






首先将坐标数据放入一个矩阵中
Coornidate=[103.73 36.03;
103.73 36.03;
101.74 36.56;
104.06 30.67;
114.48 38.03;
102.73 25.04;
106.71 26.57;
114.31 30.52;
113.65 34.76;
117.00 36.65;
118.78 32.04;
117.27 31.86;
120.19 30.26;
115.89 28.68;
119.30 26.08;
113.23 23.16;
113.00 28.21;
110.35 20.02;
123.38 41.80;
125.35 43.88;
126.63 45.75;
112.53 37.87;
108.95 34.27;
121.30 25.03;
116.46 39.92;
121.48 31.22;
106.54 29.59;
117.20 39.13;
111.65 40.82;
108.33 22.84;
91.11 29.97;
106.27 38.47;
87.68 43.77;
114.17 22.28;
113.54 22.19] %网上搜到的35个城市保留两位小数的位置坐标上面的坐标数据可以直接进行替换
N=size(Coordinate,1); %输出Coordinate坐标矩阵的行数,有35行,也就是矩阵里包含的城市个数
D=zeros(N); %生成35X35的全零数组,目的是为了存储各个城市间的距离数据下面计算各城市之间的距离
%%%%%%%%%%%%%%计算任意两个城市距离,并将其存储到D矩阵当中%%%%%%%%%%%%%%
for i=1:N
for j=1:N
D(i,j)=((Coordinate(i,1)-Coordinate(j,1))^2+(Coordinate(i,2)-Coordinate(j,2))^2)^0.5;
end
end
%D(i,j)=((第一个城市的横坐标-第j个城市的横坐标)^2+(第i个城市的纵坐标-第j个城市的纵坐标)^2)^0.5
step1:这里少部分代码的功能不能直接理解,因为这是初始化-参数预设,一些后面更新的东西都会统一放在前面,所以感觉很无厘头是吧,请慢慢往后看就知道了。。。。。。
Np=200; %设置初始种群数量
G=1500; %设置最大进化代数
f=zeros(Np,N); %生成一个用于储存种群的200*35的全零数组
F=[]; %种群更新中间存储
for i=1:Np
f(i,:)=randperm(N) ;%随机生成初始种群, randperm(N) 返回行向量,其中包含从1到N没有重复元素的整数随机排列
end
R=f(1,:); %将f矩阵的第一行存入R中
len=zeros(Np,1); %储存路径长度
fitvalue=zeros(Np,1); %储存归一化适应度值
gen=0;
step2:本章最重要的部分,以一条循环语句贯穿始终
while gen<G
%%%%%%%%%%%%%%%%%%%%%计算路径长度%%%%%%%%%%%%%%
for i=1:Np
len(i,1)=D(f(i,N),f(i,1));
for j=1:(N-1)
len(i,1)=len(i,1)+D(f(i,j),f(i,j+1));
end
end
lenmax=max(len);
lenmin=min(len); %len=min(A) 是包含每一列的最小值的行向量
%%%%%%%%%%%%%%%更新最短路径%%%%%%%%%%%%%%%%%%%%%%%
