






强化学习
前言
这个博客主要讲强化学习的基本概念:state,action,reward,policy,return,action-value function,optimal action-value function,state-value function
随着强化学习的不断发展,强化学习的应用越来越多,很多人都开始学习强化学习,本文就介绍了强化学习的基本概念。
一、强化学习的基本概念
1.策略(policy)π:策略π根据观测到的状态做出决策,控制智能体(agent)做出动作(action)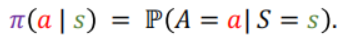
策略的一般定义为一个概率密度函数;
2.奖励(reward)Ri:reward是agent做出动作后,环境给出的奖励;
它与状态st和动作at有关;
3.回报(Return)Ut:
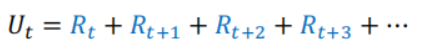
回报也就是未来的累积奖励,return定义为把t时刻开始往后的reward(rt+1,rt+2,…)都加起来,一直加到游戏结束时的最后一个奖励;
4.折扣回报(Discounted return ):
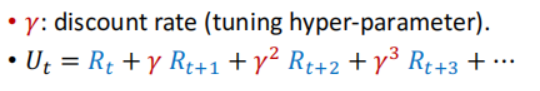
如果未来的奖励比较重要,r比较大;相反如果未来的奖励不重要,r会比较小;r是位于0和1之间的!
定义折扣的原因:未来的奖励没有现在有价值,比如我现在给你一百块和过十年后再给你一百块肯定不一样,大家都会选现在给一百块;
5.回报的随机性:
(1)agent的动作有随机性:policy函数π把状态st当做输入,输出一个概率分布,动作是从这个概率分布随机抽样得到的;
(2)下一个状态的随机性:给定当前的状态st和当前的动作at,状态转移函数p输出一个概率分布,环境从这个概率分布中随机抽样得到下一个状态s’;(状态转移函数p只有环境知道!)
状态转移函数p:
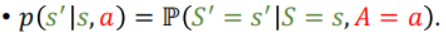
6.动作价值函数(Action-value function)Qt(s,a):

对随机变量Ut求期望得到了Qπ,怎么得到的:Ut是关于未来的动作和状态的函数,未来的动作和状态都具有随机性,未来的动作有policy函数π,未来的状态有状态转移函数p,求期望的过程中除了st和at,其余的随机变量都被积分积掉了,得到的了Qπ,st和at没有被积掉因为它们是被当做观测数值对待的,Qπ与策略π有关,还与状态st和动作at有关;
动作价值函数的作用:在使用策略π时,给定状态st下,做出动作at是好的还是坏的,有多好有多坏,即它的价值;
7.最优动作价值函数(Optimal action-value function):使用让Qπ(st,at)最大化的策略π,即对Qπ(st,at)使用最好的策略函数π,就去掉了策略函数π,因此与π就无关了;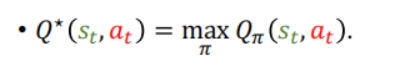
最优动作价值函数的作用:给定当前的状态st,对动作at进行评价;
8.状态价值函数(State-value function)Vπ(st):把动作价值函数Qt(s,a)的动作当做随机变量,对它求期望,从而就消掉了动作A,函数Vπ(st)只与状态st和策略π有关,与状态at无关!
状态价值函数的作用:评价当前状态的好坏,在策略π固定的情况下,状态st越好,Vπ(st)数值越大;
评价策略π的好坏,π越好,Vπ(st)平均值越大;
9.控制agent玩游戏的两种方式:
(1)学习策略函数π:观测到状态st,把状态st作为策略函数π的输入,策略函数输出每个动作的概率,这些概率随机抽样,得到at,然后agent执行动作at;
(2)学习最优动作价值函数Q*(s,a):观测到状态st,agent根据Q*(s,a)告诉我们处在状态st时,做动作at的好坏,对每一个动作进行评价,做能够让Q*(s,a)最大的动作;
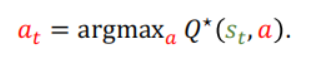
总结
以上就是今天要讲的内容,本文仅仅简单介绍了强化学习的基本概念,后续我会介绍一些关于强化学习算法如价值学习和策略学习等。
















 7381
7381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









