







Abstract:
问题
训练大规模的MoE模型依赖TPU,不向公众开放。
设计
基于pytorch的分布式MOE训练系统:
- 提供分层接口,模型设计更加灵活,适应不同的应用。
- 训练速度优化。
- 支持多节点的多个gpu放置不同的expert,允许专家数量随gpu数量线性增加。
Introduction
- NLP提高大模型需求。
- MoE专家激活具有稀疏性,能够在不显著增加计算量的情况下将模型大小扩大几个数量级,因此当expert数目扩展到几个专家时,MoE 的 all2all通信模式不平衡使算法和系统的协同设计变得复杂àpytorch、TensorFlow不能直接支持MoE。
- MoE传统结构如下:
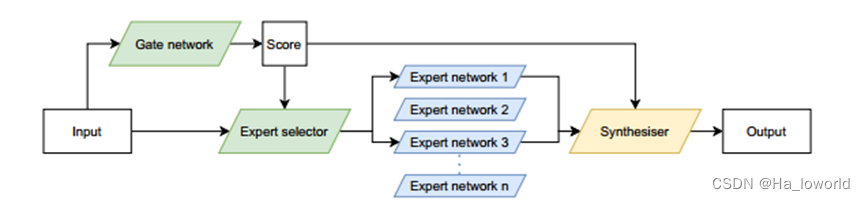
MoE系统的输入通过 门控网络给出每个expert的适配得分,然后通过expert 选择器选择工作的expert,最后的输出进行组合合成作为输出。
- FasterMoE设计目标:
- Easy to use:设计用户友好的界面定义MoE层,并支持语言模型训练系统Megatron-LM
- Flexible:便于自定义gate、expert network。
- Efficient:为Transformer集成高度优化的前馈层FFN。
- Scalable:支持通过在多个节点上跨多个gpu进行训练(使用NCCL)来扩展MoE的模型大小。
- 相对于传统的单gpu pytorch实现,FastMoE专注于efficient和Scalable。
Mixture of Experts
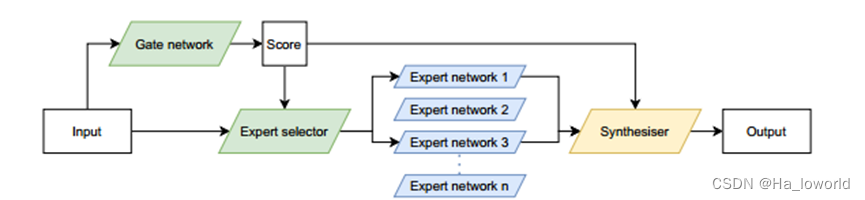
Expert各司其职,Gate负责根据输入为每一个专家评分,根据评分和选择专家的算法(因模型而异)来选择激活的专家来对输入进行处理。最终专家的输出结合gate 给出的score根据一定的算法组合成最终的输出。
-tips:约束 expert在相同的向量空间中取相同的输入和输出,
-tips:举例,选择得分最高的前k为专家,输出的结合上,利用得分作为专家产出的权重,加权到最终的输出中(该方法因为梯度可以通过分数传播,因此使训练门网络变得容易一些)。
目前的MoE训练系统:
Gshard系统:每个tpu上有一个expert,在2048个TPU上训练语言模型,支持大规模训练模型,但是该系统不公开
Pytorch:不支持在多个gpu上进行训练。
FastMoE系统设计:
不同模型支持:
关键内容总结:支持任意的神经网路、对于Transformer有FFN的高度优化、支持Pytorch和Megatraon-LM。
支持使用任意的神经网络expert,FastMoE的FMoE接口以任意神经网络的构造函数作为输入来构造expert实例。其中对于expert输出批次的次序与输入数据批次对应,使得专家模块的实现与MoE体系结构解耦(设计expert时无需考虑MoE),使得开发人员可以专注于设计自己的神经网络。
Expert_fn函数使用专家模块进行前向计算(forward),因此可以重载该函数以进一步定制MoE的行为。
支持将多个专家放在同一个worker上,不必一个专家一个worker,使得专家数量的配置空间更加灵活。
高度优化的FFN for Transformer,FastMoE提供了一个标准的高性能FFN实现,更好的支持MoE训练Transformer。
