







 本文详细介绍了如何在Windows和Linux系统中使用TesseractOCR库进行图像文字识别,包括依赖管理、网络资源处理、文件操作以及在不同环境下的Tesseract配置和代码实现。
本文详细介绍了如何在Windows和Linux系统中使用TesseractOCR库进行图像文字识别,包括依赖管理、网络资源处理、文件操作以及在不同环境下的Tesseract配置和代码实现。
1.Windows使用
1.引入依赖
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.5</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>8.11.1</version> <!-- 版本号根据您的实际需求进行调整 -->
</dependency>
<dependency>
<groupId>org.apache.ant</groupId>
<artifactId>ant</artifactId>
<version>1.10.11</version>
</dependency>2.代码实现
try {
//创建一个网络资源对象
URL image = new URL(url);
//创建文件对象
File file = new File("命名一个临时文件");
//将网络资源文件对象中的内容复制到文件中
FileUtils.copyURLToFile(image, file);
//创建Tesseract识别对象
Tesseract tesseract = new Tesseract();
tesseract.setDatapath("训练库地址");
//设置识别语言,对应训练库名称
tesseract.setLanguage("chi_sim");
String result;
BufferedImage imageRead = ImageIO.read(file);
result = tesseract.doOCR(imageRead);
stringContent.append(result);
file.delete();
} catch (IOException e) {
} catch (TesseractException e) {
}2.Linux使用
1.在linux系统上安装Tesseract
参靠下面博主的文章
【tesseract】Linux环境安装tesseract教程(一)_linux tesseract-CSDN博客
2.程序中拷贝生成so文件
将下面文件夹中的这两个文件拷贝到Java程序中resource下的linux-x86-64文件夹中
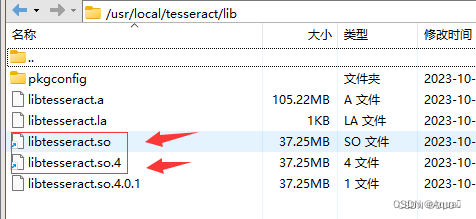
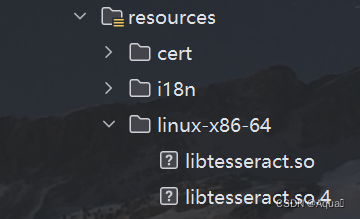
3.程序中使用同windows一样的依赖
4.代码实现
try {
//创建一个网络资源对象
URL image = new URL(url);
//创建文件对象
File file = new File("命名一个临时文件");
//将网络资源文件对象中的内容复制到文件中
FileUtils.copyURLToFile(image, file);
//创建Tesseract识别对象
Tesseract tesseract = new Tesseract();
//linux环境
//安装Tessercat的时候,将这个路径配置在环境变量中了
String dataPath = System.getenv("TESSDATA_PREFIX");
tesseract.setDatapath(dataPath);
//设置识别语言,对应训练库名称
tesseract.setLanguage("chi_sim");
String result;
BufferedImage imageRead = ImageIO.read(file);
result = tesseract.doOCR(imageRead);
stringContent.append(result);
file.delete();
} catch (IOException e) {
} catch (TesseractException e) {
}















 1143
1143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











