







图像修复-恶劣天气图像修复-CVPR2021-TransWeather: Transformer-based Restoration of Images Degraded by Adverse Weather Conditions
文章目录
TransWeather 提出了一种基于 Transformer 的端到端模型,采用 Intra-Patch Transformer 结构增强局部注意力,并引入可学习的天气类型嵌入,仅用单个编码器和解码器即可高效去除多种恶劣天气条件,在多个数据集上显著超越现有方法。
论文链接:TransWeather: Transformer-based Restoration of Images Degraded by Adverse Weather Conditions
一、主要创新点
-
统一的 Transformer 结构:提出了一种基于 Transformer 的端到端模型 TransWeather,仅使用单个编码器和解码器即可去除所有类型的恶劣天气条件(如雨、雾、雪),相比于 All-in-One 方法使用多个编码器的设计更加高效。
-
引入 Intra-Patch Transformer Blocks:在 Transformer 编码器中采用 Intra-Patch Transformer 结构,增强图像块(patch)内部的注意力机制,从而更有效地去除较小尺度的天气退化影响,提高图像修复能力。
-
可学习的天气类型嵌入(Weather Type Embeddings):在 Transformer 解码器中引入了可学习的天气类型嵌入,使模型能够自适应不同的天气退化情况,从而提升去天气效果(主要是借鉴思想是Detr的cross attention 的块查询机制)。
-
性能突破:TransWeather 在多个测试数据集上显著超越了 All-in-One 方法以及针对特定天气类型优化的去天气方法,例如:
-
在 Test1(雨+雾)数据集上提升 +6.34 PSNR。
-
在 SnowTest100K-L 数据集上提升 +4.93 PSNR。
-
在 RainDrop 测试集上提升 +3.11 PSNR。
-
二、模型架构图
从图中可以看出主要由三部分组成:
Transformer Encoder(编码器):Transformer Encoder 采用层次化结构,结合多头自注意力和前馈神经网络(FFN)进行特征提取,并通过重叠补丁合并(Overlapped Patch Merging)保持特征一致性。为了提高计算效率,模型使用缩减比 R 降低自注意力计算复杂度,并在 FFN 内引入深度卷积(DW-C)以增强局部特征学习。此外,设计了 Intra-Patch Transformer Block(Intra-PT),在各阶段内部对特征划分子补丁进行额外的自注意力计算,专门提取小尺度特征,以更好地去除雨滴、轻雾等细微降质。最终,Intra-PT 结果与主 Transformer Block 特征融合,实现高效的全局-局部特征提取,从而在各种天气降质场景下取得更优的图像恢复效果。Transformer Decoder(解码器):Transformer Decoder 受 Transformer 和 DETR 结构启发,采用可学习的天气类型查询(weather type queries)来解码任务,并预测任务特征向量,以恢复受天气影响的图像。与传统自注意力机制不同,该 Decoder 采用查询(Q)作为天气类型嵌入,而键(K)和值(V)来自 Transformer Encoder 的最后阶段特征。Decoder 通过单阶段多块结构提取和融合特征,并结合 Transformer Encoder 的各层信息,最终通过卷积尾部(Convolutional Tail)重建清晰图像。这种设计使模型能够适应多种天气降质情况,并提升恢复质量。Convolutional Projection Block(卷积映射恢复):模型将 Transformer Encoder 的层次化特征与 Transformer Decoder 任务特征作为输入,并通过 四层卷积 逐步重建清晰图像。每层卷积前加入 上采样层 以恢复原始分辨率,同时在卷积尾部引入 跳跃连接,与 Transformer Encoder 进行特征融合,以提高恢复能力。最后,采用tanh激活函数约束输出,确保生成的去天气降质图像具有稳定的像素分布。
下面将从源码层面解释Transformer Encoder(编码器)和Transformer Decoder(解码器),对于Convolutional Projection Block(卷积映射恢复)只是简单的卷积还原操作。
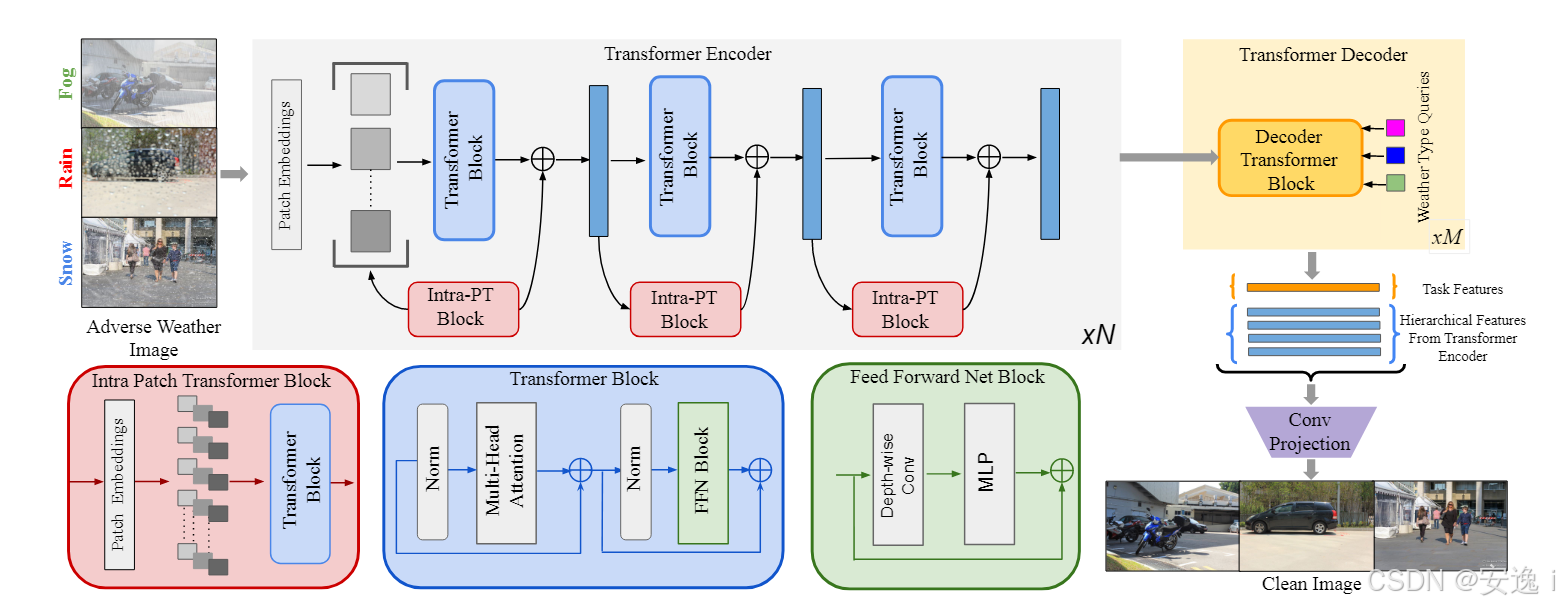
三、Transformer Encoder
- 层次化特征提取:在 Transformer Encoder 内部,通过多级结构提取不同层次的特征,使模型能够捕捉低级和高级信息,提高对各种天气降质的恢复能力。
- 重叠补丁合并(Overlapped Patch Merging):在每个阶段,通过合并重叠补丁(patches)来保持特征尺寸一致,同时提高特征表达能力,减少信息损失。
- Transformer Block 计算:使用多头自注意力(MSA)计算输入特征的自注意力信息,并通过前馈神经网络(FFN)进一步处理,使模型能够学习到全局和局部信息。
