






简介
P-Tuning就是提示调优(Prompt Tuning),主要思想是固定预训练模型的参数,然后在模型的输入端添加可学习的"prompt"(提示)进行调整。这种方法的优点是计算成本低,因为只需要更新少量的参数。它不改变模型,而是通过对提示的优化,让模型输出最佳的结果
静态提示训练举例:
- 首先,初始化一个或多个“提示”向量。这些向量可以随机初始化,或者使用一些先验知识来初始化。
- 在每个输入文本前加上一个“提示标记”。例如,我们可以添加一个“[SENTIMENT]”标记,然后紧跟原始文本。如:“[SENTIMENT] This movie is great!”
- 将这些“提示标记”与对应的提示向量关联起来。也就是说,模型在处理输入时,不仅会看到原始文本,还会看到与“[SENTIMENT]”关联的提示向量。
- 在情感分析的训练数据上进行训练。与传统的微调不同,这里我们只更新提示向量,而不更新模型的其他参数(或者只更新很少的参数)。这意味着,我们主要是在调整这些提示向量,使它们能够帮助模型更好地执行情感分类。
- 在测试时,我们依然在每个输入文本前加上“[SENTIMENT]”标记,并使用学到的提示向量来辅助模型进行分类。]
- P-tuning 使用的是可学习的、参数化的提示,这意味着每个提示都对应一个嵌入向量,这个向量是在任务的训练过程中被优化的。
- 为了使用提示,输入文本被扩展来包含这些参数化的提示。例如,一个情感分析任务的输入可能会被扩展为“[P1] [P2] [P3] This movie is great!”,其中 [P1], [P2], [P3] 是参数化的、可学习的提示。
- 在训练过程中,模型的主要参数保持固定,而提示的嵌入会被更新。目标是找到最优的提示嵌入,使得模型在给定任务上的表现最佳。在训练过程中,模型的预训练参数不发生变化,只有提示 [P1], [P2], [P3] 的嵌入向量会被更新。
prefix-tuning
相对于fine-tuning,在调节模型的过程中只优化一小段可学习的continuous task-specific vector(prefix)而不是整个模型的参数。

P-Tuning v1
