






文章目录
什么是位置编码
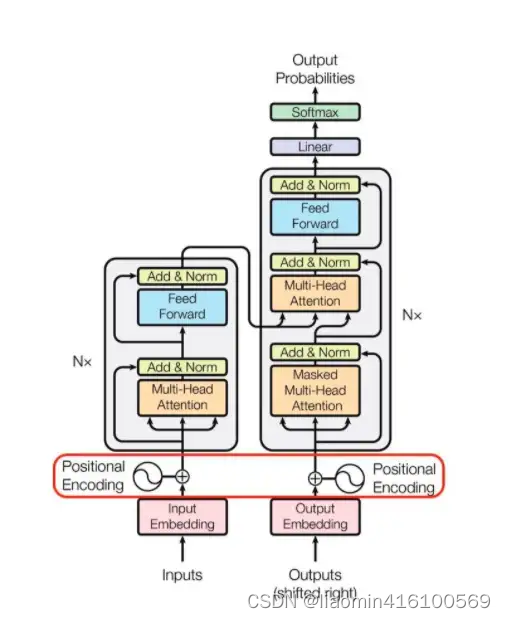
在transformer的encoder和decoder的输入层中,使用了Positional Encoding,使得最终的输入满足:
i
n
p
u
t
=
i
n
p
u
t
_
e
m
b
e
d
d
i
n
g
+
p
o
s
i
t
i
o
n
a
l
_
e
n
c
o
d
i
n
g
input = input\_embedding + positional\_encoding
input=input_embedding+positional_encoding
word embedding:理解参考
这里,input_embedding是通过常规embedding层,将每一个token的向量维度从vocab_size映射到d_model,由于是相加关系,自然而然地,这里的positional_encoding也是一个d_model维度的向量。(在原论文里,d_model = 512)
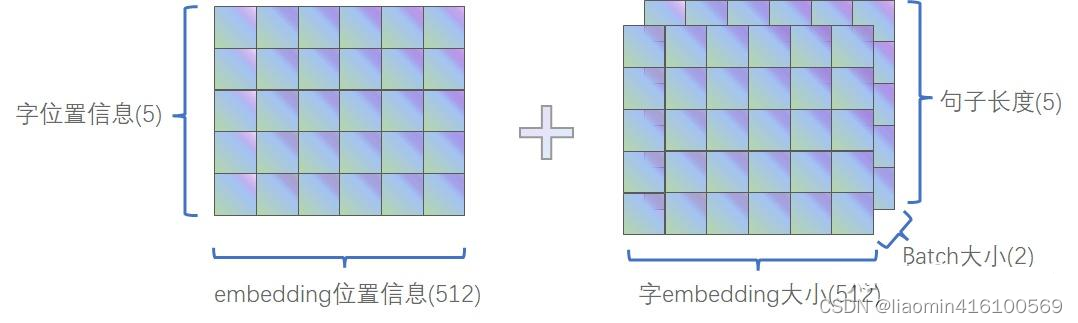
注意:在Transformer模型中,“token”(标记)是指输入序列中的每个元素,它通常是一个单词、一个子词或一个字符,假设我们有一个句子:“The cat sat on the mat.”,单词级别的标记: [“The”, “cat”, “sat”, “on”, “the”, “mat”, “.”]。然后被转换成词嵌入(word embeddings)和位置嵌入(position embeddings),然后这两种嵌入会被相加起来形成输入嵌入(input embeddings)。这个输入嵌入会作为模型的输入,并传递到Transformer的神经网络中进行处理,token本身不会再作为数据传递到模型中。
Input Embedding为什么解决的是语义问题,没有解决位置问题??,语义不是有顺序才有吗??
-
Input Embedding (输入嵌入):
input_embedding主要解决的是词汇语义的表示问题。通过将单词映射为连续的低维向量空间,词嵌入技术(如Word2Vec、GloVe等)可以捕获单词之间的语义关系,比如单词的近义词、反义词等。这使得神经网络在处理文本时能够更好地理解单词的含义,从而提高了对语义的建模能力。- 但是,词嵌入并没有直接解决词序的问题。即使单词被嵌入到向量空间中,神经网络在处理这些向量时仍然不知道它们在句子中的位置。这就是为什么我们需要进一步引入位置编码的原因。
-
Positional Encoding (位置编码):
positional_encoding解决的是序列数据的位置信息丢失问题。在自然语言处理中,文本是由单词或字符组成的序列,这些单词的排列顺序对句子的含义至关重要。通过引入位置编码,我们可以向神经网络提供关于单词在序列中位置的信息,从而使网络能够区分不同位置的单词并更好地处理序列数据。- 位置编码通常是与词嵌入相加的方式来融合位置信息和语义信息。这样,神经网络在处理输入数据时既能考虑单词的语义关系,又能考虑单词在句子中的位置关系,从而更全面地理解文本数据。
因此,input_embedding 和 positional_encoding 两者都是为了帮助神经网络更好地理解文本数据,但它们解决的是不同层面的问题:input_embedding 解决的是语义表示问题,而 positional_encoding 解决的是位置信息丢失问题。这两者结合起来能够提高神经网络对文本数据的建模能力。
在transformer的self-attention模块中,序列的输入输出如下(不了解self-attention没关系,这里只要关注它的输入输出就行):
