







Step1:导入所需的模块
import csv
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn import preprocessing
from mpl_toolkits.mplot3d import axes3dStep2:导入所需数据
nodedata=pd.read_csv('node.data.txt')
newnodedata=nodedata.loc[0:9][["population","Total industrial output value","Consumption of material assets"]]
newnodedata#读取指定的行和列,多个列同时读取要加[]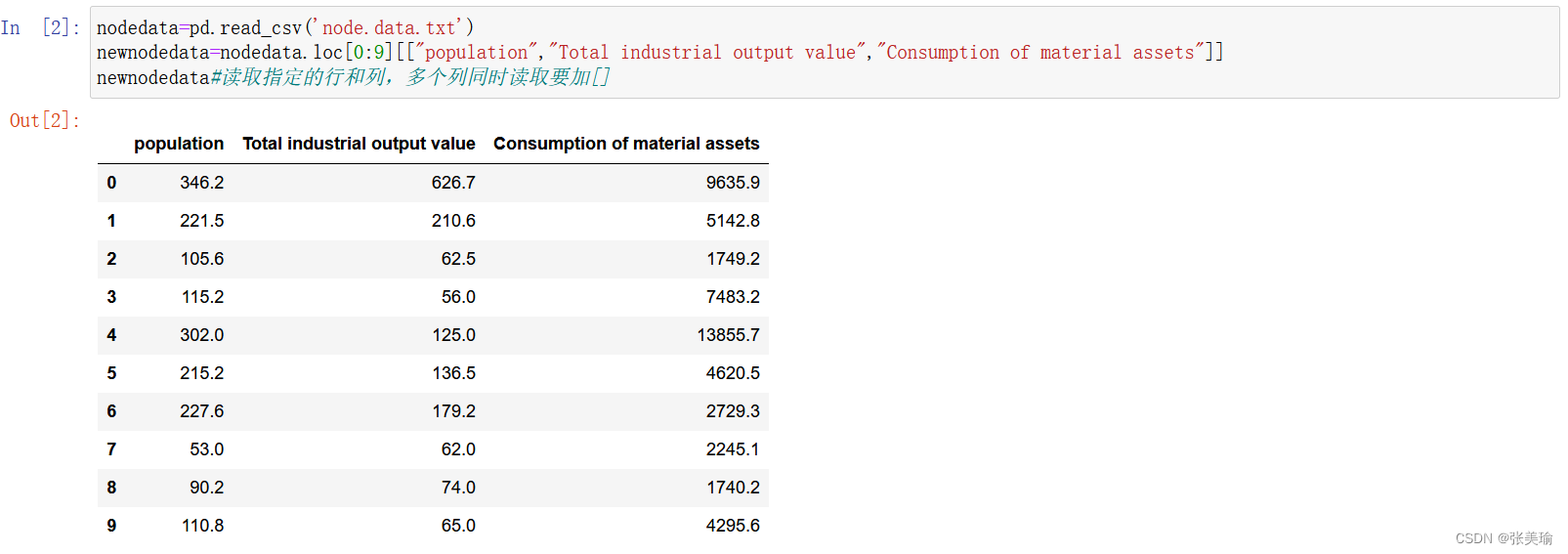
Step3:数据预处理
dataset_array=np.genfromtxt('node.data.txt',delimiter=',',skip_header=1,usecols=(1,2,3))#跳过第一行表头,读取有效的三列数据,以数组形式存储,不可删除
print(dataset_array) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4344
4344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









