试集。
构建batch_size=128使得可以一次迭代处理128个序列。对于训练集来说:使用TensorFlow构建数据集的代码,将训练数据集x_train和标签y_train转换成一个数据集对象train_ds,并将每个批次的大小设置为 batch_size,同时对数据集进行随机打乱。验证集与测试集做同样处理,但是不需要随机打乱。
最后创建iter迭代器结合next函数提取一个批次的数据集,结果如下图6所示:

图6 一个批次的数据集
自此数据集打包完成,可以进行网络训练模型的搭建。
五、构建CNN-LSTM网络
思路分析:使用CNN卷积神经网络在模型前部分提取特征之间的空间关系。对于瓦斯浓度数据来说,具有明显的时间依赖性,所以在卷积神经网络后添加LSTM长短时记忆模型来对时序进行处理。
构建模型时批次的维度不需要展示设为None,保证输入层与训练数据集的shape一致,即输入层的shape为[None,14,4],再通过reshape对维度进行调整为[None,14,4,1]这样就可以后续进行二维卷积操作。对卷积层设置参数滤波器的数量、卷积核kernel的大小和正则化,同时设置Padding=same来对输入进行0值填充。使用BN层对批次进行标准化可以加快模型的训练速度,缓解梯度的消失并服从正态分布。批标准化后添加RELU激励层,使求梯度变得更简单,提升收敛速度,再用池化进一步放大特性信息,此时卷积网络完成后提取到了特征之间的空间关系。卷积完成后,对卷积通道进行1*1调整。模型如图7所示:
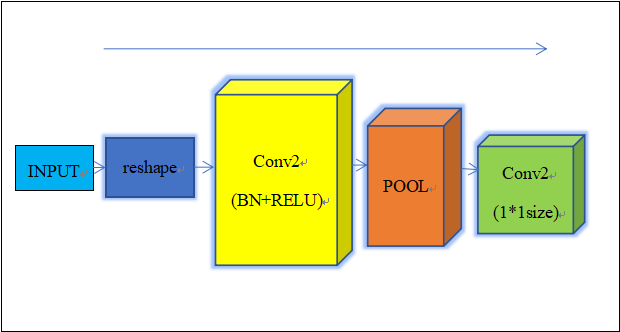
图7 卷积过程流程图
卷积过程结束后,先通过squeeze层挤掉最后一个维度,使得shape由四维变成三维后就可以运用LSTM(其中第一层处理输入序列并返回每一个时间步骤的输出序列,第二层处理第一层的输出序列并返回整个序列的单个输出)来处理数据的时间序列信息。然后添加一个包含64个神经元的Dense层对输入数据进行非线性变换并学习输入特征与输出存在的非线性关系,在最后,使用全连接层作为输出层,如图8所示:
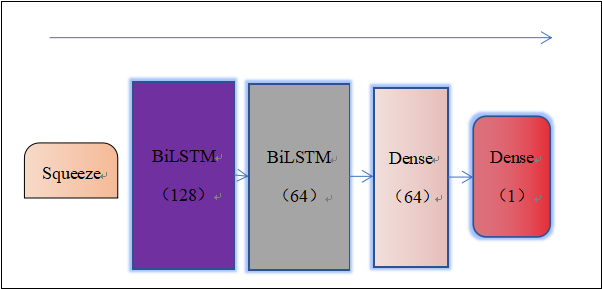
图8 时序处理兼输出示意图
在CNN-LSTM模型中,CNN提取特征的空间关系时,数据的维度为四维状态,但是在利用LSTM进行时序处理时,所需要的数据维度则是需要三维。所以在两个模型的中间需要对数据的维度进行转换,在卷积过程后先利用池化层放大特征信息,然后运用1*1卷积层和Squeeze层进行降维处理,最后将降维处理后的数据进行时序处理,从而实现对提取了空间关系的数据进行时序的处理。卷积过程到时序处理过程示意图如下图9所示:
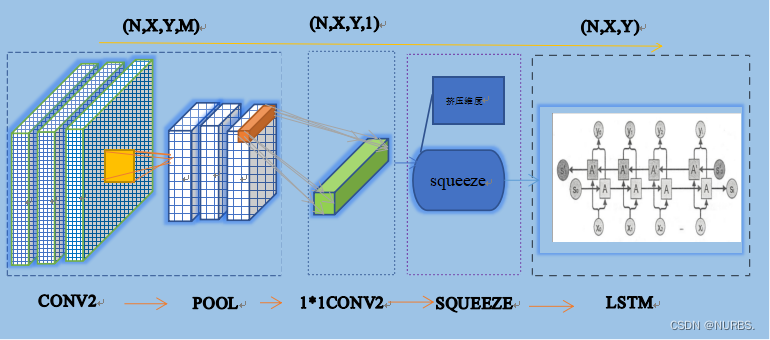
图9 卷积过程到时序处理过程示意图
通过对卷积过程到时序处理的分析和对数据集的处理,可以构建出整个网络模型的结构示意图以及每一层中数据的变化状态。具体结构示意图如图10所示:
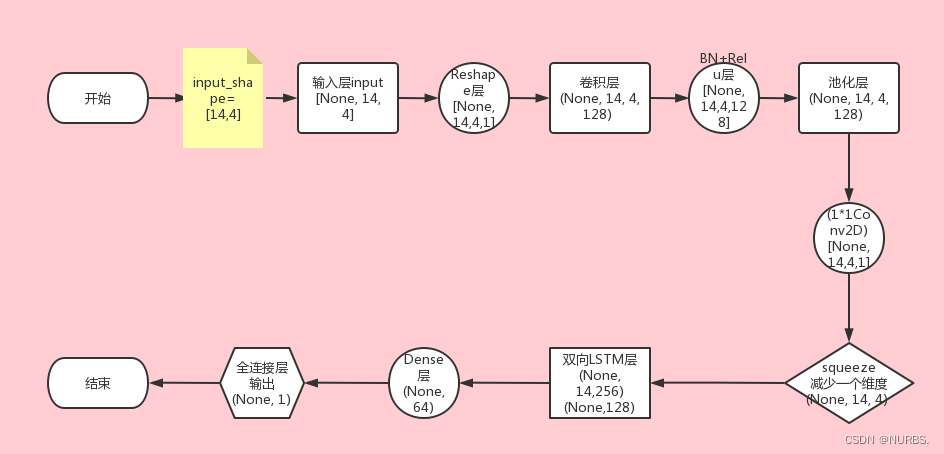
图10 网络模型结构示意图
CNN-LSTM网络模型结构代码如下所示:
#构建CNN-LSTM网络模型
# 输入层要和x_train的shape一致,但注意不要batch维度
input_shape = sample[0].shape[1:] # [14,4]
# 构造输入层
inputs = keras.Input(shape=input_shape) # [None, 14, 4]
# 调整维度 [None,14,4]==>[None,14,4,1]
x = layers.Reshape(target_shape=(inputs.shape[1], inputs.shape[2], 1))(inputs)
# 卷积+BN+Relu [None,14,4,1]==>[None,14,4,128]
x = layers.Conv2D(128, kernel_size=(3,3), strides=1, padding='same', use_bias=False,
kernel_regularizer=keras.regularizers.l2(0.01))(x)
x = layers.BatchNormalization()(x) # 批标准化
x = layers.Activation('relu')(x) # relu激活函数
# 池化下采样 [None,14,4,128]==>[None,14,4,128]
x = layers.MaxPool2D(pool_size=2, strides=1, padding="same")(x)
# 1*1卷积调整通道数 [None,14,4,128]==>[None,14,4,1]
x = layers.Conv2D(1, kernel_size=(3,3), strides=1, padding='same', use_bias=False,
