






CVPR2022论文TransWeather: 基于Transformer的恶劣天气图像恢复技术详解
引言
在计算机视觉领域,恶劣天气条件下的图像恢复是一个重要研究方向。雨、雾、雪等天气现象会显著降低图像质量,影响视觉系统的性能,包括检测、分割和深度估计等任务[10]。TransWeather作为一种基于Transformer的图像恢复模型,通过创新的网络架构和设计,为解决恶劣天气条件下的图像恢复问题提供了高效解决方案。本文将深入分析TransWeather的设计细节,包括其创新点、网络架构、关键技术以及性能表现。
TransWeather的提出背景
在恶劣天气图像恢复领域,早期的研究主要基于经验观察建立天气条件的模型[10]。这些方法通常针对特定天气条件进行建模,缺乏通用性。例如:
- 雨滴被建模为 I = ( 1 − M ) B + R I = (1−M)B + R I=(1−M)B+R,其中M是掩码,B是背景,R是雨滴残留
- 雨雾被建模为 I = T ( B + ∑ R i ) + ( 1 − T ) A I = T(B + \sum R_i) + (1−T)A I=T(B+∑Ri)+(1−T)A,其中T是散射效应产生的透射图,A是场景中的大气光
- 雪通常被建模为
I
=
M
S
+
M
(
1
−
z
)
I = M S + M (1−z)
I=MS+M(1−z),其中z是指示雪的掩码,S对应雪粒
虽然这些方法针对特定任务取得了良好效果,但缺乏解决多种天气问题的通用模型。最近,基于CNN的方法如All-in-One网络开始尝试解决这个问题,但仍然使用多个编码器来处理不同任务,计算复杂度较高[10]。
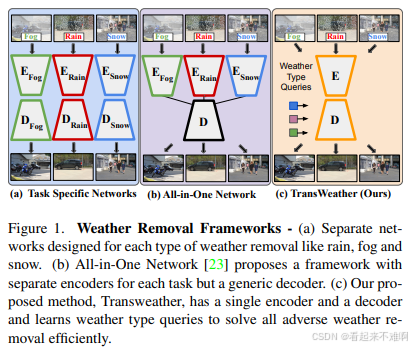
TransWeather的核心创新点
TransWeather提出了一种基于Transformer的端到端模型,与现有方法相比,主要创新点包括:
- 单编码器-单解码器架构:TransWeather使用一个编码器和一个解码器来解决所有恶劣天气去除问题,而非为每个任务使用单独的编码器[13]。
- 可学习的天气类型嵌入:在解码器中引入了可学习的天气类型查询(Weather Type Queries),使模型能够学习并适应不同类型的天气降质[10]。
- Intra-Patch Transformer结构:在编码器中使用了Intra-Patch Transformer(Intra-PT)块,增强对小尺寸天气降质(如雨滴、雨线、雪)的局部注意力[10]。
- 高效参数利用:TransWeather有31M参数,少于All-in-One网络的44M参数,但性能更优[10]。
TransWeather网络架构详解
TransWeather的网络架构由三个主要部分组成:Transformer编码器、Transformer解码器和卷积投影块。下面我们详细分析每个部分的结构和功能。
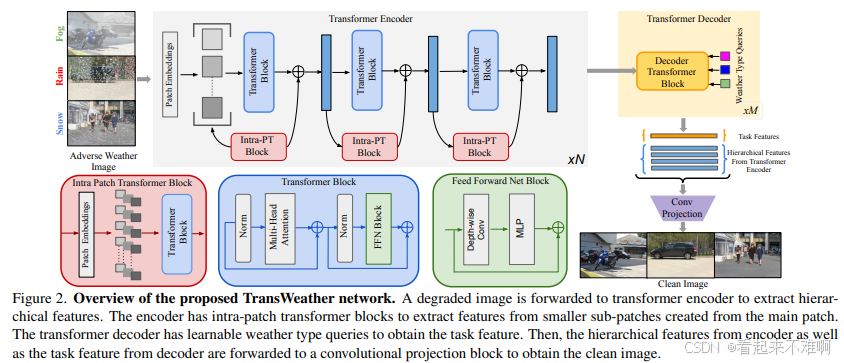
Transformer编码器
Transformer编码器生成输入图像的层次化特征表示,提取多级特征。在编码器的每个阶段,通过执行重叠patch合并来降低分辨率,以确保Transformer同时学习粗粒度和细粒度信息[10]。
Transformer块:
在每个Transformer块中,使用多头自注意力层和前馈网络来计算自注意力特征。其计算过程可以总结为:
T
i
(
I
i
)
=
F
F
N
(
M
S
A
(
I
i
)
+
I
i
)
T_i(I_i) = FFN(MSA(I_i) + I_i)
Ti(Ii)=FFN(MSA(Ii)+Ii)
其中,T表示Transformer块,FFN表示前馈网络块,MSA表示多头自注意力,I是输入,i表示编码器中的阶段。
在原始自注意力网络中,查询(Q)、键(K)和值(V)具有相同的维度,计算如下:
A
t
t
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
)
V
Attn(Q,K,V) = softmax\left(\frac{QK^T}{\sqrt{d}}\right)V
Attn(Q,K,V)=softmax(dQKT)V
其中d表示维度。每个Transformer块中有多个注意力头,头的数量是超参数,可以在Transformer编码器的每个阶段进行变化。