rr=find(len==lenmin); %找出len矩阵当中数值等于minlen的元素下标并赋值给rr
R=f(rr(1,1),:);
f=5 23 14 31 11 6 13 3 28 25 2 27 22 19 4 24 21 15 8 29 7 10 20 26 9 17 12 16 30 18 1
在执行step2的%%%%%计算路径长度%%%%%之前,在f=zeros(Np,N)的作用下生成的一组数据,这里把他当成一个在杂乱无章的个体,模拟的实际情况是一种从某个城市遍历所有城市的距离加和,这是混乱的加和,也是一种随意的枚举,这里就是只枚举了Np个随意的路径规划方案。
step3:适应度的计算:非常普通的归一化
%%%%%%%%%%%%%%%%计算归一化适应度值%%%%%%%%%%%%%%%%%
for i =1:length(len)
fitvalue(i,1)=1-(len(i,1)-lenmin)/(lenmax-lenmin+0.001);
end
step4:选择操作
%%%%%%%%%%%%%%%%%%选择操作%%%%%%%%%%
nn=0;
for i=1:Np
if fitvalue(i,1)>=rand
nn=nn+1;
F(nn,:)=f(i,:);
end
end %rand函数返回一个在区间 (0,1) 内均匀分布的随机数。随机数会决定200个体中哪些可以参与进化的并将其存储进F矩阵当中
[aa,bb]=size(F); %返回矩阵的维度mXn,例如,如果A是一个3×4矩阵,则size(A)返回向量[3 4]。
while aa<Np
nnper=randperm(nn); %从1到nn的一个随机排列,nnper就成为了一个行向量
A=F(nnper(1),:); %选中nnper中第一个元素数值在F矩阵中的行数赋给A,A成为了F矩阵当中存储的某个个体
B=F(nnper(2),:); %选中nnper中第二个元素数值在F矩阵中的行数赋给B,B成为了F矩阵当中存储的某个个体
这部分最终的结果就是随机选出了A、B两个随机个体,为下面的交叉操作做好准备
step5:交叉操作
%%%%%%%%%%%%%%%%%%%交叉操作%%%%%%%%%%%%%%
W=ceil(N/10); %ceil函数将X的每个元素四舍五入到大于或等于该元素的最接近整数。这里W=4
p=unidrnd(N-W+1); %unidrnd,产生一组离散均匀随机整数。这里p=unidrnd(32)产生一个随机数
for i =1:W
x=find(A==B(p+i-1)); %find查找的是索引,是A中和B()相同元素的下标,赋给x
y=find(B==A(p+i-1)); %find查找的是索引,是B中和A()相同元素的下标,赋给y
temp=A(p+i-1);
A(p+i-1)=B(p+i-1);
B(p+i-1)=temp;
temp=A(x);
A(x)=B(y);
B(y)=temp;
end进行了2次三步交换,就是将A()和B()两个进行交换,交换第一次后会出现重复,所以再进行一次交换,最终实现不重复。但这种交换不是等位基因的交换,比较草率
step6:变异操作
%%%%%%%%%%%%%%%%%%%%%变异操作%%%%%%%%%%%%%%%%%%%%
p1=floor(1+N*rand()); %floor(X)将X的每个元素四舍五入到小于或等于该元素的最接近整数
p2=floor(1+N*rand());
while p1==p2
p1=floor(1+N*rand());