kernel_regularizer=keras.regularizers.l2(0.01))(x)
# 把最后一个维度挤压掉 [None,14,4,1]==>[None,14,4]
x = tf.squeeze(x, axis=-1)
# [None,14,4] ==> [None,14,256] ==> [None,128],双向LSTM层
# 第一个LSTM层, 如果下一层还是LSTM层就需要return_sequences=True, 否则就是False
x = layers.Bidirectional(layers.LSTM(128, activation='relu',return_sequences=True,
kernel_regularizer=keras.regularizers.l2(0.01)))(x)
# 添加第二个LSTM层
x = layers.Bidirectional(layers.LSTM(64, activation='relu',return_sequences=False,
kernel_regularizer=keras.regularizers.l2(0.01)))(x)
# 添加全连接层
x = layers.Dense(64, activation='relu')(x)
# 添加输出层
outputs = layers.Dense(1, activation='sigmoid')(x)
# 构建模型
model = keras.Model(inputs=inputs, outputs=outputs, name='cnn_lstm_model')
model.summary()
最终构建网络模型如下表2所示:
表2 CNN-LSTM网络模型
| Layer (type) | Output Shape | Param # |
| input_1 (InputLayer) | [(None, 14, 4)] | 0 |
| reshape (Reshape) | (None, 14, 4, 1) | 0 |
| conv2d (Conv2D) | (None, 14, 4, 128) | 1152 |
| batch_normalization(BatchNormalization) | (None, 14, 4, 128) | 512 |
| activation (Activation) | (None, 14, 4, 128) | 0 |
| max_pooling2d(MaxPooling2D) | (None, 14, 4, 128) | 0 |
