






旅行商问题(TSP)
旅行商问题是一个经典的组合优化问题,它要求在给定一系列城市和每对城市之间的距离后,找到一条访问每个城市一次并返回起点的最短路径。它是一个 NP 难问题,也就是说,没有已知的多项式时间内的算法可以保证找到最优解。
遗传算法求解代码
完整代码如下
'''遗传算法解决旅行商问题,编码部分将一条路径编为染色体,基因位是城市在列表中所对应的序号 '''
import numpy as np
import matplotlib.pyplot as plt
import random
import pandas as pd
import math
import csv
def write_data(): # 写入csv文件
file = open('city.csv', encoding='utf-8', mode='w', newline='') # 参数newline=''可以避免不必要的空行
a = [['city', 'x', 'y'],
['北京', '116.46', '39.92'],
['天津', '117.2', '39.13'],
['上海', '121.48', '31.22'],
['重庆', '106.54', '29.59'],
['拉萨', '91.11', '29.97'],
['乌鲁木齐', '87.68', '43.77'],
['银川', '106.27', '38.47'],
['呼和浩特', '111.65', '40.82'],
['南宁', '108.33', '22.84'],
['哈尔滨', '126.63', '45.75'],
['长春', '125.35', '43.88'],
['沈阳', '123.38', '41.8'],
['石家庄', '114.48', '38.03'],
['太原', '112.53', '37.87'],
['西宁', '101.74', '36.56'],
['济南', '117', '36.65'],
['郑州', '113.6', '34.76'],
['南京', '118.78', '32.04'],
['合肥', '117.27', '31.86'],
['杭州', '120.19', '30.26'],
['福州', '119.3', '26.08'],
['南昌', '115.89', '28.68'],
['长沙', '113', '28.21'],
['武汉', '114.31', '30.52'],
['广州', '113.23', '23.16'],
['台北', '121.5', '25.05'],
['海口', '110.35', '20.02'],
['兰州', '103.73', '36.03'],
['西安', '108.95', '34.27'],
['成都', '104.06', '30.67'],
['贵阳', '106.71', '26.57'],
['昆明', '102.73', '25.04'],
['香港', '114.1', '22.2'],
['澳门', '113.33', '22.13']
]
csv_writer = csv.writer(file) # 返回一个writer对象
csv_writer.writerows(a) # 调用该对象的方法将字符串文本写入csv文件
file.close()
print('写入成功')
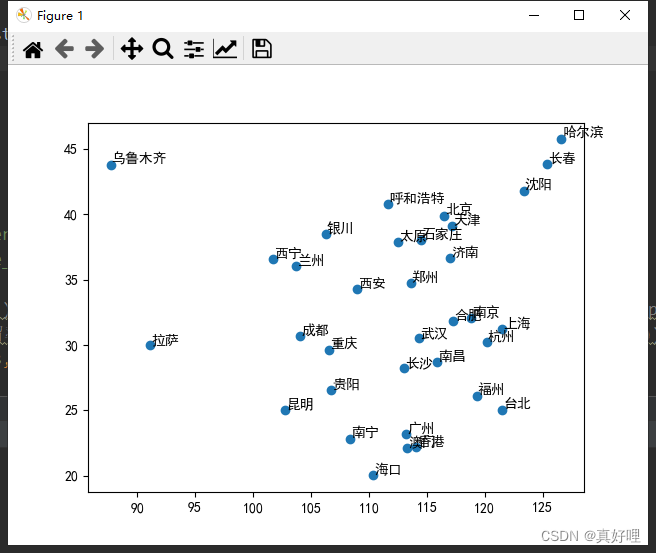
def read_date(): # 读取csv文件中的数据,并绘制城市坐标图
date = pd.read_csv('city.csv')
city_name = date['city']
city_x = date['x']
city_y = date['y']
plt.figure()
plt.scatter(city_x, city_y)
for i in range(len(city_x)): # range(34) 元素个数为34,len(city_x)也是34
plt.annotate(city_name[i], (city_x[i], city_y[i]), (city_x[i] + 0.1, city_y[i] + 0.1)) # 此函数用于标注文字
plt.show()
return city_x, city_y, city_name
def distance_citys(city_x, city_y, city_name): # 计算城市之间的距离
global city_count, distance # 使局部变量成为全局变量