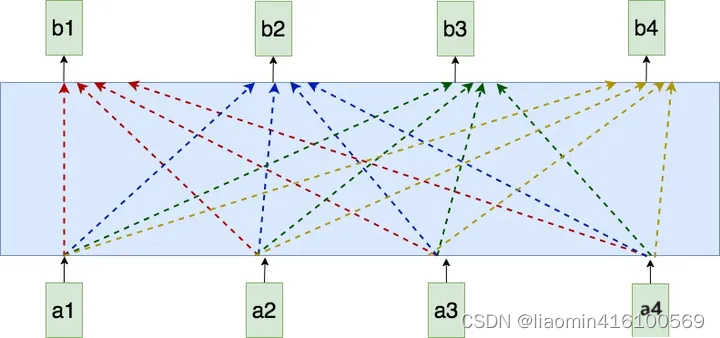
在self-attention模型中,输入是一整排的tokens,对于人来说,我们很容易知道tokens的位置信息,比如:
(1)绝对位置信息。a1是第一个token,a2是第二个token…
(2)相对位置信息。a2在a1的后面一位,a4在a2的后面两位…
(3)不同位置间的距离。a1和a3差两个位置,a1和a4差三个位置…
但是这些对于self-attention来说,是无法分辩的信息,因为self-attention的运算是无向的。因为,我们要想办法,把tokens的位置信息,喂给模型。
连续有界
有界又连续的概念是数学中对函数或者集合的性质进行描述的。一个函数或者集合被称为有界的意思是它在某个范围内有限,即它的值不能无限增长或减小;而连续则表示函数或者集合中的元素在某个区间内没有断裂或跳跃。
举个例子,考虑函数 (f(x) = \sin(x))。这个函数是有界的,因为正弦函数的值范围在 ([-1, 1]) 之间,不会超出这个范围。而且,正弦函数在定义域内是连续的,没有断点或跳跃。因此,正弦函数 (f(x) = \sin(x)) 是一个有界又连续的函数。
另一个例子是闭区间 ([0, 1]) 上的实数集合。这个集合是有界的,因为它的元素都在区间 ([0, 1]) 内;同时,这个集合是连续的,因为在闭区间内没有任何间隔或断裂。
总的来说,有界又连续的概念在数学中非常常见,许多函数、集合以及数学对象都可以被描述为有界又连续的。
为什么要有界
在Transformer等模型中,位置编码用于为序列中的不同位置提供唯一的标识,以便模型能够区分不同位置的词语。通常情况下,位置编码是与词嵌入向量相加的,因此需要确保位置编码与词嵌入向量的范围相匹配,以避免结果的数值过大或过小。
此外,由于模型的输入通常是通过词嵌入向量表示的,而词嵌入向量通常是有限范围的,因此位置编码的范围也被限制在一个合理的范围内,以保持整个输入的稳定性和可训练性。
因此,尽管位置编码并不一定必须是有界的,但在实践中,为了保持模型的稳定性和可训练性,通常会设计位置编码为有界的。
为什么要连续
位置编码必须是连续的,因为它们用于表示序列中的位置信息,而序列中的位置是连续的。在自然语言处理任务中,如语言模型或机器翻译,序列中的每个词或标记都对应着一个连续的位置。
如果位置编码不是连续的,那么模型将无法正确地理解序列中各个位置之间的关系。例如,如果某个位置的位置编码与其相邻位置的位置编码之间存在不连续性,模型可能会误解序列中的顺序关系,从而影响其性能。
另外,连续的位置编码有助于模型更好地捕捉序列中的局部和全局关系,因为它们可以在连续的空间中表示位置信息,使模型能够更准确地理解序列中不同位置之间的距离和关联。
综上所述,位置编码必须是连续的,以确保模型能够有效地理解序列中的位置信息,并正确地捕捉序列中的关系和结构。
位置编码的演变
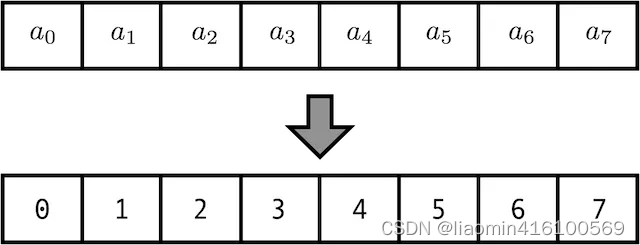
用整型值标记位置
一种自然而然的想法是,给第一个token标记0,给第二个token标记1…,以此类推。
这种方法产生了以下几个主要问题:
- 模型可能遇见比训练时所用的序列更长的序列。不利于模型的泛化。
- 模型的位置表示是无界的。随着序列长度的增加,位置值会越来越大。
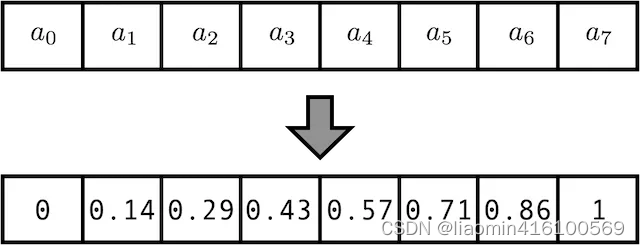
用[0,1]范围标记位置
为了解决整型值带来的问题,可以考虑将位置值的范围限制在[0, 1]之内,其中,0表示第一个token,1表示最后一个token。比如有3个token,那么位置信息就表示成[0, 0.5, 1];若有四个token,位置信息就表示成[0, 0.33, 0.69, 1]。
