








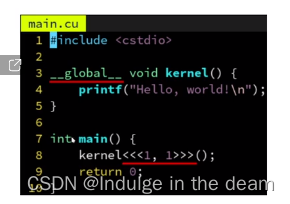
定义函数kernel,前面加上_ _global_ _修饰符,让他可以在GPU上执行

调用kernel时,使用kernel<<<1,1>>>();这样的三重括号。因为GPU和CPU是异步通信的,如果需要执行GPU上的任务可以调用cudaDeviceSynchronisze();让cpu陷入等待,等GPU执行任务后再返回;


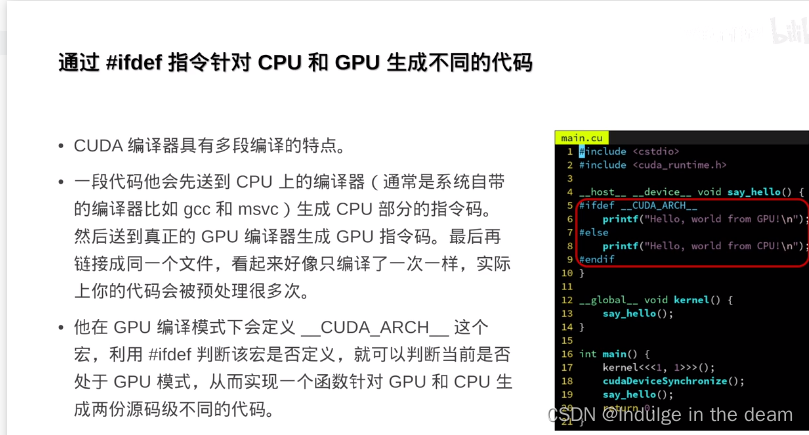
__device__定义在GPU上,而__host__则相反,将函数定义在CPU上。








也可以指定多个版本号,用分号分隔







SIMD(SingleInstruction Multiple Data)是单指令流多数据技术,是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。在微处理器中,单指令流多数据流技术则是一个控制器控制多个平行的处理微元,例如Intel的MMX,SSE,AVX,FMA以及AMD的3D Now!技术和ARM的NEON技术。通过这些技术,我们可以实现通过一个CPU指令,对4对浮点数进行并行计算。




就是说可以把一个kelper的值算出来后给另外一个kelper使用
内存管理:

就是说可以把一个kelper的值算出来后给另外一个kelper使用





所以有解决方案:

由于在GPU和CPU分配内存比较麻烦所以:


数组:





c++封装








数学运算



优化:

CUDA官方thrust库






原子操作



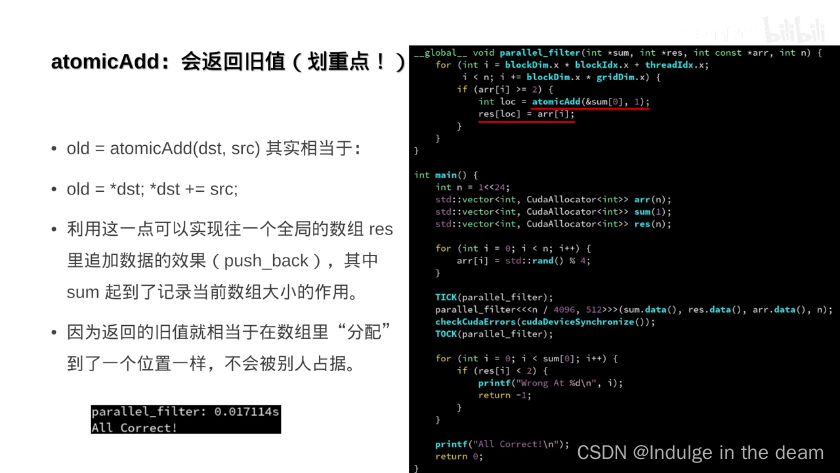






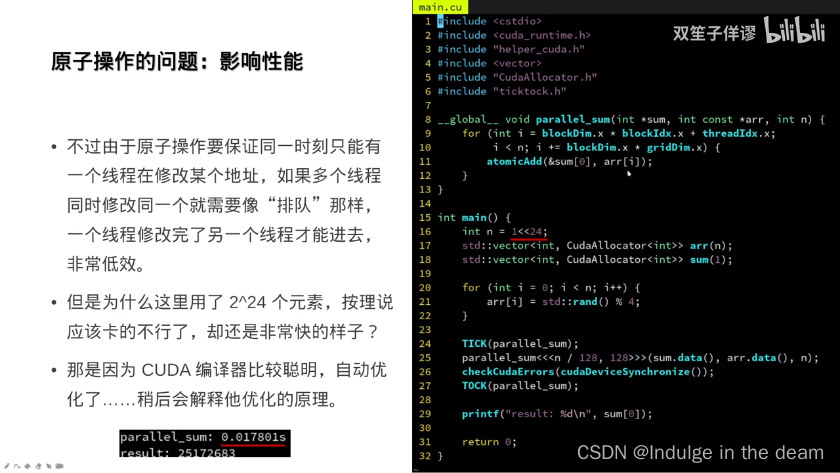
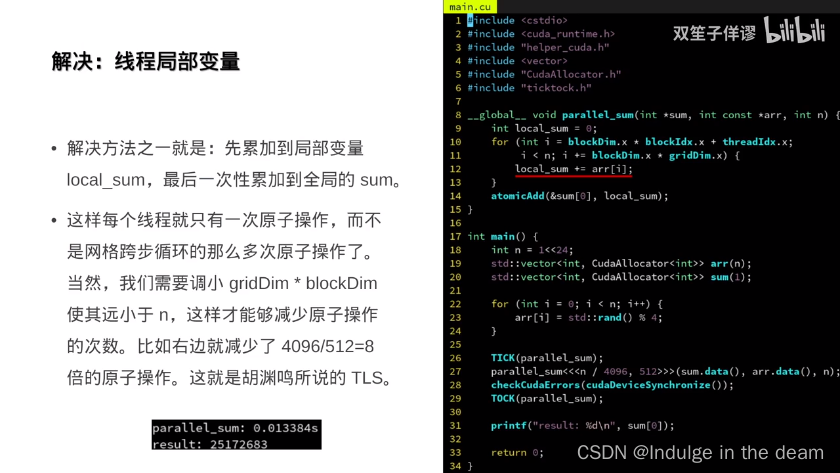
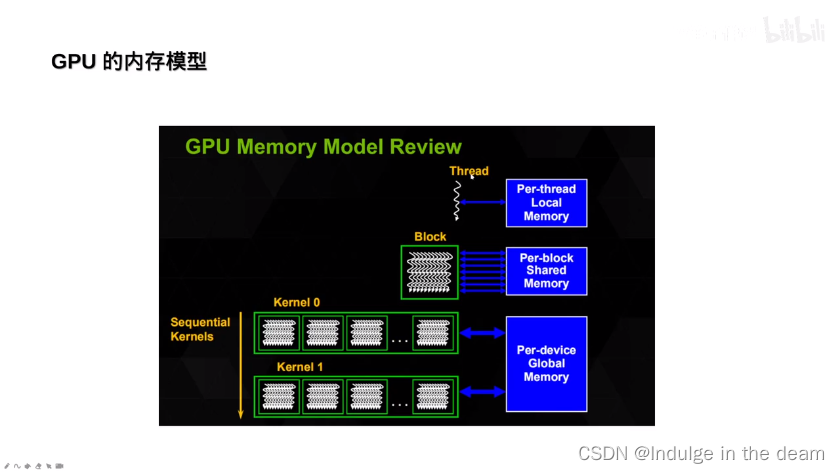
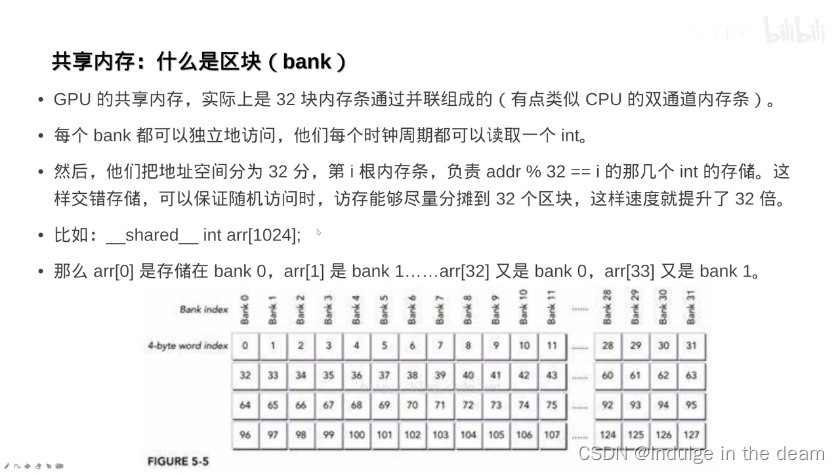
板块与共享内存:
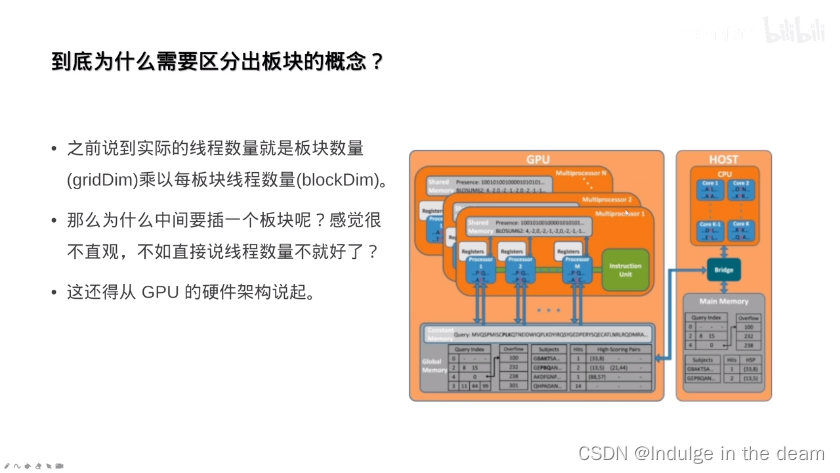








