







一、源代码
import random
from datetime import time
import torch
import torch.nn as nn
import numpy as np
import os
import time
from matplotlib import pyplot as plt
from torch.utils.data import Dataset, DataLoader
from PIL import Image
from torch import optim
from torchvision.transforms import transforms
from tqdm import tqdm
# os.environ['CUDA_VISIBLE_DEVICES']='0,1'
def seed_everything(seed): # 随机种子,遇到好的保存,以免无法复现
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
#################################################################
seed_everything(0)
###############################################
HW = 224 # 设置长宽
# 数据增广 (对图片进行处理,如放缩,变色,让计算机学会完全掌握一张图片)
train_transform = transforms.Compose([ # 训练集
transforms.ToPILImage(), # 改变维度 224*224*3 -》 3*224*224
transforms.RandomResizedCrop(224), # 图片随机放大
transforms.RandomRotation(50), # 50°内随机旋转
transforms.ToTensor() # 转为张量
])
val_transform = transforms.Compose([ # 局部测试集
transforms.ToPILImage(), # 改变维度 224*224*3 -》 3*224*224
transforms.ToTensor() # 转为张量
])
class foodDataset(Dataset): #将文件夹中的数据读入
def __init__(self, path, mode):
x, y = self.read_file(path)
if mode == "train":
self.transform = train_transform
else:
self.transform = val_transform
self.X = x
self.Y = torch.LongTensor(y) # y里面都是整数,转化为长张量类型
def __getitem__(self, item):
return self.transform(self.X[item]), self.Y[item] # 取x时,进行数据增广
def read_file(self, path):
for i in tqdm(range(11)):
file_dir = path + "/%02d" % i # %02d表示两位整数,i=00,01,02,03
file_list = os.listdir(file_dir) # 把文件夹内所有文件名读出
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8) # 280个框,每个框里面是3*224*224的图片
yi = np.zeros((len(file_list)), dtype=np.uint8)
for j, each in enumerate(file_list):
img_path = file_dir + "/" + each # 拼凑每个图片的路径
img = Image.open(img_path) # 读入图片
img = img.resize((HW, HW)) # 重新设置长宽
xi[j, ...] = img # 把照片放入框中
yi[j] = i
if i == 0: # 第一个文件夹下的照片和标签直接保存到X和Y中,后续文件夹的照片和标签”竖直拼接“在X和Y后面
X = xi
Y = yi
else:
X = np.concatenate((X, xi), axis=0)
Y = np.concatenate((Y, yi), axis=0)
print("共读入%d张照片" % len(Y))
return X, Y
def __len__(self):
return len(self.X)
##########################################################
# conv2d(输入特征图厚度,输出特征图厚度,卷积核大小,步长,padding) #
# pool(3,2) 3*3化为一格 步长为2(维度减半) #
# 输出特征图大小公式 O = (I - K + 2P)/S + 1 #
##########################################################
class myModel(nn.Module):
def __init__(self, num_class): # 类别数
super(myModel, self).__init__() # 3*224*224 -> 512*7*7 ->1000 -> 11
# 传统写法
# self.conv1 = nn.Conv2d(3, 64, 3, 1, 1) # 3*224*224->64*224*224
# self.bn = nn.BatchNorm2d(64) # ?????????????????????批量归一化
# self.relu = nn.ReLU()
# self.pool1 = nn.MaxPool2d(2) # 最大值池化 64*224*224 -> 64*112*112
#省劲写法
self.Layer1 = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # 3*224*224->64*224*224
nn.BatchNorm2d(64), # ?????????????????????批量归一化
nn.ReLU(),
nn.MaxPool2d(2) # 最大值池化 64*224*224 -> 64*112*112
)
self.Layer2 = nn.Sequential(
nn.Conv2d(64, 128, 3, 1, 1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2)
# 64 * 112 * 112 -> 128 * 56 * 56
)
self.Layer3 = nn.Sequential(
nn.Conv2d(128, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2)
# 128 * 56 * 56 -> 256 * 28 * 28
)
self.Layer4 = nn.Sequential(
nn.Conv2d(256, 512, 3, 1, 1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2)
# 512 * 14 * 14
)
self.pool1 = nn.MaxPool2d(2)
# 512 * 7 * 7 = 25088
# 拉直 用全链接 并分类为设定的类别数
self.fc1 = nn.Linear(25088, 1000)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(1000, num_class)
def forward(self, x):
x = self.Layer1(x)
x = self.Layer2(x)
x = self.Layer3(x)
x = self.Layer4(x)
x = self.pool1(x)
x = x.view(x.size()[0], -1) # 拉直
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