但这样产生的问题是,当序列长度不同时,token间的相对距离是不一样的。例如在序列长度为3时,token间的相对距离为0.5;在序列长度为4时,token间的相对距离就变为0.33。
因此,我们需要这样一种位置表示方式,满足于:
- 它能用来表示一个token在序列中的绝对位置
- 在序列长度不同的情况下,不同序列中token的相对位置/距离也要保持一致
- 可以用来表示模型在训练过程中从来没有看到过的句子长度。
用二进制向量标记位置
考虑到位置信息作用在input embedding上,因此比起用单一的值,更好的方案是用一个和input embedding维度一样的向量来表示位置。这时我们就很容易想到二进制编码。如下图,假设d_model = 3,那么我们的位置向量可以表示成:
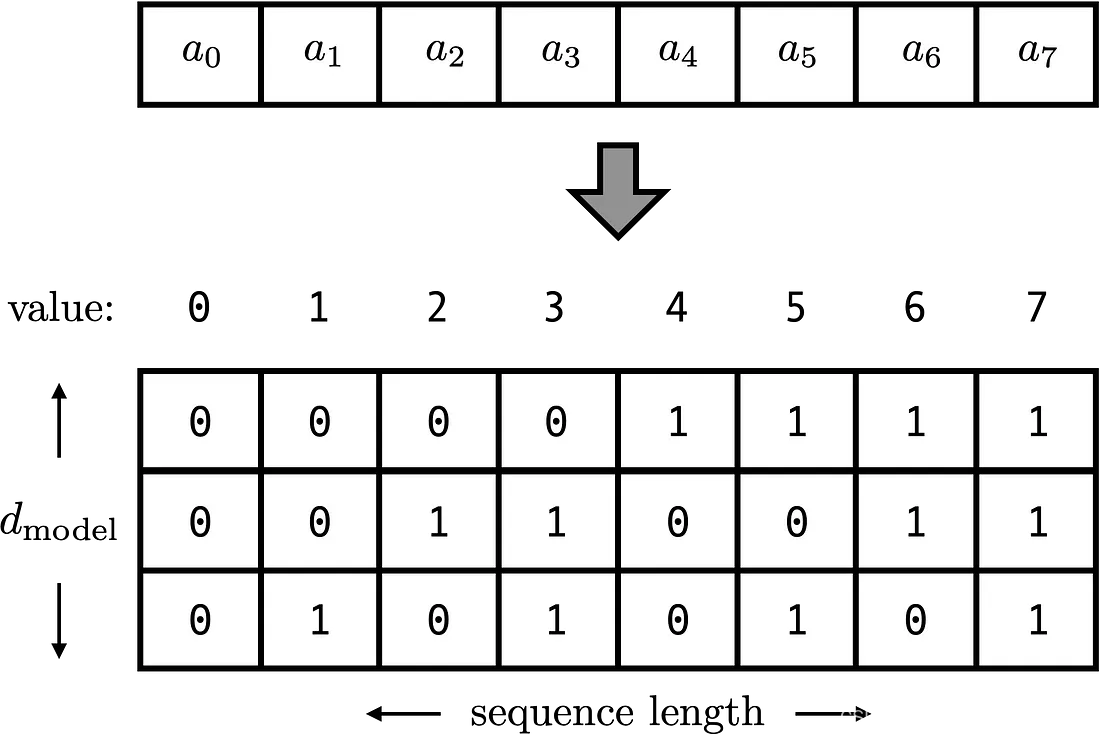
这下所有的值都是有界的(位于0,1之间),且transformer中的d_model本来就足够大,基本可以把我们要的每一个位置都编码出来了。
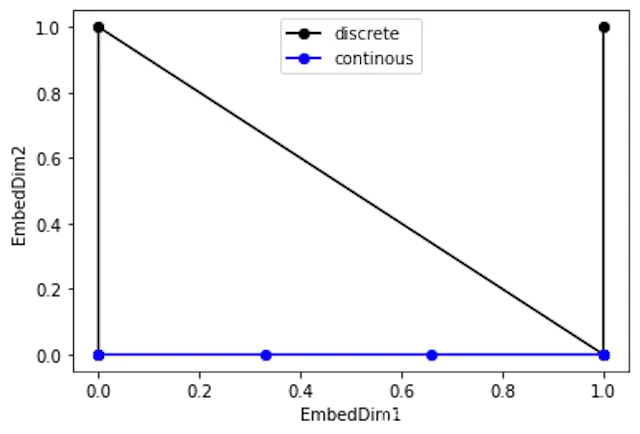
但是这种编码方式也存在问题:这样编码出来的位置向量,处在一个离散的空间中,不同位置间的变化是不连续的。假设d_model = 2,我们有4个位置需要编码,这四个位置向量可以表示成[0,0],[0,1],[1,0],[1,1]。我们把它的位置向量空间做出来:
用周期函数(sin)来表示位置
sin函数
先回顾下sin函数的几个概念,因为下面要用到sin函数:
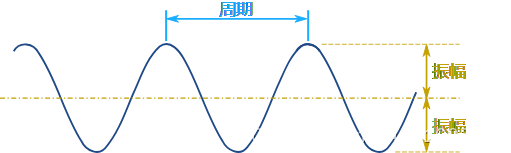
周期
周期是从一个最高点到下一个最高点(或任何一点到下一个相对点):
振幅,相移,垂直位移
振幅是从中(平)线到最高点的高度(或到最低点),也是从最高点到最低点的距离除以2。
相移是函数比通常的位置水平向右移了多远。
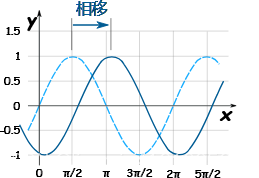
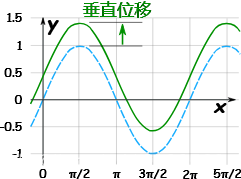
垂直位移是函数比通常的位置垂直向上移了多远。
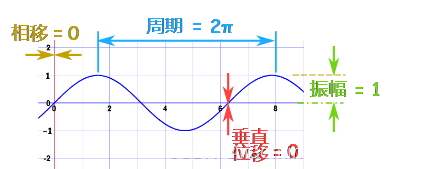
我们可以全部放进一个方程里:
y = A sin(Bx + C) + D
振幅是:A
周期是:2π/B
相移是:−C/B
垂直移位是:D
例子:sin(x)
这是正弦的基本公式。A = 1, B = 1, C = 0 and D = 0
所以振幅是1,周期是2π,没有相移或垂直移位:
振幅 1,周期 2pi,没有相移或垂直移位
频率
频率是在一个时间单位里发生多少次(每 “1”)。
例子:这个正弦函数在0到1之间重复了4次:
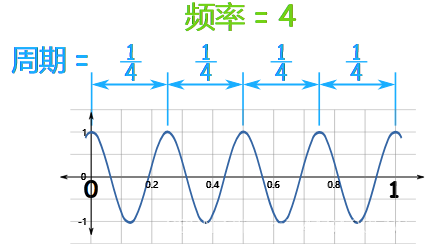
所以频率是 4
周期是
1
4
\frac{1}{4}
41
其实周期和频率是相连的,周期越大,频率越小:
频率 =
1
周期
\frac{1}{周期}
周期1
周期 =
1
频率
\frac{1}{频率}
频率1
波长
波长λ=vT,其中v是波速,T是周长。波长是一个周期内波前进的距离,而这段周期内波都是匀速直线前进的,所以直接使用匀速直线运动的位移公式即可。
sin表示位置
回想一下,现在我们需要一个有界又连续的函数,最简单的,正弦函数sin就可以满足这一点。我们可以考虑把位置向量当中的每一个元素都用一个sin函数来表示,则第t个token的位置向量(
d
m
o
d
e
l
d_{model}
dmodel表示嵌入向量维度)可以表示为:
P
E
t
=
[
s
i
n
(
1
2
0
t
)
,
s
i
n
(
1
2
1
t
)
.
.
.
,
s
i
n
(
1
2
i
−
1
t
)
,
.
.
.
