










目录
python文本分析工具NLTK
NLP(自然语言处理)领域种最常用的一个python库,NLP是将自然语言(文本)转化为计算机程序更容易理解的形式,
在python环境下运行以下代码,选择需要的语料库进行下载
nltk就像是一个骨架,我们要让他运动起来,就必须有血有肉,这些血肉就是下面的这些模型等
import nltk
nltk.download()弹出以下窗口,Collection中有各种的教程、例子等,corpora为各种语料库 ,全部下载完约1-2G左右,models为各种模型,All Packages为前面的所有包
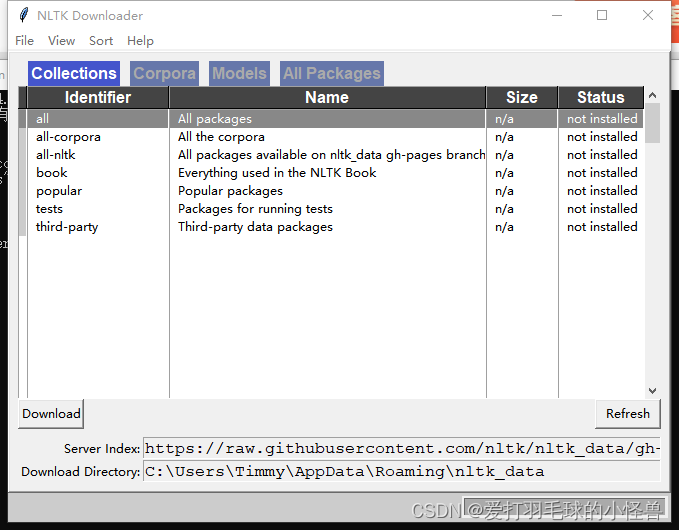
下面是brown(布朗)库的调用和基本情况查看
from nltk.corpus import brown
print(brown.cotegories())#查看语料库包含的类别
print('共有{}个句子'.format(len(brown.sents())))
print('共有{}个单词'.format(len(brown.words())))典型的文本与处理流程为
- 对原始数据进行分词
- 词形归一化
- 词性标注
- 去除停用词
- 得到处理好的单词列表
分词
默认使用punkt分词模型,在上述方法中下载此模型才可使用
nltk.word_tokenize('需要分词的句子') 结巴分词(中文分词)
结巴分词(中文分词)
使用jieba库,首先需要pip安装 pip install jieba
jieba.cut('需要分词的句子',cut_all=True/False)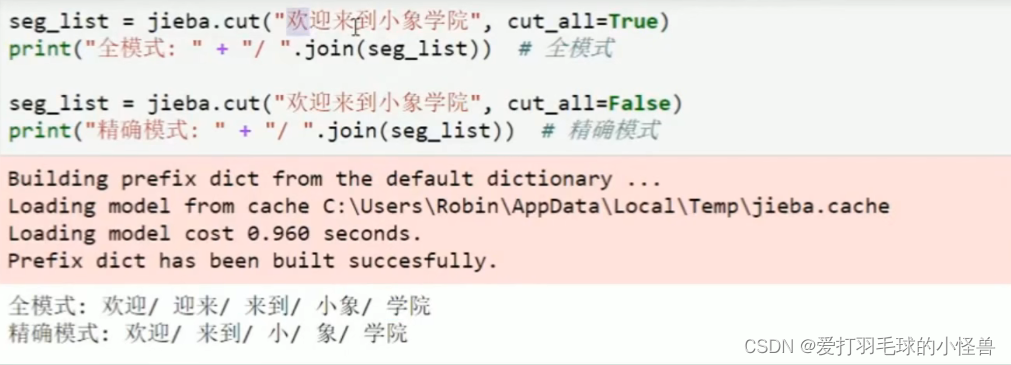
特殊字符可以使用正则表达式进行分词
如需学习可以借鉴以下链接(5条消息) 正则表达式——python对字符串的查找匹配_爱打羽毛球的小怪兽的博客-CSDN博客_python 字符串正则查找
词形问题、词形归一化