| conv2d_1 (Conv2D) | (None, 14, 4, 1) | 1152 |
| tf.compat.v1.squeeze(TFOpLambda) | (None, 14, 4) | 0 |
| bidirectional (Bidirectional) | (None, 14, 256) | 136192 |
| bidirectional_1(Bidirectional) | (None, 128) | 164352 |
| dense (Dense) | (None, 64) | 8256 |
| dense_1 (Dense) | (None, 1) | 65 |
自此CNN-LSTM网络模型创建成功。
六、模型训练
对CNN-LSTM网络模型进行训练,代码如下:
# 编译模型
model.compile(optimizer=keras.optimizers.Adam(0.001), # adam优化器学习率0.001
loss=tf.keras.losses.MeanAbsoluteError(), # 标签和预测之间绝对差异的平均值
metrics=tf.keras.losses.MeanSquaredLogarithmicError()) # 计算标签和预测之间的对数误差均方值。
epochs = 200 # 迭代200次
# 网络训练, history保存训练时的信息
history = model.fit(train_ds, epochs=epochs, validation_data=val_ds)
history_dict = history.history # 获取训练的数据字典
train_loss = history_dict['loss'] # 训练集损失
val_loss = history_dict['val_loss'] # 验证集损失
train_msle = history_dict['mean_squared_logarithmic_error'] # 训练集的百分比误差
val_msle = history_dict['val_mean_squared_logarithmic_error'] # 验证集的百分比误差
# 绘制训练损失和验证损失
plt.figure()
plt.plot(range(epochs), train_loss, label='train_loss') # 训练集损失
