



摘要
一、研究背景
在传统的 联邦图学习(FGL) 中:
-
整个图数据(如社交网络、知识图谱等)由于隐私保护原因被划分为多个子图,分布在不同客户端;
-
各客户端不共享原始数据,仅通过上传模型参数来共同训练一个全局图模型。
然而,FGL 面临一个严重的挑战:
数据异质性(Heterogeneity) —— 各客户端的节点分布、结构特征、标签类别等可能不同(即 non-IID),
导致模型难以收敛、性能下降。
二、现有方法的局限
现有研究主要集中在 模型层(Model-level) 的方法:
-
通过设计新的聚合算法或图神经网络结构,从不同客户端中提取“共享知识”;
-
但这类方法存在一个根本问题:
-
不能从根本上解决数据异质性,因为它们依赖模型结构本身;
-
一旦任务或数据场景变化,就需要重新设计模型,可迁移性差。
-
三、本文提出的创新点
作者受到 大语言模型(LLMs) 在理解与生成任务中取得突破的启发,
提出从 数据层(Data-level) 入手来解决异质性问题:
核心思想:
利用 LLM 来理解并补全每个客户端的图数据(text-attributed graphs),
通过生成“缺失的邻居节点”和推断其连接关系来增强数据一致性。
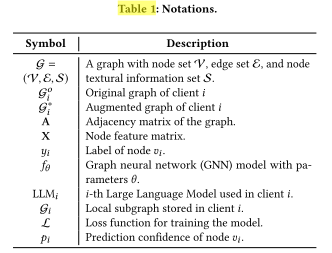
四、提出的方法 —— LLM4FGL 框架
LLM4FGL(Large Language Model for Federated Graph Learning) 是一个通用框架,
其主要流程分为两个核心子任务:
-
邻居生成(Neighbor Generation)
-
每个客户端利用 LLM 生成本地图中缺失的节点或邻居;
-
这些生成节点用于弥补图结构或类别分布不均的问题。
-
-
连接推断(Edge Inference)
-
在生成节点后,使用一个预训练的边预测模型(edge predictor)推断生成节点与原始节点之间的边连接关系。
-
五、创新机制:联邦生成与反思(Federated Generation-and-Reflection Mechanism)
为提升生成节点的质量,作者提出了一种 不修改 LLM 参数 的新机制:
-
各客户端将生成结果及反馈共享给服务器;
-
服务器根据全局反馈对生成提示(prompt)或策略进行调整;
-
形成一个“生成—反思—改进”的联邦循环过程。
该机制允许所有客户端协同优化生成质量,而无需在本地微调大模型,
从而兼顾了隐私与效率。
六、方法的兼容性与扩展性
-
LLM4FGL 可作为一个 插件式框架(plug-in),
无需修改现有的 FGL 算法结构即可集成使用; -
能与多种联邦图神经网络方法无缝结合,增强其数据一致性。
七、实验结果
在三个真实数据集上的实验表明:
-
LLM4FGL 相较于当前先进的 FGL 基线方法(baselines)表现更优;
-
在模型收敛速度和最终精度上都有显著提升;
-
证明了通过 LLM 改善数据层异质性是一种有效新思路。
引言
一、研究背景
现实世界中大量数据具有图结构,如社交网络、电子商务网络、生物蛋白相互作用网络等。
图神经网络(Graph Neural Networks, GNNs) 能通过消息传递机制(message passing)学习节点之间的关系,在推荐系统、生物医药等任务上表现优异。
但传统 GNN 有一个基本假设:
图数据是集中存储的。
在涉及隐私的场景(如金融系统、医疗机构)中,这一假设不成立——
-
图数据被划分为多个子图(subgraphs);
-
每个子图由不同的**客户端(clients)**持有;
-
客户端无法直接共享原始数据。
为此,联邦图学习(FGL) 被提出,允许多个客户端在不共享数据的前提下协同训练全局模型。
二、核心问题:数据异质性(Heterogeneity)
FGL 的主要难点在于 各客户端的数据分布不一致(Non-IID),具体包括两种类型:
-
节点异质性(Node heterogeneity):各客户端的节点标签分布不同;
-
边异质性(Edge heterogeneity):各客户端的图结构不同(如社区结构差异)。
这种异质性导致:
-
模型训练不稳定;
-
全局模型收敛变慢;
-
性能显著下降。
三、现有方法的局限
当前研究主要集中在**模型层面(Model-level)**缓解异质性,例如:
-
从本地客户端蒸馏可靠知识;
-
学习本地类别结构代理;
-
设计同质或异质传播机制(homophilous/heterophilous propagation)。
但这些方法有共同缺陷:
它们无法从根本上解决异质性问题,因为数据分布差异依然存在。
一旦迁移到新任务,还需要重新设计模型结构,通用性差。
四、论文动机
为从根本上缓解异质性,作者提出:
应从 数据层面(data-centric view) 出发,直接生成或补充数据,从而减少客户端之间的数据分布差距。
而 大语言模型(LLMs,如 GPT-4、Gemma) 在理解和生成复杂文本方面表现出强大的能力,
并在自然语言处理、计算机视觉以及文本属性图(Text-Attributed Graphs, TAGs)等任务中取得显著成功。
因此,论文的核心动机是:
能否利用 LLMs 来生成联邦图学习中缺失的节点或关系数据,以缓解 Non-IID 问题?