词干提取 stemming
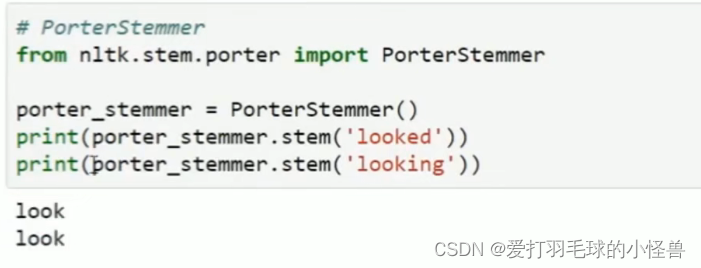
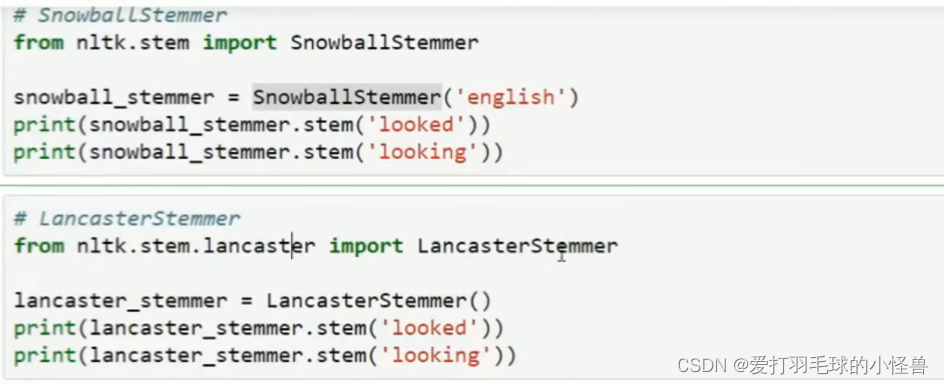
词形归并lemmatization
需要提前下载wordnet语料库才可以使用
上述的went之所以没有变成go,是因为默认他为名词,我们需要对其指定词性,比如动词

