






 本文探讨了如何利用多维度时序数据的关联性改进指标稳定性评估,提出了加权归一阈值方法,通过考虑相关性系数、超限数值和指标数量,给出综合稳定性的判断。案例以内存告警为例,展示了如何通过这种方法有效降低误报,提高告警准确性。
本文探讨了如何利用多维度时序数据的关联性改进指标稳定性评估,提出了加权归一阈值方法,通过考虑相关性系数、超限数值和指标数量,给出综合稳定性的判断。案例以内存告警为例,展示了如何通过这种方法有效降低误报,提高告警准确性。
很多情境下,我们都会遇到收集的多维度的时序性的数据,比如运维中的主机各项指标数据,网页中的各项埋点数据等等。通常情况下通过某一指标上的时序预测结果与真实值的比较来判断这一指标是否稳定,这个常用方法的缺陷是只利用起了一个维度的数据(使得模型单薄)。然而既然我们收集到了时序上多维度的数据,如何综合整合多维时序数据为该指标综合判定得出指标是否稳定的结果,是本片文章探讨的一个方向。
默认情况下我们认为收集的多维度数据本身存在相互关系,例如主机各项指标,之间一定存在一定的关系,而不是好不相关。基于这一前提下,我们在对多维的时序预测结果思考一个综合判定的方法。
基于这一思考提出一种综合评判的方法:
加权归一阈值
目的
一个合适的计算公式,综合考虑多维度之间的相关性系数、时序维度上同一时刻超出阈值数值量、同一时刻超出阈值的指标数量而给出综合的结果。
解释
公式表示:
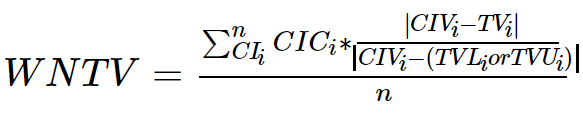
名词解释:
Correlation index{CI} : 相关指标
Correlation index corr{CIC} : 相关指标相关系数
Correlation index value{CIV} : 相关指标数值
threshold value {TV} : 阈值
threshold value up{TVU} : 阈值上限
threshold value low{TVL} : 阈值上限
weighted normalization threshold value {WNTV} : 加权归一阈值量
过程解释:
上式主要将三个角度上的数值: 同一时刻超出阈值的指标个数、同一时刻指标超出阈值指标的超出量、同一时刻每个超出阈值指标与目标指标相关性系数 ;这三个维度的计算结果加权调和成所谓的WNTV加权归一阈值。接下来对各部分解释如图:
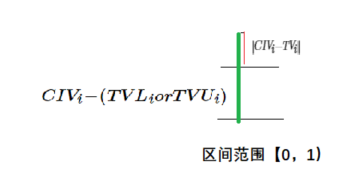
如图,上下两个横线为某指标当前时序预测所给出的上限值下限值。上边红线表示真实值与预测上限的距离(即同一时刻指标超出阈值指标的超出量),绿线为真实值与预测下限的距离。红线部分与绿线的商值构成公式的分子的后半部分。
这样的设计目的在于:针对一个样本的计算,将脱离阈值的大小有效归一化在与下限的和中,可以对于小范围波动的情况,有很好的敏感性,对于大范围波动的情况,有很好的适应性。
随后的公司部分表示,将超限指标的相关系数作为权项,给超出值加上权重,并加权平均起来。加权求和平均之后可以有效将所有相关指标值综合起来。数值范围在0到1之间,越接近一表示综合超阈值情况越严重。
加权归一阈值量可以有效的反应目标指标,综合与其相关指标状态,给出综合脱离阈值范围的情况。
结合下面列子,便于更好理解这一过程,和应用场景:
应用例子(内存告警)
背景介绍:
目前的内存指标告警,是通过单一的限制阈值的机制,如内存超过80%进行告警。
实际情景下,由于主机内存128G比较小,主机内存使用率高于80%时,其他指标占用率较低,因此主机在内存占用较高的情况下仍为正常运行状态,无需告警。
为了解决这个问题,引用多维数据综合分析,加权归一阈值的方法,可以有效降低告警误报率。
该算法需要关于主机多维度指标的数据。通过对多维度的数据趋势分析,综合结果给出一个告警结论。
数据集介绍:
https://github.com/CloudWise-OpenSource/GAIA-DataSet https://github.com/CloudWise-OpenSource/GAIA-DataSet云智慧 AIOPS社区https://www.cloudwise.ai/index.html数据集使用的是该社区提供的开源数据集,该数据集中有主机指标数据集,将系统基础指标的实时体现记录,数据亦反应了服务在运行过程中,对系统造成的影响的实时反应。对系统指标实时的监控,能有效的反应系统或服务的状态,对系统异常进行检测和预警。