,
s
i
n
(
1
2
d
m
o
d
e
l
−
1
t
)
]
PE_t = [sin(\frac{1}{2^0}t),sin(\frac{1}{2^1}t)...,sin(\frac{1}{2^{i-1}}t), ...,sin(\frac{1}{2^{d_{model}-1}}t)]\\
PEt=[sin(201t),sin(211t)...,sin(2i−11t),...,sin(2dmodel−11t)]
PE:位置编码:Positional Encoding,t表示第t个token,i表示位置编码是第几个列。
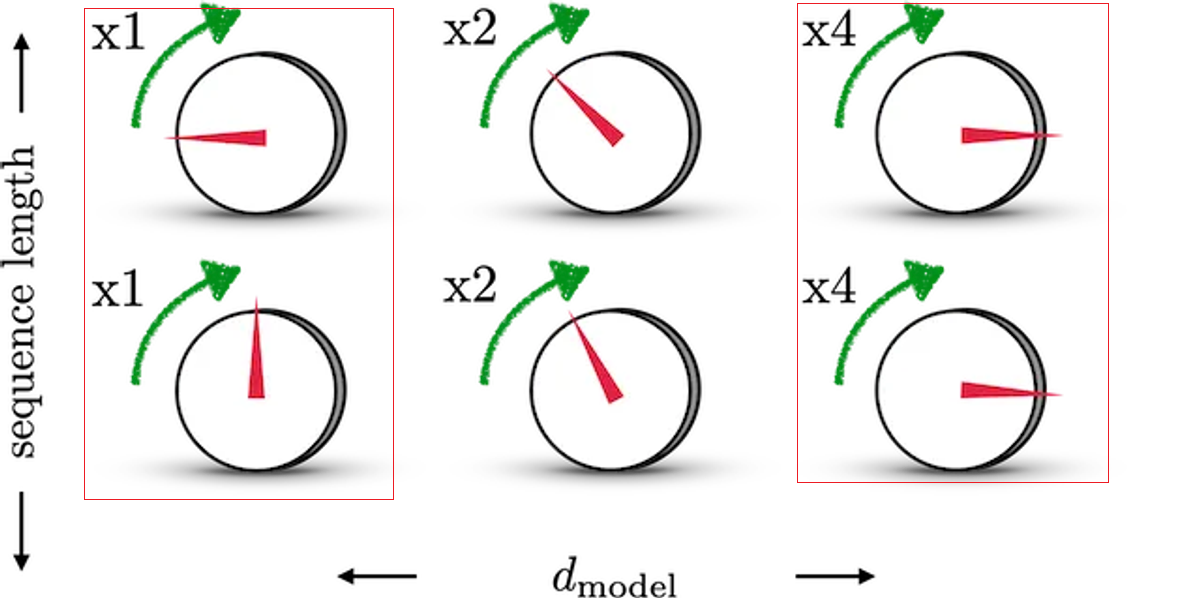
列sin函数,越往右波长(入*(2π/B))越长,频率越低。
说个题外话,说说音量调节,后面会有用:
假设你在调节音量。如果你向右旋转音量旋钮,音量(精度)可能会从低到高逐渐增加。一开始,当音量较低时,每次向右旋转可能只会增加一点音量,这时候你可能希望更细微地调整音量。但是,当音量已经相对较高时,每次向右旋转可能会增加更多的音量,这时候你可能不希望调整得太大,因此需要更小的步进来精确地调整音量。
因此,可以概括,向右旋转旋钮会增加调整参数的精度,也就是每次移动的步幅会变小,以便更精细地调整参数的值。
言归正传:
结合下图,来理解一下这样设计的含义。图中每一行表示一个
P
E
t
PE_t
PEt,每一列表示
P
E
t
PE_t
PEt中的第i个元素。旋钮用于调整精度,越往右边的旋钮,需要调整的精度越大,因此指针移动的步伐越小。每一排的旋钮都在上一排的基础上进行调整(函数中t的作用)。通过频率sin(12i−1t)sin(\frac{1}{2^{i-1}}t)sin(2i−11t)来控制sin函数的波长,频率不断减小,则波长不断变大,此时sin函数对t的变动越不敏感,以此来达到越向右的旋钮,指针移动步伐越小的目的。

由于sin是周期函数,因此从纵向来看,如果当函数的频率增大并导致波长缩短时,意味着波形在相同时间内完成了更多的周期,则不同t下的位置向量可能出现重合的情况。比如在下图中(d_model = 3),图中的点表示每个token的位置向量,颜色越深,token的位置越往后,在频率偏大的情况下,位置相连点连成了一个闭环,靠前位置(黄色)和靠后位置(棕黑色)竟然靠得非常近:
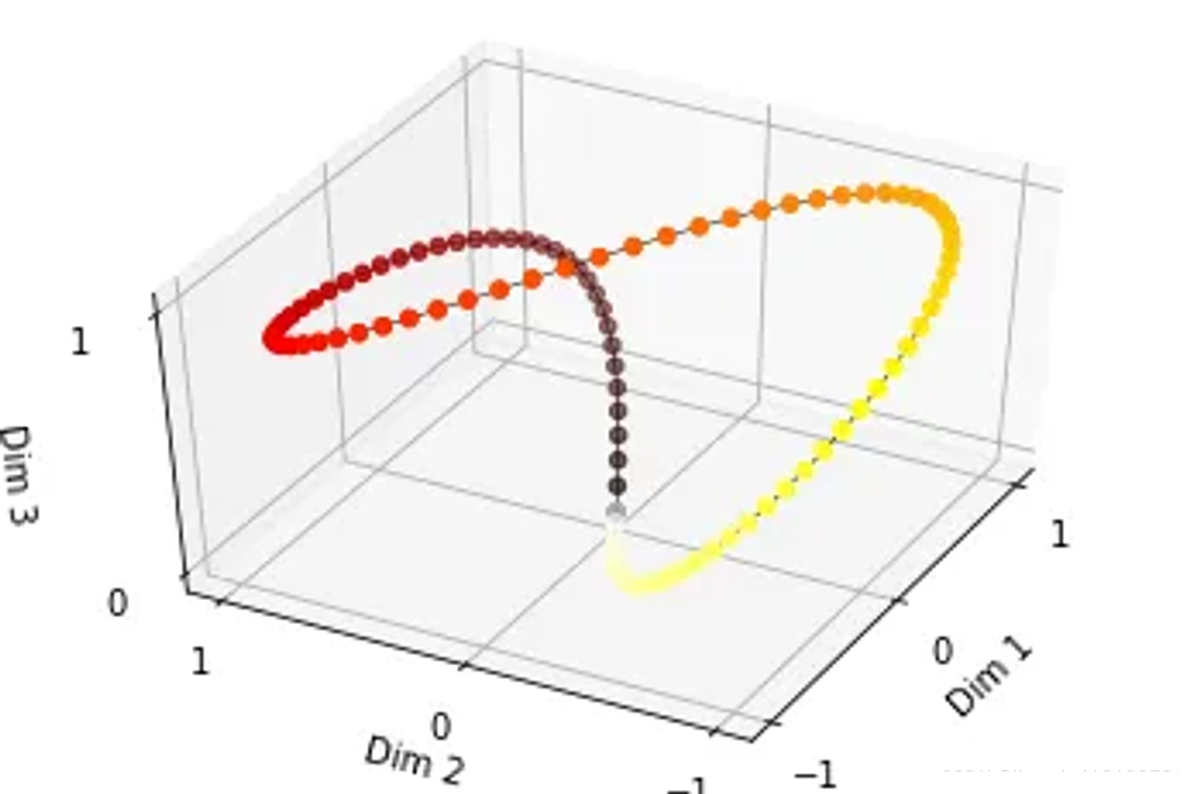
为了避免这种情况,我们尽量将函数的波长拉长。一种简单的解决办法是同一把所有的频率都设成一个非常小的值。因此在transformer的论文中,采用了
1
1000
0
i
/
(
d
m
o
d
e
l
−
1
)
\frac{1}{10000^{i/(d_{model}-1)}}
10000i/(dmodel−1)1这个频率(这里i其实不是表示第i个位置,但是大致意思差不多,下面会细说)
总结一下,到这里我们把位置向量表示为:
P
E
t
=
[
s
i
n
(
w
0
t
)
,
s
i
n
(
w
1
t
)
.