五、面临的挑战
作者指出两个关键挑战:
-
隐私限制下的全局数据感知不足
-
LLM 无法访问所有客户端的数据,只能看到局部信息;
-
无法准确推断全局分布,从而影响生成质量。
-
-
LLM 在图数据生成方面研究不足
-
现有研究多关注从零生成图结构;
-
本文目标是基于已有部分图数据生成“未见数据”,这一问题更复杂、更贴近联邦场景。
-
六、提出的方法:LLM4FGL 框架
为解决上述挑战,作者提出了 LLM4FGL 框架,从数据层缓解异质性问题。
(1)任务分解
LLM4FGL 将生成任务拆解为两个子任务:
-
节点生成(Node Generation)
-
利用 LLM 生成缺失的邻居节点的文本信息;
-
-
边推断(Edge Inference)
-
使用一个轻量的边预测模型(edge predictor)推断生成节点与原始节点之间的连接。
-
这种分解让 LLM 专注于其擅长的文本理解与生成,而结构推断由独立模块完成。
(2)生成与反思机制(Generation-and-Reflection Mechanism)
为提高生成数据质量,论文设计了一个创新机制:
-
每个客户端根据节点及其邻居信息的提示(prompt),利用 LLM 本地生成新节点文本;
-
所有客户端再用增强后的数据共同训练一个全局 GNN;
-
通过模型输出的**预测置信度(confidence)**作为反馈:
-
若置信度低 → 表示生成节点质量差 → 通知 LLM 再生成;
-
形成“生成 → 训练 → 反思 → 再生成”的循环优化。
-
此外,所有客户端还协同训练轻量级边预测器,选择前 k 条最可能的边作为新连接。
这一过程嵌入到每一轮联邦训练中,
最终得到增强后的图数据,可直接用于普通 GNN 训练。
七、框架特点
-
数据级插件(Data-level plug-in):
无需修改现有模型结构,可直接作为扩展模块使用; -
隐私友好:
无需上传原始数据,仅共享反馈指标; -
通用性强:
可与各种 FGL 模型结合,进一步提升性能。
八、主要贡献
论文总结了三项创新贡献:
-
首次将 LLM 应用于联邦图学习(FGL)
-
从数据层角度提出解决异质性的新框架 LLM4FGL;
-
理论上将问题分解为节点生成 + 边推断两部分。
-
-
提出生成与反思机制
-
指导 LLM 迭代优化生成质量;
-
联合轻量边预测器补全图结构。
-
-
实验验证效果显著
-
在三个真实数据集上,LLM4FGL 显著优于现有方法;
-
作为插件模块还能提升其他模型的性能。
-
相关工作
联邦图学习
一、研究主题
本节介绍了 FGL(Federated Graph Learning) 的基本概念与挑战:
FGL 是将联邦学习(Federated Learning, FL)的理念扩展到图数据上的方法,
允许多个客户端在分布式环境中协同学习全局图模型,
同时保护各自数据隐私。
二、FGL 的核心挑战
与传统联邦学习类似,FGL 的关键问题也是 数据异质性(data heterogeneity),
主要表现为:
-
节点异质性(node heterogeneity):不同客户端的节点标签分布差异;
-
边异质性(edge heterogeneity):不同客户端的子图结构或连边模式不同。
这种异质性导致全局模型聚合困难、性能下降。
三、现有代表性方法及其局限
论文回顾了几种主流模型层(model-level)方法来缓解异质性问题:
| 方法 | 核心思路 | 存在问题 |
|---|---|---|
| FedSage+ [33] | 训练一个线性生成器,用于生成缺失的邻居节点信息,以缓解结构异质性。 | 信息共享过程增加了通信开销。 |
| Fed-PUB [1] | 从**子图社区(subgraph community)**角度出发,通过测量子图相似度来选择性地更新子图参数。 | 依赖相似性估计,适应性有限。 |
| FedGTA [15] | 利用**拓扑平滑置信度(topology-related smoothing confidence)**与图矩(graph moments)优化聚合。 | 在全局聚合时可能受到不可靠类别知识的影响。 |
| FedTAD [38] | 量化每类的置信度,并通过知识蒸馏从本地模型中提取可靠知识传递到全局模型。 | 蒸馏过程依赖客户端质量,仍属模型层优化。 |
| AdaFGL [14] | 结合全局知识提取器与本地优化器,实现个性化(personalized)联邦图学习。 | 属于模型层方法,无法根本解决数据差异。 |
四、现有方法的共性与问题
这些方法虽在一定程度上缓解了异质性,但都属于 模型层策略(model-level strategies),
因此存在以下局限:
-
无法从根本上消除由数据分布差异引起的异质性;
-
当任务或数据变化时,需要重新设计或调整模型结构;
-
通信与计算开销较大,扩展性受限。
五、本文的创新视角
作者指出,他们的方法与上述工作有根本区别:
本文不再从模型结构入手,而是从数据层面出发,
利用 大语言模型(LLMs) 强大的理解与生成能力,
来直接生成或补充图数据,从而缓解联邦图学习中的数据异质性问题。
换句话说,
传统方法改“模型”来适应异质数据,
本文则改“数据”来统一异质模型。
大模型+图学习
一、LLMs 在图学习中的应用趋势
近年来,大语言模型(LLMs) 被广泛用于各种图学习任务,
并且在性能上已经超越了传统基于图神经网络(GNNs)的方法,
在许多任务上达到了最新的先进水平(state-of-the-art)。