https://github.com/CloudWise-OpenSource/GAIA-DataSet云智慧 AIOPS社区https://www.cloudwise.ai/index.html数据集使用的是该社区提供的开源数据集,该数据集中有主机指标数据集,将系统基础指标的实时体现记录,数据亦反应了服务在运行过程中,对系统造成的影响的实时反应。对系统指标实时的监控,能有效的反应系统或服务的状态,对系统异常进行检测和预警。
主机指标数据集,每个csv文件名包含文件所属的节点、ip、对应的指标名称和时间段,对应数值,这些都是根据固定的时序记录生成的。
基础指标数据,在data文件夹下,每个压缩包代表一个服务节点的基础指标数据,包括cpu、memory、disk等一系列指标。
这里使用dbservice1_0.0.0.4_docker服务节点docker所在主句数据进行分析。
系统个服务器配置图表:
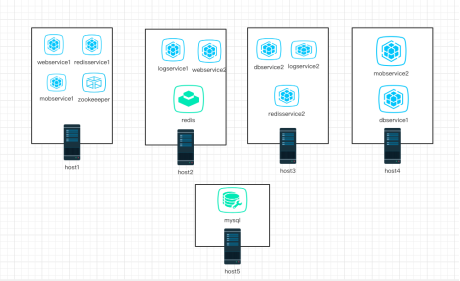
上图为整个系统配置图。一个主机被docker容器隔离,部署多个服务。为每种类型的服务部署了两个容器实例,它们都位于不同的主机上。每个服务都在zookeeper上注册。地址,也可以通过zookeeper获取其他服务的地址。
dbservice1_0.0.0.4_docker节点所在主机为host4号主机。
数指标介绍
字段量
['timestamp', 'docker_cpu_core_0_norm_pct', 'cpu_core_0_pct_value', 'cpu_core_0_ticks_value', 'cpu_core_10_norm_pct_value', 'cpu_core_10_pct_value', 'cpu_core_10_ticks_value', 'cpu_core_11_norm_pct_value', 'cpu_core_11_pct_value', 'cpu_core_11_ticks_value', 'cpu_core_12_norm_pct_value', 'cpu_core_12_pct_value', 'cpu_core_12_ticks_value',
.............
'network_in_errors_value', 'network_in_packets_value', 'network_outbound_bytes_value', 'network_outbound_dropped_value', 'network_outbound_errors_value', 'network_outbound_packets_value', 'network_out_bytes_value', 'network_out_dropped_value', 'network_out_errors_value', 'network_out_packets_value']
共计156个指标
部分字段名称含义
docker_cpu_core_0_norm_pct 代表cpu 0号核使用率;
docker_cpu_core_0_ticks系统时钟每秒的tick数量;
docker_cpu_kernel_norm_pct 内核占用率;
docker_diskio_read_bytes 硬盘读子节量;
docker_diskio_read_ops 硬盘读操作统计;
docker_diskio_read_queued 硬盘读取队列;
docker_diskio_read_rate 读取速率;
docker_diskio_write_bytes 硬盘写入字节数;
docker_memory_fail_count 内存失败计数;
docker_memory_limit 内存限制;
memory_rss_pct 内存rss 使用率;
docker_memory_stats_active_anon 分配的内存状态;
.......