为了降低原始自注意力的计算复杂度,TransWeather引入了减少比R:
- 将键的维度从(N,C)重塑为(NR, C.R)
- 使用线性层将第二个维度从C.R恢复为C
- 这样,键的维度变为N×R × C,从而在计算自注意力时降低了复杂度
自注意力特征随后传递到前馈网络块。与ViT不同,TransWeather在前馈网络中引入了深度可分离卷积到MLP,以引入局部信息并为Transformer提供位置信息[10]。
Intra-Patch Transformer块:
Intra-Patch Transformer块位于Transformer编码器各阶段之间。这些块接收从原始patch创建的子patch作为输入。子patch的尺寸是原始patch高度和宽度的一半。Intra-PT使用类似于上述Transformer块的结构,但使用较高的减少比来提高计算效率。
Intra-PT块有助于提取有助于去除较小降质的精细细节,因为在较小的patch上操作时,可以更好地处理较小的降质。值得注意的是,Intra-PT块在特征级别创建patch,除了在第一阶段是在图像级别创建外[10]。
编码器中前馈过程的公式可以总结为:
Y i = M T i ( X i ) + I n t r a P T i ( P ( X i ) ) Y_i = MT_i(X_i) + IntraPT_i(P(X_i)) Yi=MTi(Xi)+IntraPTi(P(Xi))
其中,I是每个阶段输入到Transformer的输入,Y是每个阶段的输出,MT是主Transformer块,IntraPT是Intra-Patch Transformer块,P()对应于从输入patch创建子patch的过程,i表示阶段。
Transformer解码器
在原始Transformer解码器中,使用自回归解码器逐个元素预测输出序列。受DETR启发,TransWeather定义了天气类型查询来解码任务,预测任务特征向量,并使用它来恢复干净图像[10]。
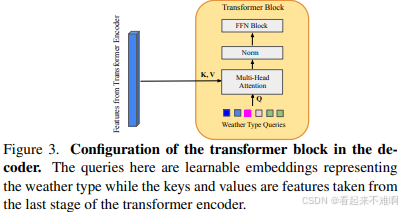
这些天气类型查询是可学习嵌入,与网络的其他参数一起学习。这些查询关注Transformer编码器的特征输出。解码器中的Transformer块与编码器-解码器Transformer块类似。与自注意力Transformer块不同,这里的Q是天气类型可学习嵌入,而K和V来自Transformer编码器最后一阶段的特征。
解码器中的Transformer块配置如图所示:
- 查询是表示天气类型的可学习嵌入
- 键和值来自Transformer编码器的最后一阶段特征
- 解码器在单个阶段运行,但有多个块
卷积投影块
来自Transformer编码器的层次特征集和来自Transformer解码器的任务特征被传递通过一系列4个卷积层来输出干净图像。在每个卷积层之前使用上采样层以恢复到原始图像大小。在卷积尾部的每个阶段都有来自Transformer编码器的跳越连接。最终层使用tanh激活函数。
TransWeather的损失函数
TransWeather通过端到端方式训练,使用预测(Î)和地面真实(G)之间的平滑L1损失。平滑L1损失定义为:
L
s
m
o
o
t
h
L
1
=
{
0.5
E
2
如果
∣
E
∣
<
1
∣
E
∣
−
0.5
其他情况
L_{smoothL1} = \begin{cases} 0.5E^2 & \text{如果 } |E| < 1 \\ |E| - 0.5 & \text{其他情况} \end{cases}
LsmoothL1={0.5E2∣E∣−0.5如果 ∣E∣<1其他情况
其中E = Î - G。
此外,还添加了一个感知损失,用于测量预测和地面真实特征之间的差异。使用在ImageNet上预训练的VGG16网络提取这些特征。从VGG16的第3、第8和第15层提取特征来计算感知损失。感知损失的公式如下:
L
p
e
r
c
e
p
t
u
a
l
=
L
M
S
E
(
V
G
G
3
,
8
,
15
(
I
^
)
,
V
G
G
3
,
8
,
15
(
G
)
)
L_{perceptual} = L_{MSE}(VGG_{3,8,15}(\hat{I}), VGG_{3,8,15}(G))