二、按 LLM 在任务中的角色分类
作者根据 LLM 在图学习中的“功能角色”,将现有工作大致分为以下几类:
| 类别 | 角色描述 | 代表应用或思路 |
|---|---|---|
| ① LLM-as-enhancer(增强器) | 使用 LLM 对节点特征进行编码或扩展,通过生成额外文本信息来增强节点语义表示。 | 例如,LLM 生成节点描述、标签解释或上下文信息以提升特征表达【7, 9, 17, 23, 30】。 |
| ② LLM-as-predictor(预测器) | 将图结构序列化为自然语言输入给 LLM,让 LLM 直接进行推理和预测(如分类、链接预测等)。 | 例如,将节点关系转化为文本句子供 GPT 推断【3, 24, 26, 34, 36】。 |
| ③ 其他角色拓展 | LLM 被用于其他辅助或对抗性任务,如: • Defender(防御者):抵御对抗攻击; • Attacker(攻击者):执行图注入攻击; • Annotator(标注器):为有监督任务生成伪标签; • Generator(生成器):生成新的图结构或节点文本; • Controller(控制器):指导模型选择或超参调节; • Task planner(任务规划器):设计多步骤图推理任务。 | 这些方法拓展了 LLM 在图学习生态中的多功能性【4, 11, 12, 27, 29, 31, 32, 35】。 |
三、现有方法的局限
虽然上述方法在**非联邦场景(non-federated settings)**下表现优异,
但它们均依赖于集中化数据或统一模型访问:
因此,在联邦学习(Federated Graph Learning, FGL)场景下,
LLM 的潜力尚未被探索(remains unexplored)。
也就是说,当前 LLM 在图学习中的成功,还没有被迁移到保护隐私、数据分散的联邦环境中。
四、本文的创新点
作者指出,本论文的工作是:
首次将 LLM 引入联邦图学习(FGL),
并利用其强大的理解与生成能力来解决两个核心挑战:
节点异质性(node heterogeneity)
边异质性(edge heterogeneity)
这代表了从“集中式图学习”到“隐私保护型分布式图学习”中,LLM 应用的跨越式延伸。
前提知识
文本属性图
一、文本属性图(Text-Attributed Graph, TAG)的定义
一个 TAG(Text-Attributed Graph) 用三元组表示:
![]()
其中:
-
V:节点集合(node set),
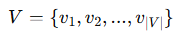
-
E:边集合(edge set),定义了节点间的连接关系
-
S:节点的文本信息集合(textual attributes of nodes),
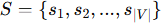
此外,引入一个邻接矩阵(adjacency matrix) ![]()
用于表示图的拓扑结构:
-
若节点 vi与 vj相连,则 Aij=1;
-
否则 Aij=0。
二、节点的文本属性与特征编码
每个节点不仅有结构连接,还带有文本信息(例如:节点描述、文档内容等)。
这类文本信息 S 会被嵌入编码(embedding) 成节点特征矩阵 X:
![]()
常见的文本编码方法包括 BERT、word2vec 等【20, 22】,
这些方法能将自然语言描述转化为可输入 GNN 的向量特征。
三、研究任务:节点分类(Node Classification)
本文聚焦于 TAG 上的 节点分类任务。
-
已标注节点集合:
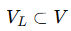 ,每个节点 viv_ivi 有标签 yiy_iyi;
,每个节点 viv_ivi 有标签 yiy_iyi; -
未标注节点集合:
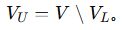
目标是训练一个图神经网络模型:
![]()
使其能利用图结构 A 和节点特征 X,
预测未标注节点 VU 的类别标签。
联邦图学习
一、FGL 的基本概念
联邦图学习(Federated Graph Learning, FGL)
是将联邦学习(Federated Learning, FL)的思想应用到图神经网络(GNN)中的方法。
设有一组客户端(clients),每个客户端存储一个本地图(local graph):
![]()
这些本地图分别由不同的数据持有者(clients)保存。
由于隐私或安全原因,客户端之间不能共享原始数据,
但可以协作训练一个全局模型(global model)。
目标是:
仅通过参数或梯度的交换(intermediate parameters),
在多个客户端上联合训练一个全局 GNN 模型 fθf_\thetafθ,
并利用该模型在各客户端上预测其未标注节点的标签。
即对于客户端 iii,
预测其未标注节点集合:
![]()
二、FGL 的训练过程
整个训练是一个多轮通信(communication rounds)的过程:
在第 t 轮:
-
模型初始化(Model initialization)
每个客户端 i 用服务器的全局模型参数 θt 初始化本地模型参数 θti。 -
本地训练(Local training)
客户端使用自己的本地数据进行训练,得到本地模型梯度 gti。 -
上传梯度(Upload gradients)
每个客户端将本地梯度上传到中央服务器(server)。 -