为了方便使用,数据并清洗处理后的数据提供在这个地址里(且用且珍惜):
链接:https://pan.baidu.com/s/1ekZiERg3J7gPmxd8_uqWXA
提取码:i0ik
各个指标线性图直观分析;
内存使用总量和其他指标对比
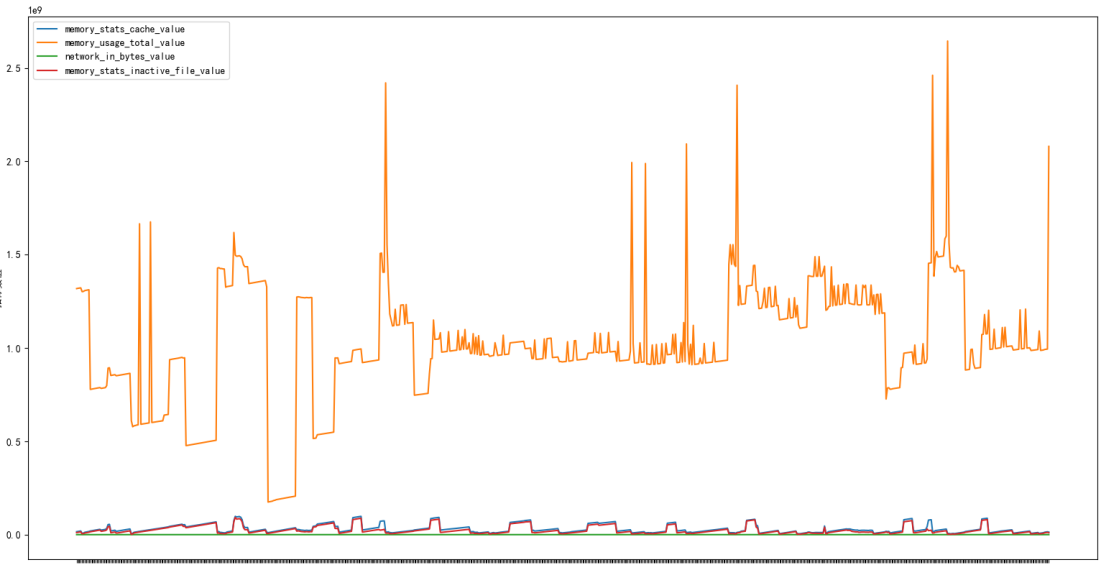
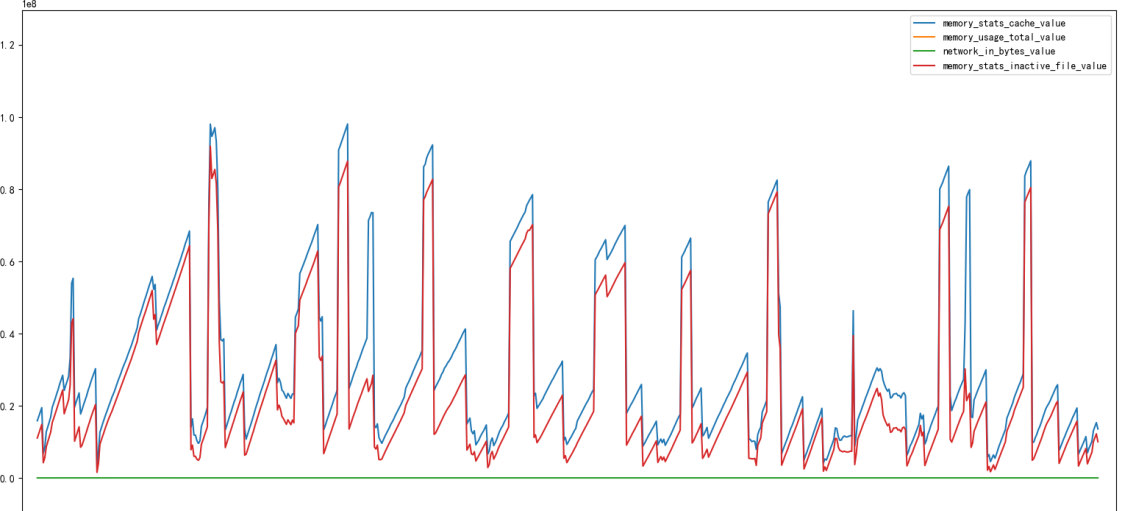
缓存和内存读入量折线图
读数据模拟生产环境
将表格写入数据库模拟真实的数据环境
读数据库可以基于最后一条向前选时间段内的数据:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@author:time-无产者
@file:finall_code.py
@time:2022/05/06
"""
import os
import pandas as pd
import numpy as np
from datetime import datetime
from sqlalchemy import create_engine
from fbprophet import Prophet
import matplotlib.pyplot as plt# 数据提取和处理=========================================================================
engine = create_engine("mysql+pymysql://root:pwd@localhost:3306/database?charset=utf8")
def r_sql(days):
'''
:param days:读多久的数据 单位天 int
:return: 相应天数的数据 df
'''
oneday = 120 * 24
day_use = days * oneday
sql_line = rf"select * from (select * from info_demo order by timestamp desc limit {day_use}) a order by a.timestamp"
# sql_line1 = "select * from info_demo"
df = pd.read_sql(sql_line, engine)
