






Embedding技术具有许多优势。首先,它可以完成语义表示,将具有相似语义的数据点映射到接近的位置,这对于很多自然语言处理任务非常有用。其次,Embedding可以完成降维,降低数据的维度,减少计算量,提高计算效率。此外,Embedding还可以学习语义关系,捕捉到数据之间的内在联系,为后续的机器学习任务提供更有用的信息。
只有当我们使用对位置不敏感(position-insensitive)的模型对文本数据建模的时候,才需要额外使用positional encoding。
什么是对位置敏感的模型??什么又是对位置不敏感的模型??
如果模型的输出会随着输入文本数据顺序的变化而变化,那么这个模型就是关于位置敏感的,反之则是位置不敏感的。
用更清晰的数学语言来解释。设模型为函数y=f(x),其中输入为一个词序列x={x1,x2,...,xn},输出结果为向量y。对x的任意置换x′={xk1,xk2,...,xkn},都有
f(x)=f(x′)
则模型f是关于位置不敏感的。
在我们常用的文本模型中,RNN和textCNN都是关于位置敏感的,使用它们对文本数据建模时,模型结构天然考虑了文本中词与词之间的顺序关系。而以attention为核心的transformer则是位置不敏感的,使用这一类位置不敏感的模型的时候需要额外加入positional encoding引入文本中词与词的顺序关系。
对于transformer模型的positional encoding有两种主流方式:
绝对位置编码

现在普遍使用的一种方法 Learned Positional Embedding编码绝对位置,相对简单也很容易理解。直接对不同的位置随机初始化一个postion embedding,加到word embedding上输入模型,作为参数进行训练。
相对位置编码
使用绝对位置编码,不同位置对应的positional embedding固然不同,但是位置1和位置2的距离比位置3和位置10的距离更近,位置1和位置2与位置3和位置4都只相差1,这些关于位置的相对含义模型能够通过绝对位置编码get到吗?使用Learned Positional Embedding编码,位置之间没有约束关系,我们只能期待它隐式地学到,是否有更合理的方法能够显示的让模型理解位置的相对关系呢?
所以就有了另一种更直观地方法——相对位置编码。下面介绍两种编码相对位置的方法:Sinusoidal Position Encoding和Complex embedding。
1. Sinusoidal Position Encoding
使用正余弦函数表示绝对位置,通过两者乘积得到相对位置:

这样设计的好处是位置pos+k的positional encoding可以被位置pos线性表示,反应其相对位置关系。
Sinusoidal Position Encoding虽然看起来很复杂,但是证明pos+k可以被pos线性表示,只需要用到高中的正弦余弦公式:

对于位置pos+k的positional encoding



2. Complex embedding
由于相对位置编码无法区别前后关系,为了更好的让模型捕获更精确的相对位置关系,比如相邻,前序(precedence)等,ICLR 2020发表的文章《Encoding Word Oder In Complex Embeddings》使用了复数域的连续函数来编码词在不同位置的表示。
不管是Learned Postional Embdedding还是Sinusoidal Position Encoding,某个词wj在pos位置上的表示为其word embedding加上对应位置的embedding,即:
(12)f(j,pos)=fwe(j)+fpe(pos)
fpe(⋅)同word embedding fwe(⋅)都是从整数域N到实数域RD的一个映射。
对于word embedding来说,这样的设计是合理的。因为不同词的index是独立的,仅和我们具体使用的词典怎么排序有关系,某个词是否在另外一个词前面或者相邻没有任何的信息。但是位置的index并不是满足独立的假设,其顺序关系对文本的正确理解有非常重要的影响。
所以,为了解决pos index的依赖问题(position-insensitive problem),文章使用了关于位置的连续函数来表征词wj在pos的表示,即:

 简单来说,complex embedding不仅具有相对位置编码的特性,还能区别前后关系。
简单来说,complex embedding不仅具有相对位置编码的特性,还能区别前后关系。
具体的原因可以看如下的例子:
对于一个给定的三元组 r(s,o)(注:即主语 s 和宾语 o 具有关系 r),这个三元组的 score 可以通过对于 s,r,o 的表示向量之间的多线性(multi-linear)乘积计算得到。以往工作的问题在于不能很好地处理非对称关系,因为实数向量之间的点积计算是具有交换性的,即如果实数表示下的 r(s,o) 成立,那么 r(o,s) 也必然成立。所以本文提出了一个基于复数表示的方法,因为复数之间的埃尔米特乘积(Hermitian dot product)是不具有交换性的,具体做法如下:

每个实体和关系都用一个复数向量表示,每个三元组的 score function 定义如下:

可以理解为如果用复数域的连续函数来编码词在不同位置的表示,下列等式可能并不成立。

3.RoPE
旋转编码(Rotational Encoding)是一种将序列数据中的相对或绝对位置信息编码进模型输入的方法,它通过将每个位置的嵌入向量(embedding)乘以一个固定或可学习的旋转矩阵,使得模型能够捕捉到序列中不同位置之间的关系,从而增强模型对序列顺序的感知能力。简而言之,旋转编码通过在嵌入向量上应用旋转变换,为深度学习模型提供了一种感知序列位置的有效手段。
- RoPE通过绝对位置编码的方式实现相对位置编码,综合了绝对位置编码和相对位置编码的优点。
- 主要就是对attention中的q, k向量注入了绝对位置信息,然后用更新的q,k向量做attention中的内积就会引入相对位置信息了。
参考这个Rotary Position Embedding (RoPE, 旋转式位置编码) | 原理讲解+torch代码实现_旋转位置编码-CSDN博客
关于Rope其实也是用复数来来编码词在不同位置的表示。
总结一下理想的位置编码应该满足:
- 为每个字输出唯一的编码;
- 不同长度的句子之间,任何两个字之间的差值应该保持一致;
- 编码值应该是有界的。
4.T5 bias
T5模型使用的是一种相对位置编码方法,它通过在自注意力(Self-Attention)机制中引入一个可学习的偏置项来实现。这个偏置项与query和key之间的距离相关,用于调整注意力分数,从而使模型能够捕捉序列中不同位置之间的相对关系。
T5 bias的优势在于它允许模型通过训练学习到最优的位置偏差,这使得模型能够更好地适应特定的任务和数据集。
ALiBi
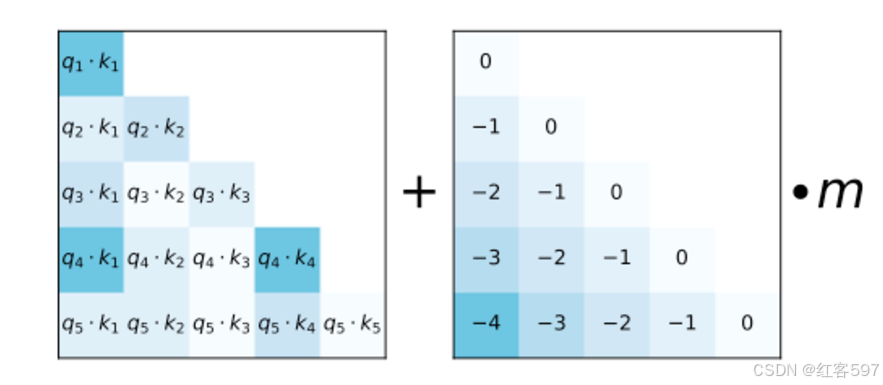
ALiBi根据token之间的距离给attention score 加一个预设的偏置矩阵,比如q和k相对位置差一就加上-1的偏置,两个token的距离越远则负数越大。并且由于注意力机制一般有多个head,针对每个head会乘上一个预设好的斜率项。因而原来的注意力矩阵为A,叠加了Alibi后为A+Bxm

代码实现
class ModelConfig:
def __init__(self) -> None:
self.num_layers = 6
self.max_len = 128
self.num_heads = 8
self.hidden_dim = 256 # num_heads * head_dim = 8 * 32
self.dropout_p = 0.1
self.is_causal = True
class MHA(nn.Module):
def __init__(self, config: ModelConfig) -> None:
super().__init__()
self.num_heads = config.num_heads
self.scale = 1 / torch.sqrt(torch.tensor(config.hidden_dim))
self.register_buffer('m', self.get_alibi_slope(config.num_heads))
self.is_causal = config.is_causal
if config.is_causal:
self.register_buffer('mask', torch.tril(torch.ones(1, 1, config.max_len, config.max_len)))
self.qkv = nn.Linear(config.hidden_dim, 3 * config.hidden_dim, bias=False)
self.dropout = nn.Dropout(config.dropout_p)
def get_alibi_slope(self, num_heads): # 即 m
x = (2 ** 8) ** (1 / num_heads)
return torch.tensor([1 / x ** (i+1) for i in range(num_heads)]) # eg: tensor([0.5000, 0.2500, 0.1250, 0.0625, 0.0312, 0.0156, 0.0078, 0.0039])
def get_relative_positions(self, seq_len):
pos = torch.arange(seq_len)
return pos[None, :] - pos[:, None] # [sl, sl]
def forward(self, x):
bs, seq_len, _ = x.shape
query_state, key_state, value_state = self.qkv(x).chunk(3, dim=-1) # 每个都是 [bs, sl, hidden]
query_state = query_state.view(bs, seq_len, self.num_heads, -1) # [bs, sl, heads, head_dim]
query_state = query_state.transpose(1, 2) # [bs, heads, sl, head_dim] 即 Q
key_state = key_state.view(bs, seq_len, self.num_heads, -1)
key_state = key_state.permute(0, 2, 3, 1) # [bs, heads, head_dim, sl] 即 K^T
value_state = value_state.view(bs, seq_len, self.num_heads, -1)
value_state = value_state.transpose(1, 2) # [bs, heads, sl, head_dim] 即 V
alibi_bias = self.m.unsqueeze(-1).unsqueeze(-1) * self.get_relative_positions(seq_len) # [heads, sl, sl]
attn_score = torch.matmul(query_state, key_state) * self.scale + alibi_bias # [bs, heads, sl, sl]
if self.is_causal:
attn_score = attn_score.masked_fill(self.mask[:, :, :seq_len, :seq_len] == 0, float('-inf'))
attn_probs = F.softmax(attn_score, dim=-1)
out = torch.matmul(attn_probs, value_state) # [bs, heads, sl, head_dim]
out = out.transpose(1, 2).reshape(bs, seq_len, -1) # [bs, sl, hidden_dim]
out = self.dropout(out)
return out
if __name__ == '__main__':
config = ModelConfig()
model = MHA(config)
bs = 2
seq_len = 16
embed_dim = 256
x = torch.randn([bs, seq_len, embed_dim])
y = model(x)优点:不仅优化了模型的相对位置感知能力,还显著提升了模型在处理超出训练时最大序列长度L的数据时的外推性能
缺点:增加内存
T5 Bias和Alibi的主要区别在于偏置项的来源:T5 Bias通过学习得到偏置项,而Alibi使用预设的偏置项。这导致了两者在训练过程和模型性能上的差异。T5 Bias可能需要更多的计算资源和时间来训练,因为它需要学习偏置项;而Alibi由于偏置项是预设的,可能在训练速度上更快,但在模型的适应性和灵活性上可能不如T5 Bias

















 2547
2547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