p2=floor(1+N*rand());
end
tmp=A(p1);
A(p1)=A(p2);
A(p2)=tmp;
tmp=B(p1);
B(p1)=B(p2);
B(p2)=tmp;
F=[F;A;B];
[aa,bb]=size(F);
end %因为淘汰,所以F的行数小于200个,所以将变异后A、B加入进去,组成新种群,只要F的行数小于Np,就循环进化过程,直到种群数满足200,此一代的选择、交叉、变异等遗传进化操作暂停
if aa>Np
F=F(1:Np,:);
end
f=F; %将新种群200个个体赋给矩阵f,f是种群矩阵
f(1,:)=R; %之前的R是最优个体,这里把种群矩阵f中的第一个个体换成最优个体
clear F;
gen=gen+1;
Rlength(gen)=lenmin; %记录每代的最优个体,就是每一波200个路径规划方案的中的最优方案
endstep7:绘图等后续操作
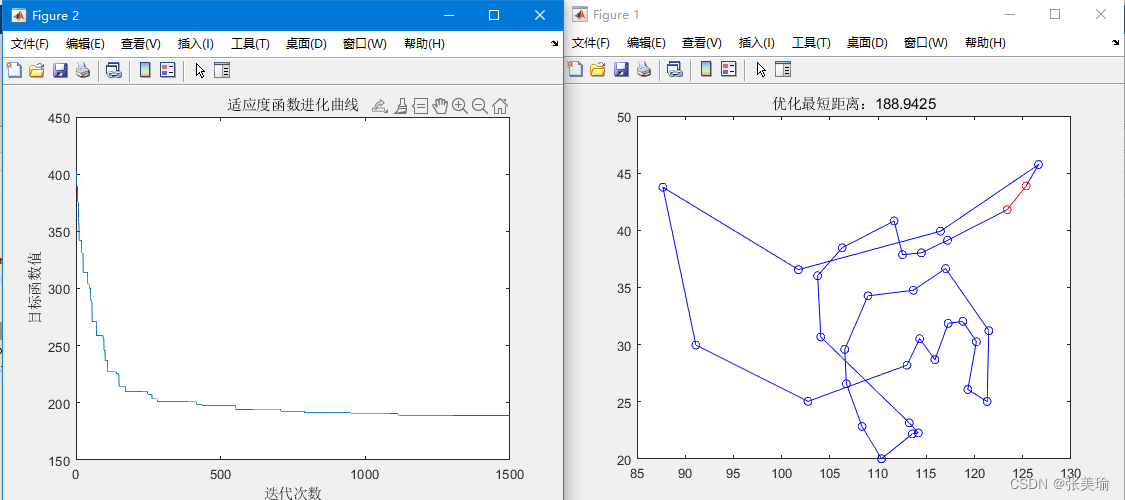
figure %%%%这里画出各城市坐标和路径规划线路图
for i=1:N-1
plot([Coordinate(R(i),1),Coordinate(R(i+1),1)],[Coordinate(R(i),2),Coordinate(R(i+1),2)],'bo-'); %依次连接最优方案中的线路各点,用蓝色线连接
hold on; %hold-添加新绘图时保留当前绘图
end
plot([Coordinate(R(N),1),Coordinate(R(1),1)],[Coordinate(R(N),2),Coordinate(R(1),2)],'ro-'); %收尾点连接,用红色线
title(['优化最短距离:',num2str(lenmin)]); %num2str将数字转换为字符数组,为了标题输出
figure %%%%%这里画迭代次数,即进化过程图
plot(Rlength)
xlabel('迭代次数')
ylabel('目标函数值')
title('适应度函数进化曲线')
%%tips:这里bo-,ro-的-是连线功能Result!!!!!!!
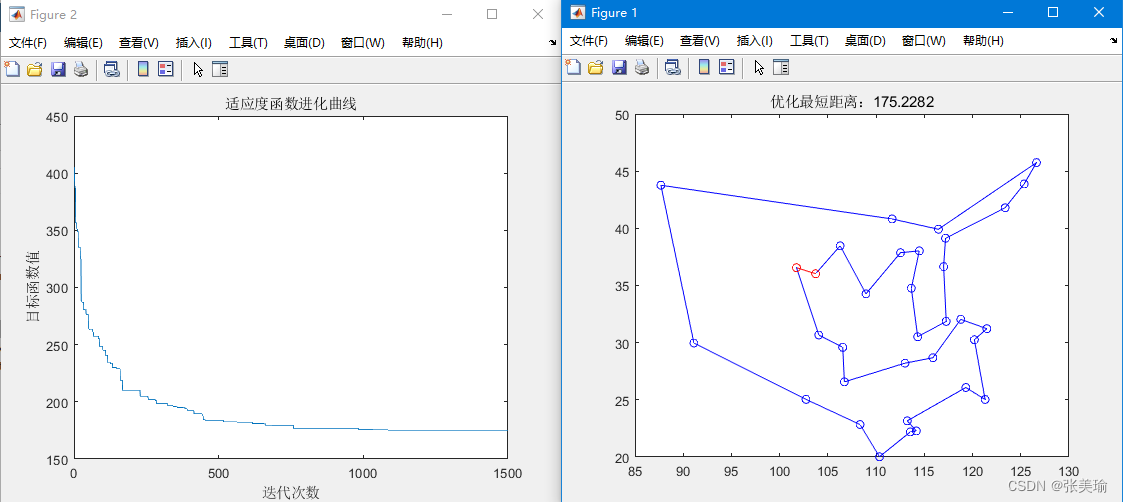 175.228这个可能是目前最好的结果,完美的一圈TSP。
175.228这个可能是目前最好的结果,完美的一圈TSP。
值得注意的是,此GA非常基础、常规,没有在任何重要算子和步骤上进行优化,虽然看不出来。同时,GA在大规模求解TSP\VRP问题上鲁棒优化是重要方向,相信多RUN几次就能感觉到,太抖了哈哈哈哈哈
最后发个全文,方便CV~·~~~~~~~~~
Coordinate=[103.73 36.03;
103.73 36.03;
101.74 36.56;
104.06 30.67;
114.48 38.03;
102.73 25.04;
106.71 26.57;
114.31 30.52;
113.65 34.76;
117.00 36.65;
118.78 32.04;
117.27 31.86;
120.19 30.26;
115.89 28.68;
119.30 26.08;
113.23 23.16;
113.00 28.21;
110.35 20.02;
123.38 41.80;
125.35 43.88;
126.63 45.75;
112.53 37.87;
108.95 34.27;
121.30 25.03;
116.46 39.92;
121.48 31.22;
106.54 29.59;