# print(df)
# print(df.info())
# print(df.describe())
# 时间格式转换
df['timestamp'] = pd.to_datetime(df['timestamp'])
# times = pd.date_range(start='2021/7/1 19:00:00', end='2021/7/14 23:59:30', freq='3min')
return df
相关性分析
目的
相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度。相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析。针对内存使用率与其他指标相关性分析,意在找到指标中适合的辅助指标来综合评判内存使用的实时状态,以到达必要的内存告警要给出反应,不必要的告警隐藏的目地。
# 计算相关系数============================================================================
def get_corr(df, clo, threshold=[0.3, 1]):
'''
:param df:输入的df -->df
:param clo: 分析的列 -->str
:param threshold: 输出指标的相关性系数范围 -->list
:return: 返回指标名称和相关系数值 -->dict
'''
# print(df.info())
hot_map = df.corr()
res = hot_map[clo][(hot_map[clo] >= threshold[0]) & (hot_map[clo] <= threshold[1])]
# print(res)
res_dic = res.to_dict()
return res_dic
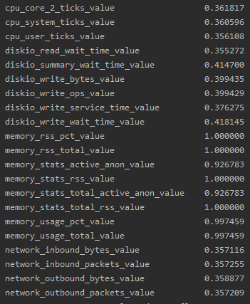
代码运行结果:
时序预测模型
目的