.
.
,
s
i
n
(
w
i
−
1
t
)
,
.
.
.
,
s
i
n
(
w
d
m
o
d
e
l
−
1
t
)
]
PE_t = [sin(w_0t),sin(w_1t)...,sin(w_{i-1}t), ...,sin(w_{d_{model}-1}t)]\\
PEt=[sin(w0t),sin(w1t)...,sin(wi−1t),...,sin(wdmodel−1t)]
其中,
w
i
=
1
1000
0
i
/
(
d
m
o
d
e
l
−
1
)
w_{i} = \frac{1}{10000^{i/(d_{model}-1)}}
wi=10000i/(dmodel−1)1
用sin和cos交替来表示位置
先来回顾下线性变化旋转的相关概念,后续用到。
线形变换——旋转
在二维坐标系中,一个位置向量的旋转公式可以由三角函数的几何意义推出。
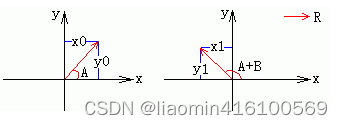
如上图假设:
- 已知:假设向量 R A R_{A} RA=(x0,y0) 角度为:A,向右旋转了角度B,新向量 R A + B R_{A+B} RA+B角度为:A+B,模: ∣ R ∣ = ∣ R A ∣ = ∣ R A + B ∣ = x 0 2 + y 0 2 |\mathbf{R}|=|\mathbf{R_{A}}|= |\mathbf{R_{A+B}}| = \sqrt{x_0^2 + y_0^2} ∣R∣=∣RA∣=∣RA+B∣=x02+y02。
- 未知:旋转后向量为:(x1,y1)
- 上面的命题就是向量 R A R_{A} RA旋转了角度B,求新向量 R A + B R_{A+B} RA+B(模大小相同), R A R_{A} RA和 R A + B R_{A+B} RA+B之间有绝对关系也有相对关系,相对一个角度B,我们需要通过公式来获得一个 R A + B R_{A+B} RA+B和 R A R_{A} RA的关系 R A + B = T B ∗ R A R_{A+B}=T_B*R_A RA+B=TB∗RA, T B T_B TB表示一个线性变换矩阵,我们可以通过公式推算出来。
在左图中,我们有关系:
x
0
=
∣
R
∣
∗
c
o
s
A
=
>
c
o
s
A
=
x
0
/
∣
R
∣
x0 = |R| * cosA => cosA = x0 / |R|
x0=∣R∣∗cosA=>cosA=x0/∣R∣
y
0
=
∣
R
∣
∗
s
i
n
A
=
>
s
i
n
A
=
y
0
/
∣
R
∣
y0 = |R| * sinA => sinA = y0 / |R|
y0=∣R∣∗sinA=>sinA=y0/∣R∣
在右图中,我们有关系:
x
1
=
∣
R
∣
∗
c
o
s
(
A
+
B
)
x1 = |R| * cos(A+B)
x1=∣R∣∗cos(A+B)
y
1
=
∣
R
∣
∗
s
i
n
(
A
+
B
)
y1 = |R| * sin(A+B)
y1=∣R∣∗sin(A+B)
其中(x1, y1)就是(x0, y0)旋转角B后得到的点。我们展开cos(A+B)和sin(A+B),得到:
x
1
=
∣
R
∣
∗
(
c
o
s
A
c
o
s
B
−
s
i
n
A
s
i
n
B
)
x1 = |R| * (cosAcosB - sinAsinB)
x1=∣R∣∗(cosAcosB−sinAsinB)
y
1
=
∣
R
∣
∗
(
s
i
n
A
c
o
s
B
+
c
o
s
A
s
i
n
B
)
y1 = |R| * (sinAcosB + cosAsinB)
y1=∣R∣∗(sinAcosB+cosAsinB)
现在把
c
o
s
A
=
x
0
/
∣
R
∣
cosA = x0 / |R|
cosA=x0/∣R∣ 和
s
i
n
A
=
y
0
/
∣
R
∣
sinA = y0 / |R|
sinA=y0/∣R∣ 代入上面的式子,得到:
x
1
=
∣
R
∣
∗
(
x
0
∗
c
o
s
B
/
∣
R
∣
−
y
0
∗
s
i
n
B
/
∣
R
∣
)
=
>
x
1
=
x
0
∗
c
o
s
B
−
y
0
∗
s
i
n
B
x1 = |R| * (x0 * cosB / |R| - y0 * sinB / |R|) => x1 = x0 * cosB - y0 * sinB
x1=∣R∣∗(x0∗cosB/∣R∣−y0∗sinB/∣R∣)=>x1=x0∗cosB−y0∗sinB
y
1
=
∣
R
∣
∗
(
y
0
∗
c
o
s
B
/
∣
R
∣
+
x
0
∗
s
i
n
B
/
∣
R
∣
)
=
>
y
1
=
x
0
∗
s
i
n
B
+
y
0
∗
c
o
s
B
y1 = |R| * (y0 * cosB / |R| + x0 * sinB / |R|) => y1 = x0 * sinB + y0 * cosB
y1=∣R∣∗(y0∗cosB/∣R∣+x0∗sinB/∣R∣)=>y1=x0∗sinB+y0∗cosB
这样我们就得到了二维坐标下向量围绕圆点的逆时针旋转公式。顺时针旋转就把角度变为负:
x
1
=
x
0
∗
c
o
s
(
−
B
)
−
y
0
∗
s
i
n
(
−
B
)
=
>
x
1
=
x
0
∗
c
o
s
B
+
y
0
∗
s
i
n
B
x1 = x0 * cos(-B) - y0 * sin(-B) => x1 = x0 * cosB + y0 * sinB
x1=x0∗cos(−B)−y0∗sin(−B)=>x1=x0∗cosB+y0∗sinB
y
1
=
x
0
∗
s
i
n
(
−
B
)
+
y
0
∗
c
o
s
(
−
B
)
=
>
y
1
=
−
x
0
∗
s
i
n
B
+
y
0
∗
c
o
s
B
y1 = x0 * sin(-B) + y0 * cos(-B)=> y1 = -x0 * sinB + y0 * cosB
