






一、标注数据(labelimg标注工具)
利用labelimg标注工具标注图片真实框,获得xml(voc)格式文件。标签名包括'ball'、'racket'、'hand'。如下图所示: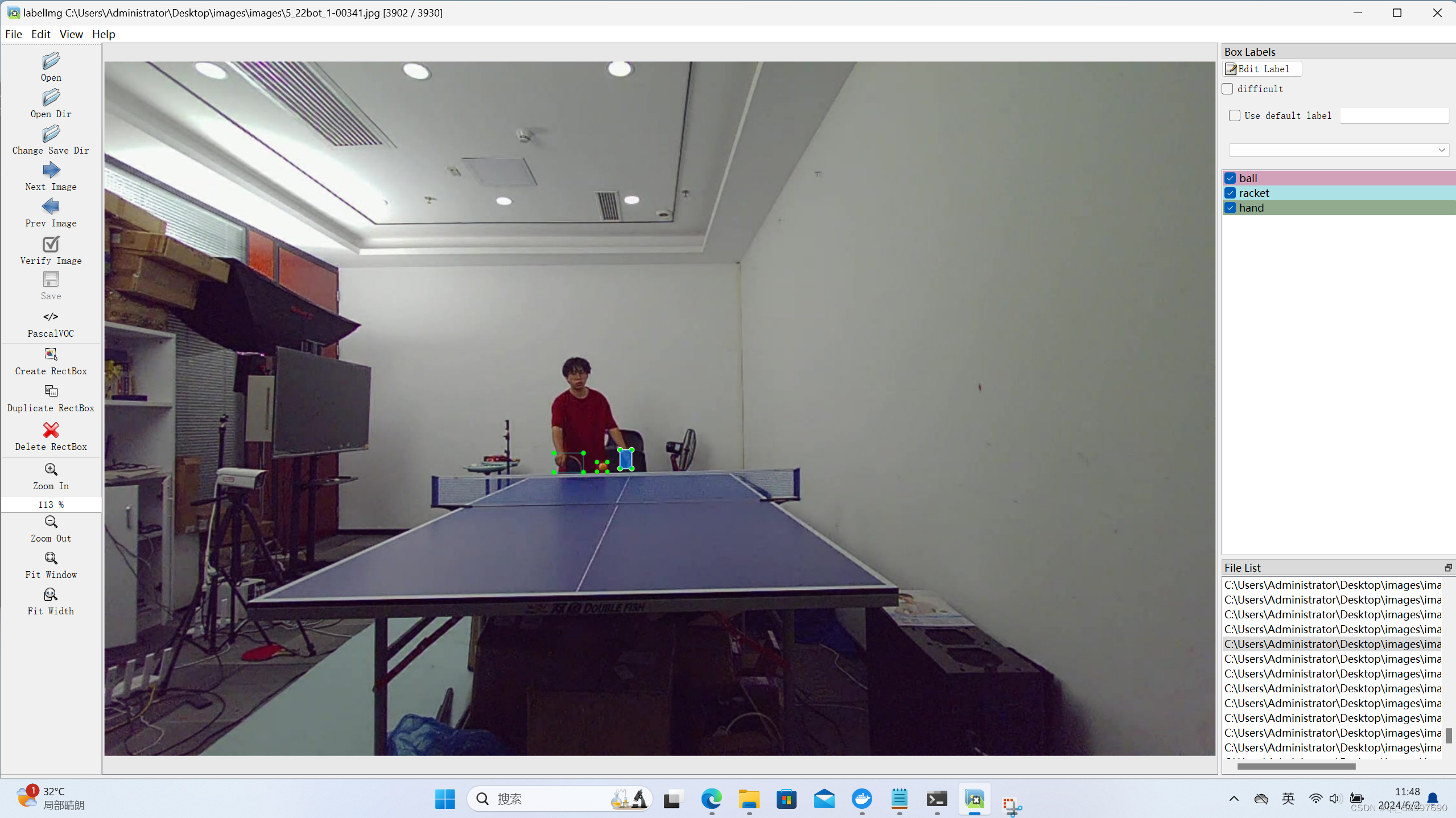
二、安装开发环境(docker、Linux、Python、Opencv)
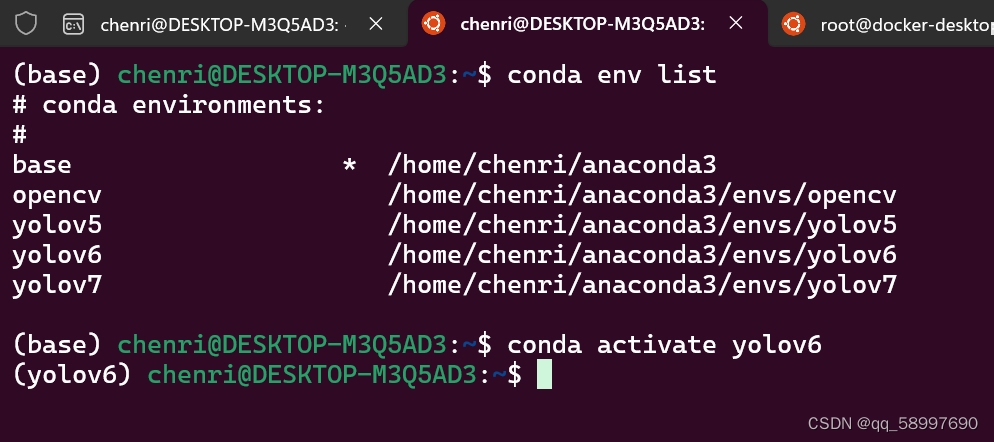
创建虚拟环境:conda create -n yolov6 python=3.8
查看虚拟环境:conda env list
激活虚拟环境:conda activate yolov6
如图所示:
三、下载yolov6源码
1、创建开发的目录,例如:/mnt/d/train/yolov6/YOLOv6
2、拉取源码:git clone https://gitee.com/qq1360011612/YOLOv6.git
