






注意:如果爬完没有信息显示的话,需要从考虑各方面的反爬技术,当然首先要考虑的就是
“User-Agent”参数,将其换成浏览器请求上的“User-Agent”参数(F12)。
发送post请求,带参数的话用data=?, 发送get请求,带参数的话用params=?
1.requests最简单的使用,搜索周杰伦相关信息
# 安装requests
# pip install requests
import requests
query = input("请输入一个你喜欢的明星: ")
# 浏览器输入url地址栏中所用方式一定是get
# f代表着格式化字符串(Formatted String)。格式化字符串是一种方便的字符串表示形式,
# 它允许您在字符串中包含变量值,并在运行时将其替换为实际值。使用格式化字符串,您可以更轻松地构建复杂的字符串,而无需手动拼接每个部分。
# 格式化字符串以字母"f"或"F"作为前缀,后跟一对大括号{},其中可以包含变量名称、表达式或函数调用
url = f'https://www.sogou.com/web?query={query}'
# 将请求头中的“User-Agent”的参数设置为浏览器上的“User-Agent“
dic = {
"User-Agent" : "xxx"
}
# 将服务器响应的东西保存在resp中
resp = requests.get(url,headers=dic) # 响应头设置为浏览器中的“User-Agent”的参数,处理一个小小的反爬
print(resp) # 打印出<Response [200]> 200:响应成功
print(resp.text) # 打印页面源代码
# 关闭resp
resp.close()
2.百度翻译
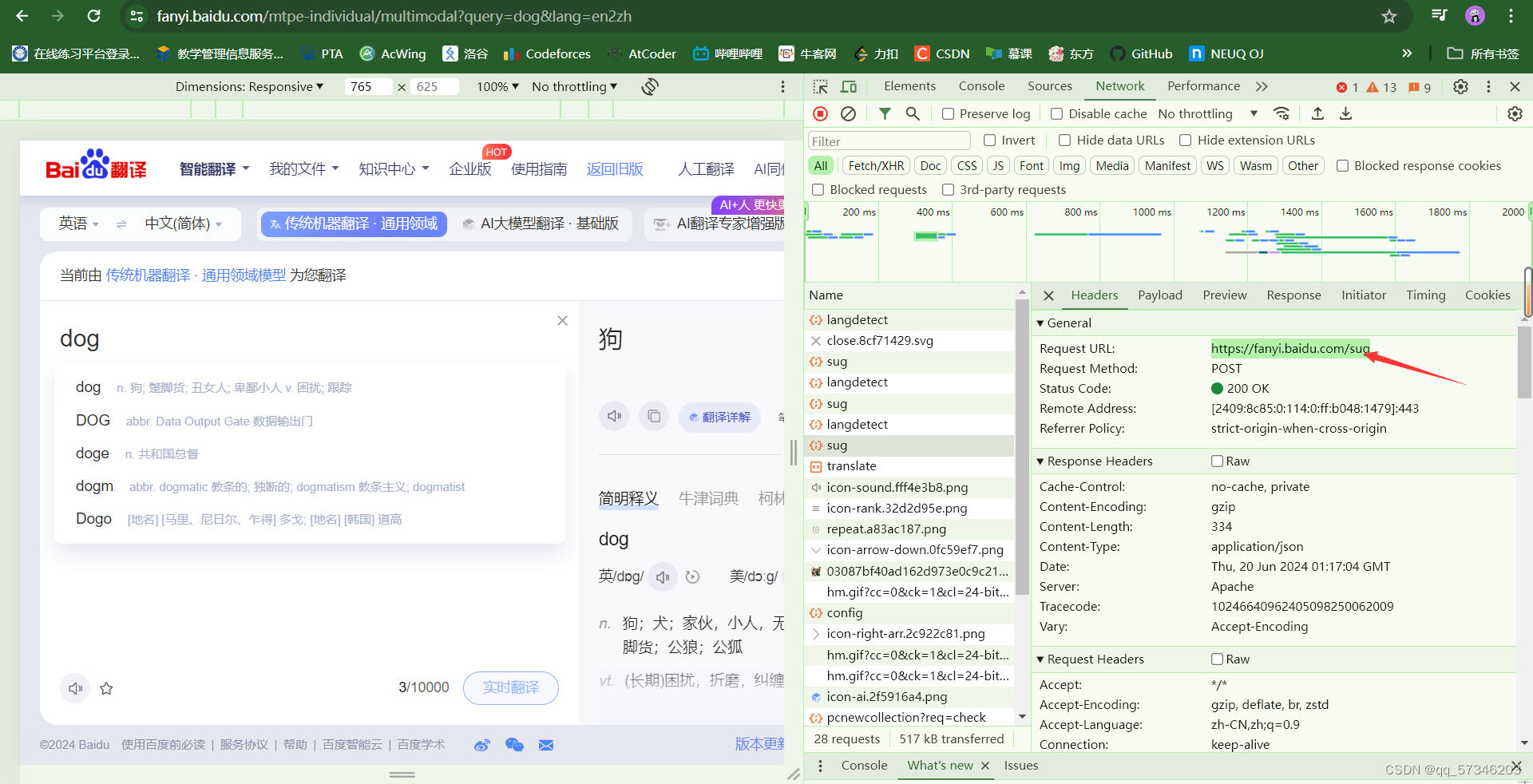
import requests
url = "https://fanyi.baidu.com/sug"
s = input("请输入您要翻译的英文单词:")
dat = {
"kw" : s, # 参数
}
# 发送post请求,发送的数据必须放在字典中,通过data参数进行传递
resp = requests.post(url, data=dat)
# 将服务器返回的内容直接处理成json()
print(resp.json())