服务器聚合(Server aggregation)
服务器对所有客户端的梯度进行聚合。
聚合采用经典的 FedAvg 算法 [18]: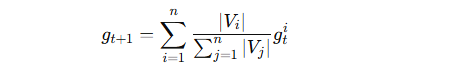
其中 ∣Vi∣ 表示客户端 iii 的节点数量,用于加权平均。
-
全局更新(Global update)
服务器根据聚合结果 gt+1 更新全局模型参数 θt+1。
三、核心思想
FGL 的关键思想是:
-
数据不出本地,隐私得以保护;
-
知识在参数层面共享,而非直接共享数据;
-
通过多轮聚合实现全局模型收敛。
这种方式使得多个数据孤岛(subgraphs)能共同学习到图结构模式,
但又不会暴露各自的原始数据内容。
方法
LLM4FGL 框架的理论基础与任务分解思路






基于大模型的图生成
一、任务目标
这一节对应前面理论框架中的第一个子任务:
利用 LLM 生成新节点及其文本属性 (Sg,Vg),以扩充本地图。
目标是:
-
为每个节点 vi 生成缺失的邻居节点(missing neighbors);
-
这些生成的节点应与原节点在语义上互补,从而增强数据多样性、缓解非IID问题;
-
同时保证隐私:每个客户端独立生成,不上传原始数据。
二、基本生成流程(Graph Data Generation)
作者假设 LLM(例如 GPT-4)以可信 API 形式部署。
每个客户端通过精心设计的提示词模板(prompt template)与 LLM 交互。
(1)提示词结构
LLM 接收两个节点的文本信息:
-
中心节点 vi(Center Node)
-
一个已存在的邻居节点 vj(Neighbor Node)
并根据它们生成一个新的“缺失邻居节点”(Missing Neighbor)。
系统提示(System prompt)大意如下:
-
给出研究主题类别列表;
-
分析中心节点的主题(输出为 "Topic Analysis");
-
生成一个逻辑上互补的邻居节点("Missing Neighbor");
-
输出必须是 JSON 格式,包含 “title” 与 “abstract”。
用户内容(User content)提供中心节点与邻居节点的文本。
(2)生成策略
根据理论公式 Eq. (4),生成每个节点时只需输入:
-
当前节点的文本信息 si
-
及其 l-hop 邻居(此处简化为 1-hop 邻居 sjs_jsj)
但由于:
-
LLM 有 token 长度限制;
-
输入过多邻居会引入噪声、降低预测信心;
因此,作者仅输入一个 1-hop 邻居,并对每个节点重复生成 ni次(邻居采样),
以获取多个新邻居节点。
这样既能保留局部结构信息,又能控制上下文复杂度。
三、本地增强与异质性问题
每个客户端都可以独立使用 LLM 生成新节点,
从而增强本地图数据(local augmentation)。
然而:
由于 LLM 只看到本地数据(无法访问其他客户端分布),
直接生成的节点仍然会带来 跨客户端分布不一致(heterogeneity) 的问题。
为了解决这个问题,作者引入了一个核心创新机制:
四、生成–反思机制(Generation-and-Reflection Mechanism)
这是 LLM4FGL 的核心设计,旨在利用全局知识指导 LLM 改进生成质量。
(1)动机
参考文献 [6, 28] 的结论:
模型预测的置信度(confidence)能反映其输出结果的正确性。
因此,可以用 预测置信度 来判断哪些节点的生成质量较低,
并引导 LLM 进行“自我反思(reflection)”和再生成。
(2)计算节点置信度
每轮全局训练第 ttt 步,全局 GNN 模型 fθt 输出每个节点的预测概率分布:
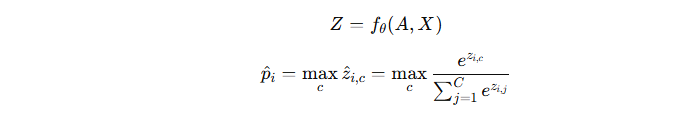
其中:
-
C:类别数量;
-
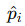 :节点 vi 的最大类别置信度。
:节点 vi 的最大类别置信度。
客户端会选择置信度最低的前 k 个节点(top-k low-confidence nodes),
送入 LLM 进行反思再生成。
(3)反思提示(Reflection Prompt)
新的系统提示中,LLM 会:
-
接收“之前生成的邻居节点”和“之前的主题分析”;
-
根据这些信息进行反思(reflection),思考错误原因(如:话题误判);
-
输出新的:
-
Topic Analysis(主题分析)
-
Reflection(反思说明)
-
Missing Neighbor(重新生成的邻居)
-
所有内容严格以 JSON 格式返回。
(4)反思循环
反思过程是迭代的:
LLM 每次接收前一轮的生成结果和反馈信号(置信度),
不断修正生成内容,使生成的邻居节点逐步提升质量。
五、与全局模型的协同
整个生成–反思过程遵循理论公式 Eq. (4):
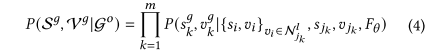
生成分布 P(Sg,Vg∣Go,Fθ) 中引入全局模型 FθF_\thetaFθ 作为指导信号。
即:
-
LLM 在客户端本地生成数据(保护隐私);
-
全局模型 Fθ 的反馈(置信度)间接反映全局分布信息;
-
从而实现“全局指导 + 本地生成”的融合机制。
边预测
一、任务目标
在前一步(LLM-based graph generation)中,LLM 为每个客户端生成了新的节点文本。
接下来需要解决的问题是:
这些生成的节点应该如何与原始节点或彼此相连?