y1=x0∗sin(−B)+y0∗cos(−B)=>y1=−x0∗sinB+y0∗cosB
现在我要把这个旋转公式写成矩阵的形式,有一个概念我简单提一下,平面或空间里的每个线性变换(这里就是旋转变换)都对应一个矩阵,叫做变换矩阵。对一个点实施线性变换就是通过乘上该线性变换的矩阵完成的。好了,打住,不然就跑题了。
现在来将下面公式转换成矩阵
逆时针:
x
1
=
x
0
∗
c
o
s
B
−
y
0
∗
s
i
n
B
x1 = x0 * cosB - y0 * sinB
x1=x0∗cosB−y0∗sinB
y
1
=
x
0
∗
s
i
n
B
+
y
0
∗
c
o
s
B
y1 = x0 * sinB + y0 * cosB
y1=x0∗sinB+y0∗cosB
所以二维旋转变换矩阵就是:
[
x
,
y
]
∗
[
c
o
s
B
s
i
n
B
−
s
i
n
B
c
o
s
B
]
=
[
x
∗
c
o
s
B
−
y
∗
s
i
n
B
,
x
∗
s
i
n
B
+
y
∗
c
o
s
B
]
[x, y] * \left[\begin{matrix}cosB & sinB \\ -sinB & cosB\end{matrix}\right] = [x*cosB-y*sinB ,x*sinB+y*cosB]
[x,y]∗[cosB−sinBsinBcosB]=[x∗cosB−y∗sinB,x∗sinB+y∗cosB]
变换矩阵为
[
c
o
s
B
s
i
n
B
−
s
i
n
B
c
o
s
B
]
\left[\begin{matrix}cosB & sinB \\ -sinB & cosB\end{matrix}\right]
[cosB−sinBsinBcosB]
顺时针:
x
1
=
x
0
∗
c
o
s
B
+
y
0
∗
s
i
n
B
x1 = x0 * cosB + y0 * sinB
x1=x0∗cosB+y0∗sinB
y
1
=
−
x
0
∗
s
i
n
B
+
y
0
∗
c
o
s
B
y1 = -x0 * sinB + y0 * cosB
y1=−x0∗sinB+y0∗cosB
同理变换矩阵为:
[
c
o
s
B
−
s
i
n
B
s
i
n
B
c
o
s
B
]
\left[\begin{matrix}cosB & -sinB \\ sinB & cosB\end{matrix}\right]
[cosBsinB−sinBcosB]
sin和cos交替表示位置
目前为止,我们的位置向量实现了如下功能:
- 每个token的向量唯一(每个sin函数的频率足够小)
- 位置向量的值是有界的,且位于连续空间中。模型在处理位置向量时更容易泛化,即更好处理长度和训练数据分布不一致的序列(sin函数本身的性质)
那现在我们对位置向量再提出一个要求,不同的位置向量是可以通过线性转换得到的。这样,我们不仅能表示一个token的绝对位置,还可以表示一个token的相对位置(也就是两个token之间得线性关系),即我们想要:
P
E
t
+
△
t
=
T
△
t
∗
P
E
t
PE_{t+\bigtriangleup t} = T_{\bigtriangleup t} * PE_{t}
PEt+△t=T△t∗PEt
这里,T表示一个线性变换矩阵。观察下面这个目标式子,联想到在向量空间中一种常用的线形变换——旋转。在这里,我们将t想象为一个角度,那么
△
t
\bigtriangleup t
△t就是其旋转的角度,则上面的式子可以进一步写成:
(
sin
(
t
+
△
t
)
cos
(
(
t
+
△
t
)
)
=
(
cos
△
t
sin
△
t
−
sin
△
t
cos
△
t
)
(
sin
t
cos
t
)
\begin{pmatrix} \sin(t + \bigtriangleup t)\\ \cos((t + \bigtriangleup t) \end{pmatrix}=\begin{pmatrix} \cos\bigtriangleup t&\sin\bigtriangleup t \\ -\sin\bigtriangleup t&\cos\bigtriangleup t \end{pmatrix}\begin{pmatrix} \sin t\\ \cos t \end{pmatrix}
(sin(t+△t)cos((t+△t))=(cos△t−sin△tsin△tcos△t)(sintcost)
有了这个构想,我们就可以把原来元素全都是sin函数的
P
E
t
PE_{t}
PEt
做一个替换,我们让位置两两一组,分别用sin和cos的函数对来表示它们,则现在我们有:
P
E
t
=
[
s
i
n
(
w
0
t
)
,
c
o
s
(
w
0
t
)
,
s
i
n
(
w
1
t
)
,
c
o
s
(
w
1
t
)
,
.
.
.
,
s
i
n
(
w
d
m
o
d
e
l
2
−
1
t
)
,
c
o
s
(
w
d
m
o
d
e
l
2
−
1
t
)
]
PE_t = [sin(w_0t),cos(w_0t), sin(w_1t),cos(w_1t),...,sin(w_{\frac{d_{model}}{2}-1}t), cos(w_{\frac{d_{model}}{2}-1}t)]\\
PEt=[sin(w0t),cos(w0t),sin(w1t),cos(w1t),...,sin(w2dmodel−1t),cos(w2dmodel−1t)]
在这样的表示下,我们可以很容易用一个线性变换,把
P
E
t
PE_{t}
PEt 转变为
P
E
t
+
△
t
PE_{t+\bigtriangleup t}
PEt+△t
P
E
t
+
△
t
=
T
△
t
∗
P
E
t
=
(
[
c
o
s
(
w
0
△
t
)
s
i
n
(
w
0
△
t
)
−
s
i
n
(
w
0
△
t
)
c
o
s
(
w
0
△
t
)
]
.
