






通过对蒲江县2021物流发展现状进行分析,运用数据爬取,使用高德地图API实现批量查询各小区中每一个地址(省、区/市县、乡镇)的经纬度数据,运用Geopy库中的默认WGS-84模型计算出误差在0.5%以内的小区距离,并以矩阵的形式导入Excel文件中,最后运用所获数据结合双约束重力模型,用编程迭代实现了蒲江县2025、2030、2035年的物流分布量预测。2021小区矩阵如下:
| 小区 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 合计 |
| 1 | 46317 | 91635 | 73508 | 59006 | 8616 | 67055 | 11590 | 97036 | 31078 | 16087 | 128516 | 159996 | 53264 | 11482 | 120421 | 73041 | 1048648 |
| 2 | 109762 | 91635 | 64444 | 241635 | 3951 | 32679 | 7231 | 2830 | 31078 | 37074 | 13791 | 37776 | 70149 | 12010 | 5090 | 8688 | 769823 |
| 3 | 121544 | 91635 | 46317 | 80668 | 4107 | 8478 | 3232 | 5258 | 3166 | 3154 | 4497 | 6350 | 43070 | 37074 | 3034 | 3166 | 464750 |
| 4 | 272904 | 146016 | 91635 | 73508 | 2566 | 76571 | 3819 | 35167 | 32613 | 15146 | 48875 | 95783 | 84036 | 7483 | 41074 | 6164 | 1033360 |
| 5 | 14864 | 31078 | 8364 | 20806 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 75112 |
| 6 | 63559 | 162994 | 13089 | 112488 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 352130 |
| 7 | 61059 | 31078 | 53804 | 127017 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 272958 |
| 8 | 62858 | 11842 | 7009 | 53846 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 135555 |
| 9 | 5894 | 11093 | 2344 | 2764 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 22095 |
| 10 | 4095 | 1817 | 1637 | 2296 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 9845 |
| 11 | 7093 | 5894 | 3022 | 4743 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 20752 |
| 12 | 64159 | 13425 | 12628 | 54865 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 145077 |
| 13 | 71055 | 31078 | 7093 | 97036 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 206262 |
| 14 | 21082 | 21082 | 11782 | 12868 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 66814 |
| 15 | 90722 | 11884 | 18444 | 31546 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 152596 |
| 16 | 40072 | 7093 | 2896 | 74586 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 124647 |
| 合计 | 1057039 | 761279 | 418016 | 1049678 | 19240 | 184783 | 25872 | 140291 | 97935 | 71461 | 195679 | 299905 | 250519 | 68049 | 169619 | 91059 |
|
在双约束重力模型中物流分布量的计算公式如下:
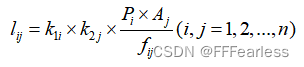


