






文献链接:
Research on Adaptive Job Shop Scheduling Problems Based on Dueling Double DQN | IEEE Journals & Magazine | IEEE Xplore
文献贡献:
(1)提出了双深度Q网络(DDQN)模型来构建用于调度问题的深度强化学习框架,其中包括目标网络和在线网络来处理一般DQN中存在的高估问题。在这个框架中,静态和动态实例都可以被优化。
(2)首次建立了基于析取图的强化学习环境,将基于析取图的调度求解过程转化为以往研究中未曾尝试过的顺序决策过程。在这种环境下,调度可以从非零状态开始,即可以先交互式地调度一些操作,然后通过算法调度剩余的操作。
(3)在每个离散时间步长,调度状态被创造性地表示为多通道图像,以避免传统强化学习中使用的手工特征。根据输入状态,CNN 选择一个启发式规则来从当前的一组可调度任务中确定具有最高优先级的作业。
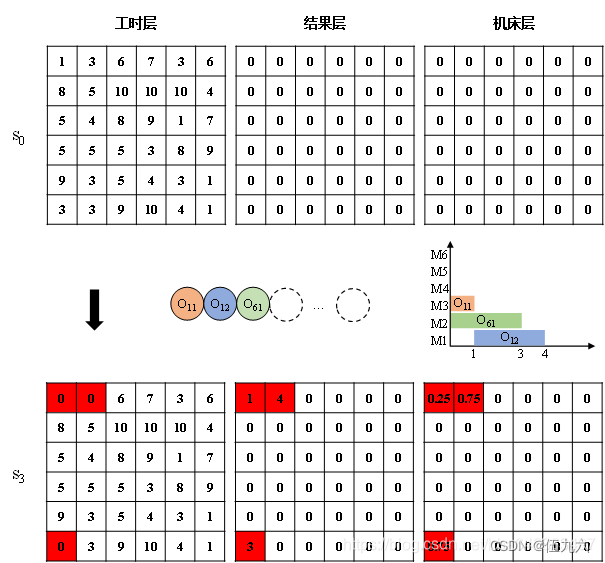
(4)设计了一种相当于Cmax的新颖奖励函数来评估每次调度对调度目标的影响。
(5)提出了考虑精英机制的改进epsilon递减策略,在训练后期以一定的概率选择当前最佳解的最优规则。
(6)进行了大量的实验来分析不同超参数的敏感性,验证了其对静态问题的有效性及其对反应性调度和不确定处理时间的动态问题的推广。
算法优点:离线训练过程结束,可以直接在线使用最优策略来获得调度结果,其运行时间近似等于简单规则的运行时间,可以等价于或甚至优于GA的性能,从而保证调度精度,提高求解效率。与元启发式算法不同,无需耗时的迭代优化即可获得高质量的解决方案。
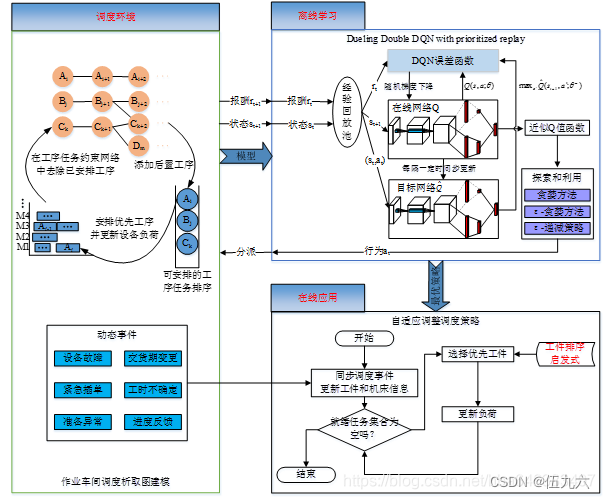
结合了基于值的 DRL 和析取图的自适应调度框架:调度环境、离线学习和在线应用
名词解释
OR-Library: OR-Library是一个收集了各种运筹学(Operations Research,OR)问题的测试数据集的网站。OR-Library由英国布鲁内尔大学的J.E.Beasley教授创建和维护,目前包含了90多个问题的超过2500个数据集,是运筹学领域的一个重要的资源。
DRL:端到端的学习,感知到行动。端对端的学习,就是把特征提取的任务也交给模型去做,直接输入原始数据或者经过些微预处理的数据,让模型自己进行特征提取。
多通道图像: 多通道图像是指具有多个通道的图像,通道是用来表示图像中不同颜色或特征的分量。通常,我们使用RGB模式来表示彩色图像,它由红色、绿色和蓝色三个通道组成,每个通道都是一个灰度图像,表示该颜色的强度。多通道图像可以用来增强图像的信息量,提高图像的质量和效果。
深度学习中的多通道图像,是指利用深度神经网络,从原始图像中提取出多个不同的特征图,每个特征图都是一个通道,表示图像的某一方面的信息。深度学习中的通道数,取决于卷积核的个数,卷积核是用来对图像进行滤波和特征提取的矩阵。不同的卷积核可以捕捉到不同的特征,比如边缘、纹理、形状等。通过增加卷积核的个数,就可以增加输出的通道数,从而增加特征的丰富度和多样性。这些特征可以帮助神经网络更好地理解和识别图像的内容和语义。
序列决策过程:
序列决策过程是一种研究如何在不确定的环境中做出最优选择的问题。序列决策过程的目标是找到一个最优策略,使得智能体在与环境交互的过程中,能够最大化累积奖励。序列决策过程的一个典型例子是马尔可夫决策过程(Markov Decision Process,MDP),它假设环境具有马尔可夫性,即下一个状态只依赖于当前状态和动作,而与之前的历史无关。
自适应调度:
能够根据不同的系统状态动态做出决策的调度策略称为自适应调度策略,基于该策略的调度方法即~。
Episode:
在强化学习中,episode是指智能体与环境的一次完整的交互过程,从智能体接收状态信息开始,通过智能体采取行动来与环境交互,直到任务结束,同时还包括了智能体从这个过程中获取的奖励信息。