单一的阈值方法不能有效的解决告警问题,在于本身内存量较小,但是并不妨碍系统的正常运行,而单一的内存使用率阈值处理方法并没有一个有效的机制使告警考虑到系统有效运行状态。时序预测则可以基于过去一段时间的平稳运行数据推测出下一个小范围内时间的运行数据。通过过去时间推测和接下来数据的对比,从而可以形成一个动态的阈值触发告警的机制。达到考虑到系统有效运行状态下的动态阈值内存告警。
一个指标采用基于过去一小时预测未来3分钟的时序模型图:
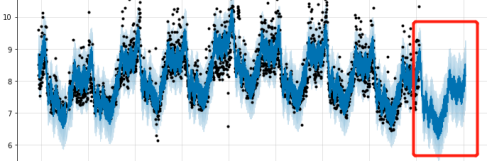
network_in_bytes_value的时序预测,与真实值结果比较:
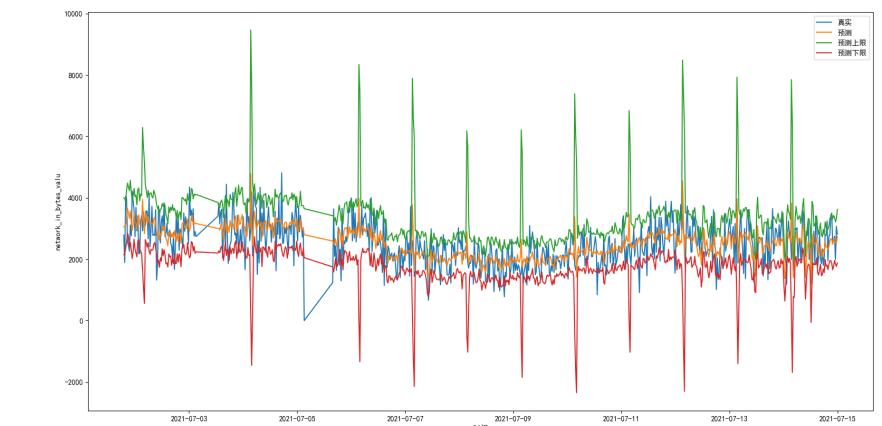
时间段内细化图:
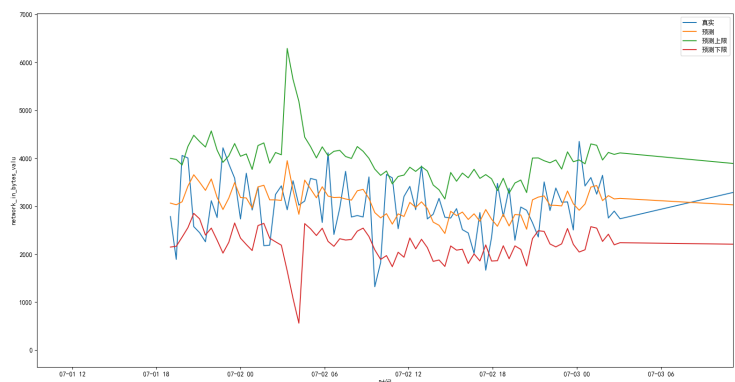
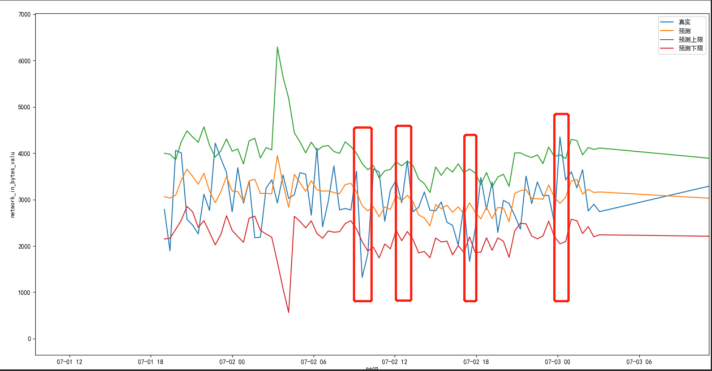
超出预测值上下限范围则考虑告警:
相关指标动态阈值
目的
通过多维度数据中其他维度和内存相关性高的维度的数据的动态时序预测,为多维度的信息同时形成动态阈值的机制。通过各个指标和动态阈值相关数据计算综合评估告警,从而提高告警的准确性。
实例:4个指标同时间轴维度的时序动态阈值图
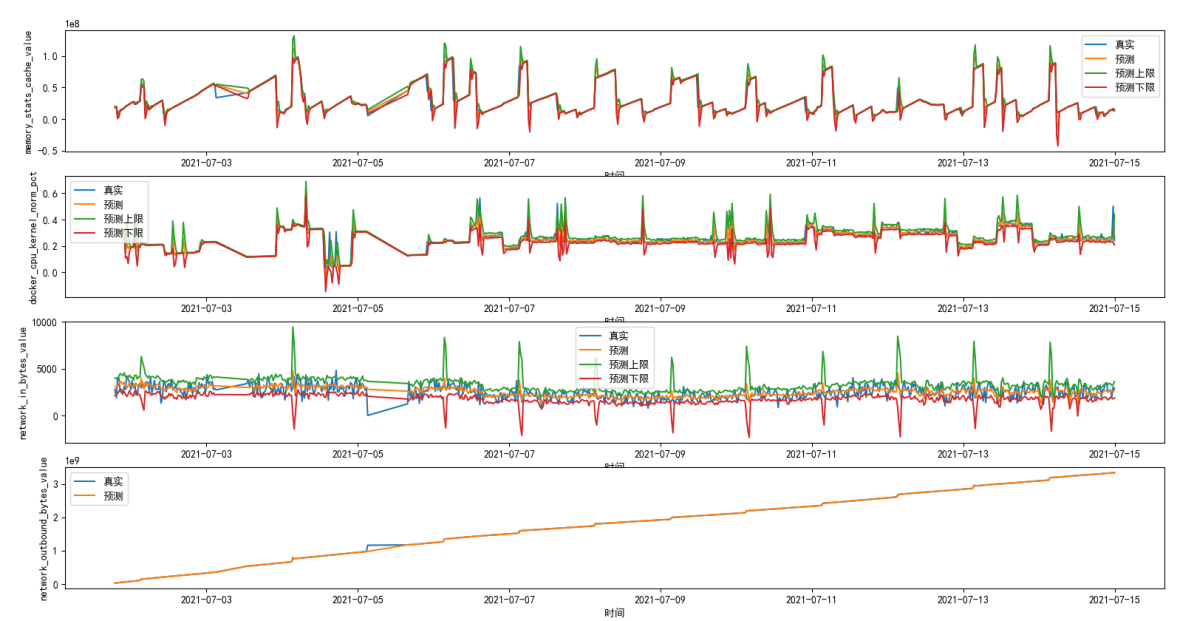
细化时间段:
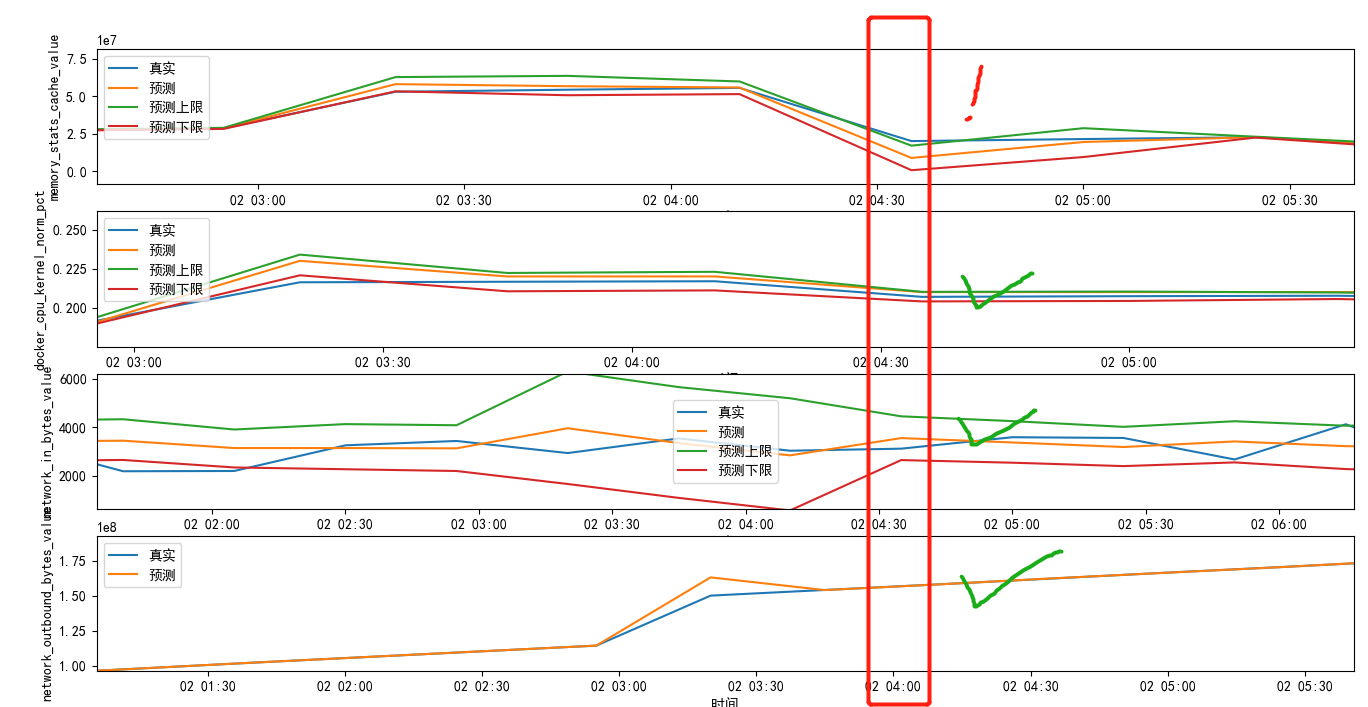
最终代码:
# 时序预测模块============================================================================
def phet(df, col, stat_time):
'''
:param df: 时序数据--> df
:param col: 时序计算的的指标 -->str
:param stat_time: 预测的条目数 --> int
:return: 返回时序预测的结果 --> df
'''
df_t = df.rename(columns={'timestamp': 'ds', col: 'y'})
# 判断fit数据集是否有效果
if len(df_t) > 2:
# 拟合模型
m = Prophet()
m.fit(df_t)
# 构建待预测日期数据框,periods = 6 代表除历史数据的日期外再往后推 8*30s,即未来3分钟
future = m.make_future_dataframe(periods=stat_time, freq='30S')