city_count = len(city_name)
distance = np.zeros((city_count, city_count)) # 创建 34 维度的全0数组(数组指ndarray数组其是同类型数据的集合,以 0 下标为开始进行元素的索引)
for i in range(city_count):
for j in range(city_count):
distance[i][j] = math.sqrt((city_x[i] - city_x[j]) ** 2 + (city_y[i] - city_y[j]) ** 2)
# 将坐标转换为弧度
'''lat1_rad = math.radians(city_x[i])
lon1_rad = math.radians(city_x[j])
lat2_rad = math.radians(city_y[i])
lon2_rad = math.radians(city_y[j])
# 计算经度差
delta_lon = lon2_rad - lon1_rad
# 计算纬度差
delta_lat = lat2_rad - lat1_rad
# 计算距离
a = math.sin(delta_lat / 2) ** 2 + math.cos(lat1_rad) * math.cos(lat2_rad) * math.sin(delta_lon / 2) ** 2
c = 2 * math.atan2(math.sqrt(a), math.sqrt(1 - a))
distance[i][j] = 6371 * c # 地球半径(单位:千米)'''
return city_count, distance
def path_length(path1, origin): # 计算一条路径的目标函数 解码部分
global distance # 使局部变量成为全局变量
length = 0
length += distance[origin][path1[0]] # 从起点到path1的第一个城市
for i in range(0, len(path1)):
#print(len(path1))
if i == len(path1) - 1: # i=32时 即path1的最后一个城市
length += distance[origin][path1[i]] # 加上从起点到最后一个城市
else:
length += distance[path1[i]][path1[i + 1]] # 加上从第一个城市到下一个城市
return length
def improve(origin, path1, improve_count): # 改良初始化
length = path_length(path1, origin) # 在一个定义函数里调用另一个定义的函数
for i in range(improve_count):
# 随机选择两个城市
u = random.randint(0, len(path1) - 1) # 生成的随机数n满足a <= n <= b,len(path)=33,所以要减一
# 如果要生成不包括上限的随机数,可以使用random.randrange(a, b)函数,其参数和返回值都与randint()函数相同,但是不包括上限b。
v = random.randint(0, len(path1) - 1) # 返回随机整数,范围区间为 [low,high ),包含 low ,不包含 high
# 参数: low 为最小值, high 为最大值, size 为数组维度大小, dtype 为数据类型,默认的数据类型是 np.int• high ,默认生成随机数的范围是 [0 , low)
if u != v: # 两个城市不是同一个时
new_path = path1.copy()
t = new_path[u] # 互换两城市在序列中位置
new_path[u] = new_path[v]
new_path[v] = t
new_distance = path_length( new_path, origin)
if new_distance < length: # 两路径距离进行比较,保留更优解
length = new_distance
path1 = new_path.copy() # 列表复制
return path1 # 返回的是path
def select(origin, population, retention, live_rate): # 选择 产生的父代即交叉池