plt.plot(range(epochs), val_loss, label='val_loss') # 验证集损失
plt.legend() # 显示标签
plt.xlabel('epochs')
plt.ylabel('loss')
plt.show()
# 绘制训练百分比误差和验证百分比误差
plt.figure()
plt.plot(range(epochs), train_msle, label='train_msle',markersize=12) # 训练集指标
plt.plot(range(epochs), val_msle, label='val_msle',markersize=12) # 验证集指标
plt.legend() # 显示标签
plt.xlabel('epochs')
plt.ylabel('msle')
plt.show()
使用Adam优化器使梯度快速下降,提升训练速度,同时在训练过程中history会去记录每一次迭代过程中所包含的损失信息和指标信息,并通过进行可视化的展示来判断模型是否过拟合。并且,在训练期间,将使用回归计算出的预测值与真实值之间的绝对误差的平均值作为损失函数,然后再用预测值和真实值之间的对数均方误差当作是训练过程中的监控指标。
模型训练过程如下图11所示:
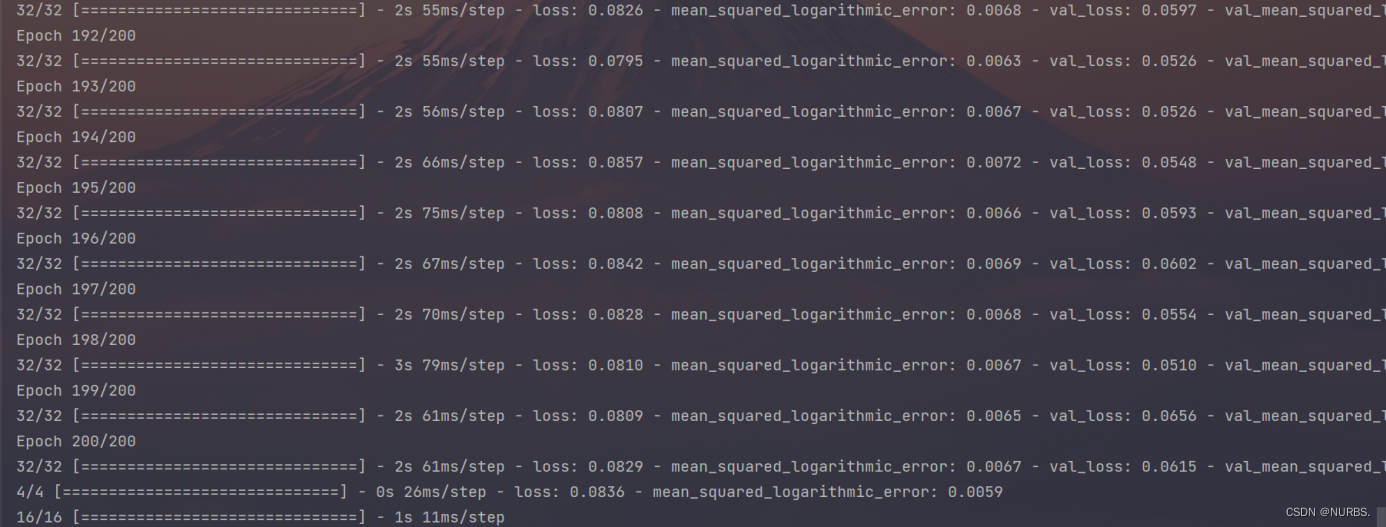
图11 模型训练过程图像
其中在迭代过程的损失信息和指标信息如图12、图13所示:
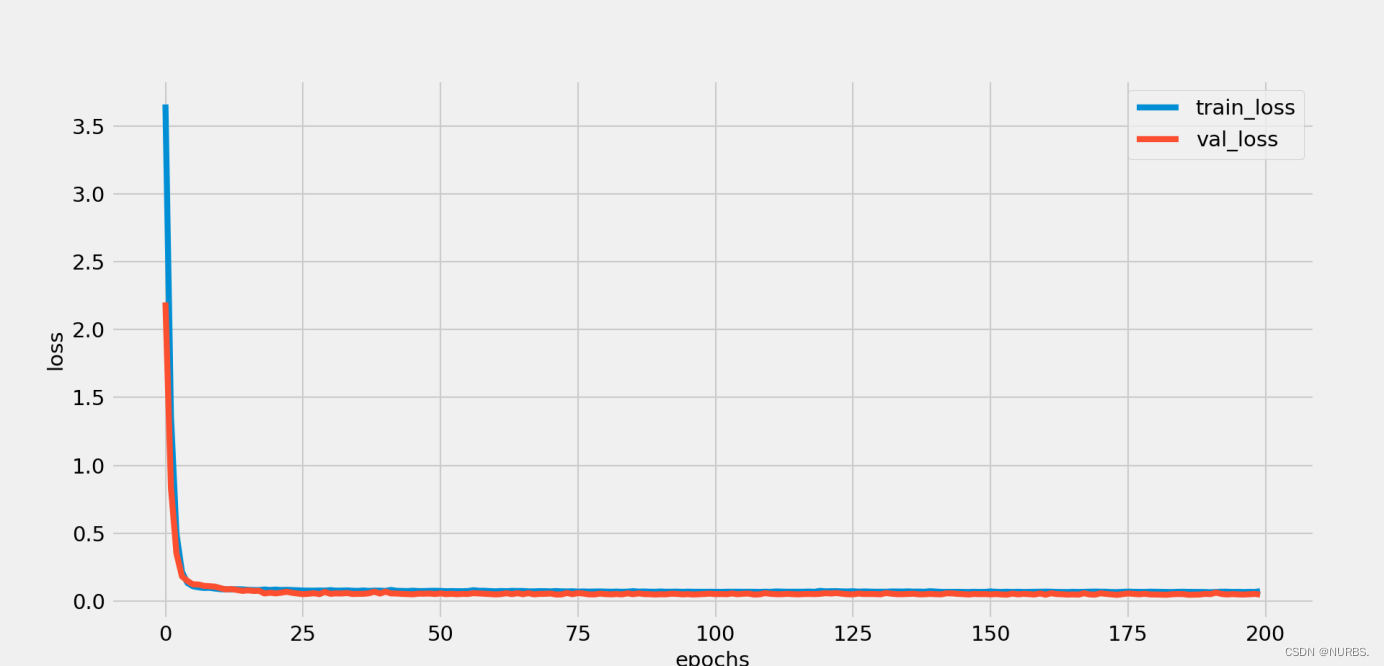
图12 损失信息图表
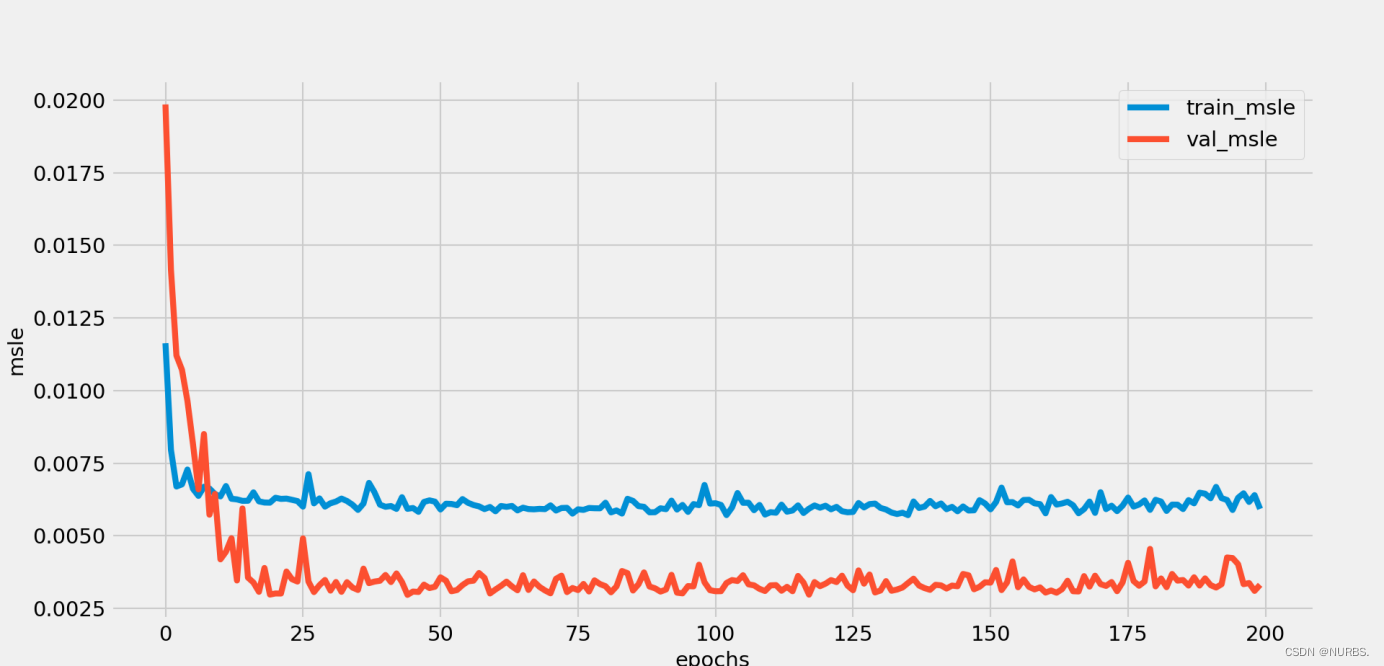
图13 指标信息图表
通过对loss的可视化图表观察,训练集和验证集的loss和msle都在逐渐下降,无过拟合现象,网络训练正常。
七、瓦斯浓度预测
瓦斯浓度预测代码:
# 对整个测试集评估
model.evaluate(train_ds)
# 预测阶段
y_pred = model.predict(x_train)
# 获取标签值对应的时间
df_time = times[-len(y_train):]
# 绘制对比曲线
fig = plt.figure(figsize=(15,10)) # 画板尺寸
ax = fig.add_subplot(111) # 画板上添加一张图
# 绘制真实值曲线
ax.plot(df_time, y_train, label='REAL',markersize=1,color="royalblue")