确定阻抗矩阵
考虑蒲江与各小区的运输费用难以查询,并与各地区流通的交通工具并不相似,故费用与时间均不能作为阻抗矩阵的依据。故此处,以各小区的距离为阻抗矩阵。因每个小区的区域广阔,故取小区间的几何中心作为参考点,以各小区几何中心点间的距离为各小区之间的距离。
小区间距离获取的方法如下:首先在高德开发平台上申请用户key,使用高德地图API实现批量查询各小区中每一个地址(省、区/市县、乡镇)的经纬度,整理表格,用分类汇总方法计算出每一个L-OD小区的平均经纬度。
将小区经纬度数据导入python中,用Geopy库中的默认WGS-84模型计算出误差在0.5%以内的小区距离,并以矩阵的形式导入excel表中。
物流分布量预测
将2025年、2030年、2035年的预测物流发生量、吸引量以及各小区之间的距离阻抗矩阵数据导入Python中,用编程的方法进行重力模型系数迭代,由于所给数据显示小区5到小区16之间没有物流交换活动,因此进行重力模型系数迭代时不应考虑5-16小区。
将误差率err设置为0.000001,结果显示2025年预测迭代了7344次,2030年预测迭代了9019次,2035年预测迭代了10095次。将分布量预测结果导入xls文件中。应注意由于小区5到小区16之间没有物流交换,重力模型系数迭代时也未考虑5-16小区,因此在物流分布量预测表中也应人为将5-16小区之间的分布量设置为0,物流分布量迭代实现代码如下:
import copy
import numpy as np
import pandas as pd
import xlwt
import xlrd
#读取发生量或吸引量
df=pd.read_excel(r"D:\预测2025.xlsx")
dis=pd.read_excel('D:\距离.xlsx',header=None) #读取距离矩阵
A=df['A'] #读取第一列
P=df['P'] #读取第二列
#获取行列数
row=len(dis)
col=dis.columns.size
cut=4
k2=np.ones(16) #初始化重力模型系数
k1=np.ones(16)
err=0.000001 #设定误差率
x=0 #控制循环条件
ite=0 #迭代次数
mat1=np.zeros(16)
mat2=np.ones(16) #初始化迭代矩阵
while x==0 :
for i in range(cut):
a=0
for j in range(col):
if dis[i][j]!=0:
a=a+k2[j]*A[j]/dis[i][j]
a=1/a
k1[i]=a
for i in range(cut,row):
for j in range(cut):
if dis[i][j]!=0:
a=a+k2[j]*A[j]/dis[i][j]
a=1/a
k1[i]=a
for j in range(cut):
a=0
for i in range(row):
if dis[i][j]!=0:
a+=k1[i]*P[i]/dis[i][j]
a=1/a
k2[j]=a
for j in range(cut,col):
for i in range(cut):
if dis[i][j]!=0:
a=a+k1[i]*P[i]/dis[i][j]
a=1/a
k2[j]=a
ite=ite+1
mat2=np.row_stack((mat2,k2))
mat1=np.row_stack((mat1,k1)) #更新矩阵
#判断是否继续迭代
for j in range(col):
if abs(mat1[ite][j]-mat1[ite-1][j])>=err:
x1=0
break
else:
x1=1
for j in range(col):
if abs(mat2[ite][j]-mat2[ite-1][j])>=err:
x2=0
break
else:
x2=1
if x2==1&x1==1 :
x=1
else:
x=0
print("mat1矩阵:",mat1)
print("mat2矩阵:",mat2)
print("ite=",ite)
#计算分布量
l=np.zeros((16,16))
for i in range(row):
for j in range(col):
l[i][j]=k1[i]*k2[j]*P[i]*A[j]/dis[i][j]
for i in range(cut,row):
for j in range(cut,col):
l[i][j]=0
filename =xlwt.Workbook() #创建工作簿
sheet1 = filename.add_sheet(u'sheet1',cell_overwrite_ok=True) #创建sheet
for i in range (0,16):
for j in range (0,16):
sheet1.write(i,j,l[i,j])
filename.save('D:\物流分布量2.xls')代码运行结果如下:
将预测分布量导入excel,以2025年为例,预测结果整理如下:
| 2025年预测OD分布 | ||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 实际求和值 | Pi | |
| 1 | 0 | 161815 | 71537 | 383090 | 21764 | 178209 | 29593 | 86654 | 76897 | 32487 | 75806 | 146108 | 67039 | 18159 | 52019 | 40316 | 1441491 | 1441527 |
| 2 | 121147 | 0 | 155903 | 295102 | 1162 | 17899 | 1543 | 35272 | 16045 | 11271 | 58761 | 100431 | 116782 | 37429 | 64744 | 24722 | 1058213 | 1058239 |
| 3 | 59210 | 172355 | 0 | 176152 | 572 | 8990 | 742 | 15726 | 7205 | 6001 | 23005 | 39425 | 60862 | 12767 | 40984 | 14859 | 638854 | 638870 |
| 4 | 287945 | 296270 | 159969 | 0 | 2949 | 48910 | 3687 | 55190 | 34463 | 48470 | 111403 | 126236 | 99504 | 25125 | 75207 | 45147 | 1420476 | 1420511 |
| 5 | 80450 | 5739 | 2554 | 14504 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 103248 | 103253 |
| 6 | 310231 | 41619 | 18908 | 113278 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 484037 | 484056 |
| 7 | 296446 | 20646 | 8978 | 49138 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 375207 | 375222 |
| 8 | 71381 | 38809 | 15651 | 60485 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 186327 | 186341 |
| 9 | 15275 | 4257 | 1729 | 9108 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 30369 | 30373 |
| 10 | 3686 | 1708 | 823 | 7316 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 13533 | 13533 |
| 11 | 6547 | 6778 | 2400 | 12800 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 28525 | 28527 |
| 12 | 58757 | 53946 | 19155 | 67540 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 199398 | 199430 |
| 13 | 44292 | 103059 | 48583 | 87465 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 283400 | 283539 |
| 14 | 14246 | 39221 | 12101 | 26224 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 91793 | 91846 |
| 15 | 37850 | 62922 | 36029 | 72803 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 209604 | 209767 |
| 16 | 45599 | 37349 | 20306 | 67937 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 171191 | 171346 |
| 实际求和值 | 1453062 | 1046494 | 574627 | 1442943 | 26448 | 254009 | 35565 | 192842 | 134610 | 98229 | 268975 | 412199 | 344188 | 93480 | 232953 | 125044 | ||
| Aj | 1453062 | 1046494 | 574627 | 1442943 | 26448 | 254012 | 35565 | 192851 | 134627 | 98234 | 268991 | 412265 | 344377 | 93544 | 233167 | 125174 | ||

















 5430
5430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