117.20 39.13;
111.65 40.82;
108.33 22.84;
91.11 29.97;
106.27 38.47;
87.68 43.77;
114.17 22.28;
113.54 22.19] %网上搜到的35个城市保留两位小数的位置坐标
N=size(Coordinate,1); %输出Coordinate坐标矩阵的行数,有35行,也就是矩阵里包含的城市个数
D=zeros(N); %生成35X35的全零数组,目的是为了存储各个城市间的距离数据
%%%%%%%%%%%%%%计算任意两个城市距离,并将其存储到D矩阵当中%%%%%%%%%%%%%%
for i=1:N
for j=1:N
D(i,j)=((Coordinate(i,1)-Coordinate(j,1))^2+(Coordinate(i,2)-Coordinate(j,2))^2)^0.5;
end
end
%D(i,j)=((第一个城市的横坐标-第j个城市的横坐标)^2+(第i个城市的纵坐标-第j个城市的纵坐标)^2)^0.5
Np=200; %设置初始种群数量
G=1500; %设置最大进化代数
f=zeros(Np,N); %生成一个用于储存种群的200*35的全零数组
F=[]; %种群更新中间存储
for i=1:Np
f(i,:)=randperm(N) ;%随机生成初始种群, randperm(N) 返回行向量,其中包含从1到N没有重复元素的整数随机排列
end
R=f(1,:); %将f矩阵的第一行存入R中
len=zeros(Np,1); %储存路径长度
fitvalue=zeros(Np,1); %储存归一化适应度值
gen=0;
while gen<G
%%%%%%%%%%%%%%%%%%%%%计算路径长度%%%%%%%%%%%%%%
for i=1:Np
len(i,1)=D(f(i,N),f(i,1));
for j=1:(N-1)
len(i,1)=len(i,1)+D(f(i,j),f(i,j+1));
end
end
lenmax=max(len);
lenmin=min(len); %len=min(A) 是包含每一列的最小值的行向量
%%%%%%%%%%%%%%%更新最短路径%%%%%%%%%%%%%%%%%%%%%%%
rr=find(len==lenmin); %找出len矩阵当中数值等于minlen的元素下标并赋值给rr
R=f(rr(1,1),:);
%%%%%%%%%%%%%%%%计算归一化适应度值%%%%%%%%%%%%%%%%%
for i =1:length(len)
fitvalue(i,1)=1-(len(i,1)-lenmin)/(lenmax-lenmin+0.001);
end
%%%%%%%%%%%%%%%%%%选择操作%%%%%%%%%%
nn=0;
for i=1:Np
if fitvalue(i,1)>=rand
nn=nn+1;
F(nn,:)=f(i,:);
end
end %rand函数返回一个在区间 (0,1) 内均匀分布的随机数。随机数会决定200个体中哪些可以参与进化的并将其存储进F矩阵当中
[aa,bb]=size(F); %返回矩阵的维度mXn,例如,如果A是一个3×4矩阵,则size(A)返回向量[3 4]。
while aa<Np
nnper=randperm(nn); %从1到nn的一个随机排列,nnper就成为了一个行向量
A=F(nnper(1),:); %选中nnper中第一个元素数值在F矩阵中的行数赋给A,A成为了F矩阵当中存储的某个个体
