






一.下载yolov5
1.下载地址(YOLOv5论文的源代码地址为):GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
下载方式1:
(1)如果能够熟练运用git的话可以打开终端windows+R输入cmd
(2)进入想要保存的目录(最好是英文目录)例如 cd E:\A f pan\yolov5
(3)输入git clone https://github.com/ultralytics/yolov5.git
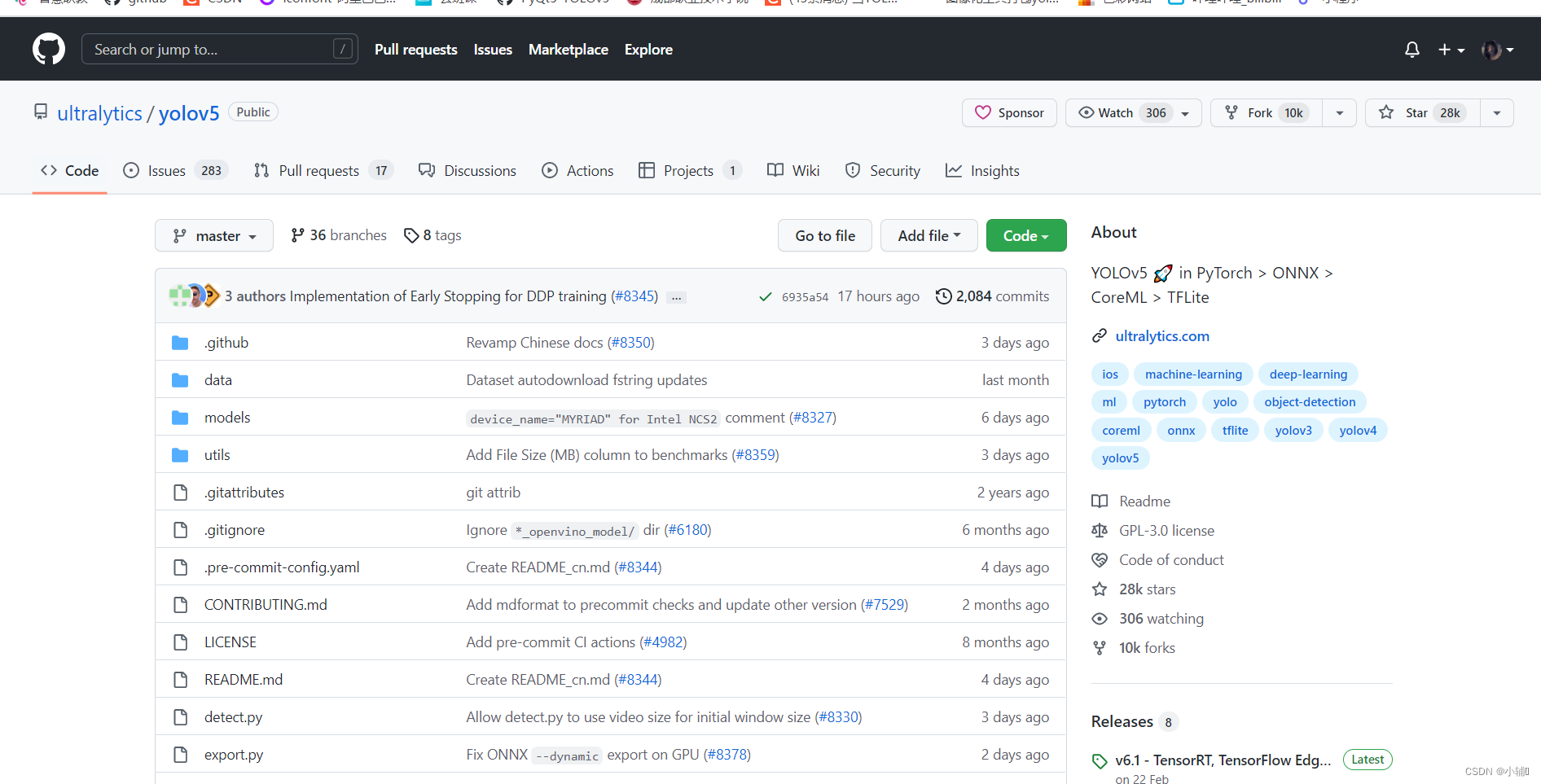
下载方式2:
(1)点击code
(2)点击download zip ,选择你要保存的地址就可以了(最好使用英文路径,创建一个单独项目)
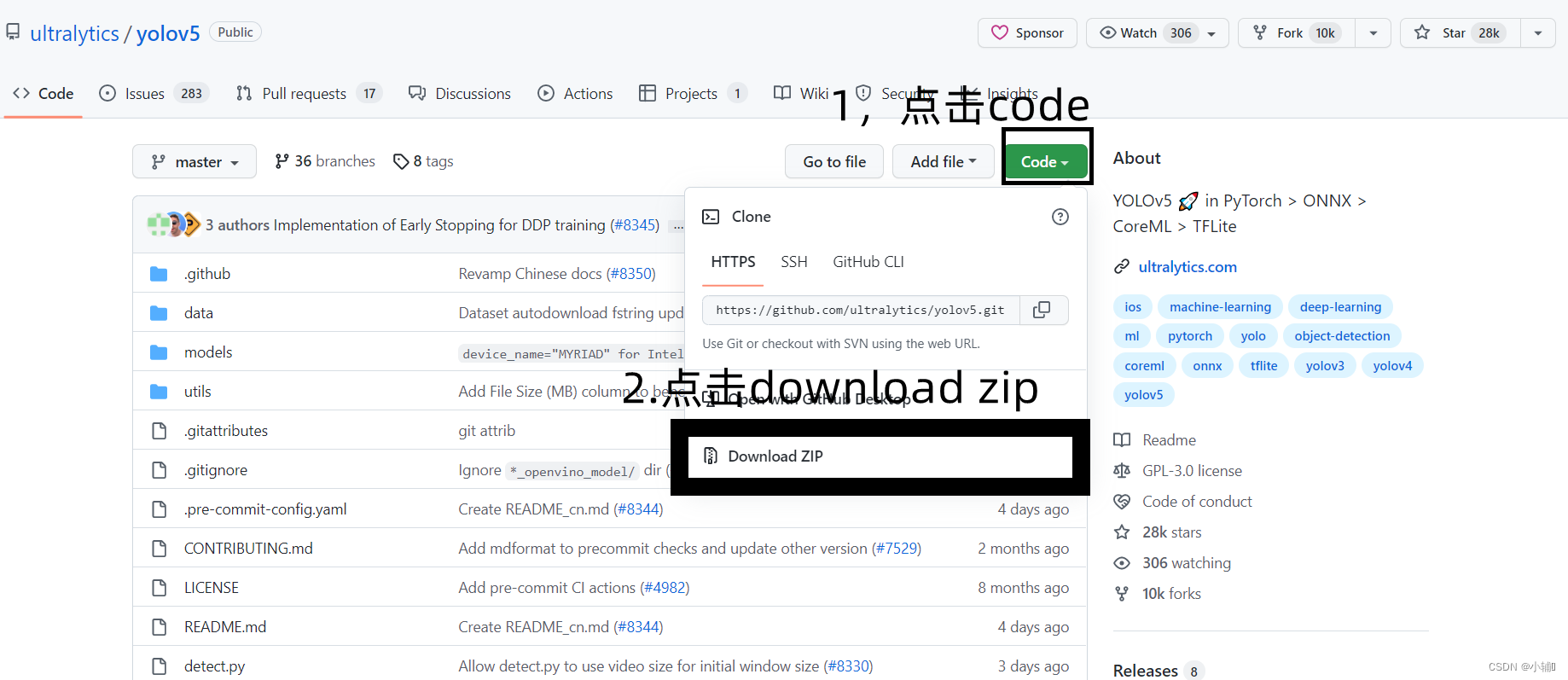
2.配置环境(我使用的是python3.6版本)
(1)下载打开后解压,这个样子
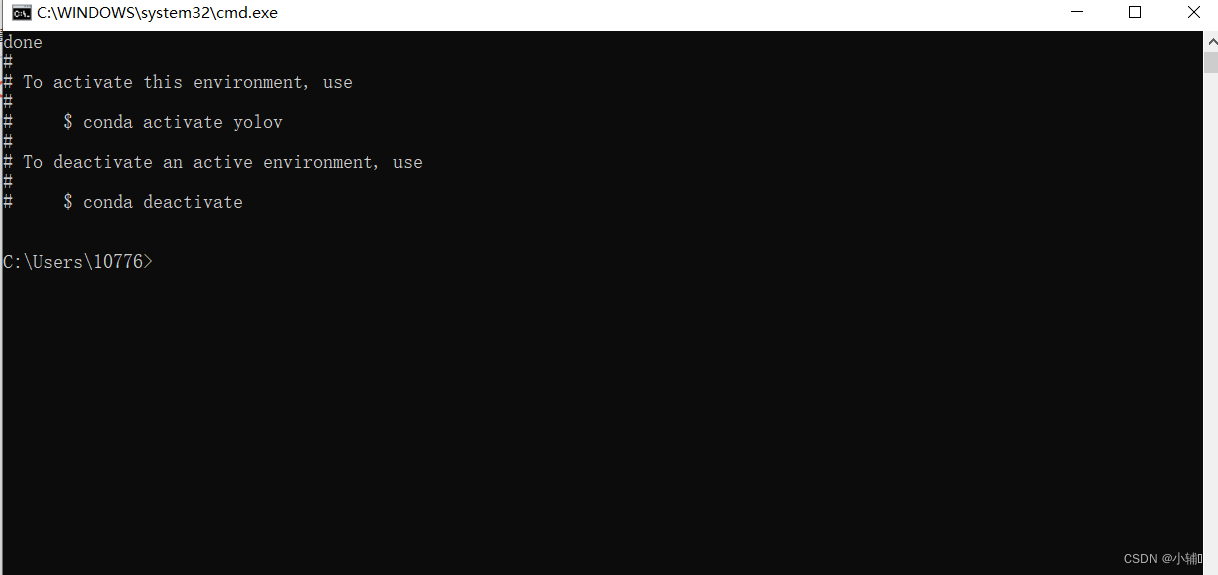
(2) 新建一个python虚拟环境,打开终端:windows+R 输入cmd(我用的anaconda),
运行conda create -n yolov python=3.6 yolov:虚拟环境名字 python=3.6:版本
(会有一个确认操作,输入y就可以了)创建成功后就是这样:
激活虚拟环境:activate +虚拟环境名字(yolov)
进入这个项目例如:cd E:\yolov5\yolov5-master
(2)打开requirements.txt,可以看到这个里面包含了yolov5需要安装的包,运行
pip install -r requirements.txt (要进入这个目录才运行,不然会找不到文件),如果哪些包不行可以尝试一下单独安装。

(3)检测yolov是否能够正常运行:
1.在正确项目路径,正确虚拟环境下,终端输入jupyter notebook(这个是anaconda的一个工具),在打开notebook的时候不要关闭终端,不然后面都无法操作
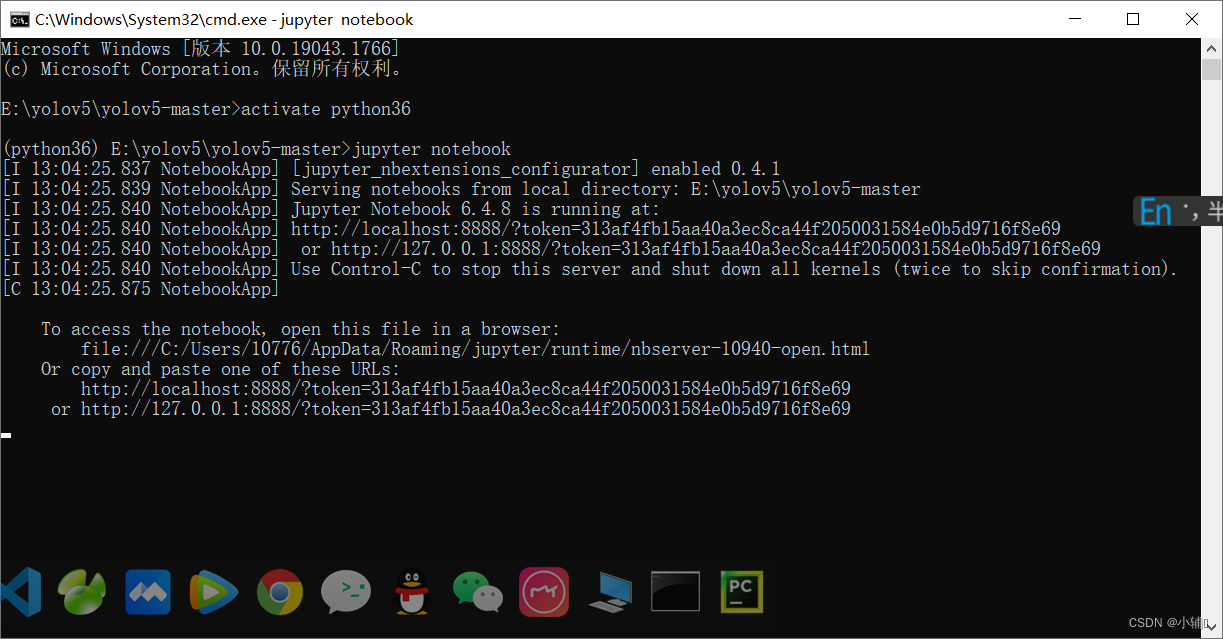
会在你的浏览器打开这个项目,
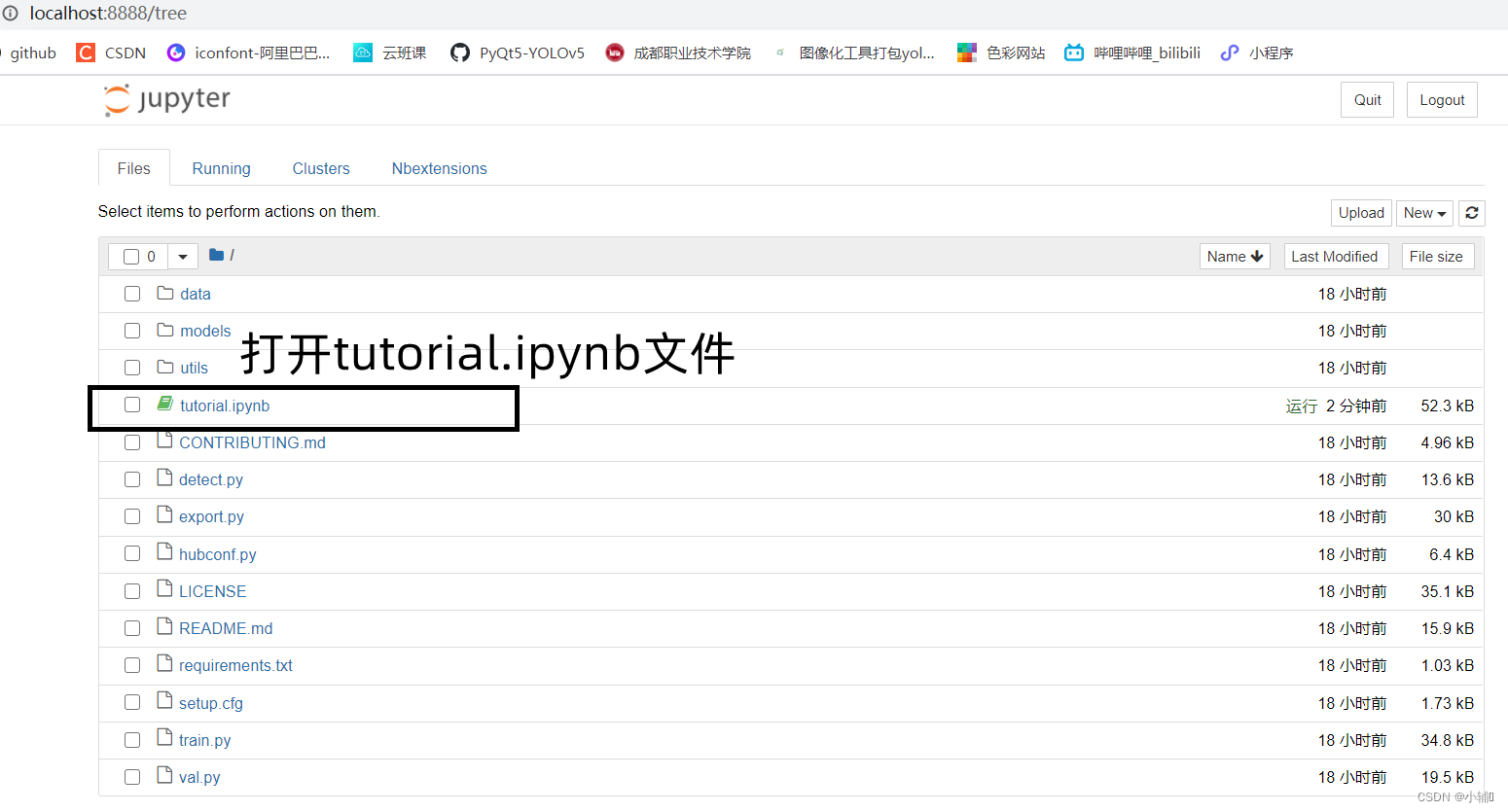
打开tutorial.ipynb文件
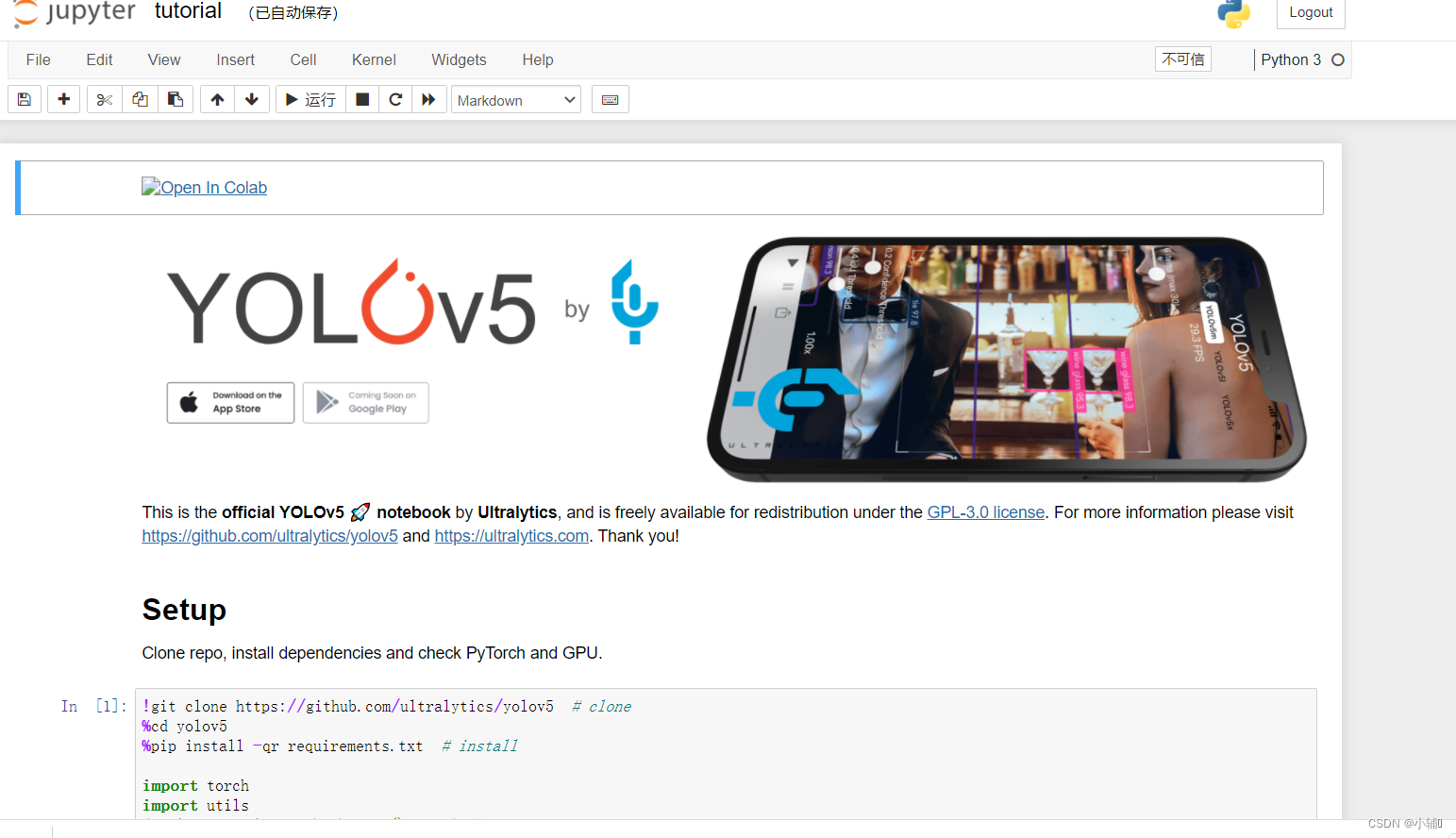
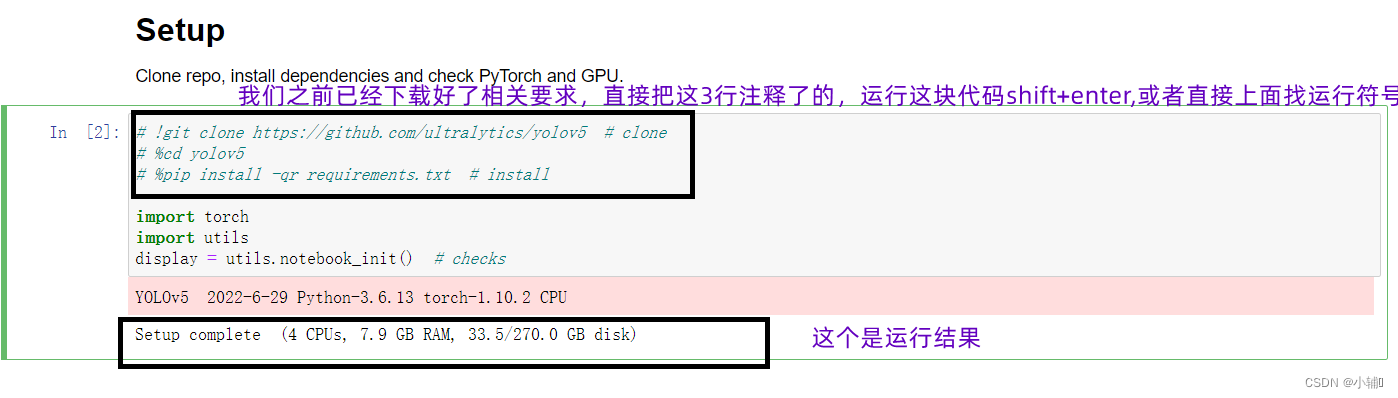
运行代码时,我们之前已经下载好了相关要求,直接把这3行注释了的,运行这块代码shift+enter,或者直接上面找运行符号
在运行第二段的时候会报错,没有找到文件,差一个yolov5s.pt文件(如果没有报错的话那是因为yolov5直接把这个文件给你下载了,会直接保存在项目中)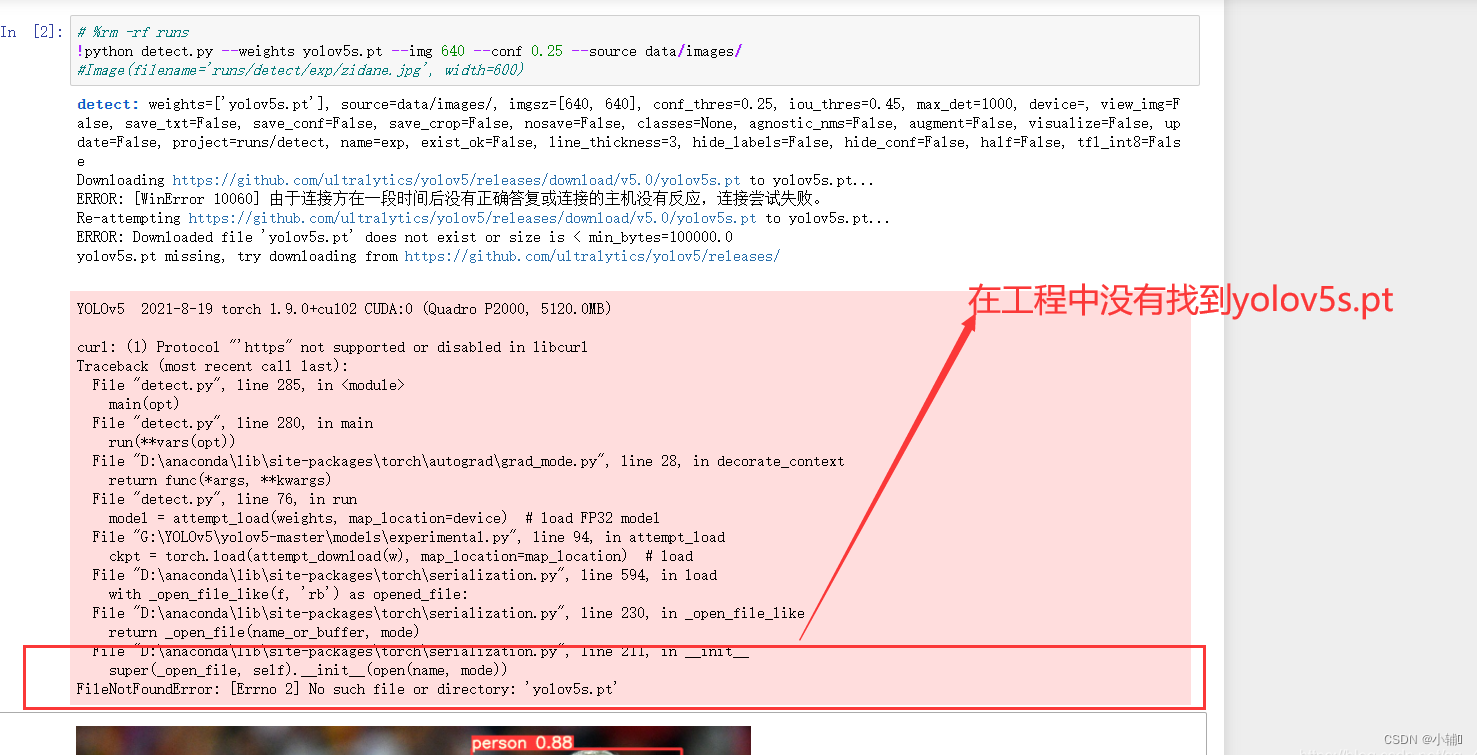
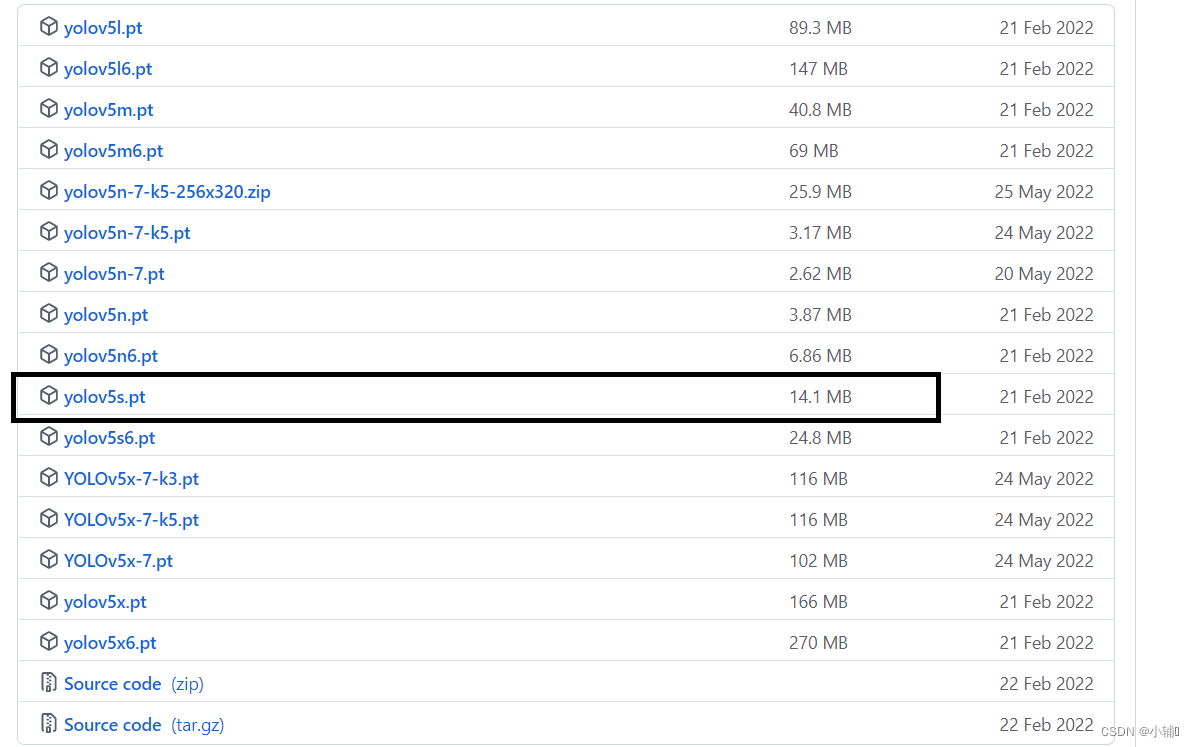
进入这个网址 https://github.com/ultralytics/yolov5/releases
下拉找到yolov5s.pt,在yolov项目下创建weigts文件夹weights,把这个文件保存到weights下
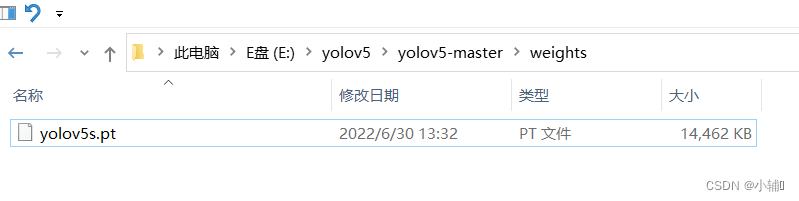
在weights加上路径,
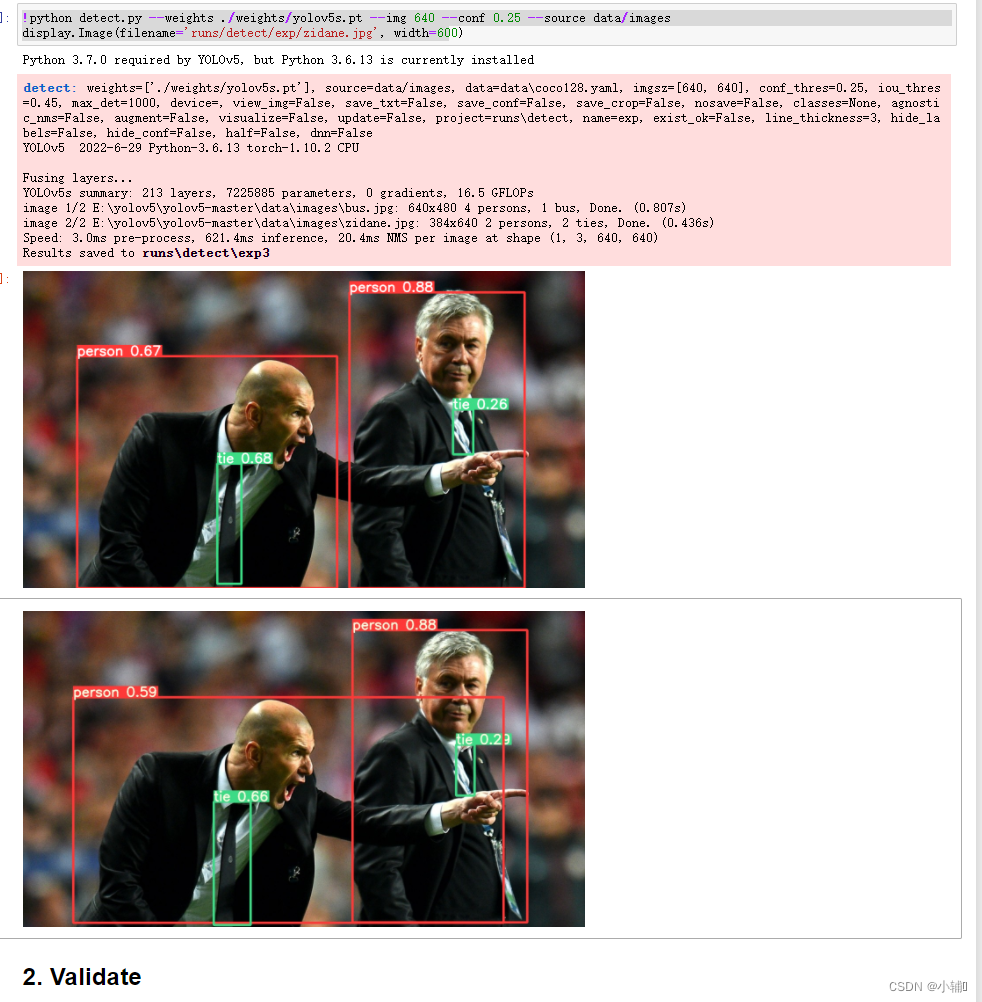
!python detect.py --weights ./weights/yolov5s.pt --img 640 --conf 0.25 --source data/images
display.Image(filename='runs/detect/exp/zidane.jpg', width=600)

现在可以发现,yolov已经可以正常运行了:
二.网上爬取训练图片