计了一种连续可微的virtual token
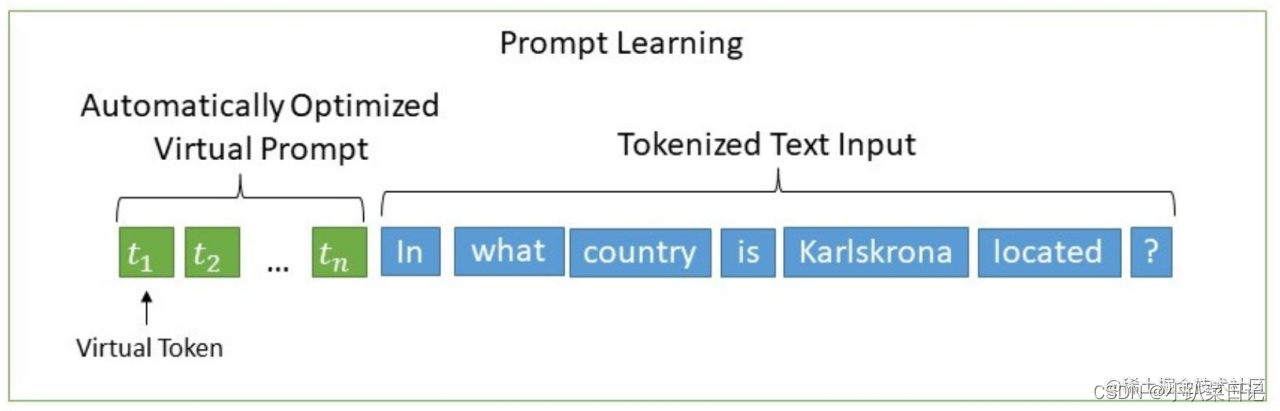
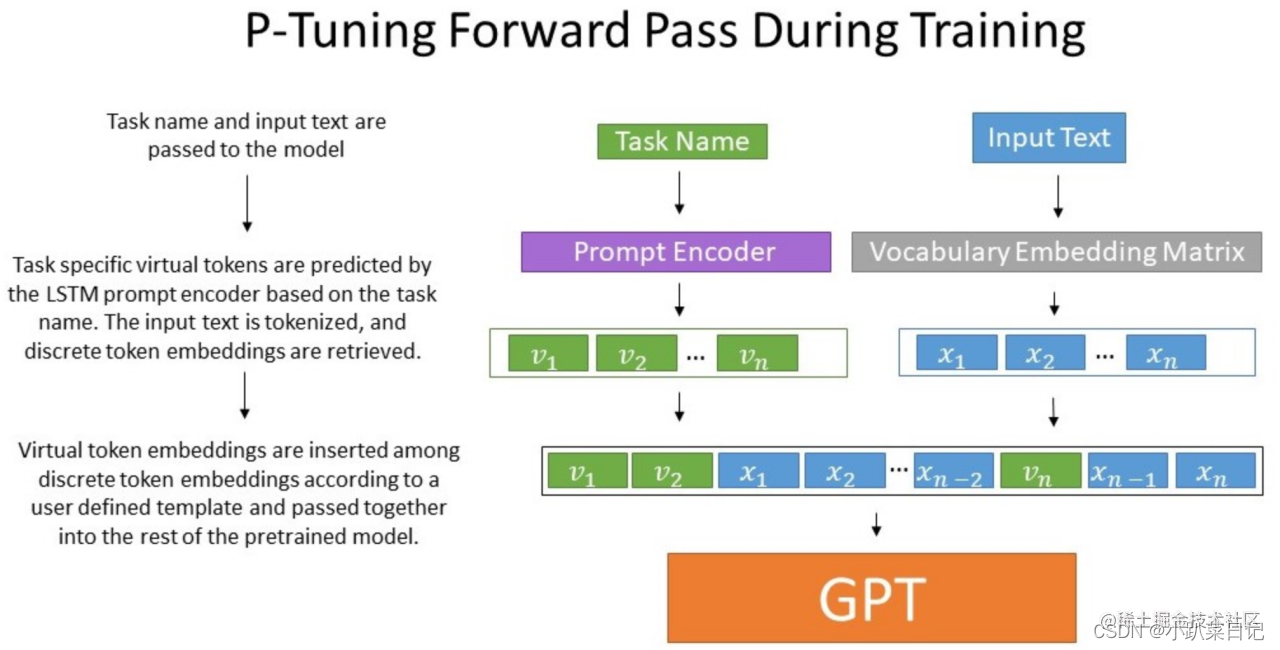
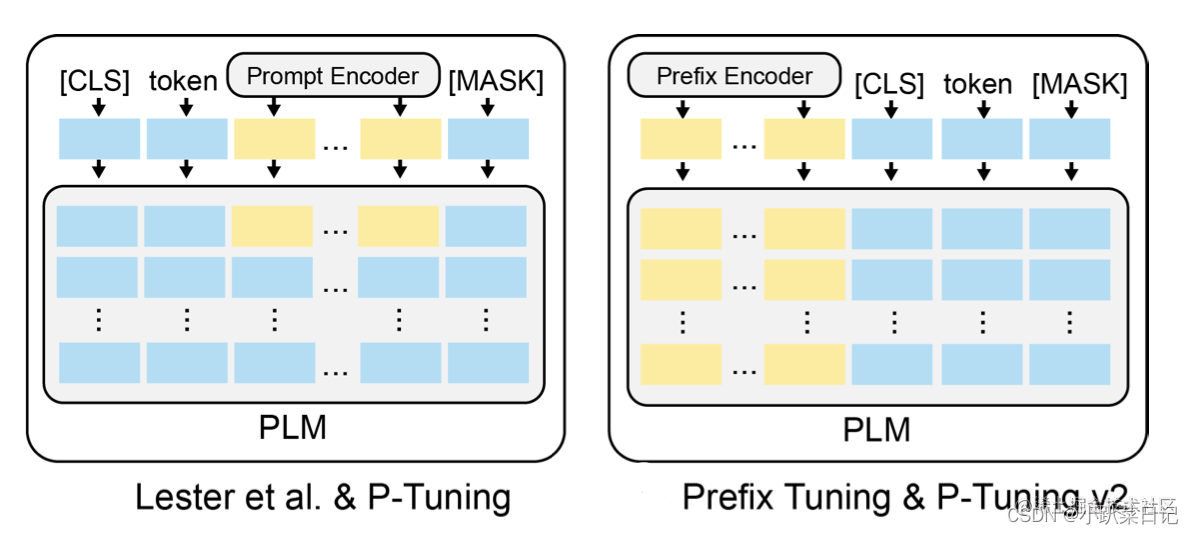
用MLP+LSTM作为Prompy Encoder层去编码这些virtual token,转换为可学习的Embedding层,然后再输入模型。 相比Prefix Tuning,P-Tuning加入的可微的virtual token,但仅限于输入层,没有在每一层都加;另外,virtual token的位置也不一定是前缀,插入的位置是可选的
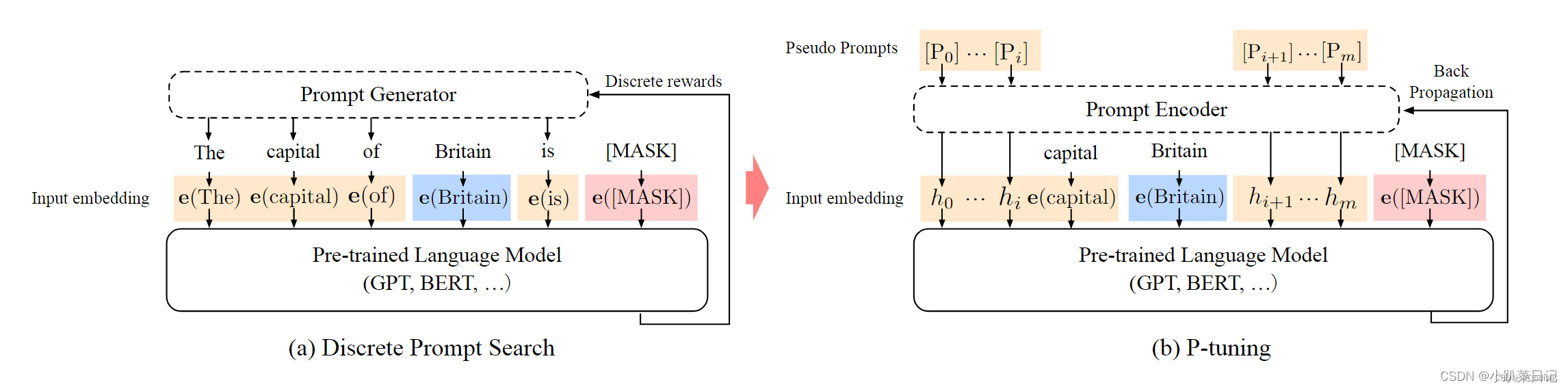
P-Tuning v2
之前的Prompt Tuning和P-Tuning等方法存在两个主要的问题:
- Prompt Tuning论文中表明当模型规模超过100亿个参数时,提示优化可以与全量微调相媲美。