# 预测数据集
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
# forecast['yhat_upper']=forecast['yhat_upper']*1.01
# forecast['yhat_lower']=forecast['yhat_lower']*0.99
# print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']])
# trend = forecast['yhat'].tolist()
# # 展示预测结果
# test_result = m.plot(forecast)
# # print(forecast)
# # m.plot(forecast).savefig('qushi.png')
# # 预测的成分分析绘图,展示预测中的趋势、周效应和年度效应
# test_detailed = m.plot_components(forecast)
# # m.plot_components(forecast).savefig('three_img.png')
# plt.show()
thres_df = forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']][-stat_time:]
thres_df.columns = ['timestamp', col + '_pre', col + '_l', col + '_u']
return thres_df
else:
print('输入时序数据数据量不够')
return None
def timeserised_pre(df, stat_time, corr_dic):
'''
:param df: 总数据 -->df
:param stat_time: 预测的条数 --> int
:param corr_dic: 关注的指标 --> dict
:return: 预测的数值加
'''
columns = [i for i in corr_dic.keys()]
# print(len(df))
all_clo = ['timestamp'] + columns
df_pre = df[all_clo]
# print(df_pre)
# print(len(df_pre))
# 遍历需要预测的指标并进行最后时间段的预测
pre_res = pd.DataFrame()
for col in columns:
# 只保留时间和指标两列
one_df = df_pre[['timestamp', col]]
# 获取3分钟前的数据
one_df = one_df[:-stat_time]
pre = phet(one_df, col, stat_time)
pre[col] = df_pre[col][-6:].tolist()
# print(pre)
# 合并预测值、阈值
if col == columns[0]:
pre_res = pre
continue
pre_res = pd.merge(pre_res, pre, on='timestamp', how='inner')
# print(pre_res)
# print(pre_res.info())
# print(pre_res.describe())
return pre_res综合评判告警
目的
使用加权归一阈值公式,综合考虑多维度之间的相关性系数、时序维度上同一时刻超出阈值数值量、同一时刻超出阈值的指标数量而给出综合的结果。
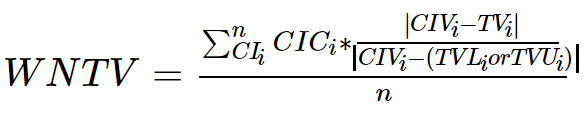
最终代码:
# 计算加权归一阈值=======================================================================
def calculate_wntv(df, corr_dic):
'''
:param df: 预测数据中的每一行 -->df
:param corr_dic: 相关系数字典 -->dict
:return: 加权归一阈值wntv --> flot
'''
l = []
columns = [i for i in corr_dic.keys()]
for col in columns:
data = df[[col, col + '_pre', col + '_l', col + '_u']]
