






<一>传统的k-means算法实现流程:
输入样本集D={x1,x2,...xm},聚类的簇树k,最大迭代次数N
输出簇划分C={C1,C2,...Ck}
1) 从数据集D中随机选择k个样本作为初始的k个质心向量: {μ1,μ2,...,μk}
2)对于n=1,2,...,N
a) 将簇划分C初始化为Ct=∅t=1,2...k
b) 对于i=1,2...m,计算样本xi和各个质心向量μj(j=1,2,...k)的距离:dij=||xi−μj||22,将xi标记最小的为dij所对应的类别λi。此时更新Cλi=Cλi∪{xi}
c) 对于j=1,2,...,k,对Cj中所有的样本点重新计算新的质心μj=1|Cj|∑x∈Cjx
e) 如果所有的k个质心向量都没有发生变化,则转到步骤3)
3) 输出簇划分C={C1,C2,...Ck}
用一幅图表示的话更容易理解

############################################################
# 计算两点之间的欧氏距离并返回
############################################################
def elu_distance(a, b):
dist = np.sqrt(np.sum(np.square(np.array(a) - np.array(b))))
return dist
############################################################
# 从数据集dataset中随机选取k个数据作为中心(centroids)并返回
############################################################
def initial_centroids(dataset, k):
dataset = list(dataset)
centroids = random.sample(dataset, k)
return centroids
############################################################
# 对dataset中的每个点item, 计算item与centroids中k个中心的距离
# 根据最小距离将item加入相应的簇中并返回簇类结果cluster
############################################################
def min_distance(dataset, centroids):
cluster = dict()
k = len(centroids)
for item in dataset:
a = item
flag = -1
min_dist = float("inf")
for i in range(k):
b = centroids[i]
dist = elu_distance(a, b)
if dist < min_dist:
min_dist = dist
flag = i
if flag not in cluster.keys():
cluster[flag] = []
cluster[flag].append(item)
return cluster
############################################################
# 根据簇类结果cluster重新计算每个簇的中心
# 返回新的中心centroids
############################################################
def reassign_centroids(cluster):
# 重新计算k个质心
centroids = []
for key in cluster.keys():
centroid = np.mean(cluster[key], axis=0)
centroids.append(centroid)
return centroids
############################################################
# 计算簇内样本与各自中心的距离,累计求和
# sum_dist刻画簇内样本相似度, sum_dist越小则簇内样本相似度越高
############################################################
def closeness(centroids, cluster):
# 计算均方误差,该均方误差刻画了簇内样本相似度
# 将簇类中各个点与质心的距离累计求和
sum_dist = 0.0
for key in cluster.keys():
a = centroids[key]
dist = 0.0
for item in cluster[key]:
b = item
dist += elu_distance(a, b)
sum_dist += dist
return sum_dist
############################################################
# 展示聚类结果
############################################################
def show_cluster(centroids, cluster):
# 展示聚类结果
cluster_color = ['or', 'ob', 'og', 'ok', 'oy', 'ow']
centroid_color = ['dr', 'db', 'dg', 'dk', 'dy', 'dw']
for key in cluster.keys():
plt.plot(centroids[key][0], centroids[key][1], centroid_color[key], markersize=12)
for item in cluster[key]:
plt.plot(item[0], item[1], cluster_color[key])
plt.title("K-Means Clustering")
plt.show()
############################################################
# K-Means算法
# 1、加载数据集
# 2、随机选取k个样本作为中心
# 3、根据样本与k个中心的最小距离进行聚类
# 4、计算簇内样本相似度,并与上一轮相似度进行比较,两者误差小于阈值,则
# 停止运行,反之则更新各类中心,重复步骤3
############################################################
def k_means(k):
dataset = load_dataset()
centroids = initial_centroids(dataset, k)
cluster = min_distance(dataset, centroids)
current_dist = closeness(centroids, cluster)
old_dist = 0
while abs(current_dist - old_dist) >= 0.00001:
centroids = reassign_centroids(cluster)
cluster = min_distance(dataset, centroids)
old_dist = current_dist
current_dist = closeness(centroids, cluster)
return centroids, cluster当阈值为2和0.00001的结果分别如下:
0.00001

2
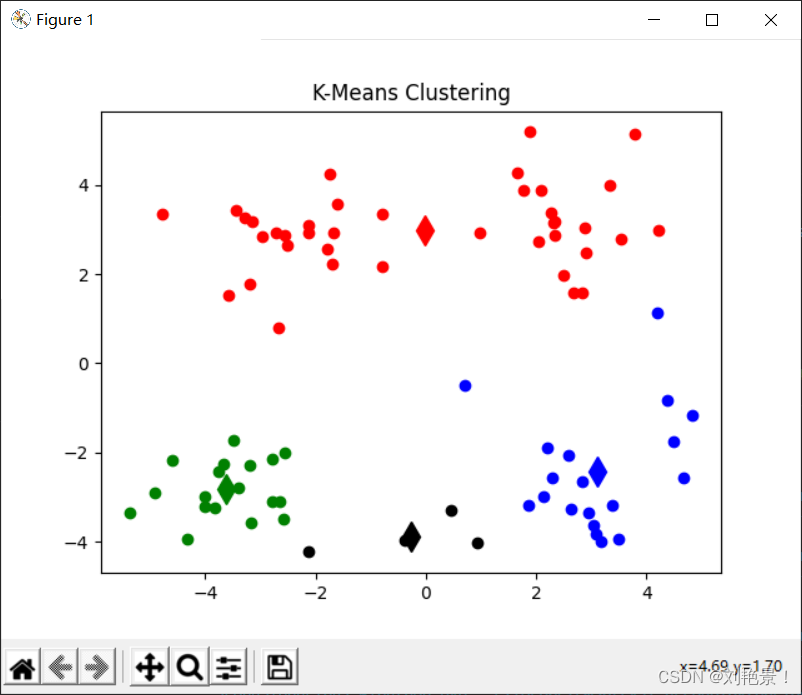
当k等于4或者5,结果如下:
k=4

k=5

<二>k-means算法优缺点
K-Means的主要优点有:
1)原理比较简单,实现也是很容易,收敛速度快。
2)聚类效果较优。
3)算法的可解释度比较强。
4)主要需要调参的参数仅仅是簇数k。
K-Means的主要缺点有:
1)K值的选取不好把握
2)对于不是凸的数据集比较难收敛
3)如果各隐含类别的数据不平衡,比如各隐含类别的数据量严重失衡,或者各隐含类别的方差不同,则聚类效果不佳。
4) 采用迭代方法,得到的结果只是局部最优。
5) 对噪音和异常点比较的敏感。
<三>优化后的k-means++算法:
a) 从输入的数据点集合中随机选择一个点作为第一个聚类中心μ1
b) 对于数据集中的每一个点xi,计算它与已选择的聚类中心中最近聚类中心的距离D(xi)=argmin||xi−μr||22r=1,2,...kselected
c) 选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
d) 重复b和c直到选择出k个聚类质心
e) 利用这k个质心来作为初始化质心去运行标准的K-Means算法
Distinguish between knn and k-means
K-Means是无监督学习的聚类算法,没有样本输出;而KNN是监督学习的分类算法,有对应的类别输出。KNN基本不需要训练,对测试集里面的点,只需要找到在训练集中最近的k个点,用这最近的k个点的类别来决定测试点的类别。而K-Means则有明显的训练过程,找到k个类别的最佳质心,从而决定样本的簇类别。
两者也有一些相似点,两个算法都包含一个过程,即找出和某一个点最近的点。两者都利用了最近邻的思想.














 6284
6284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