我使用的pycharm,打开这个项目,创建一个py文件,例如:puqu.py 用来爬取百度图片
因为使用百度爬取的图片会比较杂,所以在爬取之前最好先在百度试一下关键词,最好加一些限制词,这样效果会好一点
代码如下:
import re # 正则表达式,解析网页
import requests # 请求网页
import traceback
import os
def dowmloadPic(html, keyword, startNum):
headers = {'user-agent': 'Mozilla/5.0'} # 浏览器伪装,因为有的网站会反爬虫,通过该headers可以伪装成浏览器访问,否则user-agent中的代理信息为python
pic_url = re.findall('"objURL":"(.*?)",', html, re.S) # 找到符合正则规则的目标网站
num = len(pic_url)
i = startNum
subroot = root + '/' + word
txtpath = subroot + '/download_detail.txt'
print('找到关键词:' + keyword + '的图片,现在开始下载图片...')
for each in pic_url:
a = '第' + str(i + 1) + '张图片,图片地址:' + str(each) + '\n'
b = '正在下载' + a
print(b)
path = subroot + '/' + str(i + 1)
try:
if not os.path.exists(subroot):
os.mkdir(subroot)
if not os.path.exists(path):
pic = requests.get(each, headers=headers, timeout=10)
with open(path + '.jpg', 'wb') as f:
f.write(pic.content)
