









1.创建一个工程
scrapy startproject 工程名D:.
│ scrapy.cfg
│
└─firstSpider
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ __init__.py
│
└─spiders
__init__.py(其中蓝色为文件夹,绿色为文件)
各个主要文件的作用:(不能删!!)
- scrapy.cfg 项目的配置文件
- firstSpider项目的Python模块,将会从这里引用代码
- items.py项目的目标文件
- pipelines.py项目的管道文件
- settings.py项目的设置文件
- spiders存储爬虫代码目录
- __init__.py项目的初始化文件
2.定义目标数据的字段
在items.py文件中进行写代码
进入firstSpider文件中,找到items.py文件,输入以下2行代码:(字段名自取)
import scrapy # 定义目标数据的字段 class FirstspiderItem(scrapy.Item): title = scrapy.Field() # 章节名 link = scrapy.Field() # 各章节的链接
3.编写爬虫代码
在项目根目录(即包含firstSpider文件夹、scrapy.cfg文件)下,在cmd窗口输入以下命令,创建爬虫文件.
scrapy genspider 文件名 待爬取网页的主机地址比如:scrapy genspider novelSpider www.shucw.com
在你的spiders目录下就会增加一个爬虫文件
文件内容:
import scrapy class novelSpider(scrapy.Spider): name = 'novelSpider' # 爬虫名称 allowed_domains = ['www.shucw.com'] # 待爬的网页的主机名 start_urls = ['http://www.shucw.com/'] # 要爬取的网页【可以修改】 def parse(self, response): pass


4.在爬虫文件novelSpider文件中写入爬虫代码
爬虫代码:就在parse方法中写
import scrapy
from bs4 import BeautifulSoup
from firstSpider.items import FirstspiderItem #导包
# 全为采用Tap键缩进
class NovelspiderSpider(scrapy.Spider):
name = 'novelSpider' # 爬取识别名称
allowed_domains = ['www.shucw.com'] # 爬取网页范围
start_urls = ['http://www.shucw.com/html/13/13889/'] #起始url
def parse(self, response):
soup = BeautifulSoup(response.body,'lxml')
titles = [] # 用来保存章节标题(用list保存)
for i in soup.select('dd a'):
titles.append(i.get_text()) # 依次添加进titles中
links = [] # 用来保存各章节的链接
for i in soup.select('dd a'):
link = "http://www.shucw.com" + i.attrs['href']
links.append(link)
for i in range(0,len(titles)):
item = FirstspiderItem()
item["title"] = titles[i]
item["link"] = links[i]
yield item # 返回每一次item
5.在pipelines.py文件中将每一个item保存到本地
from itemadapter import ItemAdapter #全为采用Tab键,防止空格和Tab键混杂 # 管道文件,负责item的后期处理或保存 class FirstspiderPipeline: # 定义一些需要初始化的参数 def __init__(self): # 这里写入的文件地址:是在根目录下的article文件夹里【需手动创建】 self.file = open("article/novel.txt","a") # 管道每次接受到item后执行的方法 def process_item(self, item, spider): content = str(item) + "\n" self.file.write(content) #写入数据到本地 return item # 当爬取结束时执行的方法 def close_spider(self,spider): self.file.close()
不仅要在管道pipelines.py文件中写代码,还有在settings.py代码中进行设置
打开管道优先级【0-1000】【数字越小,优先级越高】