因此,这一部分的目标是:
-
推断图结构 E+=(Eg,Ego),
其中:-
Eg:生成节点之间的边;
-
Ego:生成节点与原节点之间的边。
-
-
实现结构补全,从而让增强图 G∗ 更加真实、连贯。
二、总体思路
作者提出:
在各客户端中协同训练一个轻量化的边预测器 fϕ,
来估计任意两节点之间存在边的概率。
该模型是对公式 Eq. (5) 的具体实现:
![]()
三、模型设计
(1)选择模型结构
考虑到:
-
客户端计算与存储资源有限;
-
边预测任务相对简单(属于二分类问题);
作者选择使用一个轻量级的多层感知机(MLP) 作为边预测器 fϕ。
(2)输入表示
对于每一对节点 vi,vj:
-
将它们的节点特征向量拼接(concatenate):
xi∥xj -
输入到 MLP 中,得到边存在的预测概率:
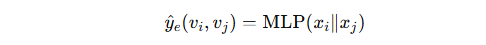
四、训练数据构造
为训练边预测器,需要构建正样本与负样本:
-
正样本(positive edges):
图中已存在的真实边(若 Ai,j=1);集合记作 Ep。 -
负样本(negative edges):
随机采样同数量的未连接节点对(Ai,j=0);集合记作 En。
这样形成一个平衡的数据集 Ep∪En。
五、损失函数
边预测器使用交叉熵损失(cross-entropy loss) 进行训练:
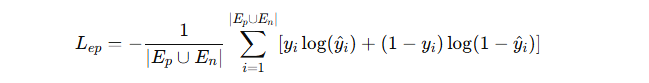
其中:
-
yi:边的真实标签(1 表示存在边,0 表示不存在);
-
yi-hat:模型预测概率。
六、联邦训练过程
每个客户端:
-
在本地使用自己的数据训练边预测器;
-
上传模型梯度到服务器;
-
服务器聚合这些梯度(类似 FedAvg),更新全局参数。
这样得到的边预测器 fϕ:
-
具备全局视角(整合了多客户端的边特征模式);
-
不泄露各客户端原始数据。
作者特别指出:
边预测器的训练与 LLM 节点生成解耦(decoupled),
因此可以提前训练好,并作为冻结模型(frozen model) 调用。
七、结构推断(Edge Inference)
当边预测器训练完毕后,就可以用于推断新结构:
-
对每一对可能的节点 vi,vj(包括原节点与生成节点):
-
将特征拼接后输入 MLP;
-
得到边存在的概率
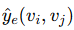
-
-
选择概率最高的 top-k 边,
作为新生成的边集合 E+=(Eg,Ego) -
此外,由于生成节点通常是基于某个原始节点生成的,
作者直接为该生成节点与原始节点添加一条边,
确保图的连通性。
整体算法
一、整体目标
这一节的目的是概述 LLM4FGL 框架的总体执行流程,
展示各个组件(LLM、边预测器、全局GNN)的协同工作方式。
整个流程可分为三个主要阶段:
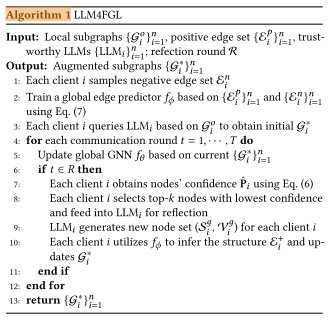
-
边预测器的训练(Edge Predictor Training)
-
LLM增强图的生成(LLM-based Graph Augmentation)
-
反思式联邦训练(Federated Generation-and-Reflection Training)
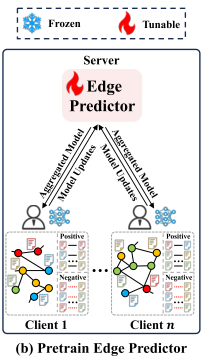
二、阶段一:边预测器的联合训练
-
所有客户端首先协同训练全局边预测器 fϕ。
-
每个客户端在本地训练轻量级的边预测模型(前面提到的 MLP),上传梯度;
-
服务器进行聚合(类似 FedAvg)得到一个共享的全局边预测模型。
这一步提前完成,使得之后 LLM 生成的新节点可以方便地与原图连接。
三、阶段二:利用 LLM 生成增强图
-
每个客户端调用本地或在线部署的 LLM(例如 GPT-4);
-
使用之前设计的 prompt 模板,为原始节点生成新的邻居节点;
-
由此得到一个增强图(augmented graph),即原始节点 + 生成节点 + 初步连接。
这一步是在数据层面对图进行扩充,缓解非IID问题。
四、阶段三:全局GNN训练与反思机制
在增强图的基础上,所有客户端开始联合训练全局 GNN 模型 fθ。
训练采用联邦方式进行,每一轮通信(communication round)包括以下步骤:
-
局部训练(Local Training):
每个客户端用本地增强图训练 GNN,上传梯度。 -
服务器聚合(Server Aggregation):
聚合各客户端的梯度,更新全局模型参数 fθf_\thetafθ。 -
反思回合(Reflection Rounds):
若当前轮 t 属于预设的反思回合:-
客户端计算本地节点的预测置信度(confidence score);
-
选出置信度最低的前 k 个节点;
-
将这些节点送入 LLM 进行“反思再生成”;
-
新生成的节点再通过边预测器 fϕ 与图中其他节点建立连接;
-
更新增强图并继续下一轮训练。
-
五、最终阶段:下游任务应用
经过多轮“生成–反思–训练”循环后:
-
每个客户端都得到一个高质量、结构完善的增强图;
-
全局模型 fθ 也已在更加一致的图分布上完成训练;
-
最终的增强图可直接用于下游任务(例如节点分类、推荐、聚类等)。
实验
实验设置
一、实验目标与研究问题(Research Questions)
作者首先提出了四个研究问题(RQs),
旨在系统地评估 LLM4FGL 框架的性能和机制:
-
RQ1:
与现有解决联邦图学习(FGL)数据异质性问题的方法相比,
LLM4FGL 的总体性能如何?