TD误差:
是时间差分(Temporal-Difference,TD)学习中的一个重要概念,它表示状态值函数的估计值和目标值之间的差异。状态值函数是指在某个策略下,从某个状态开始,能够获得的累积奖励的期望。目标值是指利用一步或多步的预测,根据当前状态,下一步的奖励和下一步的状态值函数,来估计当前状态的值函数。TD误差可以用来评价状态值函数的准确性,也可以用来更新状态值函数的估计值,从而提高学习效率和性能。
决斗网络:决斗网络是一种改进了DQN的结构的方法,它可以让智能体更好地学习不同状态的价值和不同动作的优势。决斗网络的基本思想是将最优动作价值函数Q分解为最优状态价值函数V和最优优势函数A*,并用两个独立的神经网络来分别近似它们。目标网络和在线网络是DQN和决斗网络中都使用的一种技巧,它可以解决网络参数更新过程中的不一致性和震荡性问题。目标网络和在线网络的结构是完全一样的,只是参数不同。在线网络是用来实时地估计和更新Q函数的网络,它的参数会不断地根据数据和损失函数进行调整。目标网络是用来提供目标Q值的网络,它的参数会定期地从在线网络复制过来,但不会随着数据和损失函数进行调整。这样可以保证目标Q值的稳定性,避免网络的过拟合和发散。
决斗DDQN于DDQN的区别:决斗DDQN与DDQN的区别,就是决斗DDQN是在DDQN的基础上,改进了网络的结构,隐藏层分别输出两个值:状态价值函数和优势函数,使得网络可以分别学习状态的价值和动作的优势。而DDQN是在DQN的基础上,改进了算法的流程,使得算法可以分别选择和评估动作,从而减少过估计的问题。
状态特征:
表示环境的当前情况,可以是完全可观测的,也可以是部分可观测的。状态特征可以用来帮助智能体感知环境,选择合适的动作,评估状态的价值等。如作业加工时间
精英机制: 保留最优个体
Q值:
在深度强化学习中,Q值是一种关键的评估指标,它衡量的是一个状态-动作对的价值。具体来说,Q值可以理解为在特定状态下,采取某一特定行动后,可能获得的即时奖励和未来预期奖励的总和。
如果从深度学习的角度出发,Q值可以被视为神经网络的一种输出结果。例如,在DQN(Deep Q Network)算法中,神经网络会输出当前预测的Q值。这个网络通常包含两个部分:目标网络和训练网络。目标网络负责产生参考的Q值,而训练网络则负责输出当前预测的Q值。每隔一定的时间步,这两个网络的参数会进行同步,以确保目标网络的稳定性。它是智能体进行决策的主要依据,也是智能体学习过程中需要优化的目标函数。
在深度强化学习中,Q函数(也称为动作值函数)是一个重要的概念,它用来评估在给定状态下采取某个动作的价值。Q函数通常表示为Q(s, a),表示在状态s下采取动作a的预期回报或累积奖励。
Q函数:
- **Q(s, a)**:在状态s下采取动作a的预期累积奖励。
- **s**:当前的环境状态。
- **a**:采取的动作。
- **Q(s, a)** 可以理解为在当前状态下采取某个动作所能获得的“价值”。
Q函数的特性:
- **最优Q函数(Optimal Q-function)**:在给定策略下,最优Q函数表示在每个状态下采取最优动作所能达到的最大累积奖励。这个最优Q函数满足贝尔曼最优方程(Bellman Optimality Equation)。
- 贝尔曼方程(Bellman Equation):Q函数可以递归地定义为当前动作的即时奖励加上下一状态的最大Q值,即Q(s, a) = r + γ * max(Q(s', a')),其中r是即时奖励,γ是折扣因子,s'是下一状态,a'是在s'状态下选择的最优动作。
Q函数的作用:
- **策略选择**:基于Q函数,可以采用贪婪策略(选择具有最高Q值的动作)或者ε-贪婪策略(以一定概率进行探索)来选择动作。
- **价值评估**:Q函数可以帮助评估不同动作的价值,指导智能体做出决策,以获得最大化的累积奖励。