# 适应性强的染色体
graded = [[path_length(path1, origin), path1] for path1 in population] # 列表推导式 [表达式 for 变量 in 可迭代对象 if 条件]
graded = [i[1] for i in sorted(graded)] # sorted默认正序将path从小到大排列存入graded列表中。i[1]
# 选出适应性强的染色体
retain_length = int(len(graded) * retention) # len(graded)等于种群中个体个数
parents = graded[: retain_length] # 将路径小的一部分(零到retain_length)保留下来
# 保留一定存活程度强的个体
for j in graded[retain_length:]: # 遍历种群中未被保留的个体 个体即路径
if random.random() < live_rate: # 随机生成一个[0,1)内的浮点数。
parents.append(j) # 当随机数小于设定的概率时将此个体存入父代
return parents
def cross(parents, population_num): # 交叉
chi_num = population_num - len(parents) # 子代数=种群数-父代个数 父代个数不固定吧
# 孩子列表
children = []
while len(children) < chi_num:
male_index = random.randint(0, len(parents) - 1) # 随机生成父索引范围 0到父代个数
female_index = random.randint(0, len(parents) - 1)
if male_index != female_index: # 当父和母索引不同时
male = parents[male_index] # 赋予父一个path
female = parents[female_index]
position = random.randint(0, len(male) - 1) # 随机在路径序列产生一个交配位
child1 = male[:position] # 子代1获得父系的一部分
child2 = female[:position]
for i in female:
if i not in child1: # 保证路径元素不重复
child1.append(i) # 子代1获得母系的一部分成为完整个体
for i in male:
if i not in child2:
child2.append(i)
children.append(child1)
children.append(child2)
return children
def mutation(mutation_ness, children): # 互换变异
for i in range(len(children)): # 遍历子代个体的个数 零到len(children)-1
if random.random() < mutation_ness: # 变异
child = children[i]
u = random.randint(0, len(child) - 2) # 随机选择一个位置
v = random.randint(u + 1, len(child) - 1)
tmp = child[u]
child[u] = child[v] # 讲v城市换到u位置的城市
child[v] = tmp # u换到v
children[i] = child # 更新到选中的子代个体
return children
def get_result(population, origin): # 获取最优解
graded = [[path_length(path1, origin), path1] for path1 in population] # 列表推导式 [表达式 for 变量 in 可迭代对象 if 条件]
graded = sorted(graded)
best_fit = graded[0][0]
best_path = graded[0][1]
return best_fit, best_path
def GA(origin, mutation_ness, population_num, iter_num, retention, live_rate, improve_count): # 遗传算法
city_x, city_y, city_name = read_date() # 读取数据
