






随机变量
概率论中用大小写来表示随机变量与它的观测值
比如我扔了四次硬币,就得到四个观测值

概率密度函数
比如高斯分布(正态分布)

表示x在原点的取值概率比较大,在边缘取值概率比较小
离散概率分布

x取1的概率是0.2,…,在其他任何地方取值的概率为0
对于连续概率函数分布和离散概率分布,具有如下性质
连续概率分布对函数求积分值为1
离散概率分布对概率求和值为1

期望

随机抽样
即箱子里有3种颜色的球,我随机取出一个,观测其颜色值,再放回,就是一次随机抽样
state and action 状态 和 动作
比如你在玩超级玛丽

当前图片就是一个状态,在这个状态下你可以做一些动作,跳跃或者左右移动,我们把超级玛丽叫做 Agent

policy 策略 即为 π函数
根据观测到的状态,来做出决策,控制Agent的运动,
π函数是一个概率密度函数
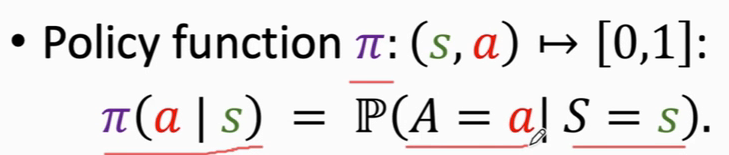
给定状态s 做出动作a 的概率密度

比如 π(left|s)=0.2 表示给出当前状态,agent向左的概率为 0.2
机器就会做一个随机抽样,以0.2的概率向左走,…,三种动作都有可能发生,但是向上的概率最大。强化学习的目的就是得到 π函数,有了这个π函数就能机器自己玩游戏;
π函数是概率密度函数,动作一定要有随机性
奖励 reward
agent每做出一个动作,我们就要给一个奖励,奖励由我们自己定义,奖励定义会影响强化学习的结果

