







最大池化的目的在于保留原特征的同时减少神经网络训练的参数,使得训练时间减少。相当于1080p的视频变为了720p
官网介绍 torch.nn — PyTorch 1.11.0 documentation
最常用的时MAXPOOL2D
最常用的是下采样,其中参数:
kernel_size:设置取最大值的窗口,类似于卷积层的卷积核,如果传入参数是一个int型,则生成一个正方形,边长与参数相同;若是两个int型的元组,则生成长方形。
stride:步径,与卷积层不同,默认值是kernel_size的大小。
padding:和卷积层一样,用法类似于kernel_size。
dilation:控制窗口中元素步幅的参数,就是两两元素之间有间隔
ceil_mode:ture是为ceil,false为floor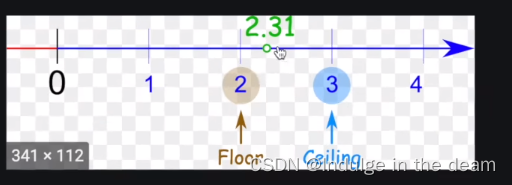

通过对一个数组操作,获取其平均采样值:
import torch
from torch import nn
from torch.nn import MaxPool2d
# 最大池化要使用浮点数
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1,]],dtype=torch.float32)
# 改变矩阵的尺寸 -1代表xxx有计算机计算
input=torch.reshape(input,(-1,1,5,5))
print(input.shape)
class LL(nn.Module):
def __init__(self):
super(LL, self).__init__()
self.maxpool =MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output=self.maxpool(input)
return output
ll=LL()
output=ll(input)
print(output)
ceil是向上取整,floor是向下取整,默认为ceil_mode=False
当ceil_mode=False时:

当ceil_mode=True时:

如果对图像数据集进行池化,相关的代码操作:
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader =DataLoader(dataset,batch_size=64)
class LL(nn.Module):
def __init__(self):
super(LL, self).__init__()
self.maxpool1 =MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output=self.maxpool1(input)
return output
ll=LL()
writer=SummaryWriter("logs_maxpool")
step=0
for data in dataloader:
imgs,targets = data
writer.add_images("input",imgs,step)
output=ll(imgs)
writer.add_images("output",output,step)
step=step+1
writer.close()输出结果:
















 1638
1638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