Lperceptual=LMSE(VGG3,8,15(I^),VGG3,8,15(G))
总损失可以总结为:
L
t
o
t
a
l
=
L
s
m
o
o
t
h
L
1
+
λ
L
p
e
r
c
e
p
t
u
a
l
L_{total} = L_{smoothL1} + \lambda L_{perceptual}
Ltotal=LsmoothL1+λLperceptual
其中λ是控制感知损失和L1损失对总损失贡献的权重。
TransWeather的训练与测试
TransWeather使用PyTorch框架实现,并使用NVIDIA RTX 8000 GPU进行训练。使用Adam优化器和0.0002的学习率。使用一个学习率调度器,在100和150个epoch后将学习率降低2倍。网络总共训练200个epoch,批量大小为32[10]。
训练数据集
TransWeather在多种天气条件降质的图像组合上训练,类似于All-in-One网络。遵循All-in-One用于公平比较的相同训练集分布。训练数据由9,000张来自Snow100K的图像、1,069张来自Raindrop的图像和9,000张Outdoor-Rain图像组成。将这些训练数据的组合称为"All-Weather",以便更好地表示[10]。
测试数据集
TransWeather在合成和真实世界数据集上进行测试。使用Test1数据集、RainDrop测试数据集和Snow100k-L测试集来测试该方法。此外,还评估了受雨线和雨滴降质的真实世界图像[10]。
TransWeather的性能比较
与特定任务方法的比较
TransWeather与为每个任务专门设计的最先进方法进行了比较,包括雨滴去除、雪去除和雨+雾霾去除。对于雨滴去除,与最先进方法如注意力GAN、Quan等人和互补级联网络(CC)进行了比较。对于雪去除,与Desnow-Net、JSTASR和深度密集多尺度网络(DDMSNet)进行了比较。对于雨+雾去除,与HRGAN、Details-Net、挤压和激发上下文聚合网络(RESCAN)和多阶段渐进恢复网络(MPRNet)进行了比较。还比较了最近的Transformer网络Swin-IR在所有数据集上的性能[10]。
与All-in-One网络的比较
TransWeather还与All-in-One网络进行了比较,后者使用单个模型实例执行所有任务。TransWeather在所有这些任务上使用单个模型实例进行训练,性能优于All-in-One网络[10]。
定量比较结果
Test1 (雨+雾)数据集:
| 方法 | PSNR(↑) | SSIM(↑) |
|---|---|---|
| 任务特定 | DetailsNet + Dehaze (DHF) | 13.36 |
| 任务特定 | DetailsNet + Dehaze (DRF) | 15.68 |
| 任务特定 | RESCAN + Dehaze (DHF) | 14.72 |
| 任务特定 | RESCAN + Dehaze (DHF) | 15.91 |
| 任务特定 | pix2pix | 19.09 |
| 任务特定 | HRGAN | 21.56 |
| 任务特定 | Swin-IR | 23.23 |
| 任务特定 | MPRNet | 21.90 |
| 多任务 | All-in-One | 24.71 |
| TransWeather | 27.96 | 0.9509 |
| SnowTest100k-L数据集: | ||
| 方法 | PSNR(↑) | SSIM(↑) |
| ------ | --------- | --------- |
| 任务特定 | DetailsNet | 19.18 |
| 任务特定 | DesnowNet | 27.17 |
| 任务特定 | JSTASR | 25.32 |
| 任务特定 | Swin-IR | 28.18 |
| 任务特定 | DDMSNET | 28.85 |
| 多任务 | All-in-One | 28.33 |
| TransWeather | 28.48 | 0.9308 |
| RainDrop数据集: | ||
| 方法 | PSNR(↑) | SSIM(↑) |
| ------ | --------- | --------- |