- 计算复杂度优化:为了降低计算量,引入缩减比 R,将自注意力计算复杂度从 O(N2)降至 O(N2R),优化计算效率。
- 改进 FFN 结构:在 FFN 内部引入深度卷积(Depth-Wise Convolution, DW-C),增强 Transformer 位置感知能力,同时保留局部信息,提高去天气降质效果。
- Intra-Patch Transformer Block(Intra-PT):在主 Transformer Block 之间额外加入 Intra-PT 模块,该模块对输入特征划分子补丁(sub-patches),专门用于提取小尺度特征,有助于消除微小降质影响,如小雨滴或轻雾。
- 融合 Intra-PT 结果:Intra-PT 的自注意力特征与主 Transformer Block 提取的特征在同一阶段进行融合,使最终特征表达更加丰富,提高图像恢复质量。
Transformer Encoder源码
# 来自源码文件:https://github.com/jeya-maria-jose/TransWeather/blob/main/transweather_model.py
class EncoderTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1]):
super().__init__()
self.num_classes = num_classes
self.depths = depths
# 定义不同阶段的 Patch Embedding
self.patch_embed1 = OverlapPatchEmbed(img_size=img_size, patch_size=7, stride=4, in_chans=in_chans,
embed_dim=embed_dims[0])
self.patch_embed2 = OverlapPatchEmbed(img_size=img_size // 4, patch_size=3, stride=2, in_chans=embed_dims[0],
embed_dim=embed_dims[1])
self.patch_embed3 = OverlapPatchEmbed(img_size=img_size // 8, patch_size=3, stride=2, in_chans=embed_dims[1],
embed_dim=embed_dims[2])
self.patch_embed4 = OverlapPatchEmbed(img_size=img_size // 16, patch_size=3, stride=2, in_chans=embed_dims[2],
embed_dim=embed_dims[3])
# 定义 Intra-patch transformer blocks 的 Patch Embedding
self.mini_patch_embed1 = OverlapPatchEmbed(img_size=img_size // 4, patch_size=3, stride=2, in_chans=embed_dims[0],
embed_dim=embed_dims[1])
self.mini_patch_embed2 = OverlapPatchEmbed(img_size=img_size // 8, patch_size=3, stride=2, in_chans=embed_dims[1],
embed_dim=embed_dims[2])
self.mini_patch_embed3 = OverlapPatchEmbed(img_size=img_size // 16, patch_size=3, stride=2, in_chans=embed_dims[2],
embed_dim=embed_dims[3])
self.mini_patch_embed4 = OverlapPatchEmbed(img_size=img_size // 32, patch_size=3, stride=2, in_chans=embed_dims[0],
embed_dim=embed_dims[3])
# 定义主编码器部分的 Transformer Blocks
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # 计算 Stochastic Depth decay
cur = 0
self.block1 = nn.ModuleList([
Block(dim=embed_dims[0], num_heads=num_heads[0], mlp_ratio=mlp_ratios[0], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i],
norm_layer=norm_layer, sr_ratio=sr_ratios[0])
for i in range(depths[0])])
self.norm1 = norm_layer(embed_dims[0])
# 定义 Intra-patch Transformer Block
self.patch_block1 = nn.ModuleList([