B=F(nnper(2),:); %选中nnper中第二个元素数值在F矩阵中的行数赋给B,B成为了F矩阵当中存储的某个个体
%%%%%%%%%%%%%%%%%%%交叉操作%%%%%%%%%%%%%%
W=ceil(N/10); %ceil函数将X的每个元素四舍五入到大于或等于该元素的最接近整数。这里W=4
p=unidrnd(N-W+1); %unidrnd,产生一组离散均匀随机整数。这里p=unidrnd(32)产生一个随机数
for i =1:W
x=find(A==B(p+i-1)); %find查找的是索引,是A中和B()相同元素的下标,赋给x
y=find(B==A(p+i-1)); %find查找的是索引,是B中和A()相同元素的下标,赋给y
temp=A(p+i-1);
A(p+i-1)=B(p+i-1);
B(p+i-1)=temp;
temp=A(x);
A(x)=B(y);
B(y)=temp;
end
%%%%%%%%%%%%%%%%%%%%%变异操作%%%%%%%%%%%%%%%%%%%%
p1=floor(1+N*rand()); %floor(X)将X的每个元素四舍五入到小于或等于该元素的最接近整数
p2=floor(1+N*rand());
while p1==p2
p1=floor(1+N*rand());
p2=floor(1+N*rand());
end
tmp=A(p1);
A(p1)=A(p2);
A(p2)=tmp;
tmp=B(p1);
B(p1)=B(p2);
B(p2)=tmp;
F=[F;A;B];
[aa,bb]=size(F);
end %因为淘汰,所以F的行数小于200个,所以将变异后A、B加入进去,组成新种群,只要F的行数小于Np,就循环进化过程,直到种群数满足200,此一代的选择、交叉、变异等遗传进化操作暂停
if aa>Np
F=F(1:Np,:);
end
f=F; %将新种群200个个体赋给矩阵f,f是种群矩阵
f(1,:)=R; %之前的R是最优个体,这里把种群矩阵f中的第一个个体换成最优个体
clear F;
gen=gen+1;
Rlength(gen)=lenmin; %记录每代的最优个体,就是每一波200个路径规划方案的中的最优方案
end
figure %%%%这里画出各城市坐标和路径规划线路图
for i=1:N-1
plot([Coordinate(R(i),1),Coordinate(R(i+1),1)],[Coordinate(R(i),2),Coordinate(R(i+1),2)],'bo-'); %依次连接最优方案中的线路各点,用蓝色线连接
hold on; %hold-添加新绘图时保留当前绘图
end
plot([Coordinate(R(N),1),Coordinate(R(1),1)],[Coordinate(R(N),2),Coordinate(R(1),2)],'ro-'); %收尾点连接,用红色线
title(['优化最短距离:',num2str(lenmin)]); %num2str将数字转换为字符数组,为了标题输出
figure %%%%%这里画迭代次数,即进化过程图
plot(Rlength)
xlabel('迭代次数')
ylabel('目标函数值')
title('适应度函数进化曲线')
%%tips:这里bo-,ro-的-是连线功能















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









