




论文地址:https://arxiv.org/pdf/1810.12890.pdf
论文概要
DropBlock 是一种类似于 dropout 的简单方法,它与 dropout 的主要区别在于,它从层的特征图中抹除连续区域,而不是抹除独立的随机单元
类似地,DropBlock 通过随机地置零网络的响应,实现了通道之间的解耦,缓解了网络的过拟合现象
这个算法的伪代码如下:
- x:特征图,shape 为 [bs, ch, h, w]
- block_size:抹除连续区域的尺寸
- γ:伯努利分布的均值,用于选中抹除区域的中心点
- trainning:布尔类型,表明是 train 模式还是 eval 模式
def DropBlock(x, block_size, γ, trainning):
if trainning:
# 选中要抹除区域的中心点
del_mask = bernoulli(x, γ)
# 抹除相应的区域
x = set_zero(x, del_mask, block_size)
# 特征图标准化
keep_mask = 1 - del_mask
x *= count(x) / count_1(keep_mask)
return x
# eval 模式下没有任何行为
return x但是在具体实现的过程中,还有很多需要补充的细节

γ 的确定是通过 keep_prob 参数确定的,keep_prob 表示激活单元 (即输出大于 0) 被保留的概率,feat_size 为特征图的尺寸:
因为在训练刚开始时,较小的 keep_prob 会影响网络的收敛,所以令 keep_prob 从 1.0 渐渐降为 0.9
从实验结果可以看到,ResNet-50 在使用了 DropBlock 后在验证集上的准确率有一定的提升

以下是不同的 DropBlock 追加位置、不同的处理方法、不同 block_size 对验证集准确率的影响:
- 按行:DropBlock 追加在 ResNet-50 的第 4 组卷积后;DropBlock 追加在 ResNet-50 的第3、第 4 组卷积后
- 按列:只在卷积分支上追加;在卷积分支、残差连接分支上追加;在卷积分支、残差连接分支上追加,并使用 keep_prob 衰减的方法
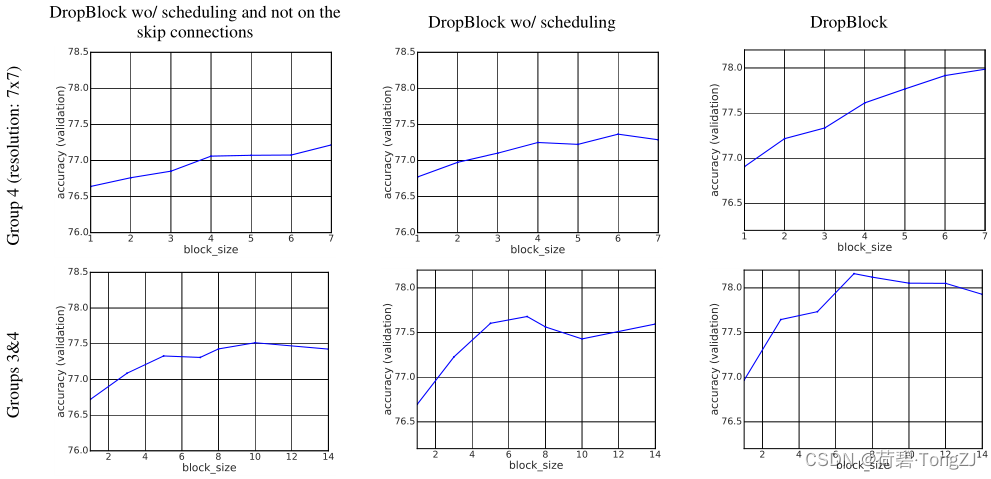
在论文中,最优的超参数是 block_size = 7, keep_prob = 0.9,但实际使用时仍需要根据 Loss 的变化情况做出调整
DropBlock 复现
在实现 DropBlock 时,有以下几个细节:
- drop_prob = 1 - keep_prob 是动态变化的,在每次从 eval 模式切换到 train 模式后进行更新
- 抹除区域的中心点是在激活单元中选择的 (即输出大于 0),令 1 表示被选中,使用 max_pool2d 可以实现连续区域的选中,以生成 drop_mask
- 标准化系数 = 原图面积 / 保留区域面积,目的是为了弥补抹除部分带来的损失
class DropBlock(nn.Module):
''' k: size of the masking area
drop: target value of drop_prob
epochs: the number of epochs in which drop_prob reaches its target value
scheme: drop_prob adjustment scheme'''
epochs = 10
scheme = 'linear'
_progress = property(fget=lambda self: torch.clip(self.cnt / self.epochs, min=0, max=1).item())
@property
def drop(self):
# Incremental method from 0 to 1
scale = {'const': lambda: 1,
'linear': lambda: self._progress,
}[self.scheme]()
return self._dp_tar * scale
def __init__(self, k=5, drop=0.1):
super().__init__()
self.register_buffer('cnt', torch.tensor([0], dtype=torch.int64))
self.k = k
assert self.k & 1, 'The k should be odd'
self._dp_tar = drop
def extra_repr(self):
return f'k={self.k}, \n' \
f'drop={self.drop}, \n' \
f'scheme={self.scheme}, \n' \
f'progress={self._progress},'
def train(self, mode=True):
self.cnt += mode and not self.training
super().train(mode)
def step(self, epochs=None):
epochs = self.epochs if not epochs else epochs
# Check the track of drop_prob
drop = []
for _ in range(epochs):
self.eval(), self.train()
drop.append(self.drop)
print(f'[WARNING] The drop probability has been changed to {self.drop}')
return drop
def forward(self, x):
if self.training and self.drop > 0:
# Select the center point of the masking area in the active area
dmask = torch.bernoulli((x > 0) * (self.drop / self.k ** 2))
kmask = 1 - (torch.max_pool2d(
dmask, kernel_size=self.k, stride=1, padding=self.k // 2
) if self.k > 1 else dmask)
# Standardization in the channel dimension
x *= np.prod(x.shape[-2:]) / kmask.sum(dim=(2, 3), keepdims=True) * kmask
return x代码测试
# 利用灰度图, 将亮度低的像素置为 0
image = cv.imread('YouXiZi.jpg')
mask = cv.cvtColor(image, cv.COLOR_BGR2GRAY) > 100
for i in range(3): image[..., i] *= mask
cv.imshow('debug', image)
cv.waitKey(0)
# 转化为 tensor, 初始化 DropBlock
tensor = tf.ToTensor()(image)
# DropBlock.inference = True
db = DropBlock(31)
print(db.step(5))
db.train()
# 切换到 train 模式, 查看抹除结果
image = db(tensor.unsqueeze(0))[0]
image = image.permute(1, 2, 0).data.numpy()
cv.imshow('debug', image)
cv.waitKey(0)
# 测试文件保存
file = 'drop.pt'
torch.save(db, file)
print('\n', torch.load(file).drop)利用灰度图将亮度暗的像素置零,亮区即为激活单元

抹除区域的中心点均出现在亮区内,而且图像的亮度相较于原图有一定提升 (标准化系数 > 1)




















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