→ 验证方法整体优越性。 -
RQ2:
LLM4FGL 能否作为一个**插件模块(plug-in)**提升现有 FGL 模型?
→ 验证框架的通用性与兼容性。 -
RQ3:
LLM4FGL 的关键组成模块(例如 LLM 生成、反思机制、边预测器)
各自对性能有何贡献?
→ 做消融实验分析模块有效性。 -
RQ4:
超参数(如生成邻居数量、反思节点数、边预测器的 top-k)
如何影响模型表现?
→ 做超参数敏感性实验。
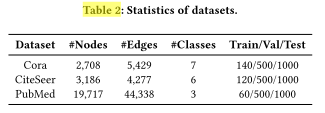
二、实验数据集(Dataset)
实验基于三大经典的引用网络数据集(citation networks):
-
Cora
-
CiteSeer
-
PubMed
这些都是图学习领域的标准基准集,
每个节点代表一篇论文,边表示论文之间的引用关系。
数据预处理采用文献 [3] 的方案。
为了模拟联邦环境中的标签异质性(label skew),
作者采用 Dirichlet 分布(α-based Dirichlet distribution)
将标签在不同客户端之间不均匀划分,
其中超参数 α 控制数据分布的集中程度:
α 越小 → 数据越异质;
α 越大 → 分布越均衡。
三、对比基线(Baselines)
作者与 七个代表性方法 进行对比实验,
涵盖了两类方法:
-
通用联邦学习(FL)方法;
-
专门面向图数据的联邦图学习(FGL)方法。
具体包括:
-
FedAvg [19] – 最经典的联邦平均算法;
按客户端样本数量加权平均参数。 -
FedProx [13] – 在 FedAvg 上增加“近端正则项”,
以缓解系统和统计异质性。 -
FedSage+ [33] – 利用生成器预测缺失邻居和节点特征,
缓解结构缺失导致的异质性。 -
FedGTA [15] – 通过拓扑相关的置信度平滑与混合邻居特征,
进行个性化优化。 -
Fed-PUB [1] – 基于子图相似度的个性化框架,
利用功能嵌入相似性加权聚合参数。 -
AdaFGL [14] – 提出两阶段自适应个性化策略,
在同质/异质场景下都能自适应传播。 -
FedTAD [38] – 采用无数据的知识蒸馏策略,
提升全局与本地模型之间的类别级知识迁移。
所有基线都在 OpenFGL [16] 框架下复现,
以确保公平、统一的实验比较。
四、实现细节(Implementation Details)
(1)模型与参数设定
-
LLM 模型: 使用 Gemma-2-9B-it [25](一个开放权重的大语言模型);
-
边预测器(MLP): 4 层,全连接,隐藏层维度 512;
-
图神经网络(GNN,使用 GCN): 2 层,隐藏层维度 256;
-
数据划分: 使用标准的训练/验证/测试划分方式 [3]。
(2)Dirichlet 参数
-
α 统一设为 100,用于控制客户端数据分布。
(3)超参数范围
-
LLM 生成邻居数(per client):{1, 5, 10, 15, 20, 25, 30};
-
反思机制中选取的低置信度节点数 k:{5, 10, 15, 20, 25, 30};
-
边预测器选取的候选边数 k:{50, 100, 150, 200, 250, 300, 350, 400}。
所有模型均基于验证集性能进行调参。
实验结果第一部分
一、实验目的
RQ1: 比较 LLM4FGL 与现有联邦图学习(FGL)方法在不同客户端数量下的性能,
验证它是否能够有效缓解数据异质性带来的性能下降问题。
二、实验设置
-
客户端数量分别设为 5、7、10,
模拟不同规模的联邦场景。 -
数据集为:Cora、CiteSeer、PubMed(三大引用网络)。
-
对比方法包括:前文提到的 7 个基线(FedAvg、FedProx、FedSage+、FedGTA、FedPUB、AdaFGL、FedTAD)。
-
实验结果见 Table 3(表格未展示,但文中进行了总结对比)。
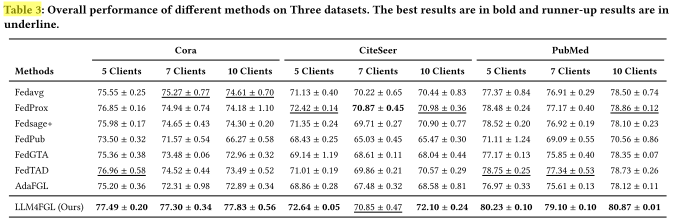
三、主要实验发现
作者报告了三个关键观察结果:
(1)LLM4FGL 整体性能最优,达到了 SOTA 水平
-
在三个数据集上,LLM4FGL 全面优于所有基线方法;
-
平均相对提升分别为:
-
Cora:+2.57%
-
CiteSeer:+0.62%
-
PubMed:+1.63%
-
-
说明 LLM4FGL 能有效缓解数据异质性(non-IID) 带来的性能损失,
并显著提升模型收敛性和准确率。
(2)传统 FGL 方法在多客户端场景下性能更差
-
结果显示,许多 FGL 方法(如 FedSage+、FedGTA)在客户端数量增加时性能下降,
甚至低于常规联邦学习(如 FedAvg、FedProx)。 -
原因分析:
-
