






文献DOI:10.19287/j.mtmt.1005-2402.2023.04.023
目录
摘要
首先,基于析取图模型构建深度强化学习的调度环境,
建立三通道状态特征,
设计 20 种复合启发式调度规则作为动作空间,
将奖励函数等价为机器利用率;
利用深度卷积神经网络搭建动作网络和目标网络,
以三通道状态特征作为输入,输出每个动作的 Q 值;
进而,使用行动有效性探索和利用策略选取动作;
最后,计算即时奖励和更新调度环境。
调度问题框架
框架由环境和网络训练组成。通过定义调度环境、状态、动作、奖励和调度策略,将作业车间调度过程映射为马尔科夫决策过程 ( MDP)。
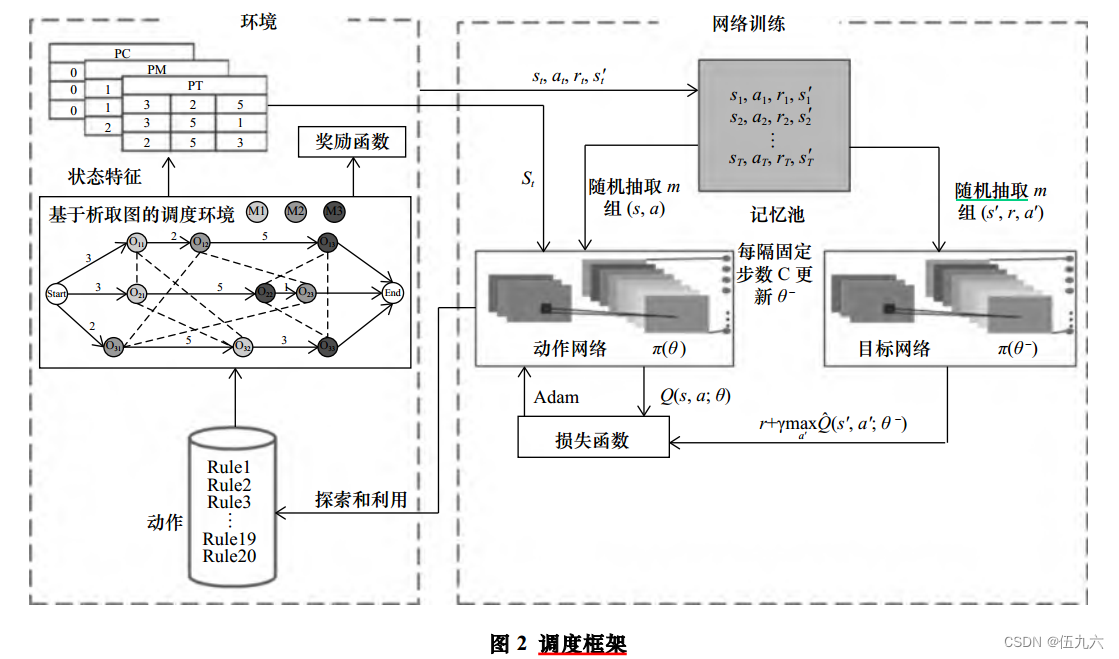
环境
环境主要包括析取图、动作空间、状态和奖励函数。
析取图
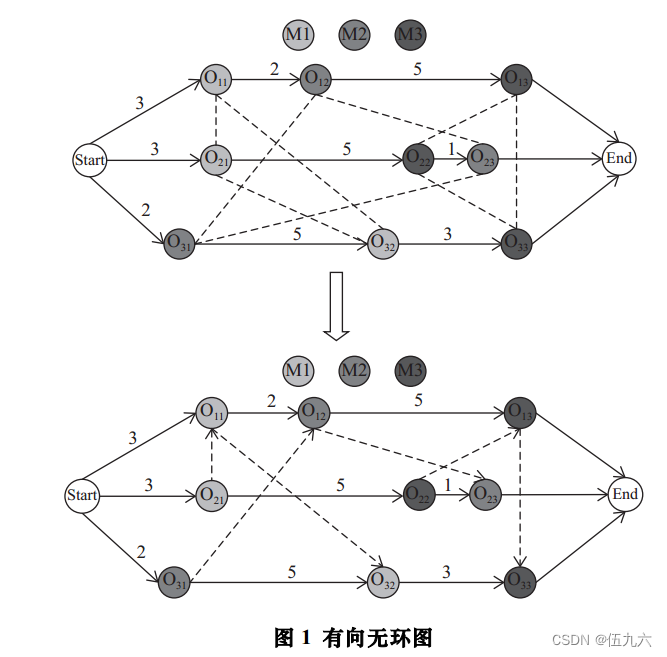 析取图作为调度环境,从工序角度出发,分派工序到机器上进行加工。为调度智能体提供了调度决策点和执行动作的环境,决定了动作对工件分派的影响。 实线--有向弧集--同一工件相邻工序 虚线--析取弧集--同一机器相邻工序 权值--加工时间
析取图作为调度环境,从工序角度出发,分派工序到机器上进行加工。为调度智能体提供了调度决策点和执行动作的环境,决定了动作对工件分派的影响。 实线--有向弧集--同一工件相邻工序 虚线--析取弧集--同一机器相邻工序 权值--加工时间
状态
在 JSSP 中状态需要反映工件和机器的全局和局部信息。
状态特征是对状态属性的数值表示,状态特征应易于计算,并进行归一化,保证尺度均匀性,对不同的调度问题状态特征需要具有一定的兼容性 。
三通道状态特征:工序工时层、工序需求层、完工时间层
![]()
PT 为工序工时层矩阵、PM 为工序需求层矩阵、PC 为完工时间层矩阵。计算公式如下:
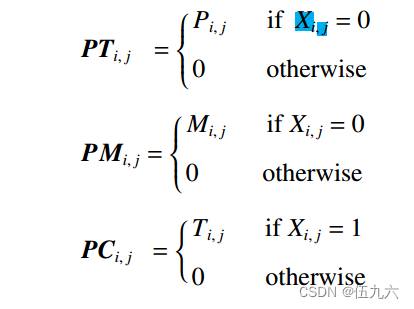
动作空间
在 JSSP 中动作是智能体可以执行的启发式调度规则。智能体通过选择的启发式调
度规则对工件进行分派,确保调度结果接近预期的性能指标。
以考虑工件全部工序加工信息的作为全局规则,只考虑工件部分工序加工信息的作为局部规则。
通过 20 个启发式调度规则组成动作空间
状态盲区:智能体在依据当前状态按照选定的规则进行工序分派时,会出现多个工件符合规则的情况。此时,从时钟角度出发对工件进行二次选择,即使用先到先服务规则进行工件选择。
复合启发式调度规则动作空间:对选定 20 种启发式规则分别与先到先服务规则进行组合应用
奖励函数
奖励函数对训练有重要的影响,合理的奖励函数能够提高训练速度,使训练结果快速收敛。
将 JSSP 中最大完工时间的最小化转化为最大化机器利用率
 其中:K 为已加工工序计数器,可以视为深度强化学习中的时间步长。 即时奖励 :