f.close()
with open(txtpath, 'a') as f:
f.write(a)
f.close()
except:
traceback.print_exc()
print('【错误】当前图片无法下载')
continue
i += 1
return i
if __name__ == '__main__':
headers = {'user-agent': 'Mozilla/5.0'}
words = ['人物高清图片']
# words为一个列表,可以自动保存多个关键字的图片
root = './download_images_of_'
for word in words:
root = root + word + '&'
if not os.path.exists(root):
os.mkdir(root)
for word in words:
lastNum = 0
# word = input("Input key word: ")
if word.strip() == "exit":
break
pageId = 0
# 此处的参数为需爬取的页数,设置为30页
for i in range(30):
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + "&pn=" + str(
pageId) + "&gsm=?&ct=&ic=0&lm=-1&width=0&height=0"
pageId += 20 # 好像没啥影响
html = requests.get(url, headers=headers)
# print(html.text) #打印网页源码,相当于在网页中右键查看源码内容
lastNum = dowmloadPic(html.text, word, lastNum, ) # 本条语句执行一次获取60张图爬取的图片会保存到一个文件夹里面,爬取的都是百度图片(想爬取其他类型的改一下46行的关键词就可以了)
三.对图片进行处理
就算加了限制词一样会有一些不符合要求的图片,最好自己手动检查一下,删除不需要的图片
然后可以修改一下图片名字,便于后面操作,代码如下:
import os
import re
"""批量修改文件夹的图片名"""
def ReFileName(dirPath,pattern):
"""
:param dirPath: 文件夹路径
:pattern:正则
:return:
"""
# 对目录下的文件进行遍历
i = 1
for file in os.listdir(dirPath):
# 判断是否是文件
if os.path.isfile(os.path.join(dirPath, file)) == True:
#c= os.path.basename(file)
newName = re.sub(pattern, str(i)+'.jpg', file)
newFilename = file.replace(file, newName)
# 重命名
os.rename(os.path.join(dirPath, file), os.path.join(dirPath, newFilename))
i+=1
print("图片名已全部修改成功")
if __name__ == '__main__':
dirPath = r"E:\A f pan\yolov5\images"
pattern = re.compile(r'.*')
ReFileName(dirPath,pattern)
在最后main函数修改你放图片的位置,把修改后的图片放在项目data/images images文件夹下,便于图片标注
四.labelimg工具进行标注
在你的环境下安装labelimg 打开终端windows+r 输入cmd,激活你的环境 activate +你的虚拟环境名,使用 pip install labelimg 命令直接安装,安装好后直接输入labelimg,打开这个工具
