






决策树算法
1.介绍
决策树是一种简单而常用的分类和回归算法。决策树算法建立的模型呈现树状结构,顶部的节点为根节点,叶子节点表示分类或预测的结果。决策树可以用于解决分类和回归问题。
决策树算法流程如下所示:
- 选择最优特征:用各种方法来找到最优的划分特征,例如信息增益、信息熵等。
- 划分数据集:根据最优特征划分数据集。对于离散特征,只需判断是否相等;对于连续特征,选择一个划分点进行二元划分,可以得到更好的分类效果。
- 递归地建立决策树:重复进行上述划分过程,直至所有样本都被正确分类或不能再添加新的分支。
- 剪枝:为了避免过拟合,需要对生成的决策树进行剪枝处理。
在建立完决策树模型后,需要对其进行评估。可以使用如下方法进行模型评估:
- 计算训练集和测试集上的准确率,如果两者差别过大,则说明模型存在过拟合或欠拟合的问题。
- 绘制混淆矩阵,计算模型的精确率、召回率等指标,从而综合评估模型的性能。
- 交叉验证:将数据集分为训练集和验证集,重复多次训练和验证过程,最终得到模型的平均性能。通过验证集的性能,可以选择最优的决策树参数和模型。
- ROC曲线:对分类模型绘制不同阈值下的真正率(True Positive Rate)和假正率(False Positive Rate),以此评估分类器的优劣。
2.数据准备
| Age | Sex | BP | Cholesterol | Na_to_K | Drug |
|---|---|---|---|---|---|
| 年龄 | 性别 | 血压 | 胆固醇 | 钠钾浓度 | 药物种类 |
3.数据划分
data = pd.read_csv('e:/pyworkplace/123/DATA/drug200.csv')
print(data.head())
# 加载变量
data_x = data[['Age', 'Sex', 'BP', 'Cholesterol', 'Na_to_K']]
y = data['Drug']
主要研究如何构建决策树模型,数据为干净可靠的数据
4.字段处理
5个维度为变量,由于像Sex这种维度的数据为分类型的数据,将这种数据映射为数字类型
# 对性别字段进行标签编码
lable_sex = preprocessing.LabelEncoder()
lable_sex.fit(['F', 'M'])
data_x['Sex'] = lable_sex.transform(data_x['Sex'])
# 对血压字段进行标签编码
lable_BP = preprocessing.LabelEncoder()
lable_BP.fit(['LOW', 'NORMAL', 'HIGH'])
data_x['BP'] = lable_BP.transform(data_x['BP'])
# 对胆固醇字段进行标签编码
lable_chol = preprocessing.LabelEncoder()
lable_chol.fit(['NORMAL', 'HIGH'])
data_x['Cholesterol'] = lable_chol.transform(data_x['Cholesterol'])
5.选取合适最大深度
较小的最大深度可能会导致欠拟合(即模型过于简单),无法捕获数据中的复杂关系;较大的最大深度可能会导致过拟合(即模型过于复杂),过多地关注特定的训练数据,而无法泛化到新的数据。因此,通常需要识别最佳的最大深度,从而得到更好的模型性能。
寻找最佳的最大深度通常需要通过交叉验证等技术进行模型评估和选择模型超参数。
param_grid = {'max_depth': np.arange(1, 10)}
tree1 = DecisionTreeClassifier(criterion="entropy")
grid_search = GridSearchCV(tree1, param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit(x_train, y_train)
print("最佳的最大深度为", grid_search.best_params_)
print("模型的精度为", grid_search.best_score_)

使用网格搜索(GridSearchCV)来寻找决策树最大深度超参数的示例代码。代码首先定义了一个参数网格(param_grid),其中’ max_depth '是要调整的参数,并且可选的值从1到9。然后,定义一个决策树模型DecisionTreeClassifier,将其作为 estimator 传递给GridSearchCV,并且将 param_grid 作为可选参数传递给GridSearchCV函数。cv表示5折交叉验证。
调用 fit 函数来训练模型,GridSearchCV会在 param_grid 指定的多种参数组合中进行训练和评估,并返回在网格搜索中最佳的参数组合,可通过属性 best_params_ 访问。如果将 scoring 参数设置为’ accuracy ',则最佳分数将给出该模型在测试数据上的精度,可以通过访问best_score_ 属性获取。
6.模型构建
tree2 = DecisionTreeClassifier(criterion="entropy", max_depth=grid_search.best_params_['max_depth'])
tree2.fit(x_train, y_train)
accuracy = tree2.score(x_test, y_test)
pre = tree2.predict(x_test)
print("预测的准确度为: ", metrics.accuracy_score(y_test, pre))
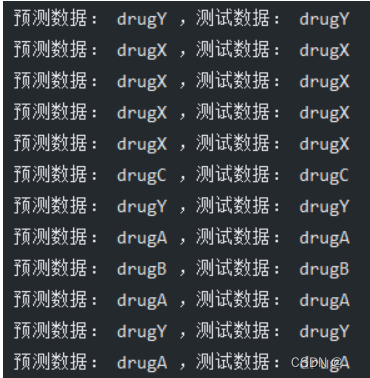

预测的准确率为0.98左右
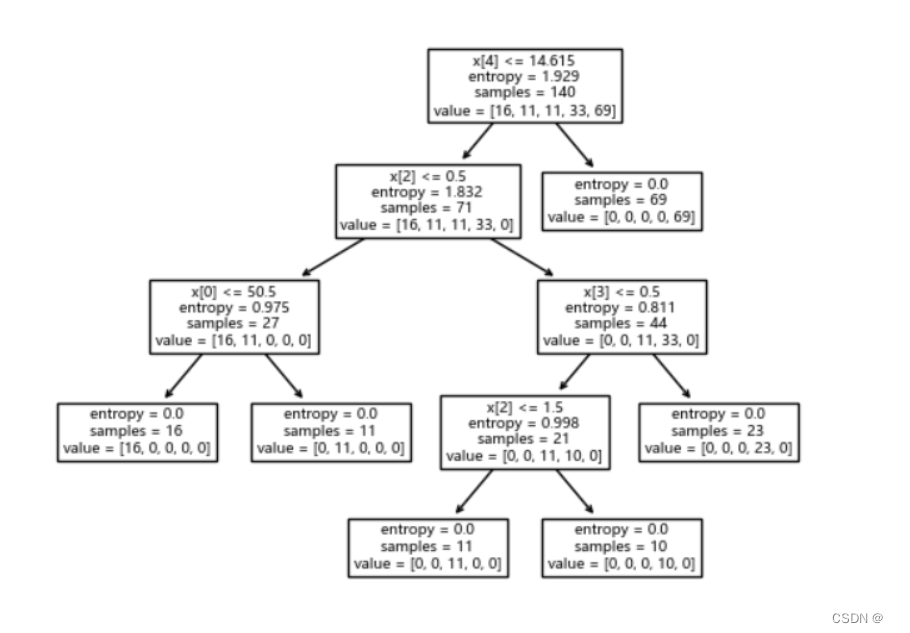
7.决策树















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