city_count, distance = distance_citys(city_x, city_y, city_name) # 计算城市之间的距离
path = [i for i in range(city_count)] # 编码
# print(path)
path.remove(origin) # 去掉起点
population = [] # 初始化种群总数
for i in range(population_num): # 初始化
path1 = path.copy()
random.shuffle(path1) # 打乱顺序
path1 = improve(origin, path1, improve_count)
population.append(path1)
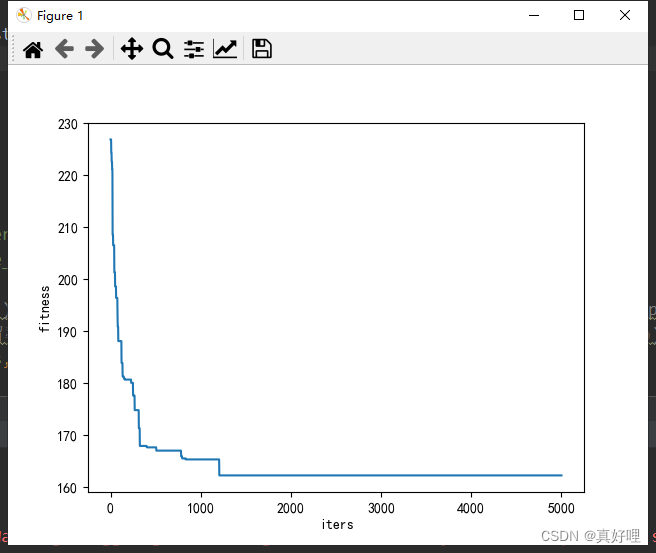
all_best = [] # 存储每一代最好的
for iters in range(iter_num): # 迭代次数
parents = select(origin, population, retention, live_rate) # 选择
children = cross(parents, population_num) # 交叉
children = mutation(mutation_ness, children) # 变异
population = parents + children # 选择后的父代和交叉变异后的子代之和
best_fit, best_path = get_result(population, origin) # 获取最优解
all_best.append(best_fit) # 每一次迭代都增加一个最佳长度
if iters % 1000 == 0: # 图片显示频率
print('迭代次数为', iters, '时最佳路径长度为', best_fit)
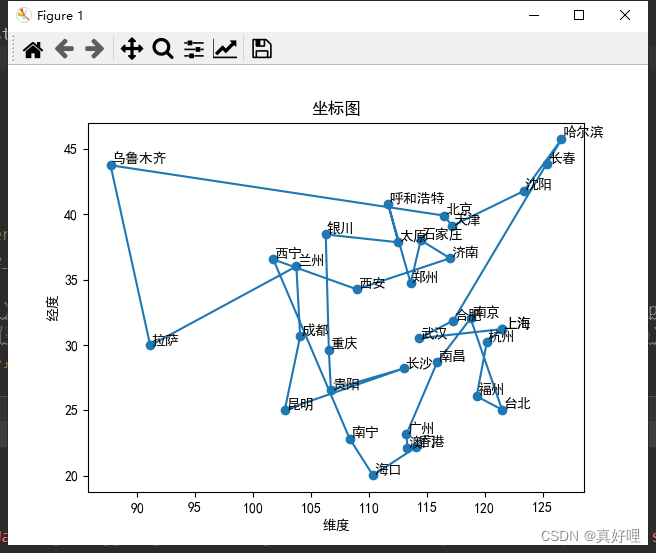
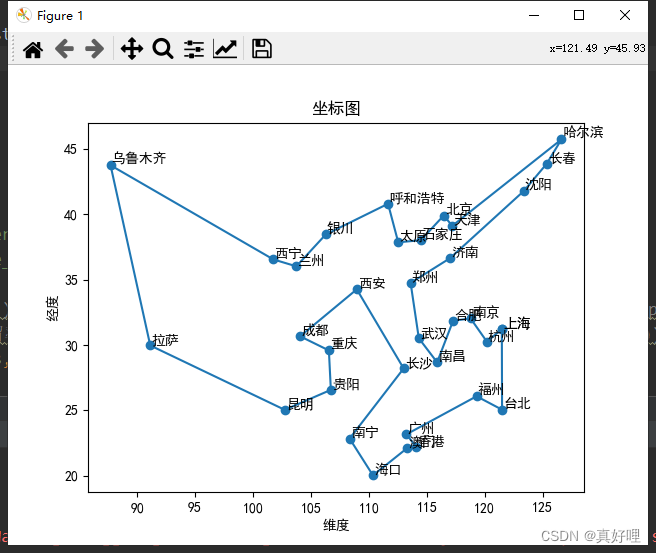
best_path = [origin] + best_path + [origin] # 拼接起点,因为加了括号加入的就是元素的拼接
plt.figure()
X = []
Y = []
for i in best_path:
X.append(city_x[i])
Y.append(city_y[i])
plt.plot(X, Y, '-o') # 用于绘制折线图。其中 X 和 Y 分别是横轴和纵轴的数据,‘-o’ 表示绘制带有圆点标记的实线
plt.xlabel('维度')
plt.ylabel('经度')
plt.title('坐标图')
for i in range(len(X)):
plt.annotate(city_name[best_path[i]], (X[i], Y[i]), (X[i] + 0.1, Y[i] + 0.1)) # 图上文字进行标注
plt.show()
# show_result()
result = best_path
result = [city_name[i] for i in result]
print('求解的最优路径为', result)
plt.figure()
plt.plot(range(len(all_best)), all_best)
plt.xlabel('iters')
plt.ylabel('fitness')
plt.show()
if __name__=="__main__":
write_data()
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签 SimHei表示黑体字
plt.rcParams['axes.unicode_minus'] = False # 这两行需要手动设置
#GA(int(input('输入起点:')), float(input('输入变异率:')), int(input('输入种群数:')), int(input('输入迭代次数:'))
#, float(input('输入保留率:')), float(input('输入生命强度:')), int(input('输入改良次数:')))
GA(2, 0.05, 300, 5001, 0.3, 0.5, 200)代码源码来自:遗传算法解决旅行商问题_叶月月的博客-CSDN博客
结果















 1139
1139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