在yolov/data文件夹下创建dataset、labels两个文件夹。其中,datasets主要用来存放打好标签后的数据集,labels主要用来存放数据标签。
我们需要对labelimg进行一些设置:
(1)首先选择自动保存模型(1.点击view 2.勾选auto save mode),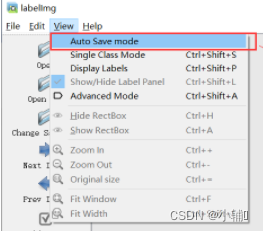
auto save mode :自动保存模型(这个要勾选,不然要一直保存)
single class mode: 单一标签标注(如果你训练只有一个标签,勾选这个很方便)
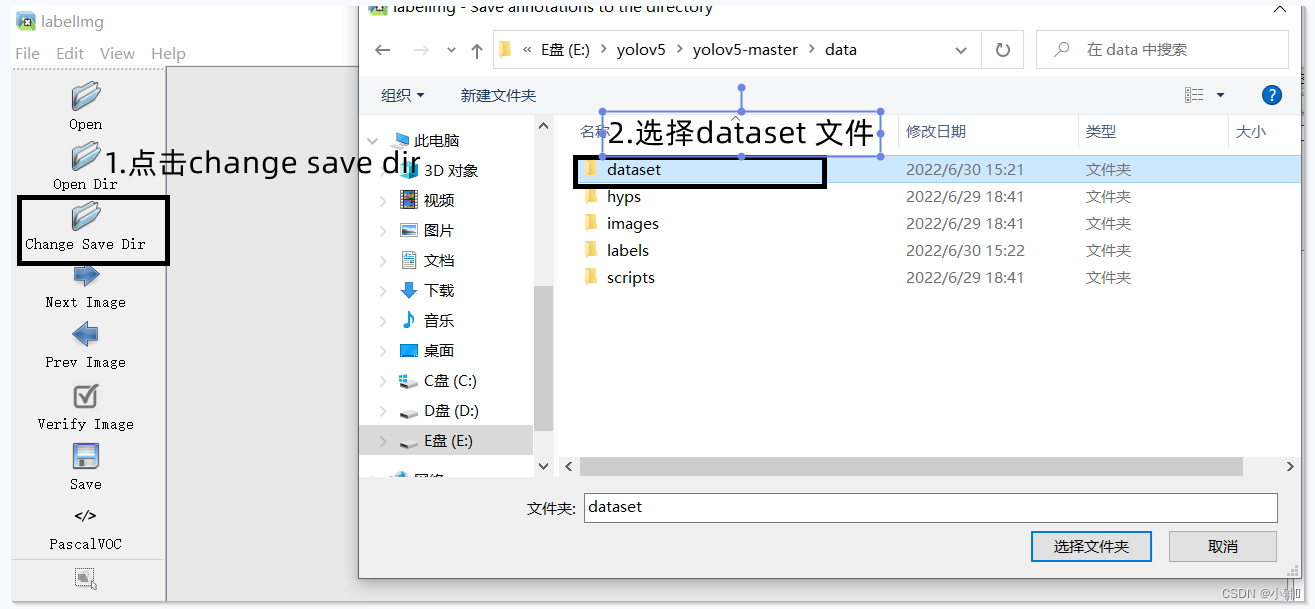
(2)然后再选择改变保存路径(1.点击change save dir 2.选择刚刚创建的dataset文件)
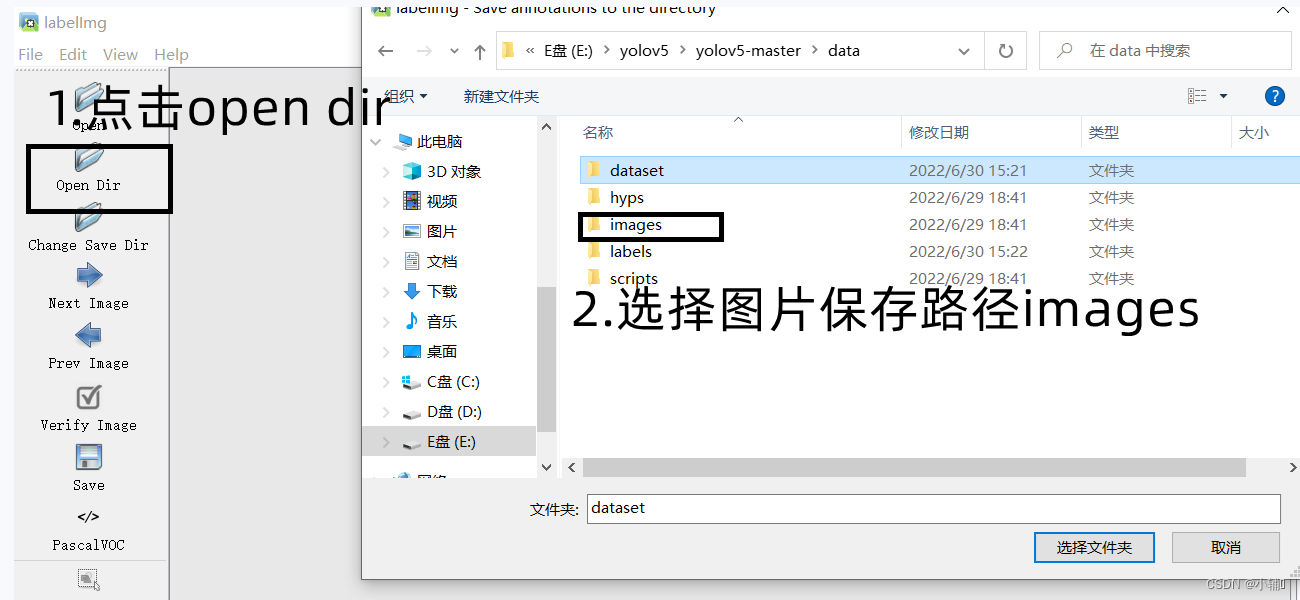
(3)打开需要进行数据标注的文件夹。(1点击open dir 2.选择需要标注图片的文件夹images)
(4)数据标注(比较枯燥),有一些快捷键可以加快标注速度
- Ctrl + d 复制当前标签和矩形框;
- Ctrl + Shift + d 删除当前图片;
- Space 将当前图像标记为已验证;
- w 开始创建矩形框;
- d 切换到下一张图;
- a 切换到上一张图;
- del 删除选中的标注矩形框;
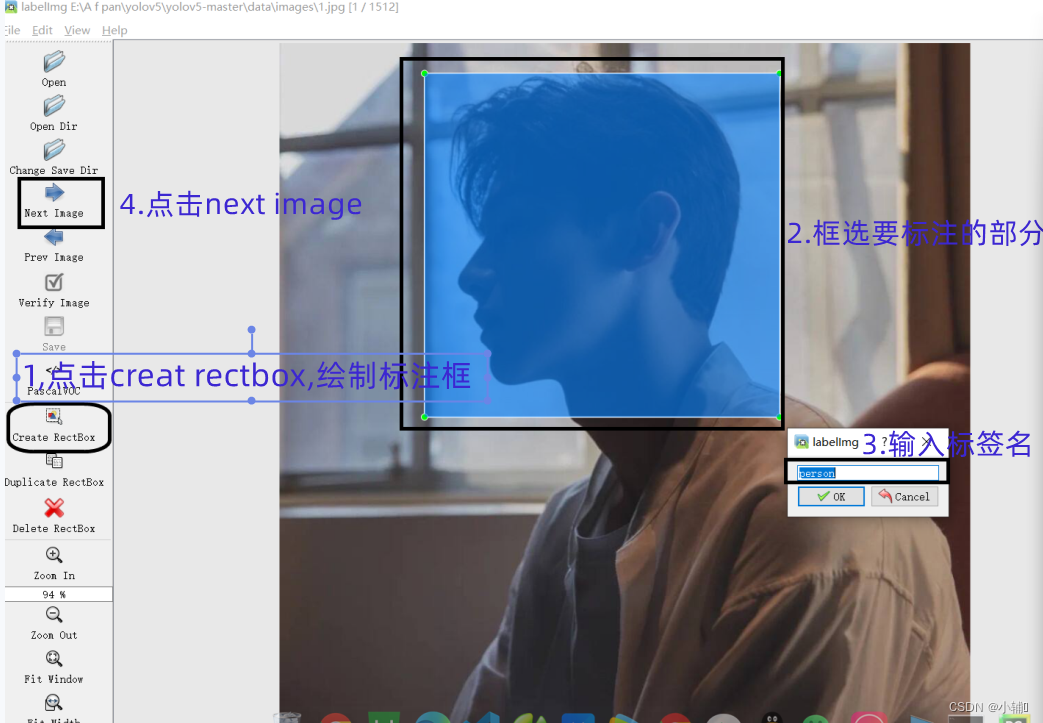
1.点击creat rectbox,绘制标注框
2.框选要标注的部分
3.输入标签名
4.点击next image
标注好的图片都在dataset文件里
五.训练数据集
接下来需要对标注好的数据进行预处理操作,在工程目录文件下新建split.py和xml_to_txt.py两个python文件:
split代码如下:
import os
import random