# 绘制预测值曲线
ax.plot(df_time, y_pred, label='predict',markersize=1,color='orange')
# 设置x轴刻度
ax.set_xticks(df_time[::1])
# 设置xy轴标签和title标题
ax.set_xlabel('Date')
ax.set_ylabel('CNN-LSTM-Prediction of gas concentration ');ax.set_title('result')
# 设置y轴上下限
ax.set_ylim(0, 2)
plt.tick_params(labelsize=15)
plt.legend(fontsize=20)
plt.grid(False)
plt.show()
使用model.evaluate来作为测试集的监控指标,并对测试集进行损失计算。之后,根据测试集的特征计算瓦斯浓度,再将预测值与真实值的图表绘制出来,如图14所示:
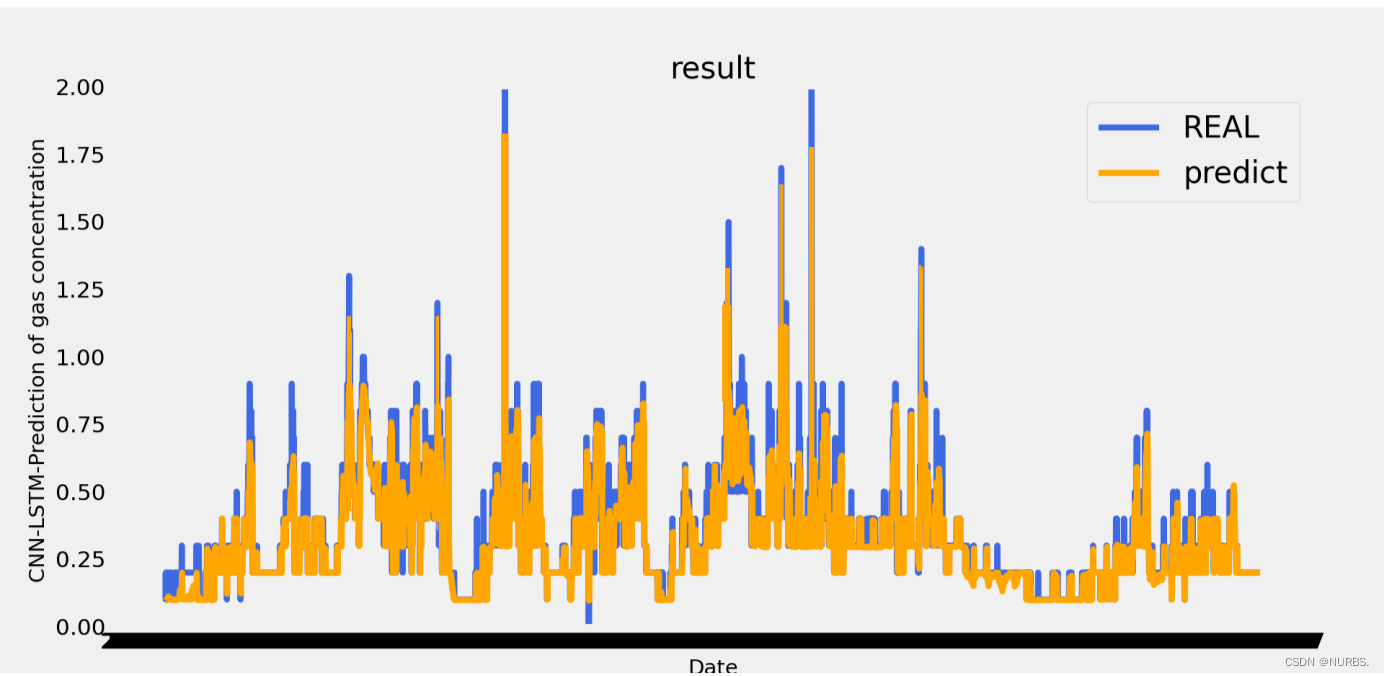
图14 CNN-LSTM神经网络预测结果图
对于回归模型来说,可以使用一些评估指标来判断模型的预测优势,这些评估指标分别是:
- 平均绝对误差(Mean Absolute Error, MAE):是绝对误差的平均值,可以更好地反映预测值误差的实际情况。
平均绝对误差公式如下:
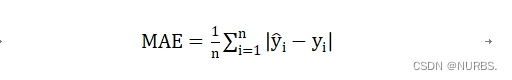
其中,n为样本数量,![]() 为预测值,
为预测值,![]() 为真实值。
为真实值。
- 均方根误差(Root Mean Square Error, RMSE):即均方误差开根号,方均根偏移代表预测的值和观察到的值之差的样本标准差。
均方根误差公式如下:
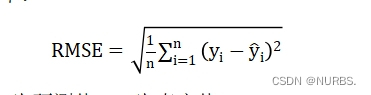
其中,n为测量次数,![]() 为预测值,
为预测值,![]() 为真实值。
为真实值。
- 决定系数R²(R squared, Coefficient of determination):决定系数,反映的是模型拟合数据的准确程度,一般R² 的范围是0到1。其值越接近1,表明方程的变量对y的解释能力越强,这个模型对数据拟合的情况也较好。
决定系数公式如下:
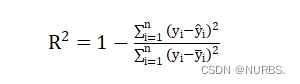
其中,n为测量次数,![]() 为预测值,