.
.
0
.
.
.
.
.
.
.
.
.
0
.
.
.
[
c
o
s
(
w
d
m
o
d
e
l
2
−
1
△
t
)
s
i
n
(
w
d
m
o
d
e
l
2
−
1
△
t
)
−
s
i
n
(
w
d
m
o
d
e
l
2
−
1
△
t
)
c
o
s
(
w
d
m
o
d
e
l
2
−
1
△
t
)
]
)
(
s
i
n
(
w
0
t
)
c
o
s
(
w
0
t
)
.
.
.
s
i
n
(
w
d
m
o
d
e
l
2
−
1
t
)
c
o
s
(
w
d
m
o
d
e
l
2
−
1
t
)
)
=
(
s
i
n
(
w
0
(
t
+
△
t
)
)
c
o
s
(
w
0
(
t
+
△
t
)
)
.
.
.
s
i
n
(
w
d
m
o
d
e
l
2
−
1
(
t
+
△
t
)
)
c
o
s
(
w
d
m
o
d
e
l
2
−
1
(
t
+
△
t
)
)
)
PE_{t+\bigtriangleup t} = T_{\bigtriangleup t} * PE_{t} =\begin{pmatrix} \begin{bmatrix} cos(w_0\bigtriangleup t)& sin(w_0\bigtriangleup t)\\ -sin(w_0\bigtriangleup t)& cos(w_0\bigtriangleup t) \end{bmatrix}&...&0 \\ ...& ...& ...\\ 0& ...& \begin{bmatrix} cos(w_{\frac{d_{model}}{2}-1 }\bigtriangleup t)& sin(w_{\frac{d_{model}}{2}-1}\bigtriangleup t)\\ -sin(w_{\frac{d_{model}}{2}-1}\bigtriangleup t)& cos(w_{\frac{d_{model}}{2}-1}\bigtriangleup t) \end{bmatrix} \end{pmatrix}\begin{pmatrix} sin(w_0t)\\ cos(w_0t)\\ ...\\ sin(w_{\frac{d_{model}}{2}-1}t)\\ cos(w_{\frac{d_{model}}{2}-1}t) \end{pmatrix} = \begin{pmatrix} sin(w_0(t+\bigtriangleup t))\\ cos(w_0(t+\bigtriangleup t))\\ ...\\ sin(w_{\frac{d_{model}}{2}-1}(t+\bigtriangleup t))\\ cos(w_{\frac{d_{model}}{2}-1}(t+\bigtriangleup t)) \end{pmatrix}
PEt+△t=T△t∗PEt=
[cos(w0△t)−sin(w0△t)sin(w0△t)cos(w0△t)]...0.........0...[cos(w2dmodel−1△t)−sin(w2dmodel−1△t)sin(w2dmodel−1△t)cos(w2dmodel−1△t)]
sin(w0t)cos(w0t)...sin(w2dmodel−1t)cos(w2dmodel−1t)
=
sin(w0(t+△t))cos(w0(t+△t))...sin(w2dmodel−1(t+△t))cos(w2dmodel−1(t+△t))
变换矩阵,也是两个一组和
P
E
t
PE_{t}
PEt进行点乘,变换数组一行就有多组,最后也是个由转换角度+参数(常量)的线性变换。
Transformer中位置编码方法
Transformer 位置编码定义
有了上面的演变过程后,现在我们就可以正式来看transformer中的位置编码方法了。
定义:
- t是这个token在序列中的实际位置(例如第一个token为1,第二个token为2…)
- P E t ∈ R d PE_t\in\mathbb{R}^d PEt∈Rd是这个token的位置向量, P E t ( i ) PE_{t}^{(i)} PEt(i)表示这个位置向量里的第i个元素 - d m o d e l d_{model} dmodel是这个token的维度(在论文中,是512)
则
P
E
t
(
i
)
PE_{t}^{(i)}
PEt(i) 可以表示为:
P
E
t
(
i
)
=
{
sin
(
w
k
t
)
,
i
f
i
=
2
k
(
偶数行
)
cos
(
w
k
t
)
,
i
f
i
=
2
k
+
1
(
奇数行
)
PE_{t}^{(i)} = \left\{\begin{matrix} \sin(w_kt),&if\ i=2k ( 偶数行 ) \\ \cos(w_kt),&if\ i = 2k+1(奇数行) \end{matrix}\right.
PEt(i)={sin(wkt),cos(wkt),if i=2k(偶数行)if i=2k+1(奇数行)
这里:
w
k
=
1
1000
0
2
k
/
d
m
o
d
e
l
w_k = \frac{1}{10000^{2k/d_{model}}}
wk=100002k/dmodel1
i
=
0
,
1
,
2
,
3
,
.
.
.