def train_val(model, train_loader, val_loader, device, epochs, optimizer, loss, save_path):
model = model.to(device)
plt_train_loss = []
plt_val_loss = []
plt_train_acc = []
plt_val_acc = []
max_val_acc = 0.0
for epoch in range(epochs): # 训练标志
train_loss = 0.0
val_loss = 0.0
train_acc = 0.0
val_acc = 0.0
start_time = time.time()
model.train() # 训练模式
for batch_x, batch_y in train_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x) # 数据通过模型,会有梯度 #前传
train_bat_loss = loss(pred,target) #算出loss
#train_bat_loss = loss(pred, target, model) # 自定义loss(正则化)
train_bat_loss.backward() # 梯度回传
optimizer.step() # 更新参数
optimizer.zero_grad() # 清零所有参数的梯度
train_loss += train_bat_loss.cpu().item()
# 找到最大值所在下标 从gpu取下来,转为矩阵形式 求出横向最大值
train_acc += np.sum(np.argmax(pred.detach().cpu().numpy(),axis=1) == target.cpu().numpy()) #进行判断,并算出判断正确的个数
plt_train_loss.append(train_loss / train_loader.dataset.__len__()) #计算平均loss
plt_train_acc.append(train_acc / train_loader.dataset.__len__()) #计算准确率
model.eval() # 测试验证
with torch.no_grad():
for batch_x, batch_y in val_loader:
val_x, val_target = batch_x.to(device), batch_y.to(device)
val_pred = model(val_x) # 计算预测值
val_bat_loss = loss(pred, target) # 算出loss
#val_bat_loss = loss(pred, target, model) # 自定义loss(正则化)
val_loss += val_bat_loss.cpu().item() # 累计loss和
# 找到最大值所在下标 从gpu取下来,转为矩阵形式 求出横向最大值
val_acc += np.sum(np.argmax(val_pred.detach().cpu().numpy(), axis=1) == val_target.cpu().numpy()) # 进行判断,并算出判断正确的个数
plt_val_loss.append(val_loss / val_loader.dataset.__len__())
plt_val_acc.append(val_acc / val_loader.dataset.__len__()) # 计算准确率
if val_acc > max_val_acc:
torch.save(model, save_path)
max_val_acc = val_acc
print("[%03d/%03d] %2.2f secs Trainloss: %.6f Trainacc: %.6f Valloss: %.6f Valacc: %.6f"
%(epoch, epochs, time.time() - start_time, plt_train_loss[-1],plt_train_acc[-1], plt_val_loss[-1], plt_val_acc[-1]))
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title("loss")
plt.legend(["train", "val"])
plt.show()
plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title("acc")
plt.legend(["train", "val"])
plt.show()
#迁移学习 用大佬们的特征提取器
def initialize_model(model_name, num_classes, linear_prob=False, use_pretrained=True):
# 初始化将在此if语句中设置的这些变量。
# 每个变量都是模型特定的。
model_ft = None
input_size = 0
if model_name =="MyModel":
if use_pretrained == True:
model_ft = torch.load('model_save/MyModel')
else:
model_ft = MyModel(num_classes)
input_size = 224
elif model_name == "resnet18":
""" Resnet18
"""
model_ft = models.resnet18(pretrained=use_pretrained) # 从网络下载模型 pretrain=true 使用参数和架构 false 仅使用架构
set_parameter_requires_grad(model_ft, linear_prob) # 是否为线性探测,线性探测: 固定特征提取器不训练。
num_ftrs = model_ft.fc.in_features #分类头的输入维度
model_ft.fc = nn.Linear(num_ftrs, num_classes) # 删掉原来分类头, 更改最后一层为想要的分类数的分类头。
input_size = 224
elif model_name == "resnet50":
""" Resnet50
"""
model_ft = models.resnet50(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "googlenet":
""" googlenet
"""
model_ft = models.googlenet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "alexnet":
""" Alexnet
"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg":
""" VGG11_bn
"""
model_ft = models.vgg11_bn(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "squeezenet":
""" Squeezenet
"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
""" Densenet
"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
""" Inception v3
Be careful, expects (299,299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
# 处理辅助网络
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# 处理主要网络
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs,num_classes)
input_size = 299
else:
print("Invalid model_utils name, exiting...")