6.运行爬虫程序
在项目根目录下,在cmd窗口输入以下命令,创建爬虫文件.
scrapy crawl 爬虫文件名比如:scrapy crawl novelSpider
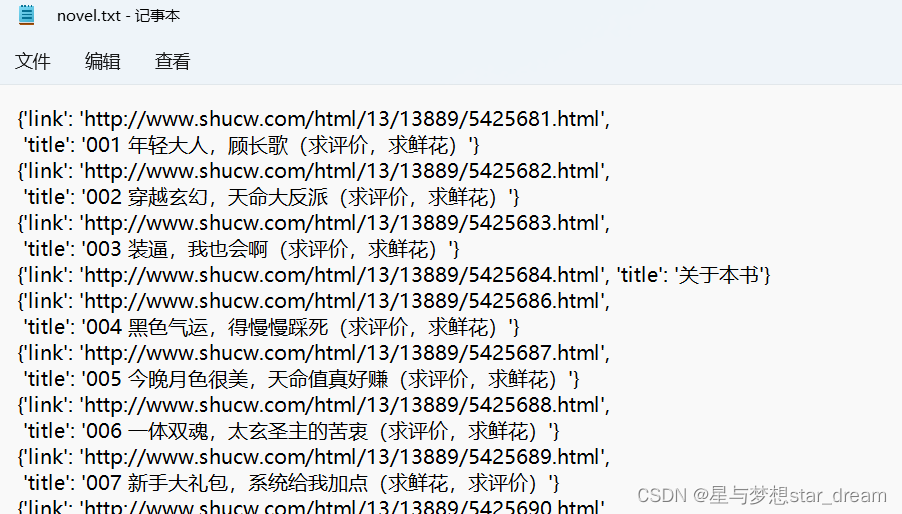
我们回到根目录,进入article文件夹,打开novel.txt,我们爬虫的信息就获取到了
7.如何进行post请求和添加请求头
在爬虫文件(youdaoSpider.py)中输入以下代码【这是另外一个工程】
import scrapy import random class TranslateSpider(scrapy.Spider): name = 'translate' allowed_domains = ['fanyi.youdao.com'] # start_urls = ['http://fanyi.youdao.com/'] agent1 = "Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 " \ "Mobile/10A5376e Safari/8536.25 " agent2 = "Mozilla/5.0 (Windows NT 5.2) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30" agent3 = "Mozilla/5.0 (Linux; Android 9; LON-AL00 Build/HUAWEILON-AL00; wv) AppleWebKit/537.36 (KHTML, like Gecko) " \ "Version/4.0 Chrome/76.0.3809.89 Mobile Safari/537.36 T7/11.25 SP-engine/2.17.0 flyflow/4.21.5.31 lite " \ "baiduboxapp/4.21.5.31 (Baidu; P1 9) " agent4 = "Mozilla/5.0 (Linux; Android 10; MIX 2S Build/QKQ1.190828.002; wv) AppleWebKit/537.36 (KHTML, like Gecko) " \ "Version/4.0 Chrome/76.0.3809.89 Mobile Safari/537.36 T7/12.5 SP-engine/2.26.0 baiduboxapp/12.5.1.10 (Baidu; " \ "P1 10) NABar/1.0 " agent5 = "Mozilla/5.0 (Linux; U; Android 10; zh-CN; TNY-AL00 Build/HUAWEITNY-AL00) AppleWebKit/537.36 (KHTML, " \ "like Gecko) Version/4.0 Chrome/78.0.3904.108 UCBrowser/13.2.0.1100 Mobile Safari/537.36 " agent6 = "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/533.21.1 (KHTML, like Gecko) Version/5.0.5 " \ "Safari/533.21.1 " agent_list = [agent1, agent2, agent3, agent4, agent5, agent6] header = { "User-Agent":random.choice(agent_list) } def start_requests(self): url = "https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule" # 向队列中加入一个带有表单信息的post请求 yield scrapy.FormRequest( url = url, formdata={ "i": key, "from": "AUTO", "to": "AUTO", "smartresult": "dict", "client": " fanyideskweb", "salt": "16568305467837", "sign": "684b7fc03a39eebebf045749a7759621", "lts": "1656830546783", "bv": "38d2f7b6370a18835effaf2745b8cc28", "doctype": "json", "version": "2.1", "keyfrom": "fanyi.web", "action": "FY_BY_REALTlME" }, headers=header, callback=self.parse ) def parse(self, response): pass
本文彩蛋部分:
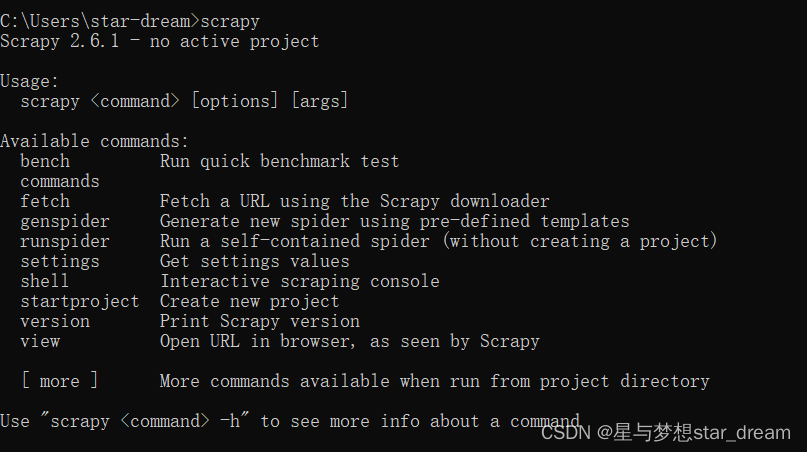
在cmd中输入scrapy,可以了解各个命令
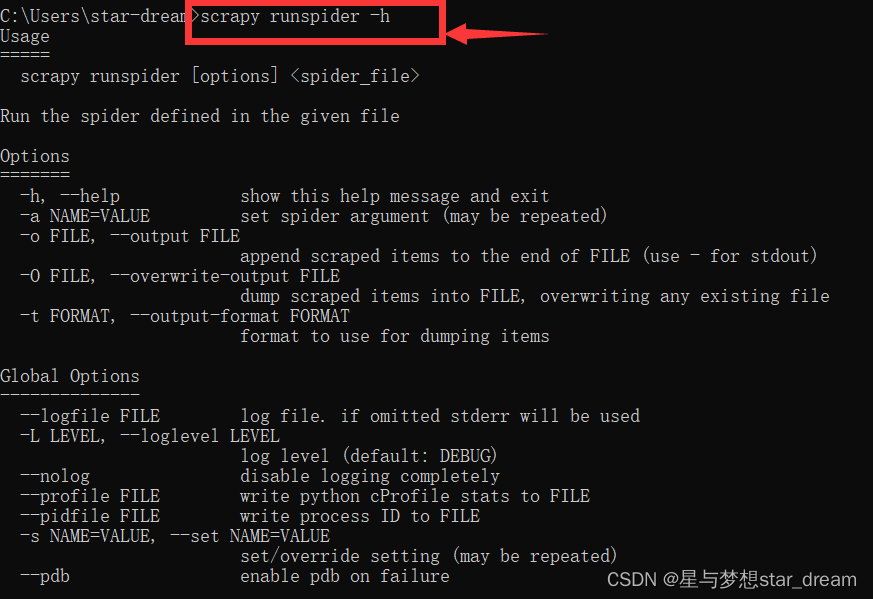
如果不知道这些命令的含义,可以在后面加上-h,获取详细信息
就比如:scrapy runspider -h
完
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











