






写在前面:解决的问题是分类问题。
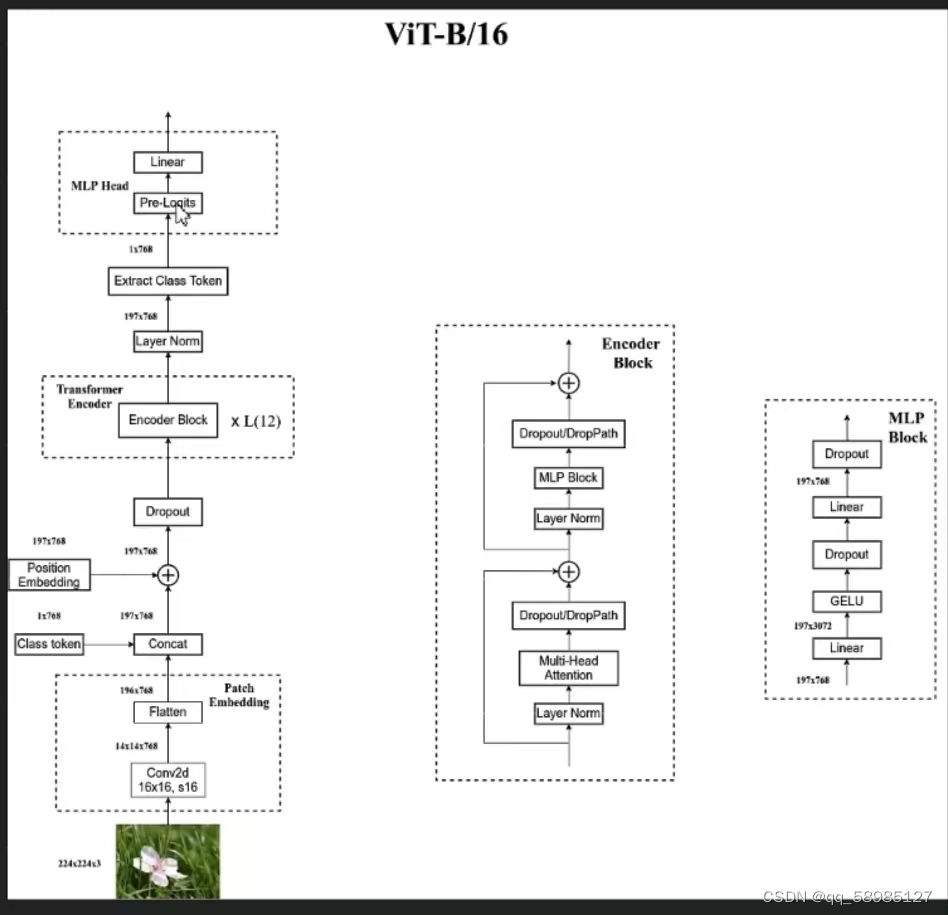
下图模型架构图参考:B站博主霹雳吧啦
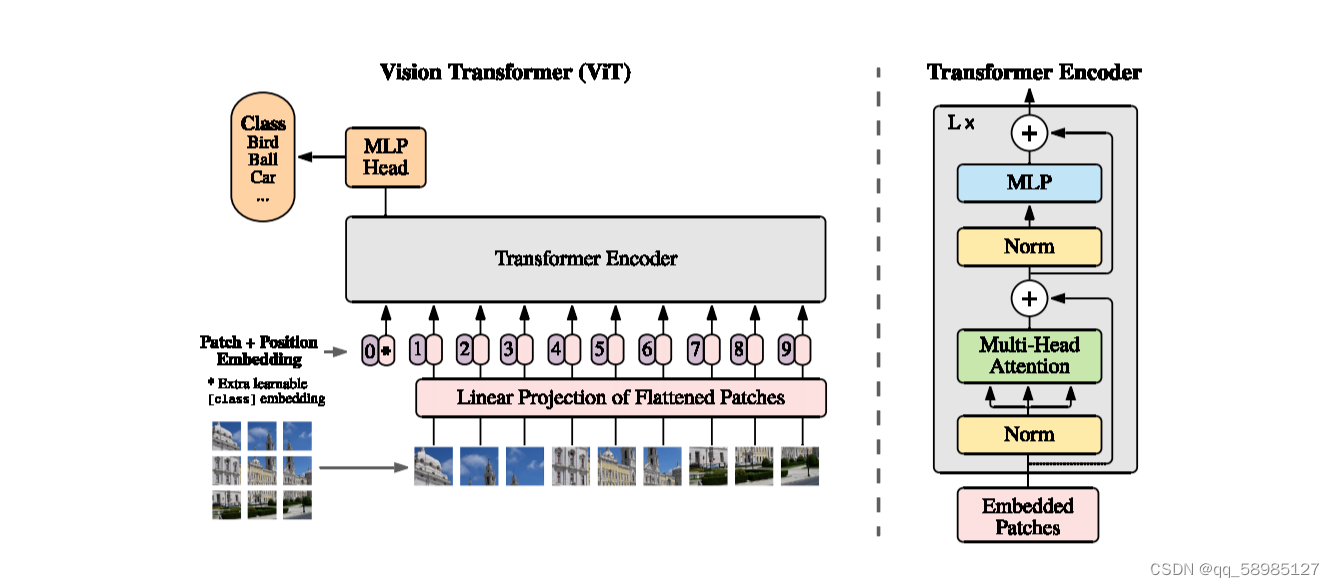
下图来自原论文:
目录
二、VisionTransformer函数中的前向传播函数(包含了模型的全部过程):
2.1.2、cls_token.expand(x.shape[0], -1, -1)介绍:
2.1.3、x = torch.cat((cls_token, x), dim=1)
2.1.4、 x = self.pos_drop(x + self.pos_embed)
2.1.5、x = self.blocks(x)是Transformer中Encoder的Block模块
一、首先从模型创建步骤看起:
from vit_model import vit_base_patch16_224_in21k as create_model
model = create_model(num_classes=args.num_classes, has_logits=False).to(device)def vit_base_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True):
"""
ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.
weights ported from official Google JAX impl:
https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch16_224_in21k-e5005f0a.pth
"""
model = VisionTransformer(img_size=224,
patch_size=16,
embed_dim=768,
depth=12,
num_heads=12,
representation_size=768 if has_logits else None,
num_classes=num_classes)
return model上述是使用的模型参数的创建,从这个函数名称可以看出对应的图片大小输入是224*224的大小,通道数是3(R,G,B),转换到Transform模型中的是14*14*768,也就是第一章图最下面的几个部分过程,具体下述代码会进行介绍。这个函数调用了VisionTransformer函数,接下来看这个类中的前向传播函数。
二、VisionTransformer函数中的前向传播函数(包含了模型的全部过程):
2.1、特征的前向传播函数:
这个是特征的前向传播函数。也就是输入到Transform模型中的前处理函数。是图中Dropout及一下的部分。
def forward_features(self, x):
# [B, C, H, W] -> [B, num_patches, embed_dim]
x = self.patch_embed(x) # [B, 196, 768]
# [1, 1, 768] -> [B, 1, 768]
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
if self.dist_token is None:#是为了适配其他模型,只看if条件中的东西就行了