本实验使用了标签不平衡划分(label imbalance split),
会导致客户端之间**跨子图边缺失(missing cross-client edges)**更严重,
异质性更高; -
现有 FGL 方法主要聚焦在模型层设计(model-level),
无法从根本上弥补数据层面的信息缺失。
-
-
相反,LLM4FGL 从数据层出发,
通过 LLM 直接生成补充节点与结构,
因此在不同客户端数量下都保持稳定、高性能表现。
(3)LLM4FGL 超越个性化 FGL 方法
-
一些个性化方法(如 FedPUB、FedGTA)会为每个客户端训练独立模型,
以适应不同的数据分布; -
但 LLM4FGL 仍然在总体性能上超过了这些个性化方法。
-
这说明:
-
数据层增强(data-level augmentation)从根本上缓解了异质性问题;
-
同时,LLM4FGL 减少了个性化建模带来的额外计算成本,
提升了全局模型的一致性与效率。
-
实验结果第二部分
一、实验目的
RQ2 的核心问题:
验证 LLM4FGL 是否可以作为一个数据层插件(plug-in module),
与现有 FGL 方法结合,从而进一步提升模型性能。
二、实验设计
-
LLM4FGL 被当作数据预处理方法使用。
它能够为每个客户端恢复一个更完整的本地图结构(recovered graph),
并可无缝集成到各种联邦图学习框架中。 -
实验中,作者在七个主流基线模型上测试了两种情况:
-
Original: 原始模型,不使用 LLM4FGL;
-
Integrated LLM4FGL: 在模型前加入 LLM4FGL 的数据增强模块。
-
-
实验结果记录在 Table 4(表中未展示,但结论被文字总结)。
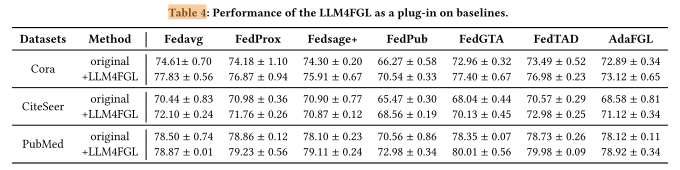
三、主要实验发现
(1)LLM4FGL 能显著提升所有基线的性能
-
在三个数据集上的平均相对准确率提升为:
-
Cora:+3.88%
-
CiteSeer:+2.81%
-
PubMed:+1.62%
-
-
说明通过 LLM4FGL 生成补全节点与边后,
原本缺失的结构信息得到恢复,各模型的整体性能都有提升。
(2)不同数据集的提升幅度不同
-
在 PubMed 上的提升相对较小,原因是:
-
PubMed 数据集文本特征更丰富、图结构更稠密,
-
本身信息完整,因此 LLM4FGL 生成的新信息边际贡献较低。
-
-
而 Cora 与 CiteSeer 的原始图结构较稀疏、文本较短,
因此从 LLM 生成的补充信息中获益更多。
(3)数据层与模型层结合最优
-
作者发现:
有些基线方法在集成 LLM4FGL 后,性能甚至超过了单独的 LLM4FGL 模型,
尤其是以 FedAvg 为基础的模型。 -
这说明:
-
LLM4FGL 的数据层增强(生成更完整的数据分布)
与 -
模型层优化策略(如个性化聚合、知识蒸馏)
相互补充;
二者结合能更全面地解决异质性问题。
-
实验结果第三部分
一、实验目的
RQ3: LLM4FGL 框架中的关键组成部分各自对性能有何影响?
作者聚焦于两个核心模块:
-
LLM 的生成–反思机制(generation-and-reflection mechanism);
-
边预测器(edge predictor)。
通过逐步去除它们来观察性能变化,从而分析每个组件的贡献程度。
二、实验设计
-
数据集: Cora、CiteSeer、PubMed;
-
客户端数量: 10 个(模拟多客户端高异质性场景);
-
实验设置:
-
w/o R → 去除反思机制(Reflection);
-
w/o E → 去除边预测器(Edge Predictor);
-
w/o R&E → 同时去除两者;
-
Vanilla FGL → 不使用 LLM 生成数据(原始联邦图学习基线)。
-
实验结果见 Table 5(文中总结了对比结论)。
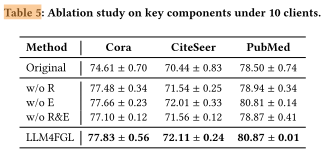
三、主要实验发现
(1)两个模块都对性能提升有正面作用
-
去除任意一个模块(R 或 E)都会导致性能下降;
-
同时去除两个模块(w/o R&E)时,性能进一步下降,
说明这两个模块在 LLM4FGL 中互为补充、协同增强。
(2)反思机制(Reflection)更为关键
-
反思机制相比边预测器,对整体性能的提升贡献更大;
-
尤其是在 PubMed 数据集上效果更明显。
解释:-
PubMed 的文本信息丰富、语义复杂,
-
反思机制能帮助 LLM 生成更高质量、更相关的邻居节点文本,
从而直接提升中心节点分类的准确率。
-
(3)边预测器的作用取决于生成数据质量
-
边预测器的效果依赖于生成节点的质量:
-
若节点文本高质量(有反思机制时),
边预测器能进一步提升结构完整性和整体性能; -