exit()
return model_ft, input_size
#model = myModel(11) 自己写的
model,_ = initialize_model("resnet18", 11, use_pretrained= True) #返回了俩个值,第二个不要
# train_set = foodDataset(r"C:\Users\86157\Desktop\自学\food-classification\food-11_sample\training\labeled", mode="train")
#val_set = foodDataset(r"C:\Users\86157\Desktop\自学\food-classification\food-11_sample\validation", mode="val")
train_set = foodDataset(r"C:\Users\86157\Desktop\自学\food-classification\food-11\training\labeled", mode="train")
val_set = foodDataset(r"C:\Users\86157\Desktop\自学\food-classification\food-11\validation", mode="val")
# _,_1 = read_file(r"C:\Users\86157\Desktop\自学\food-classification\food-11_sample\training\labeled")
train_loader = DataLoader(train_set, batch_size=16, shuffle=True) # 提供一批数据
# _,_1 = read_file(r"C:\Users\86157\Desktop\自学\food-classification\food-11_sample\training\labeled")
val_loader = DataLoader(val_set, batch_size=16, shuffle=True) # 提供一批数据
lr = 0.001
optimizer = optim.AdamW(model.parameters(), lr, weight_decay=0.0001) # 考虑历史的梯度,更具有全局观 #模型参数,学习率,权重衰减
loss = nn.CrossEntropyLoss() # 交叉商损失,传入模型输出和标签,即可得loss
device = "cuda" if torch.cuda.is_available() else "cpu"
epochs = 20
save_path = r"C:\Users\86157\Desktop\自学\food-classification\best_model"