x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]
else:
x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)
x = self.pos_drop(x + self.pos_embed)
x = self.blocks(x)
x = self.norm(x)
if self.dist_token is None:#这个是另一个网络,不用管
return self.pre_logits(x[:, 0])
else:
return x[:, 0], x[:, 1]#取出所有样本的第一个和第二个特征。也就是取出x中的196和768
2.1.1、patch_embed(x)函数:
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# flatten: [B, C, H, W] -> [B, C, HW]#没有实质性的作用
# transpose: [B, C, HW] -> [B, HW, C]
x = self.proj(x).flatten(2).transpose(1, 2)#proj是经过了一次卷积,把原来输入的224*224的图片转换成了14*14
x = self.norm(x)
return xself.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)这个函数是通过一个卷积,把原来输入的224*224大小的图片,经过kernel=16*16,stride=16,channel=768的卷积核进行卷积后,会得到一个14*14*768大小的特征图,因为卷积核大小是16*16,且步长为16,就可以把他看成是对整个图片进行了16等分的切分。然后通过flatten(2)原来的[16,768,14,14]转变为[16,768,196],然后经过transpose(1,2)交换第1维和第2维的数据(维数从0开始),变成[16,196,768]。总的来说,就是对数据转换为适合Transformer输入的tensor格式。
2.1.2、cls_token.expand(x.shape[0], -1, -1)介绍:
x.shape的形状是:B,196,768。其中x.shape[0]就是B(也就是自己设置的batch_size参数,准许一次放入CPU进行处理的batch个数。注意和patch_size进行区分)。这个cls_token.expand()的意思就是创建一个和x形状大小一样的tensor,将 cls_token 进行扩展,使其在第一个维度上的大小与 x 的第0维相匹配,而在其它维度上的大小保持不变。cls_token也就[1,1,768](这个是初始化后的结果,在这里没展示初始化部分)变成了[6,1,768](这里的6是batch_size,也就是前面说的一次放在CPU中的batch数)
2.1.3、x = torch.cat((cls_token, x), dim=1)
在维度1上,也就是在196所对应的维度上进行拼接,也就是在第一个维度上进行相加(维度从0开始计数),也就是196+1=197。
2.1.4、 x = self.pos_drop(x + self.pos_embed)