若节点文本低质量(无反思机制),
边预测器的提升效果有限甚至不显著。
-
-
因此,数据生成质量是下游结构预测模块能否有效的前提。
(4)LLM 生成带来最大总体提升
-
即使在去掉反思与边预测模块的情况下(w/o R&E),
单纯使用 LLM 生成的合成节点仍能显著提升 vanilla FGL 的性能; -
这充分说明:
-
LLM 生成(data-level augmentation)本身就具有极强的潜力,
-
能有效缓解联邦图学习中的数据异质性问题。
-
实验结果第四部分
一、实验目的
RQ4 的目标:
分析 LLM4FGL 的三个核心超参数对性能的影响,
验证模型对超参数设置的敏感度以及最佳取值范围。
二、实验设计
在 Cora、CiteSeer、PubMed 三个数据集上进行超参数敏感性实验,
考察以下三个变量:
-
边预测器的参数 k — 控制选取的“最可能存在的边”数量;
-
反思节点数量 k — 每个客户端在反思步骤中选择的低置信度节点数量;
-
生成邻居数量 n — 每个节点生成的虚拟邻居数量。
结果展示在 Figure 2(a)、(b)、(c) 中(文中总结了趋势)。
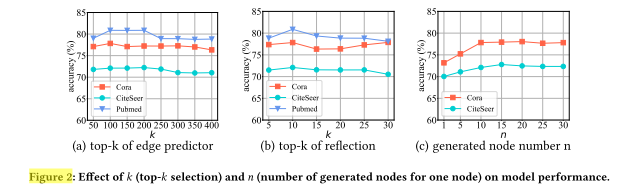
三、主要实验发现
(1)边预测器的 k:先升后降
-
当 k 较小时,模型的结构信息不充分,导致准确率较低;
-
随着 k 增大,性能先提升,达到最优点;
-
若 k 过大,则会引入过多噪声边(无效或错误连接),
导致性能下降。
结论: 需要一个适中的 k 来平衡“结构完整性”和“噪声控制”。
(2)反思节点数量 k:同样呈现“先升后降”趋势
-
若 k 太小 → 仅反思少量低置信度节点,生成数据改进有限;
-
若 k 太大 → 包含了部分预测已正确的节点,反而破坏了模型判别边界;
-
因此,适中数量的反思节点能最有效提升生成质量与分类性能。
结论: 反思机制的效果依赖于合理选择 k,避免过度反思或不足反思。
(3)生成邻居数量 n:收益递减
-
适度增加生成邻居数能显著提升性能,
因为它增强了局部数据的多样性与信息密度; -
但当 n 过大时,增益趋于平缓,甚至略微下降;
-
说明 生成质量比生成数量更关键。
-
若 n 太小,则生成数据过少、噪声比例更高,
模型容易受虚假节点干扰。
结论: 最优性能依赖高质量的少量补充数据,而非大量生成。
四、总体结论
核心发现:
LLM4FGL 对关键超参数的变化表现出明显的“先升后降”规律;
性能最优点出现在中等取值时;
模型性能的关键在于生成数据的质量而非数量,
这一点与作者提出的**反思机制(reflection mechanism)**的核心思想一致。
案例分析
一、实验目的
目标:
通过案例分析(case study)直观展示 LLM4FGL 中的
“生成–反思” 机制是如何提升生成节点文本质量的,
从而验证反思机制的有效性和实际作用。
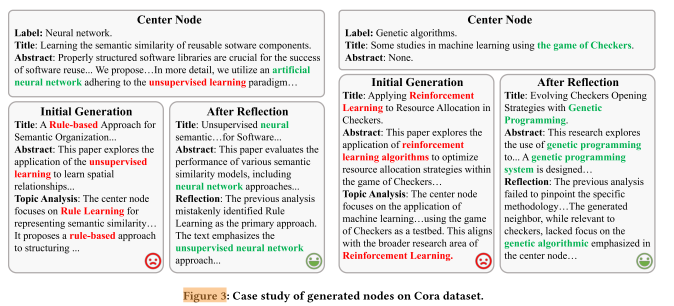
二、案例一:主题误判到修正
-
原始中心节点真实主题: Neural Network(神经网络)
-
LLM 初次生成时的错误:
-
模型错误聚焦于 “Unsupervised Learning(无监督学习)”;
-
因此生成了一个与 “Rule Learning(规则学习)” 相关的错误节点。
-
-
经过反思机制后:
-
LLM 重新识别到文本中核心关键词 “Neural Network”;
-
并生成了一个主题正确、内容相关的新节点。
-
结论: 反思机制帮助 LLM 修正主题误判,提升生成节点与中心节点的一致性。
三、案例二:信息缺失下的误判与纠正
-
中心节点原始问题:
-
论文只有标题、缺少摘要(信息不完整);
-
真实主题是 Genetic Algorithms(遗传算法)。
-
-
LLM 初次误判:
-
因为看到 “game of Checkers” 等词汇,
结合已有知识,误以为主题是 Reinforcement Learning(强化学习)。
-
-
反思后修正:
-
LLM 在反思阶段意识到强化学习的推断可能错误;
-
进一步思考到 “遗传算法也能用于策略设计”;
-
最终生成了正确主题为 Genetic Algorithms 的节点。
-
结论: 反思机制让 LLM 在信息不完整的情况下进行自我纠错,
通过重新理解上下文与逻辑关系,生成了更准确的补充节点。
四、总体结论
核心发现:
反思机制能让 LLM 在生成节点时进行“自我检查”与“主题校正”;
它有效减少了语义偏差和错误主题生成;
提升了生成节点文本的质量与与中心节点主题的契合度;
从而使中心节点信息得到更充分的补全,改善整个图数据的语义完整性。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