| 任务特定 | Pix2pix | 28.02 |
| 任务特定 | Attn. GAN | 30.55 |
| 任务特定 | Quan et al. | 31.44 |
| 任务特定 | Swin-IR | 30.82 |
| 任务特定 | CCN | 31.34 |
| 多任务 | All-in-One | 31.12 |
| TransWeather | 28.84 | 0.9460 |
| 从这些结果可以看出,TransWeather在大多数情况下优于All-in-One网络和其他特定任务的方法[10]。 |
推理速度比较
在推理速度方面,TransWeather在处理256×256尺寸的图像时仅需0.14秒,比之前的天气去除方法更快。这使得TransWeather更适合实时系统应用[10]。
TransWeather的局限性
尽管TransWeather取得了良好的性能,但仍存在一些局限性:
- 高强度降雨处理不佳:在一些真实世界图像中,当雨强度很高时,TransWeather的性能不够理想。这是因为高强度雨在尺寸和强度上与模型训练时使用的合成数据有很大差异。
- 难以去除飞溅效果:当雨滴击打场景中物体或人物表面时,会产生飞溅效果。目前包括TransWeather在内的所有方法都无法很好地去除这种飞溅效果[10]。
TransWeather与All-in-One网络的对比
TransWeather与All-in-One网络有以下主要区别:
- 基础架构:All-in-One是基于CNN的方法,而TransWeather使用为低级视觉任务构建的Transformer骨干,特别注重处理较小的patch。
- 编码器结构:All-in-One使用多个编码器,而TransWeather利用单个编码器。
- 训练方法:All-in-One使用对抗训练和神经架构搜索,而TransWeather仅使用L1和感知损失的组合,使训练更稳定。
- 性能比较:TransWeather具有更快的推理速度,更少的参数数量,同时获得更好的定量和定性性能[10]。
TransWeather的未来研究方向
基于TransWeather的现有成果,未来的研究方向可以包括:
- 改进高强度降雨处理:开发更有效的模型来处理高强度降雨和飞溅效果。
- 扩展到更多天气条件:将模型扩展到处理更多类型的天气降质,如雾霾、沙尘暴等。
- 实时应用优化:进一步优化模型以实现在移动设备等资源受限环境中的实时应用。
- 与其他计算机视觉任务的结合:探索TransWeather在其他计算机视觉任务中的应用,如在恶劣天气条件下的目标检测和分割。
结论
TransWeather作为一种基于Transformer的端到端模型,为解决恶劣天气条件下的图像恢复问题提供了高效解决方案。通过使用单编码器-单解码器架构、可学习的天气类型嵌入和Intra-Patch Transformer结构,TransWeather在多种天气降质条件下表现出色,性能优于现有方法。
TransWeather的主要优势包括:
- 计算效率高,参数量少(31M)
- 推理速度快(0.14秒/张256×256图像)
- 性能优于All-in-One网络和其他特定任务的方法
- 能够处理多种天气条件,包括雨、雾、雪及其组合
尽管存在处理高强度降雨和飞溅效果的局限性,但TransWeather代表了恶劣天气图像恢复领域的重要进展,为未来研究提供了坚实基础。随着深度学习技术的不断发展,TransWeather框架有望在更多实际应用场景中发挥重要作用。
参考文献
[10] TransWeather: Transformer-based Restoration of Images Degraded by Adverse Weather Conditions. https://arxiv.org/pdf/2111.14813.
[13] 【cvpr2022】TransWeather: Transformer-based Restoration of … https://blog.csdn.net/weixin_44734371/article/details/130855475.


















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