Block(dim=embed_dims[1], num_heads=num_heads[0], mlp_ratio=mlp_ratios[0], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur],
norm_layer=norm_layer, sr_ratio=sr_ratios[0])
])
self.pnorm1 = norm_layer(embed_dims[1])
# 继续构建后续层的 Transformer Blocks
cur += depths[0]
self.block2 = nn.ModuleList([...]) # 类似 block1 的结构
self.norm2 = norm_layer(embed_dims[1])
self.patch_block2 = nn.ModuleList([...])
self.pnorm2 = norm_layer(embed_dims[2])
cur += depths[1]
self.block3 = nn.ModuleList([...])
self.norm3 = norm_layer(embed_dims[2])
self.patch_block3 = nn.ModuleList([...])
self.pnorm3 = norm_layer(embed_dims[3])
cur += depths[2]
self.block4 = nn.ModuleList([...])
self.norm4 = norm_layer(embed_dims[3])
self.apply(self._init_weights) # 初始化权重
def _init_weights(self, m):
"""初始化网络权重"""
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward_features(self, x):
"""前向传播特征提取"""
B = x.shape[0]
outs = []
# Stage 1
x1, H1, W1 = self.patch_embed1(x)
x2, H2, W2 = self.mini_patch_embed1(x1.permute(0, 2, 1).reshape(B, 64, H1, W1))
for blk in self.block1:
x1 = blk(x1, H1, W1)
x1 = self.norm1(x1).reshape(B, H1, W1, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x1)
# 类似的处理 Stage 2, 3, 4
return outs
def forward(self, x):
"""前向传播"""
return self.forward_features(x)
四、Transformer Decoder
- 借鉴自 Transformer 和 DETR:原始 Transformer Decoder 采用自回归(autoregressive)方式逐步预测序列,而 DETR 使用对象查询(object queries)来解码目标框坐标和类别标签。受此启发,本文引入天气类型查询(weather type queries),用于解码任务并预测任务特征向量,以恢复干净图像。
- 天气类型查询(Weather Type Queries):这些查询是可学习的嵌入(learnable embeddings),在模型训练过程中与其他参数一起学习,使模型能够适应不同的天气降质类型。
- 注意力机制:Transformer Decoder 关注来自 Transformer Encoder 的特征输出,通过查询机制提取任务相关的信息。
- 单阶段多块结构:与典型的 Encoder-Decoder 结构类似,该 Transformer Decoder 仅在单一阶段运行,但包含多个 Transformer Block,每个块进行特征提取和融合。
- 查询-键值(QKV)设计:不同于传统的自注意力(self-attention)机制,该 Transformer Decoder 采用 Q(查询)为天气类型查询的可学习嵌入,而 K 和 V(键和值)分别来自 Transformer Encoder 的最终阶段特征。
- 任务特征向量:Decoder 输出的解码特征表示任务特征向量(task feature vector),该特征向量与 Transformer Encoder 各阶段的特征融合,以增强恢复能力。
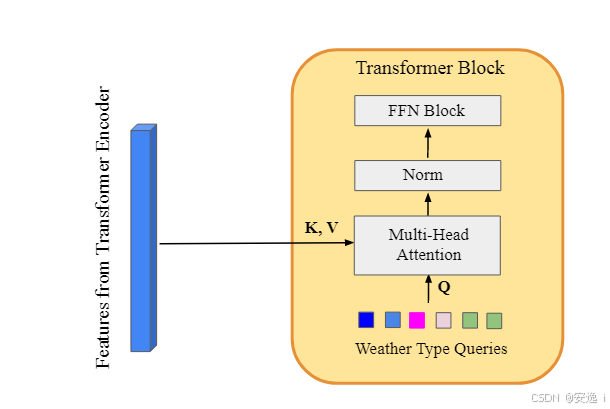
Transformer Decoder源码
# 来自源码文件:https://github.com/jeya-maria-jose/TransWeather/blob/main/transweather_model.py
class DecoderTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1]):
"""
Transformer 解码器
参数:
- img_size: 输入图像尺寸
- patch_size: Patch 的大小