在深度强化学习中,有时会使用深度神经网络来近似Q函数,尤其是在使用Q-learning、DQN(Deep Q-Network)等算法时。这些方法使用神经网络来逼近Q函数,以处理大型状态空间和动作空间,并优化智能体的决策策略。
Q值与Q函数关系:
- Q值是Q函数在特定状态和动作下的具体数值,即Q值是Q函数的某个具体实例。
- Q函数是一个函数,包含了所有可能状态下的动作值。
在强化学习中,Q值是我们关注的具体值,它代表了智能体在特定状态下采取特定动作的价值。而Q函数则是一个更广泛的概念,它涵盖了所有状态和动作的价值关系。在实践中,我们通过不断更新Q值或逼近Q函数来指导智能体做出更好的决策。
损失函数:
用来度量模型的预测值f(x)与真实值Y的差异程度的运算函数,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。作用是在模型的训练阶段,每个批次的训练数据送入模型后,通过前向传播输出预测值,然后损失函数会计算出预测值和真实值之间的差异值,也就是损失值。得到损失值之后,模型通过反向传播去更新各个参数,来降低真实值与预测值之间的损失,使得模型生成的预测值往真实值方向靠拢,从而达到学习的目的。
数据集:
是指用于训练、验证和测试机器学习模型的数据集合。通常,数据集会被划分为三个部分:训练集、验证集和测试集。其中,训练集用于训练模型,验证集用于调整模型参数,测试集用于评估模型性能。
验证集:验证集(validation set)是用于调整模型的超参数(如学习率、正则化系数等)并评估模型性能的数据集。验证集的作用是帮助开发者选择最优的模型,避免模型过拟合或欠拟合。验证集在训练过程中会被多次使用,每次训练完一个模型,就会用验证集来计算模型的误差或准确率,然后根据验证集的结果来调整模型的超参数,直到找到最佳的模型。
测试集:测试集(test set)是用于评估模型最终性能的数据集。测试集的作用是评估模型在未见过的数据上的泛化能力,并判断模型是否足够准确和鲁棒。测试集只在训练完成后使用一次,即在选择好最优的模型后,用测试集来测试模型的性能,得到模型的误差或准确率,作为模型的最终评价指标。
随机处理时间扰动:
是指在生产过程中,由于各种不确定因素,如机床故障、工人技能、工艺变化等,导致工件的实际加工时间与预先估计的加工时间不一致,从而影响调度方案的执行和性能。随机处理时间扰动可以用不同的方式来建模和描述,一种常用的方法是用概率分布来表示加工时间的随机性,例如正态分布、均匀分布、泊松分布等。另一种方法是用区间数或模糊数来表示加工时间的不确定性,例如区间加工时间、三角模糊数、梯形模糊数等。还有一种方法是用随机参数或随机变量来表示加工时间的变化,例如随机工时、随机恶化效应、随机学习效应等。
超参:
超参(hyperparameters)是在机器学习和深度学习中指的是那些需要手动设置的参数,而不是通过学习算法自动学习得到的参数。与超参不同的是,模型的参数是通过训练数据来学习得到的,例如权重和偏置。超参的选择通常是基于经验和试验的,需要进行调优以获得更好的模型性能。在机器学习中,调整超参是一个重要的步骤,常常使用交叉验证或者网格搜索等技术来寻找最佳的超参组合。调整超参的目标是找到能够在未知数据上表现良好的模型。
耦合:
机器学习中的耦合是指模型或数据之间的相互作用或影响程度。耦合可以是正面的,也可以是负面的,取决于模型或数据的目标和性质。一般来说,耦合越高,模型或数据之间的相互影响越大,但也越复杂和难以控制;耦合越低,模型或数据之间的相互影响越小,但也越独立和易于维护。在神经网络中,耦合可以指不同层次或不同类型的神经元之间的连接强度。耦合可以影响神经网络的表达能力、泛化能力、可解释性等。一些常见的方法来降低神经网络中的耦合是使用注意力机制、变分自编码器、多任务学习等。
文献讲解视频


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