但是对于那些较小的模型(从100M到1B),提示优化和全量微调的表现有很大差异,这大大限制了提示优化的适用性。尽管Prompt Tuning和P-tuning在一些 NLU 基准测试中表现出优势,但提示调优对硬序列标记任务(即序列标注)的有效性尚未得到验证。
- 由于序列长度的限制,可调参数的数量是有限的。除了语言模型的第一层之外,其他层的prompt embddding都来自于上一层,输入embedding对模型预测只有相对间接的影响
v2 在v1的基础上进行了改进,在每一层都加入了Prompts tokens作为输入,层与层之间的continuous prompt是相互独立的,加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
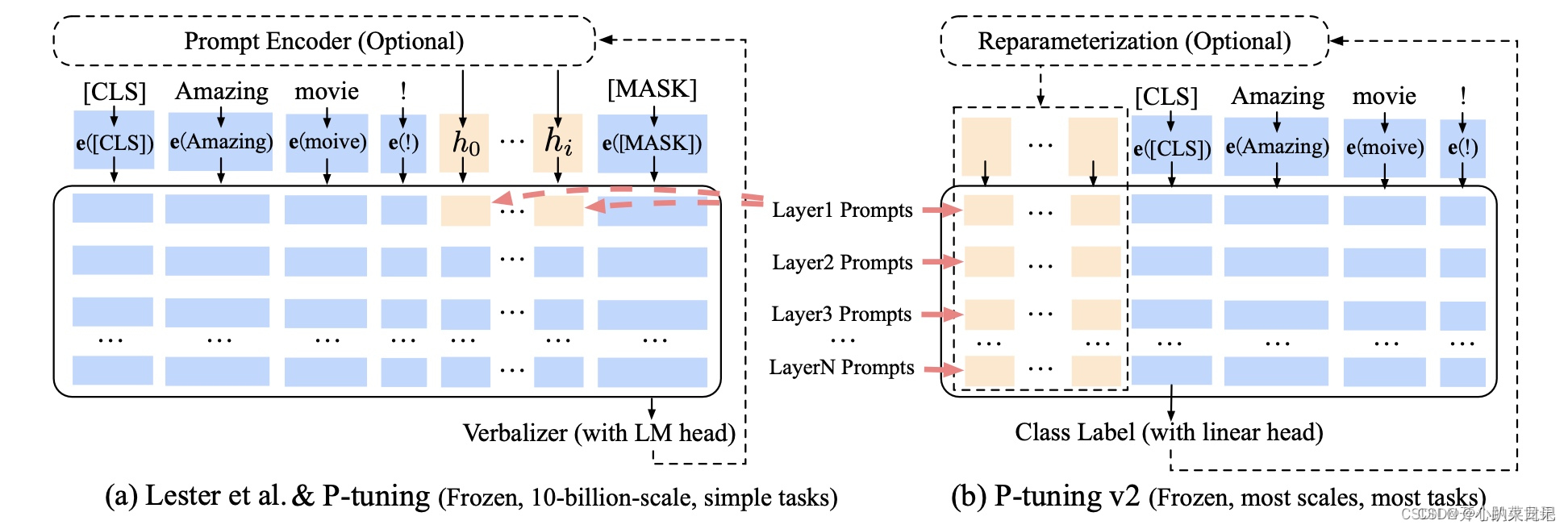
优化手段:
1. 移除重参数化的编码器。之前的方法(例如P-Tuning/prefix-tuning)为了增强模型鲁棒性,提升训练速度和模型表现,针对continuous prompt设计了LSTM/MLP等Reparameterization的方法。但是在实践中,作者发现这些设计并不一定有效。