为预测值,![]() 为真实值,
为真实值,![]() 为平均值。公式中的
为平均值。公式中的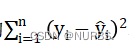 表示均方误差,
表示均方误差,![]() 表示方差。
表示方差。
为CNN-LSTM模型添加MAE、RMSE和R2等评估指标过程如下并将结果保存到csv文件中:
# 假设预测结果为y_pred,真实结果为y_true
y_pred = np.array(y_pred)
y_true = np.array(y_train)
# 计算MAE、RMSE和R2
mae = mean_absolute_error(y_true, y_pred)
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
r2 = r2_score(y_true, y_pred)
# 输出结果
print("MAE: {:.2f}".format(mae))
print("RMSE: {:.2f}".format(rmse))
print("R2: {:.2f}".format(r2))
# 将输出结果保存到csv文件中
with open(r'C:\Users\hmzjb\PycharmProjects\pythonProject7\CNN-LSTM\预测指标对比\CNN-LSTM.csv', mode='w') as file:
writer = csv.writer(file)
writer.writerow(["MAE", "RMSE", "R2"])
writer.writerow([mae, rmse, r2])
计算模型预测指标结果并将数据保存到CNN-LSTM.csv文件中,分别保存时间步长为T+1、T+3和T+5的预测指标,数据在CSV文件中如表3所示:
表3 保存后的数据
| Pre_seconds | MAE | RMSE | R2 |
| T+1 | 0.089927841 | 0.115169649 | 0.929529859 |
| T+3 | 0.091476584 | 0.112012027 | 0.877006299 |
| T+5 | 0.092810051 | 0.121517791 | 0.866386878 |

















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