# 关闭resp
resp.close()
3.豆瓣喜剧电影
参数过多时,可以将url后面的参数重新封装
import requests
# 原版url是,将url后面的参数重新封装(即?后的参数)
# https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=0&limit=20
url = "https://movie.douban.com/j/chart/top_list"
# 重新封装的参数
param = {
"type": "24",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20,
}
# 发送post请求,带参数的话用data=?, 发送get请求,带参数的话用params=?
# resp = requests.get(url=url, params=param)
# 输出的是https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=0&limit=20
# 和浏览器抓包工具中的url一样
# print(resp.request.url)
# print(resp.text) 没有输出数据,因为网站有反爬技术,此时需要考虑各种因素尝试,首先考虑将User-Agent参数换成浏览器上的
dic = {
"User-Agent" : "xxx"
}
resp = requests.get(url=url, params=param, headers=headers)
print(resp.json())
# 关闭resp
resp.close()
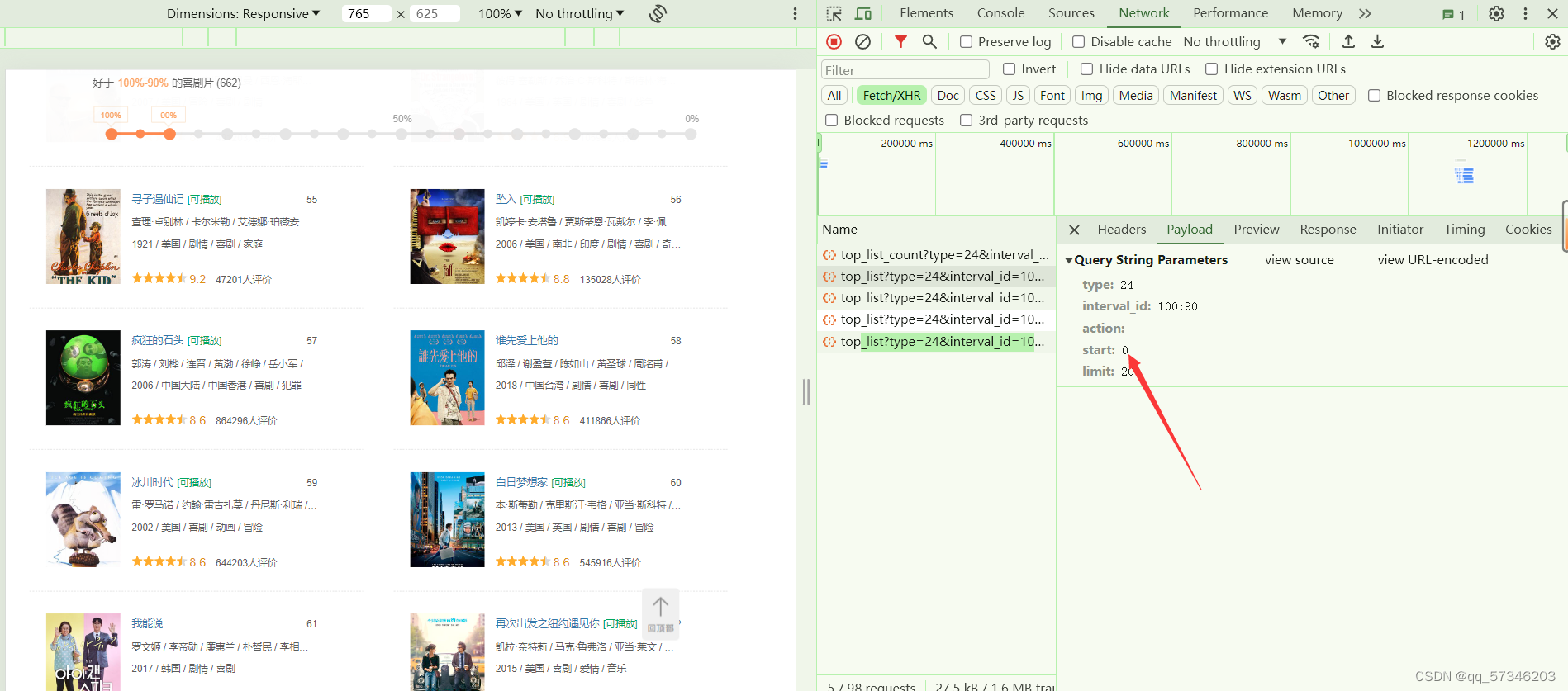
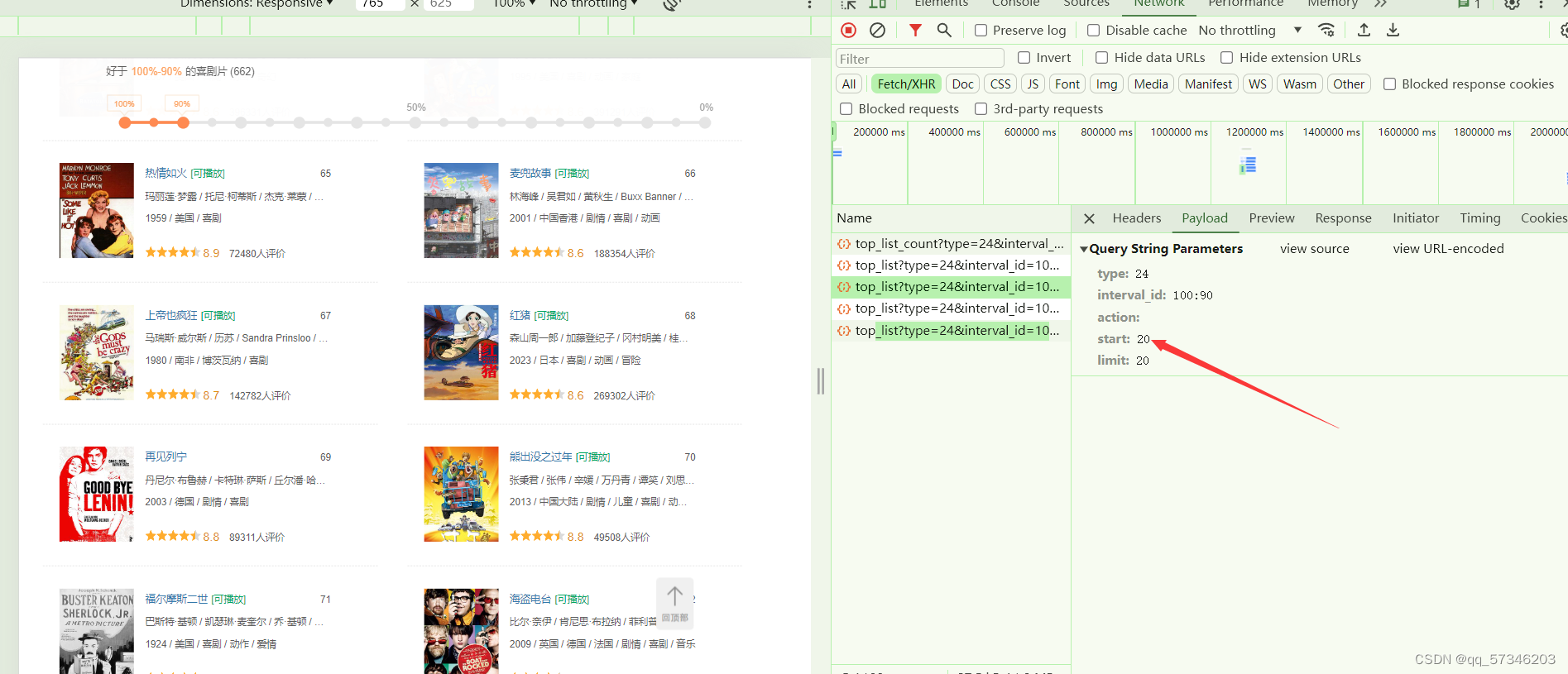
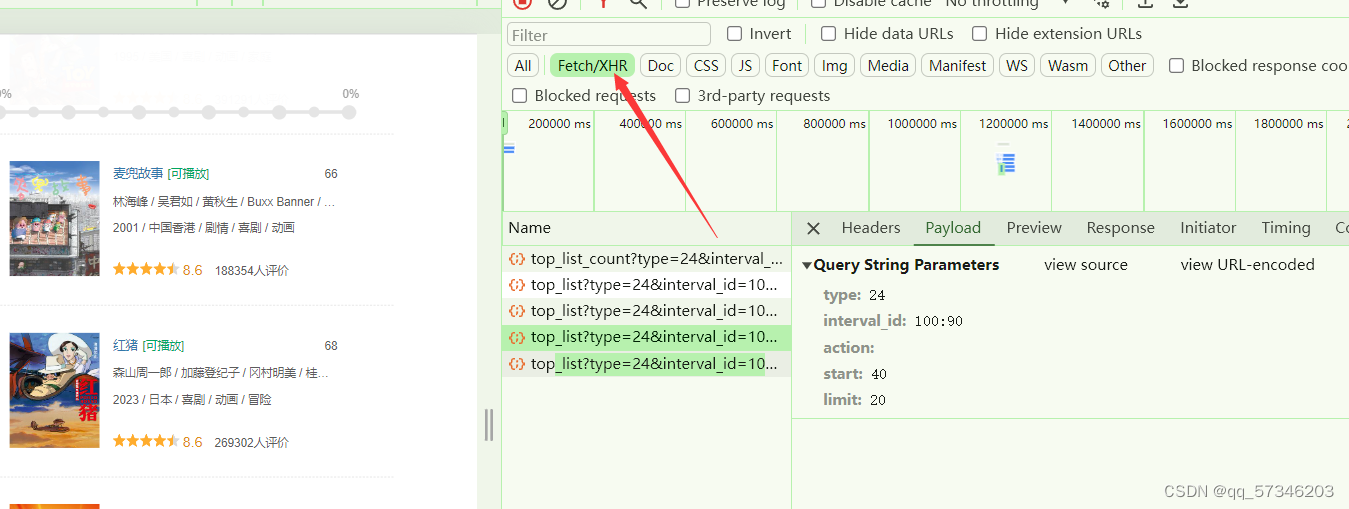 鼠标滚轮往下滚动,XHR会多出现一个数据包,且可以发现参数中的“start”总是以20进行递增
鼠标滚轮往下滚动,XHR会多出现一个数据包,且可以发现参数中的“start”总是以20进行递增















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