2. 我们发现不同的理解任务通常用不同的提示长度来实现其最佳性能
3. 多任务学习能够很大的提升模型表现。然后再适配下游任务
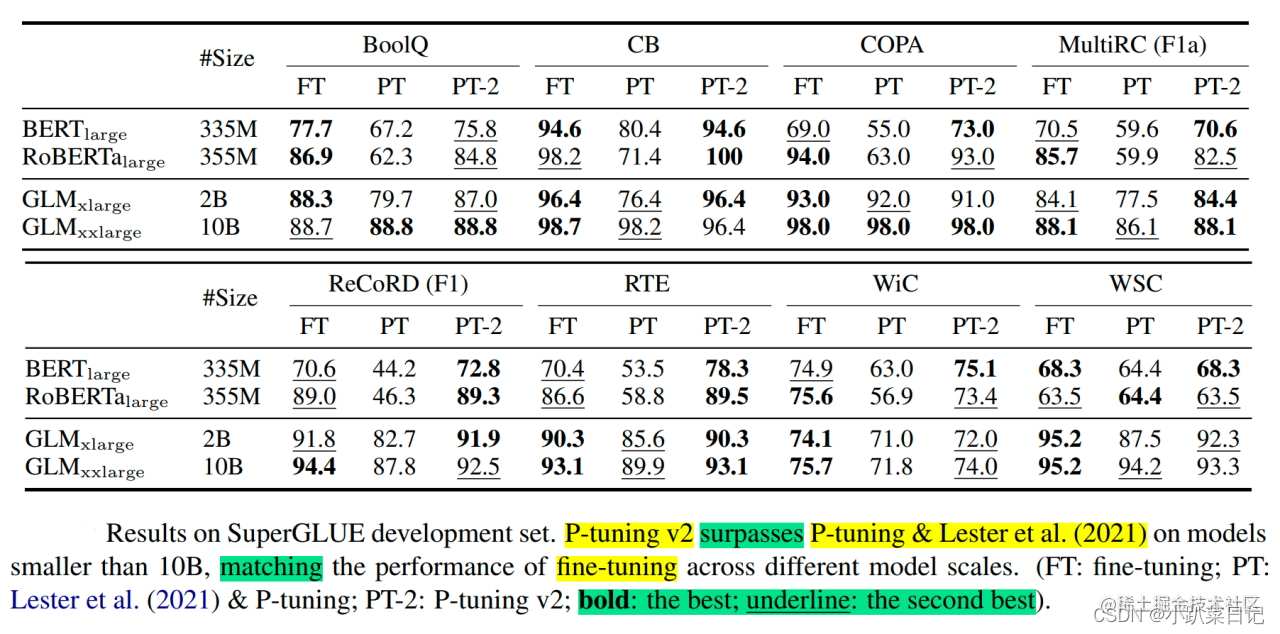
论文中展示了,当涉及到复杂的挑战时,如:自然语言推理(RTE)和多选题回答(BoolQ),PT的效果相比于FT要差的多,而P-Tuning v2的差别则没那么大,甚至更好。P-Tuning v2在较小规模的所有任务中都与FT的性能相匹配。并且,P-tuning v2在RTE中的表现明显优于FT,特别是在BERT中。
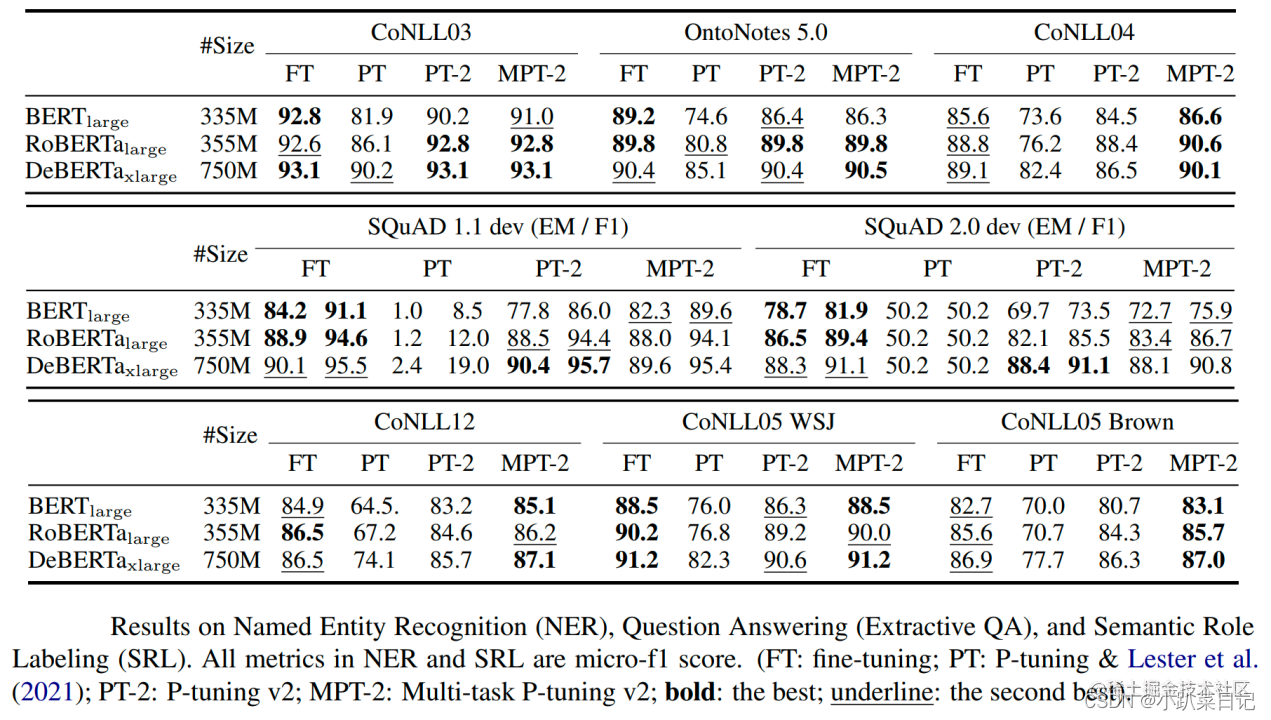
GLUE和SuperGLUE的大多数任务都是相对简单的NLU问题。为了评估P-Tuning v2在一些困难的NLU挑战中的能力,作者选择了三个典型的序列标注任务(名称实体识别、抽取式问答(QA)和语义角色标签(SRL)),共八个数据集。我们观察到P-Tuning v2在所有任务上都能与全量微调相媲美。