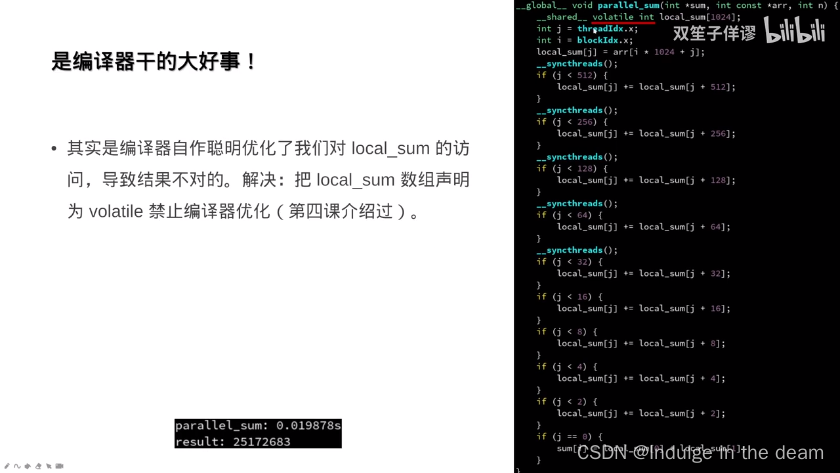



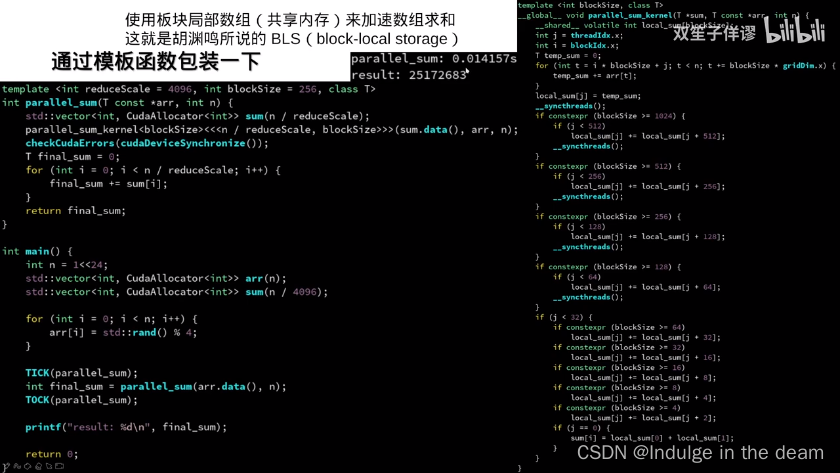
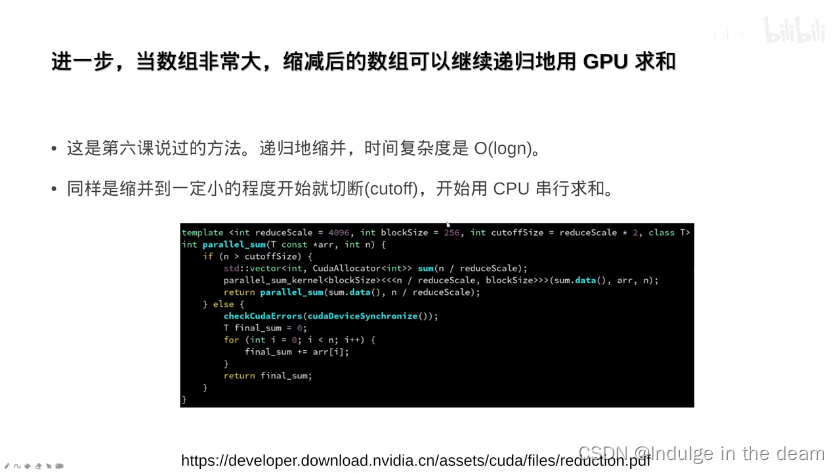


