






1.MNIST手写数字数据集介绍
MNIST数据集是学习图像处理接手的第一个数据集,其地位相当于我们学习C语言的第一个源程序“Hello World!”只不过你需要提前掌握图像处理基础知识和pytorch的基本语法规则。
MNIST数据集构成:60000张训练数据集和10000张测试数据集。
每一张灰度图包含28*28个像素,且其通道数为1。MNIST数据集的内容为0-9数字,由不同的人手写在纸上后,经过大小标准化处理和中心化处理呈现为以下形式: (以8*8个图像组成为例)

官方介绍原文:MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
2.网络模型介绍
因为MNIST数据集已经经过中心化处理,且为单通道图像,所以没有必要选取大型的深度神经网络对其进行处理,这里选取了一个较为简单的神经网络模型对其进行训练: 
3.模型训练
新建神经网络模型:(新建文件model.py)
# 搭建mnist神经网络模型
import torch
from torch import nn
class mnist_Model(nn.Module):
def __init__(self):
super(mnist_Model, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(1, 32, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Flatten(),
nn.Linear(7*7*64, 128),
nn.Dropout2d(p=0.5),
nn.Linear(128, 10)
)
def forward(self, x):
x = self.model(x)
return x用MNIST手写数据集训练上述模型:(新建文件model.py,名称无所谓,注意import别引用错)
# 训练网络并测试
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import*
import time
writer = SummaryWriter("mnist_model") # tensorboard查看运行结果
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") #有gpu则用gpu进行训练,否则用cpu
# 读取数据并转化为tensor类型
train_data = torchvision.datasets.MNIST("./dataset", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.MNIST("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# 数据长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练集的长度为:{}".format(train_data_size))
print("测试集的长度为:{}".format(test_data_size))
# 定义一次取多少张图片
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 读取CNN并令CNN在gpu上运行
mnist_model = mnist_Model()
mnist_model = mnist_model.to(device)
# 定义损失函数并令其在gpu上运行
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 定义优化器和学习率
learning_rate = 0.01
optimizer = torch.optim.SGD(mnist_model.parameters(), lr=learning_rate)
# 定义训练前初值
train_step = 0
test_step = 0
epoch = 30
start_time = time.time()
for i in range(epoch): # i为训练轮数
print("第{}轮训练开始".format(i+1))
mnist_model.train() # 置为训练状态
for data in train_dataloader: # 取数据并令其在gpu上运行 一轮为一整个训练集经过一次网络
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device) # 将图片输入模型
outputs = mnist_model(imgs)
loss = loss_fn(outputs, targets) # 计算模型输出值和目标值的交叉熵
optimizer.zero_grad() # 优化器梯度置零
loss.backward() # 反向传播
optimizer.step() # 更新参数
train_step += 1
if train_step % 100 == 0: # 输出每一轮训练中的训练情况
end_time = time.time()
print("训练次数:{},Loss:{},所用时间:{}".format(train_step, loss, end_time-start_time))
mnist_model.eval() # 置为测试状态
test_loss = 0
test_accuracy = 0 # 定义损失值和正确率
with torch.no_grad(): # 测试集不进行训练
for data in test_dataloader: # 一轮为一整个测试集经过一次网络正向
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device) # 取数据并令其在gpu上运行
outputs = mnist_model(imgs) # 将图片输入模型
loss = loss_fn(outputs, targets) # 计算损失值
test_loss += loss # 计算每一轮的总损失值
accuracy = (outputs.argmax(1) == targets).sum() # 输出10个数中的最大值是否对应targets,是则为1,否则为0,最后总和
test_accuracy += accuracy
print("整体测试集上的Loss:{},Accuracy:{}".format(test_loss, test_accuracy/test_data_size)) # 输出正确率和损失值
writer.add_scalar("test_accuracy", test_accuracy/test_data_size, i+1)
test_step += 1
在上述代码中设置了30轮训练和测试,其在测试集上的正确率随轮数的变化关系 :
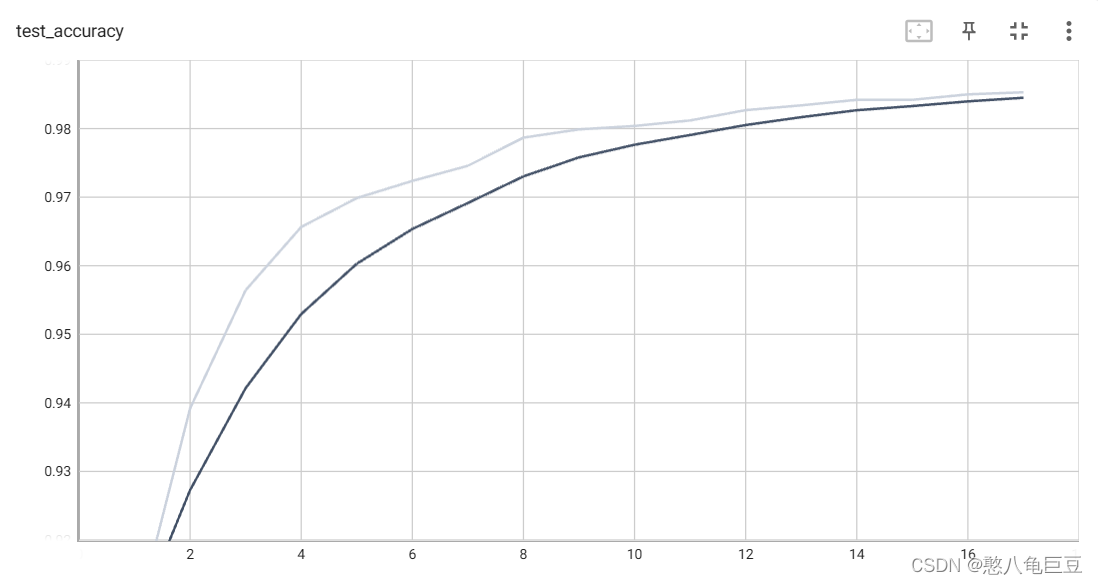
因为手写数字数据集经过中心化处理,且为单通道图像,其特征图较易提取,在第一轮训练结束后模型在测试集上的正确率便可达到90%,经过30轮训练可以达到99.2%.















 689
689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