对于多个expert在一个worker上时,简单的实现是简单循环遍历这些expert串行计算。FastMoE中,专用的FMoELinear模块优化全连接层的并行执行,保持一个可用的硬件资源池,并行的应用expert计算。
允许现有的传统的训练网络,支持pytorch和Megatron-LM。
分布式增大模型容量
容纳大量的专家群体并且并行训练是一种扩大模型容量的有效途径。但该方法主要面对困难时gpu之间、节点之间的复杂数据传输是困难的,需要计算机体系结构和并行编程方面的专业知识。
FastMoE支持将专家分步在多个节点上的多个worker上,并且输入数据交换的细节隐藏在FMOE接口中à模型开发人员只需要为单个expert编写代码,每个expert都会从FastMoE中获取所有输入数据,模型开发人员不必考虑跨worker通信的实现细节。
Tips:不必你去考虑跨gpu、节点并行计算、数据传输的实现细节。
分布式的一个主要问题:分配给每一个worker节点的所有expert输入样本数目变化很大,在gate输出之前不清楚传入样本的数量。但是分配缓冲区(放置输入样本)需要清楚样本的数量。因此处理策略为:计算每个worker分配给每个expert的数量,worker之间交换数据,这样就会得到每个worker将会接受的输入样本数量,因此就可以分配缓冲区,再交换数据,并且这些数据在整个训练迭代过程中可以重复使用。(个人理解)对应的流程:
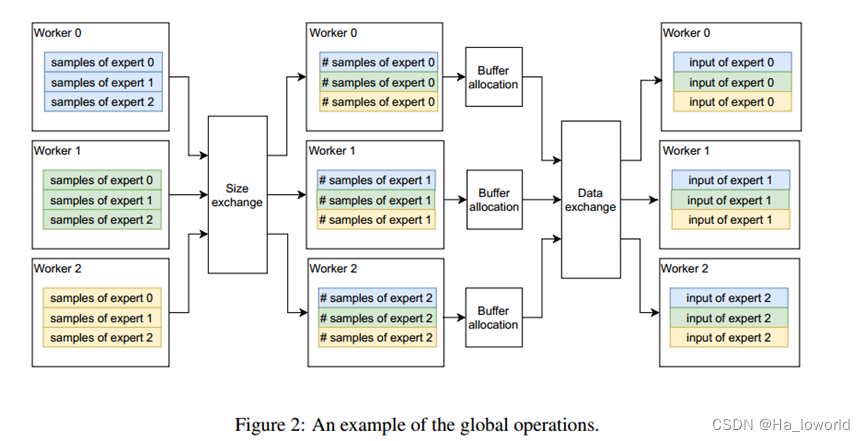
异构性问题。网络的不同部分可能被复制到不同worker的工作节点,因此分布式模块必须确定是否需要同步某个参数的梯度、和哪些worker节点进行同步。FastMoE采用数据并行通信组标签,对于每个参数引入一个标签,表明属于哪个通信组以解决异构性带来的同步性问题。
标签的设置举例:一共有三种:
- world全局标签,代表梯度应该与所有其他worker节点同步,如gate网络。
- data parallel,与模型并行组正交的数据并行组内的工作节点同步,如注意力层。
- none,不同步任何工作节点,如worker节点(服务于独特的expert网络)。
Tips:
模型并行:大型神经网络划分成几个部分,每个部分由不同的工作节点处理,这些工作节点之间可能需要进行横向的同步(同一层级的计算单元),涉及到不同部分之间的信息传递和同步。
数据并行:整个模型上训练但是将不同的数据分配给不同的工作节点。数据并行中,工作节点需要纵向同步(不同层次或者不同任务之间的同步操作),以确保每个节点的参数梯度能够被整个模型共享。
高性能优化:
FFN:前馈神经网络
GeMM:矩阵操作乘(General Matrix Multiplication)
GeMV:矩阵向量乘
单个节点上的MoE计算性能十分重要,决定系统扩展到任何规模的理论上限。
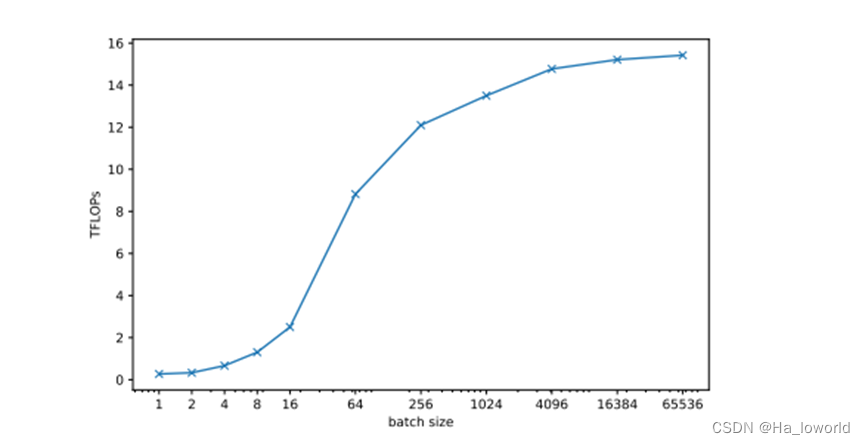
该部分讲述在MoE中对样本进行批处理能够更加充分的利用硬件资源。
总结:
- 用于接收 网络构造函数的接口,以构造为expert,能够让用户能够专注于设计自己的网络,支持多种不同类型的网络。
- 接口的实现为用户隐藏了不同worker之间数据的传递跨gpu、节点并行计算、数据传输的实现细节。
- 利用 标签 解决了分布式的异构性问题
- 输入数据的 批处理、流处理 提高硬件使用效率。















 1366
1366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