- in_chans: 输入通道数
- num_classes: 分类类别数
- embed_dims: 每个阶段的嵌入维度
- num_heads: 每个阶段的注意力头数
- mlp_ratios: MLP 扩展比例
- qkv_bias: 是否使用 QKV 偏置
- qk_scale: QK 缩放因子
- drop_rate: Dropout 比例
- attn_drop_rate: 注意力 Dropout 比例
- drop_path_rate: Drop Path 比例
- norm_layer: 归一化层类型
- depths: 每个阶段的 Transformer Block 数量
- sr_ratios: 空间降采样率
"""
super().__init__()
self.num_classes = num_classes
self.depths = depths
# Patch 嵌入层 (用于处理 Encoder 的输出)
self.patch_embed1 = OverlapPatchEmbed(img_size=img_size // 16, patch_size=3, stride=2,
in_chans=embed_dims[3], embed_dim=embed_dims[3])
# 计算 Drop Path 比例
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
# Transformer 解码器第一阶段
self.block1 = nn.ModuleList([
Block_dec(dim=embed_dims[3], num_heads=num_heads[3], mlp_ratio=mlp_ratios[3], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i],
norm_layer=norm_layer, sr_ratio=sr_ratios[3])
for i in range(depths[0])
])
self.norm1 = norm_layer(embed_dims[3])
cur += depths[0]
# 初始化权重
self.apply(self._init_weights)
def _init_weights(self, m):
"""
权重初始化方法
"""
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def init_weights(self, pretrained=None):
"""
加载预训练权重
"""
if isinstance(pretrained, str):
logger = get_root_logger()
load_checkpoint(self, pretrained, map_location='cpu', strict=False, logger=logger)
def reset_drop_path(self, drop_path_rate):
"""
重新设置 Drop Path 率
"""
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(self.depths))]
cur = 0
for i in range(self.depths[0]):
self.block1[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[0]
for i in range(self.depths[1]):
self.block2[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[1]
for i in range(self.depths[2]):
self.block3[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[2]
for i in range(self.depths[3]):
self.block4[i].drop_path.drop_prob = dpr[cur + i]
def forward_features(self, x):
"""
提取解码器的特征
"""
x = x[3] # 选取 Encoder 的最后一层特征
B = x.shape[0] # 获取 batch size
outs = []
# 第一阶段解码
x, H, W = self.patch_embed1(x)
for blk in self.block1:
x = blk(x, H, W)
x = self.norm1(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
return outs
def forward(self, x):
"""
前向传播
"""
x = self.forward_features(x)
# x = self.head(x) # 这里可以加上分类头部
return x


















 5047
5047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