train_val(model, train_loader, val_loader, device, epochs, optimizer, loss, save_path)
代码中所需数据集下载地址:ml2021spring-hw3 | Kaggle
二、遇到的问题
1、NotImplementedError报错
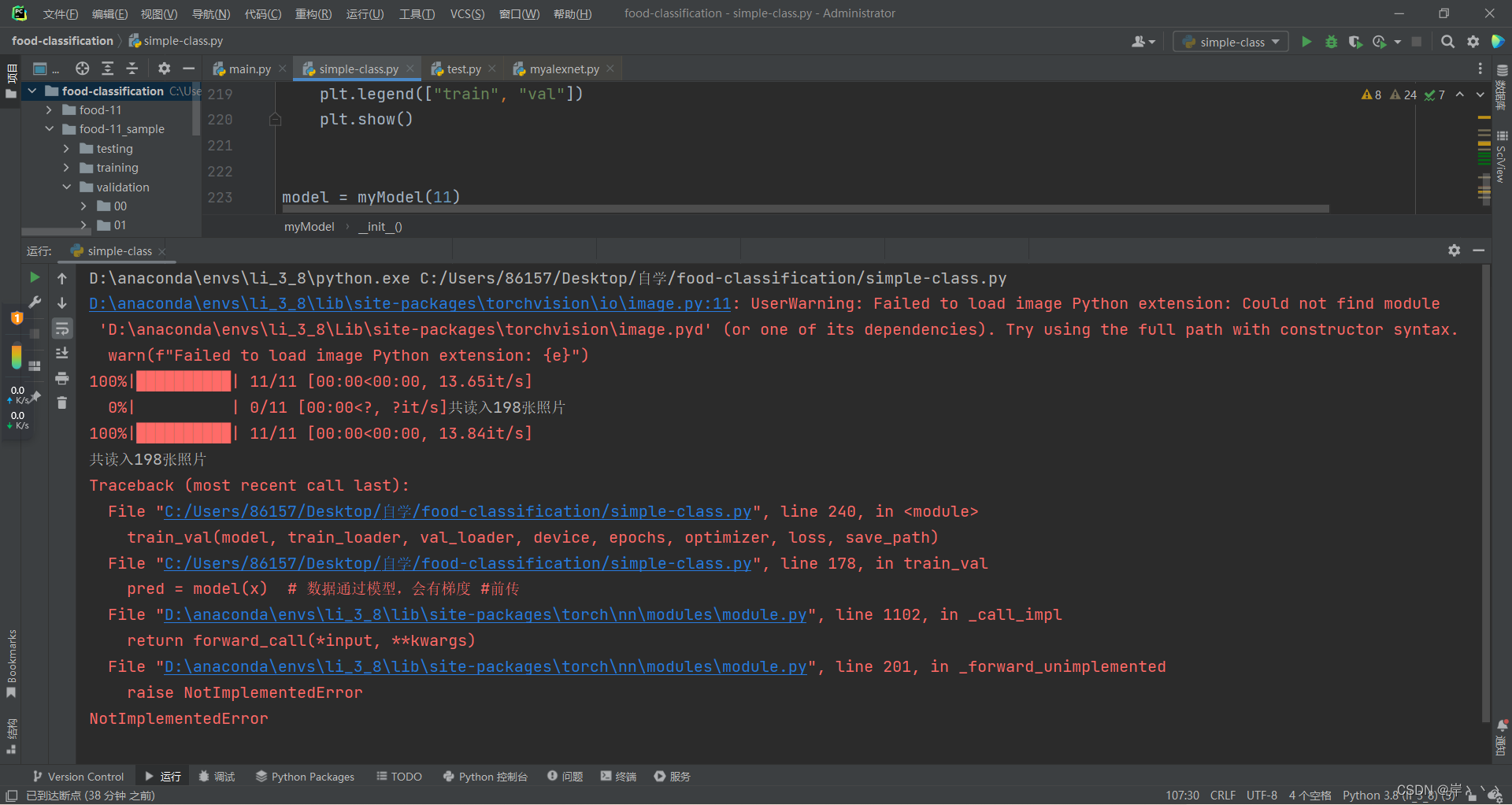
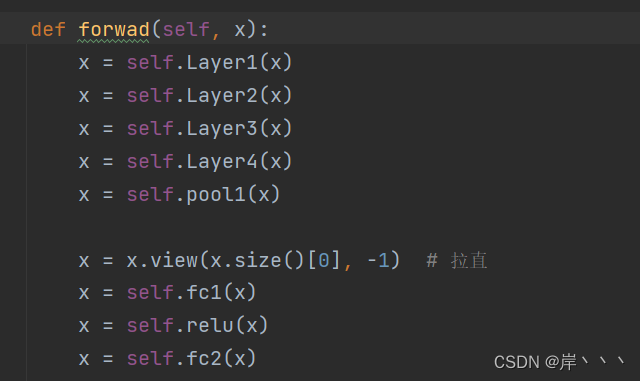
myModel类中,方法“forward”拼错
三、本次学习总结
- 要保持每个数据的平等地位--->独热编码
- 直接对原图进行拉直,用长列向量来训练,参数量过大,因此采用卷积神经网络
- 感受野:特征图的一部分,鸟嘴或者猫耳
- zero padding(零填充)保持特征图在卷积后的大小不变
- 卷积核参数量计算=特征图个数*每层格子数*深度(卷积核总格子数)+1(一个偏置值)
- 缩小特征图(Sbusampling),
扩大步长:正常卷积一次移动一格,扩大步长可以让卷积计算时扩大每次移动的格子数,使特征图与感受野比对后变小,达到缩小特征图的目的。
卷积尺寸计算公式:O = (I-K+2P)/S+1
I:input(输入特征图的维度) K:卷积核大小(维度) P:padding S:stride(步长)
池化(pooling):划分为多个区域,每个区域用一个数值表示(最大值,平均值)
自适应池化Adaptive Pooling:设置输出的大小,交给pytorch
7.softmax 方法: 使输出数值变为概论分布
8.Dropout:丢弃某些神经元,缓解过拟合
补充:
- 归一化:可以让模型关注数据的分布,而不受数据量纲的影响,归一化可以保持学习有效性,缓解梯度消失和梯度爆炸。
- Batch-Normalization (BN),是一种让神经网络训练更快、更稳定的方法(faster and more stable)。它计算每个mini-batch的均值和方差,并将其拉回到均值为0方差为1的标准正态分布。BN层通常在nonlinear function的前面/后面使用。
- Vgg网络被提出,在AlexNet的基础上,运用更小的卷积核,并且加深了网络,达到了更好的效果(更深,更大)
- 梯度爆炸,梯度消失(relu解决),层数太深,指数爆炸增长导致梯度爆炸,回传到开头数值过小导致梯度消失
- restNet,何凯明老师,用f(x)+x代替f单纯的f(x),使经过操作后的预测值更加接近真实值,有效的防止梯度消失
- 显卡推动深度学习的快速发展
- 卷积与全连接的关系,卷积是一种参数共享的“不全链接”
- 深度学习=玩特征,特征一般是一个一维向量
- 迁移学习:数据量少时的最佳选择,用大佬预训练后的特征提取器,再加上自己微调,以提高模型的分类准确率
















 5204
5204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