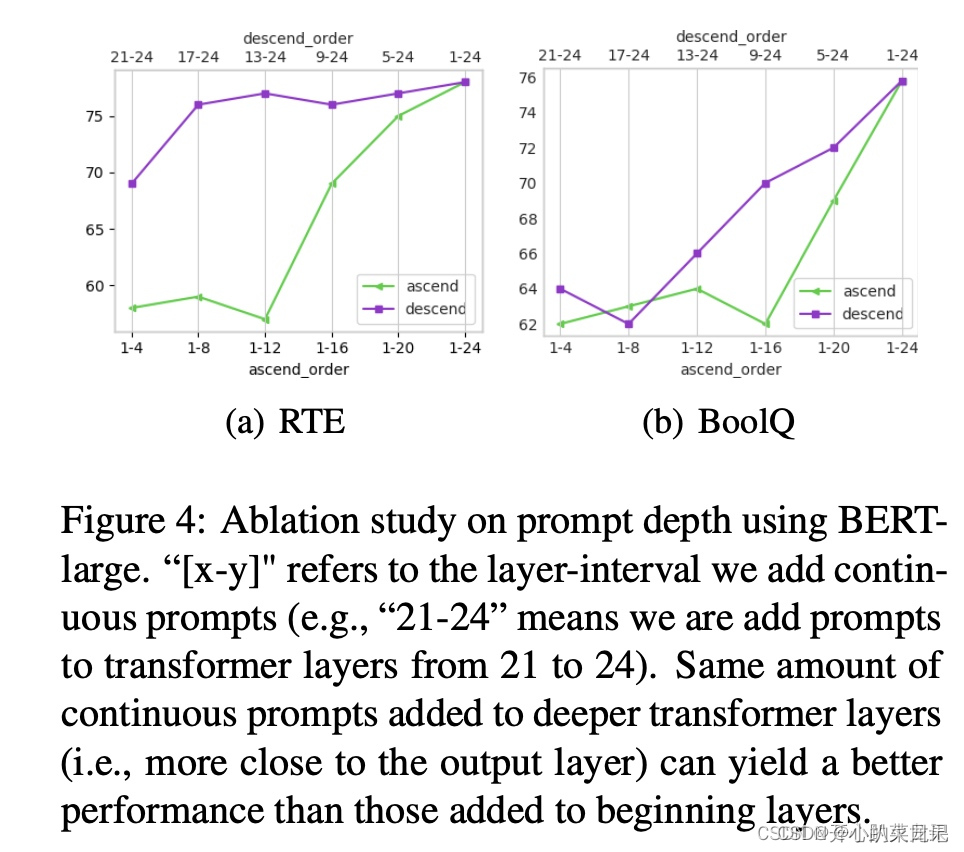
在模型的5-24层添加prompt能够达到和所有层都添加prompt一致的效果。另外,在深层添加prompt的效果总是好于在浅层添加。
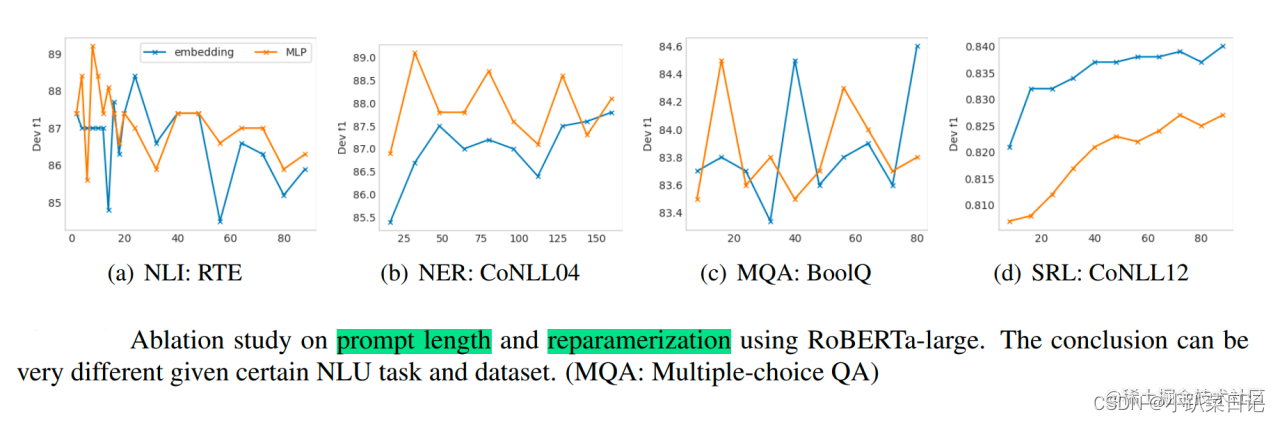
论文还通过消融实验研究了不同任务上Prompt Length的影响
对于简单的NLU任务,较短的提示足以获得最佳性能;对于较难的序列任务,通常,超过 100 的提示会有所帮助。
可以简单的将P-Tuning认为是针对Prompt Tuning的改进,P-Tuning v2认为是针对Prefix Tuning的改进。
大模型参数高效微调技术原理综述(三)-P-Tuning、P-Tuning v2_ptuning和 全量微调对比-CSDN博客

















 518
518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