词性标注和停用词
词性标注需要提前下载averaged_perceptron_tagger

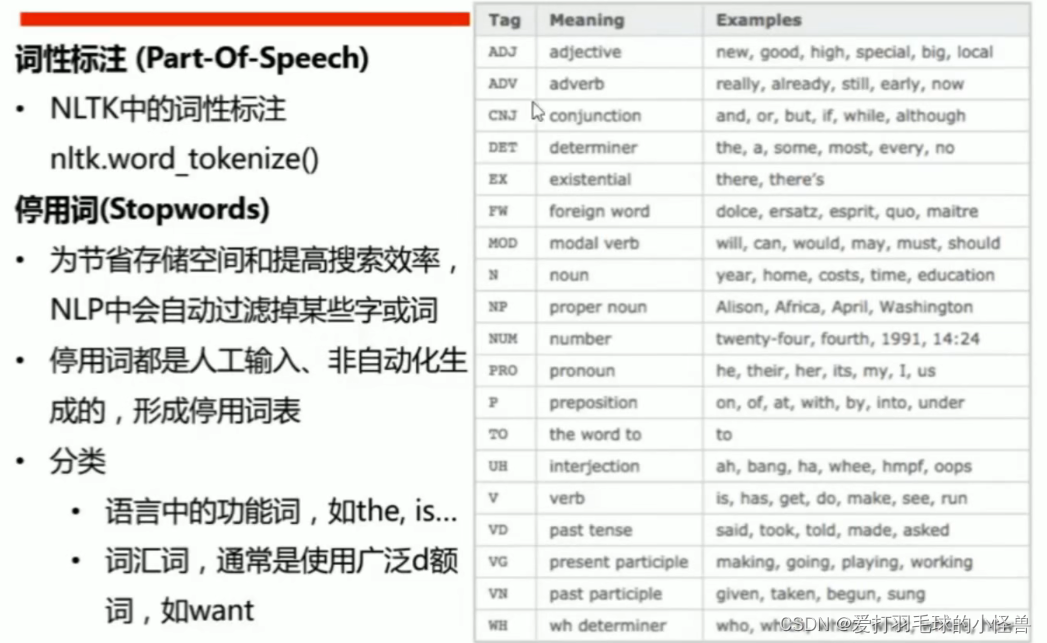

停用词需要提前下载stopwords
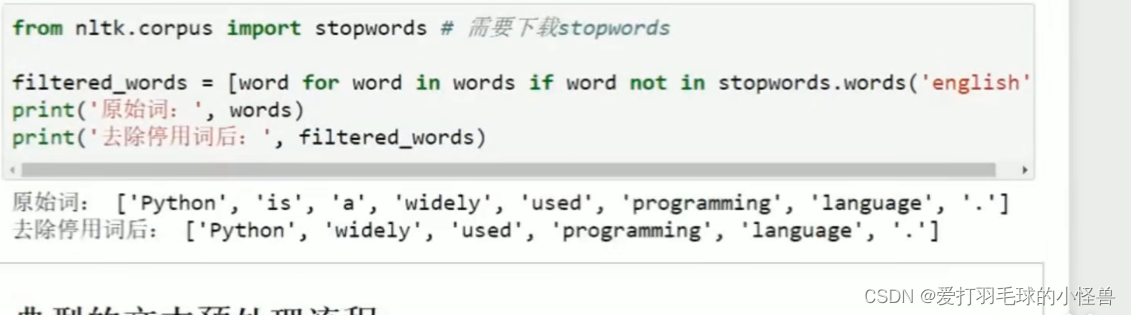
使用词频表示文本特征来度量文本间的相似性
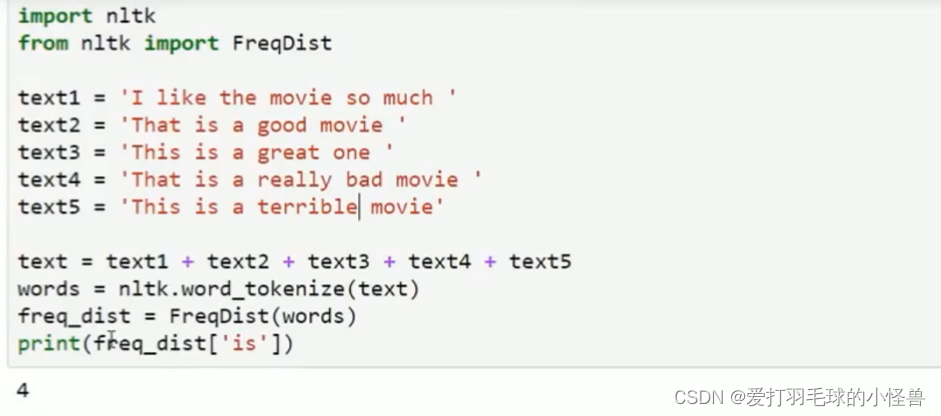
取出词频统计的最多的n个单词
文本分类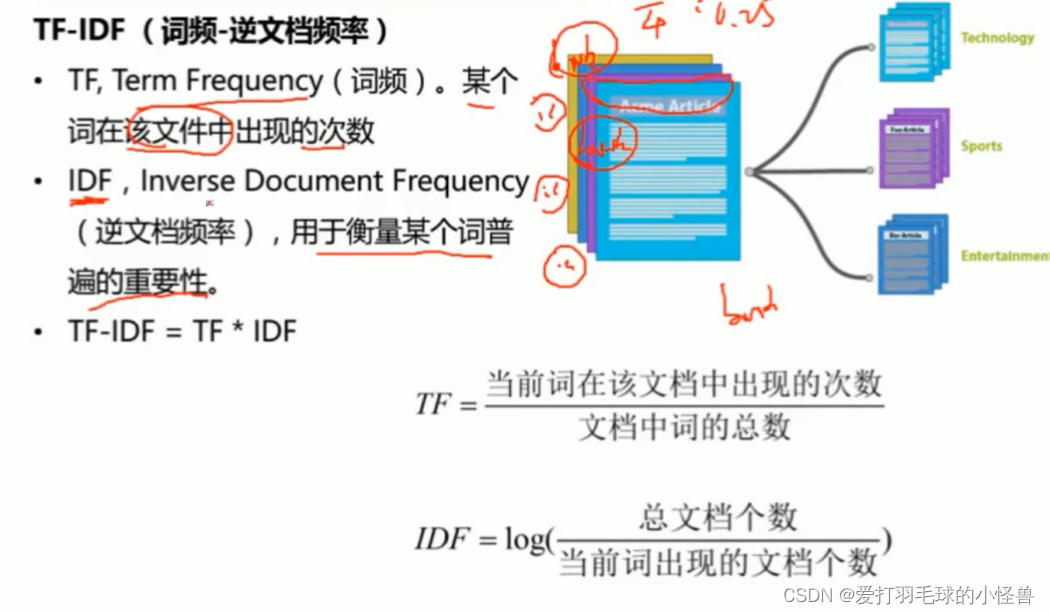
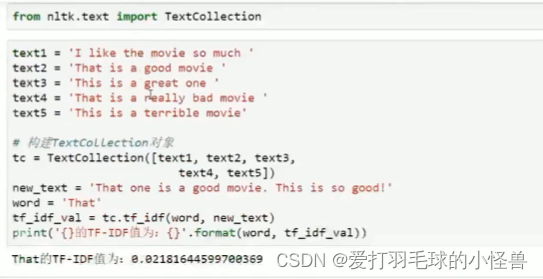
使用TextCollection自己创建一个语料库文件,如图所示
朴素贝叶斯算法
可以借鉴下面两个链接来了解机器学习的基础知识,若是又想提高模型预测率的同学可以查阅相关资料
机器学习示例总结(线性回归、逻辑回归、KNN算法、朴素贝叶斯、SVM算法、决策树)_爱打羽毛球的小怪兽的博客-CSDN博客
















 9927
9927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