这个包含了两个过程:①x+self.pos_embed是位置嵌入过程,也就是把位置信息与输入张量x进行相加;②pos_drop()是随机丢弃一些数据的过程,也就是一定概率下把数据置为0的过程。是为了防止过拟合,提高模型的泛化能力。
2.1.5、x = self.blocks(x)是Transformer中Encoder的Block模块
也就是第一张图的中间部分。
这个语句调用的是Block这个类,这个类的前向传播函数是:
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x也就是执行了第一章图中间部分的几个过程:norm过程、多头自注意力过程、DropPath过程、残差连接过程等。
2.2、全过程的forward过程:
def forward(self, x):
x = self.forward_features(x)
if self.head_dist is not None:#不用管
x, x_dist = self.head(x[0]), self.head_dist(x[1])
if self.training and not torch.jit.is_scripting():
# during inference, return the average of both classifier predictions
return x, x_dist
else:
return (x + x_dist) / 2
else:
x = self.head(x)#全连接,得到分类结果。
return x2.2.1、x = self.forward_features(x)
这个是调用了2.1这个特征的正向传播过程。在图一中展示的是Layer Norm及以下的部分。
2.2.2、x=self.head(x)
这个调用执行的是
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
也就是一个单纯的全连接,用于输出类别数。
另外:补充Pre_Logits作用(个人理解): 可以视为一个要进入全连接层中的一个预处理过程,其目的是将模型输出的特征向量进行适当的变换,因为全连接层神经元个数是固定的,所以也就是把上层的输出个数转换为与全连接层的神经元个数相同的数据输出。
三、损失函数:
for step, data in enumerate(data_loader):
images, labels = data
sample_num += images.shape[0]
pred = model(images.to(device))
pred_classes = torch.max(pred, dim=1)[1]
accu_num += torch.eq(pred_classes, labels.to(device)).sum()
loss = loss_function(pred, labels.to(device))
loss.backward()
accu_loss += loss.detach()
其中
loss_function = torch.nn.CrossEntropyLoss()
使用的是交叉熵损失函数。把预测标签和实际标签传入交叉熵损失函数中计算损失。

















 2217
2217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