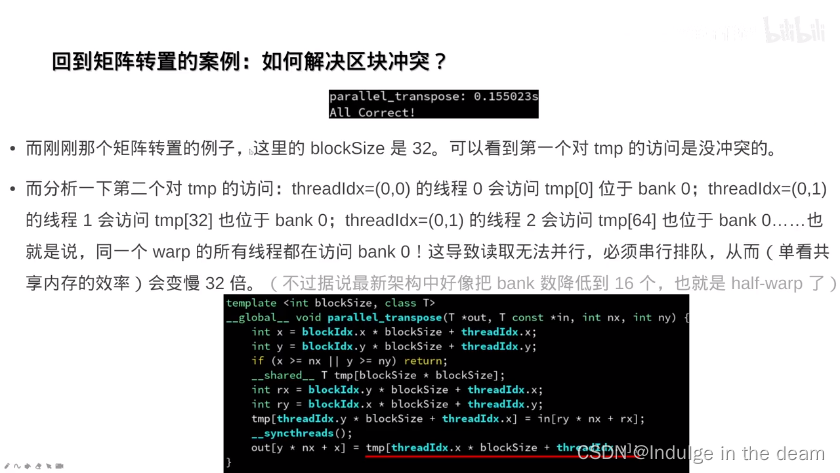
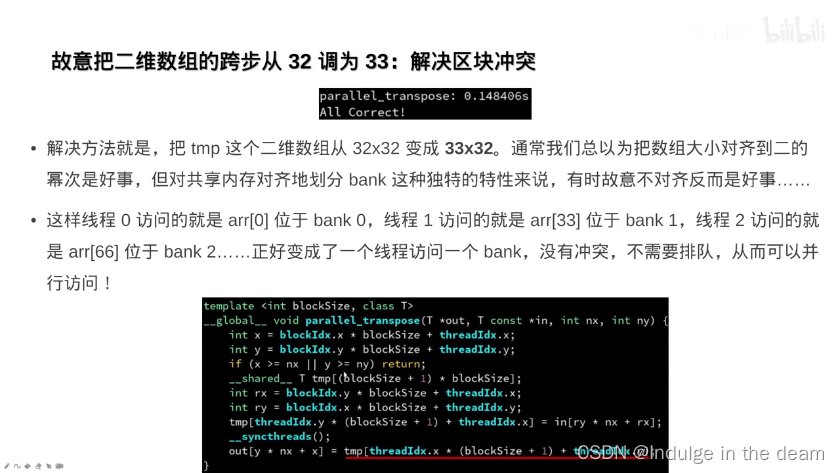
共享内存的进阶用法












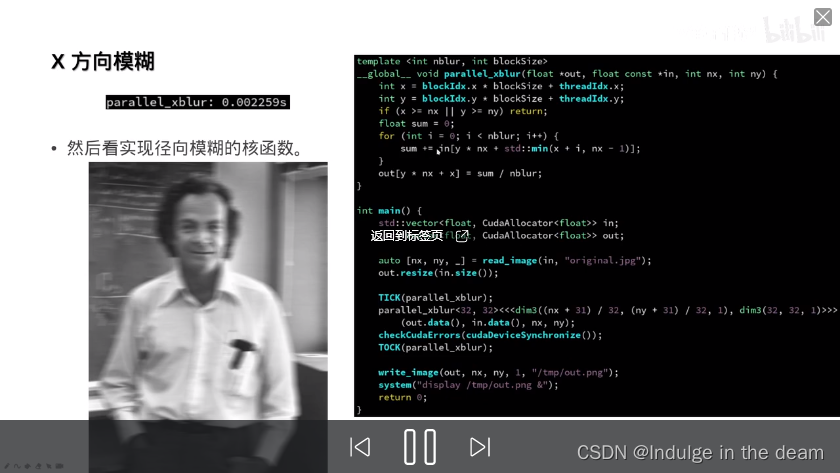
插桩操作实战:



















 546
546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