# print(data)
col_true = data[col].tolist()[0]
col_u = data[col + '_u'].tolist()[0]
col_l = data[col + '_l'].tolist()[0]
cor = corr_dic[col]
# print('真实值:',col_true)
# print('上限阈值:',col_u)
# print('下限阈值:',col_l)
tvi = ((col_true - col_u) / (col_true - col_l)) * cor
if tvi > 0:
l.append(tvi)
# print('tvi的值',l)
if len(l) == 0:
wntv = 0
# print('该时刻状态良好')
return wntv
wntv = sum(l) / len(l)
# print('wntv的值:',wntv)
return wntv
def WNTV(df, corr_dic):
'''
:param df: 预测数据 -->df
:param corr_dic: 相关系数字典 -->dict
:return: 加权归一阈值wntv --> flot
'''
res = []
for i in range(len(df)):
per_wntv = calculate_wntv(df.loc[[i]], corr_dic)
res.append(per_wntv)
print(res)
return sum(res) / len(res)结果结论
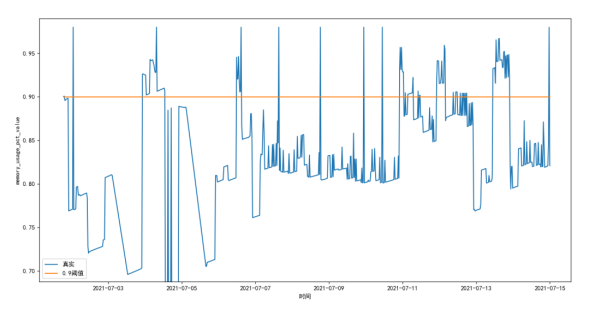
单一内存阈值告警强情况下如下图:
以超过90%为阈值,则告警数据6023条,其中大多数数据同时刻其他指标变现正常。
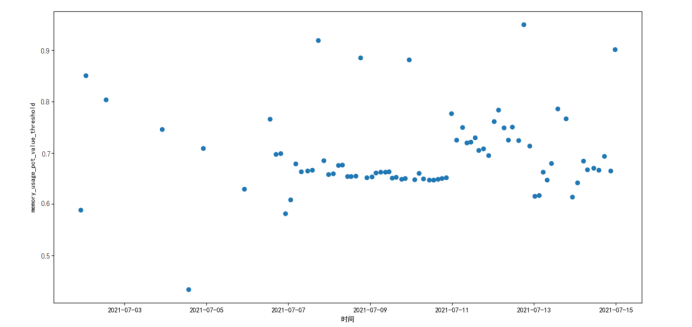
取WNTV加权归一阈值量置信度为0.3时,多维度分析告警强情况下如下图:
标点为产生告警点,总计告警数据2035条,其中大多数数据同时刻其他指标变现正常。
有效减低了报警次数,且在告警样本中,其他指标多是出现异常的情况。

















 292
292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