,
d
m
o
d
e
l
2
−
1
i = 0,1,2,3,...,\frac{d_{model}}{2} -1
i=0,1,2,3,...,2dmodel−1
注意:当使用 w k = 1 1000 0 2 k / d model w_k = \frac{1}{10000^{2k/d_{\text{model}}}} wk=100002k/dmodel1作为位置编码的调节因子时,当 k 增大时,分母中的指数项会变得非常大,可能导致数值溢出或者数值精度问题。为了避免这种情况,可以使用其对数形式 − log ( 10000.0 ) d model -\frac{\log(10000.0)}{d_{\text{model}}} −dmodellog(10000.0)这样做有以下几个优点:
- 数值稳定性: 对数形式避免了指数项过大导致的数值溢出或者数值精度问题。
- 计算效率: 对数形式的计算更加高效,避免了重复计算指数项。
- 一致性: 使用对数形式可以保持代码中的一致性,因为在其他部分可能也会涉及到对数形式的处理。
把512维的向量两两一组,每组都是一个sin和一个cos,这两个函数共享同一个频率
w
i
w_i
wi ,一共有256组,由于我们从0开始编号,所以最后一组编号是255。sin/cos函数的波长(由
w
i
w_i
wi
决定)则从
2
π
2\pi
2π增长到
2
π
∗
10000
2\pi*10000
2π∗10000,下面是代码实现
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
"""
位置编码器类的初始化函数
共有三个参数,分别是
d_model:词嵌入维度
dropout: dropout触发比率
max_len:每个句子的最大长度
"""
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings
# 注意下面代码的计算方式与公式中给出的是不同的,但是是等价的,你可以尝试简单推导证明一下。
# 这样计算是为了避免中间的数值计算结果超出float的范围,
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)
return self.dropout(x)
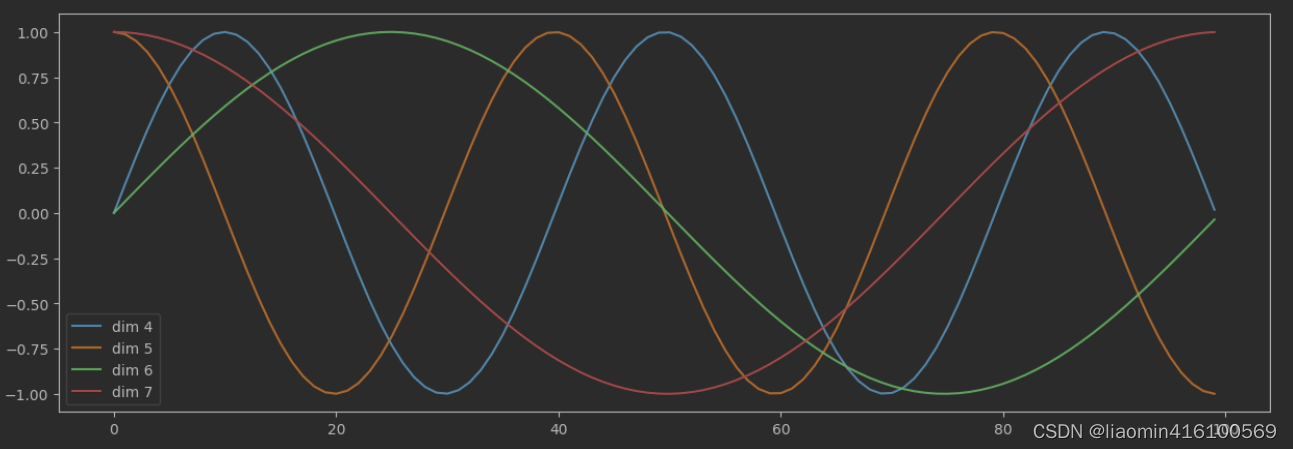
确认是否维度越往后,是否波长越长
plt.figure(figsize=(15, 5))
pe = PositionalEncoding(20, 0)
y = pe.forward(torch.zeros(1, 100, 20))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d"%p for p in [4,5,6,7]])
Transformer位置编码可视化
下图是一串序列长度为100,位置编码维度为512的位置编码可视化结果:
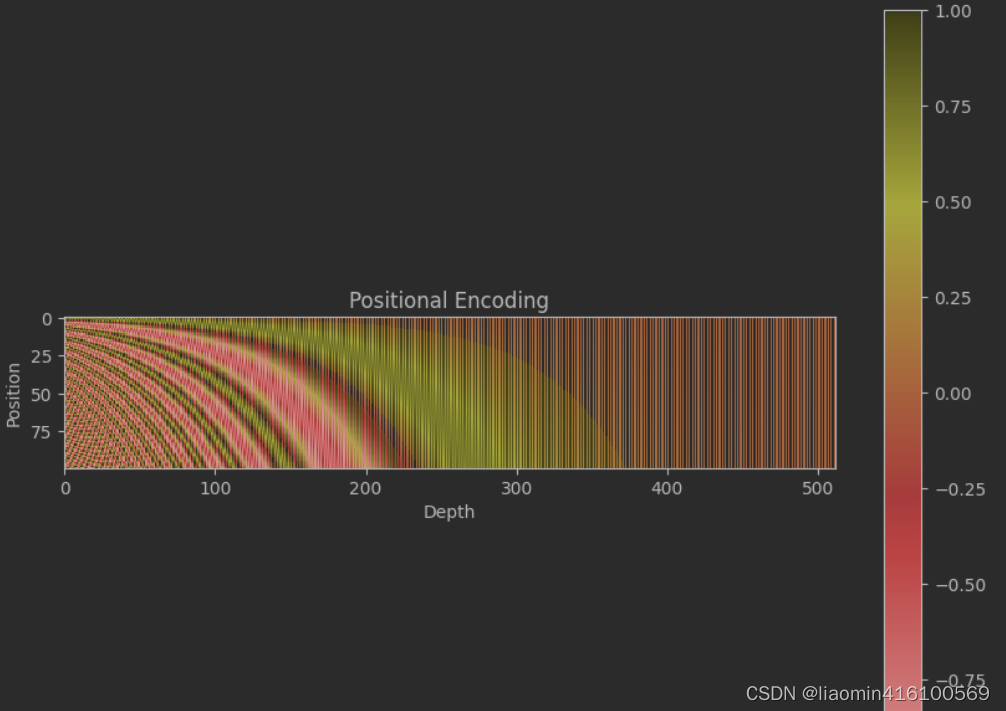
途中y轴表示单词的位置,从0开始到100,横坐标表示每个单词的512维度,颜色表示值,sin,cos函数的值在【-1,1】之间
可以发现,由于sin/cos函数的性质,位置向量的每一个值都位于[-1, 1]之间。同时,纵向来看,图的右半边几乎都是黄色的,这是因为越往后的位置,频率越小,波长越长,所以不同的t对最终的结果影响不大。而越往左边走,颜色交替的频率越频繁。
代码:
import matplotlib.pyplot as plt
import numpy as np
# 设置序列长度和模型维度
sequence_length = 100 # 序列长度
d_model = 512 # 模型维度
# 初始化位置编码矩阵
positional_encoding = np.zeros((sequence_length, d_model))
# 计算位置编码
for pos in range(sequence_length):
for i in range(d_model):
if i % 2 == 0:
# 偶数索引使用正弦函数
positional_encoding[pos, i] = np.sin(pos / (10000 ** (i / d_model)))
else:
# 奇数索引使用余弦函数
positional_encoding[pos, i] = np.cos(pos / (10000 ** ((i - 1) / d_model)))
# 绘制位置编码的图像
plt.figure(figsize=(10, 8))
plt.imshow(positional_encoding, cmap='hot', interpolation='nearest')
plt.title('Positional Encoding')
plt.xlabel('Depth')
plt.ylabel('Position')
plt.colorbar()
plt.show()

















 2622
2622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