其中:K 为已加工工序计数器,可以视为深度强化学习中的时间步长。 即时奖励 : ![]() 累积奖励 :
累积奖励 : 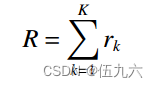
从上式中可以推导出最小化最大完工时间可以等价为累计奖励最大化
网络训练
网络训练部分主要由记忆池、动作网络、目标网络和损失函数组成
记忆池
记忆池:用于存储环境提供的状态值、动作值和奖励值,为动作网络和目标网络的更新提供样本,通过随机抽取样本的方式打破数据之间的关联性
经验回放机制:
动作网络
动作网络:通过环境和记忆池提供的训练样本计算出预测值
用动作网络对值函数进行拟合
动作网络作为状态与动作的非线性映射器,将状态和动作的关系映射到深度卷积神经网络
目标网络
目标网络:通过环境和记忆池提供的训练样本计算出实际值
损失函数
损失函数:目标值与预测值的均方差
均方差:
均方差(Mean Squared Error,MSE)是衡量一组数据与其均值之间差异的一种方法,它用于评估预测值与真实值之间的平均偏差大小。
每个数据值与全体数据值的平均值的差的平方的平均数
解释:
- 平方差: 对于每个数据点,MSE计算预测值与真实值之间的差异,将其平方,以消除正负值对求和结果的影响。
- 均值: 对所有数据点的平方差进行求和并取平均,得到均方差。
- 衡量预测误差: MSE越小,预测值与真实值之间的偏差越小,表示模型拟合效果越好。但如果MSE过大,则表示模型的预测能力较差。
应用:
- 模型评估: 在机器学习中,MSE通常用作回归模型的评价指标。它衡量了模型预测值与真实值之间的平均偏差,可以帮助评估模型的拟合程度。
- 优化目标: 在训练过程中,可以使用MSE作为损失函数,通过优化减小预测值与真实值之间的差异,从而改善模型的性能。
总体来说,均方差是一种常用的衡量预测误差的指标,它量化了模型预测值与真实值之间的差异,常被用于评估和优化机器学习模型的性能。
神经网络结构
深度卷积神经网络由输入层、输出层和 3 层隐藏层构成。
输入层为三通道特征。
隐藏层由两层卷积层和一层全连接层构成,两层的卷积层和一层的全连接层
输出层由 20 个节点组成。
行动有效性探索和利用策略
探索和利用是调度智能体选择动作的两种相互冲突的重要策略
epsilon-decreasing 策略:在开始时探索高于利用,随着智能体的学习进行探索被逐步转移到利用,当探索率为零时,选择最优动作执行。
行动有效性:当可供空闲机器选择的工件唯一时,状态转移唯一,智能体无法有效地利用历史经验,为了提高智能体的学习效率,直接将工件分派到空闲机器上,使智能体的行动更加有效。

















 1779
1779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