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--xml_path', default='data/dataset', type=str, help='input xml label path')
parser.add_argument('--txt_path', default='data/labels', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.8
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
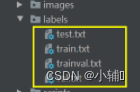
file_test.close()运行后会在labels生成四个文件:
xml_to_txt.py代码如下:
import xml.etree.ElementTree as ET
from tqdm import tqdm
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ['person'] # 这里改为你要训练的标签,否则会报错。比如你要识别“hand”,那这里就改为hand
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
# try:
in_file = open('data/dataset/%s.xml' % (image_id), encoding='utf-8')
out_file = open('data/labels/%s.txt' % (image_id), 'w', encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " +
" ".join([str(a) for a in bb]) + '\n')
# except Exception as e:
# print(e, image_id)
wd = getcwd()
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/labels/%s.txt' %
(image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in tqdm(image_ids):
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()修改第七行代码,将标签改为你自己的,运行后labels出现的文件就是已经打好标签的txt文件
在data文件夹中新建myvoc.yaml文件:

代码如下:
train: data/train.txt
val: data/val.txt
# number of classes
nc: 1
# class names
names: ["person"]nc:为你的标签类有几个(我的是对人的检测,只有一个)
将names: 里面的标签改为你自己的标签。
然后就可以训练了打开终端,激活自己的环境,进入项目工程下,输入训练命令:
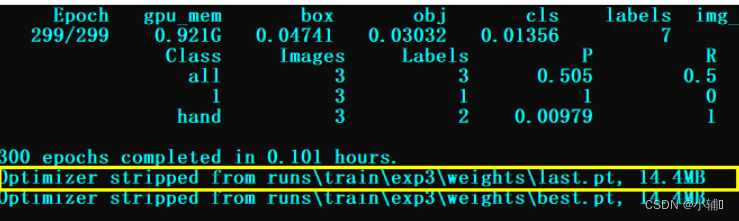
python train.py --epoch 300 --batch 4 --data ./data/myvoc.yaml --cfg ./models/yolov5s.yaml --weight ./weights/yolov5s.pt --workers 0
epoch 300 训练300轮
batch 4 一次读入4张图片进行训练
如果电脑性能不是那么理想的话可以适当修改这两个参数值,训练好后会有两个文件best.pt和last.pt,会显示他的路径,找到就可以了,这两个就是你训练的模型
last.pt: 训练最后一轮的模型
bast.pt:效果最优的模型















 2916
2916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