强化学习的目标就是使得奖励总和尽量要高
状态转移 state transition
agent在当前状态下 做出一个动作就会进入一个新的状态
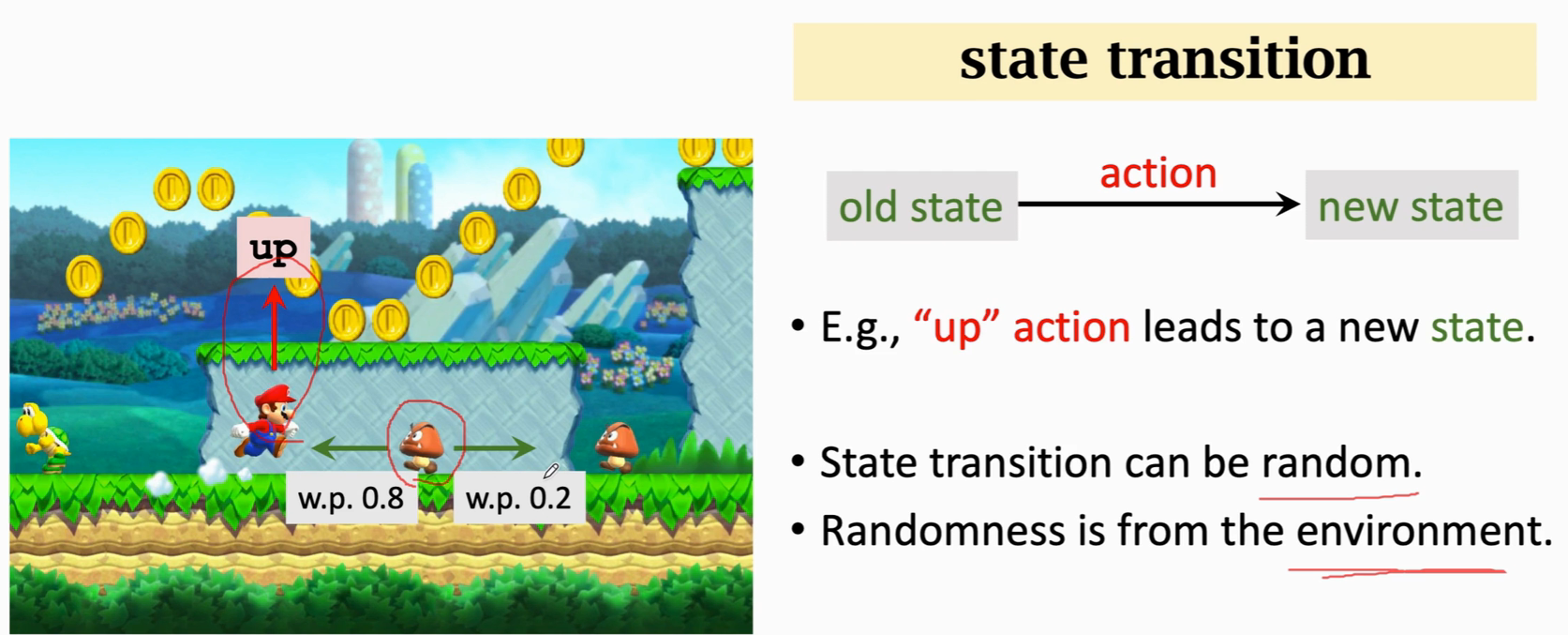
状态转移用 p函数表示,这是一个条件概率密度函数,我们是不知道的,由环境决定
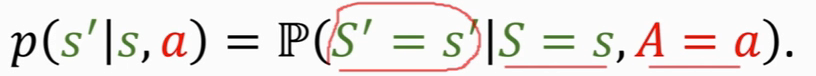
表示,在观测到状态s和动作a 的情况下,p函数输出状态变为s‘的概率
agent 与 environment的交互
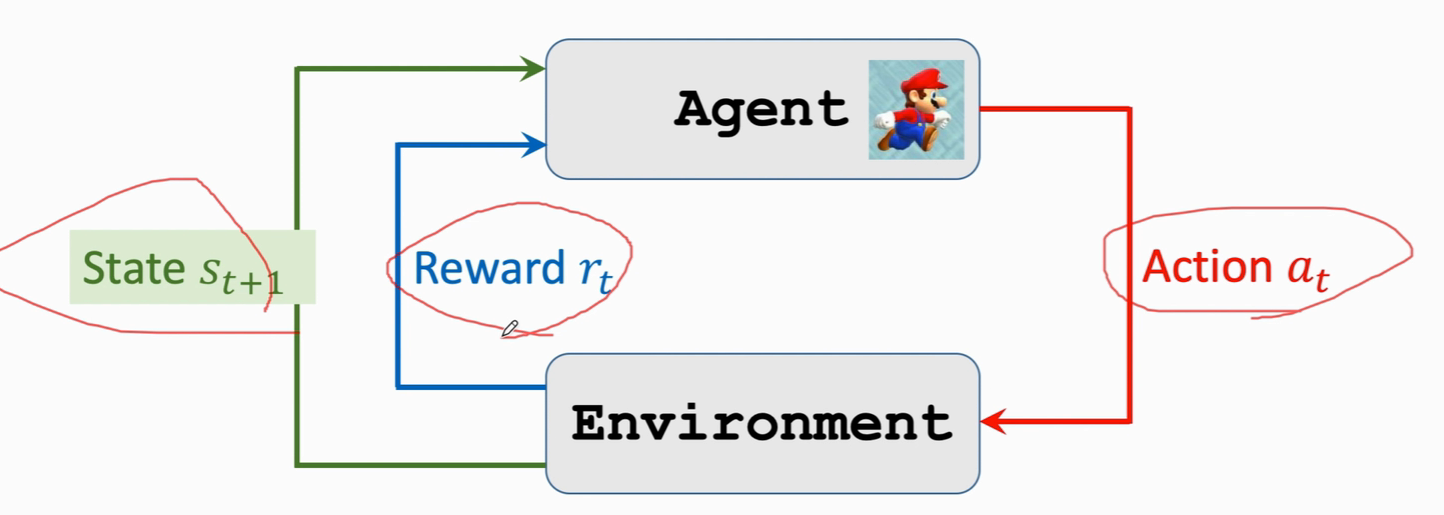
agent在状态s下 做出动作 a ,环境会更新下一个状态s’ 同时给agent一个奖励
强化学习中两种随机性的来源
- agent动作的随机性,由π函数(概率密度函数)随机抽样给出
- state transition 的随机性,由p函数抽样给出

循环过程:

直到打赢游戏,或死掉,则结束
结束后会得到一个序列

return

定义Ut 为Rt(当前的奖励)加上未来的所有奖励,直到游戏结束
Rt+1 的权重要小于Rt,未来的奖励要比当前的奖励价值更少

折扣回报

r为折扣率,位于[0,1]区间,当前时刻回报折扣率为1
Ut是一个随机变量,依赖于动作At,At+1,…和状态 St,St+1
因为我们不能事先知道Ut,但是我们可以预估Ut,对它求期望得到Qπ函数
动作价值函数
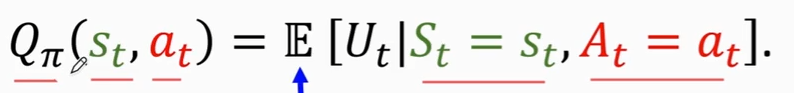
Qπ函数去掉了Ut中的随机性,保留了st、at,这两个值通过观测得到
Qπ 告诉我们,如果用π函数,在状态st下做动作at的结果是好还是坏,Qπ可以对动作a打分
最优动作价值函数:
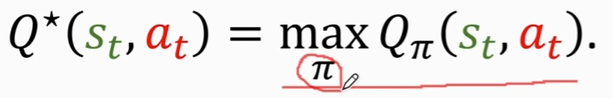
我们有无数种π函数,但是我们应该用最好的那种π函数,就是Qπ最大化的那个π
Q* 告诉我们在St下做动作at,结果是好还是坏
状态价值函数
Vπ(st)
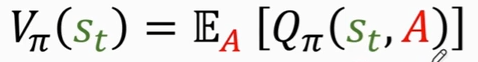
在Qπ函数中对A求期望,然后把动作A消掉
Vπ告诉我们当前的局势好不好,与π和s有关,可以评估我们是快赢了还是快输了
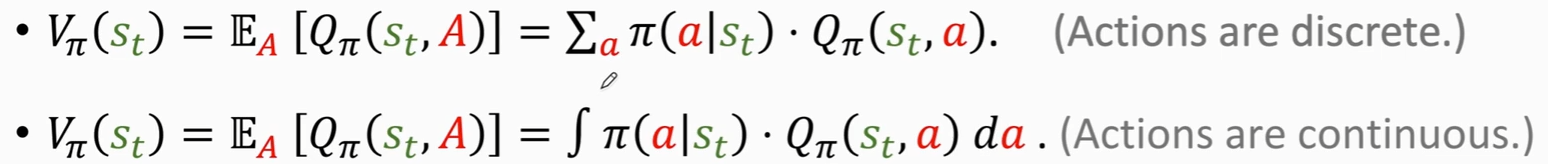
如何使用上面的概念进行控制agent
方式一:
- 首先学习π函数(策略学习),得到π(a|s)
- 观察到当前状态st,把它输入到 π函数,π函数会输出每一个动作的概率,并对这些动作进行随机抽样得到at; at~π(·|st)
- agent执行动作at
方式二:
-
学习函数Q*(价值学习),Q*(s,a)
-
观察到当前状态st,把它输入到 Q*函数,Q*会评估当前状态下所有动作的好坏,选取Q*输出最大值的那个动作at,(at在此是参数)

-
agent执行at
整个过程

















 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