四、安装第三方库
安装命令:pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
安装torch-gpu命令:pip3 install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html
参考官方链接:Previous PyTorch Versions | PyTorch![]() https://pytorch.org/get-started/previous-versions/
https://pytorch.org/get-started/previous-versions/
五、标签xml(voc)格式转为txt(yolov)格式并划分数据集
xml文件如图所示:
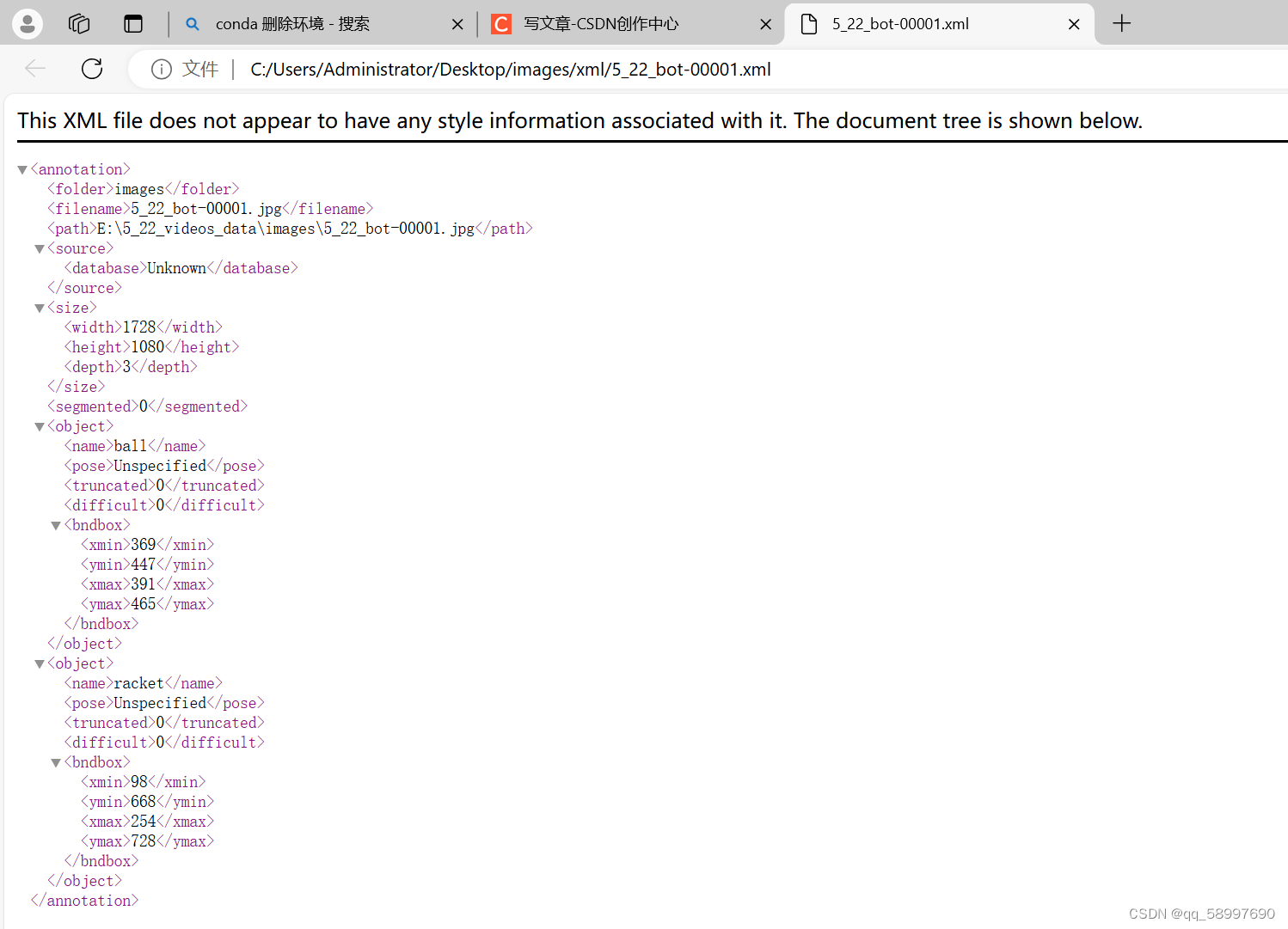
txt文件如图所示:
划分后的数据集如图所示: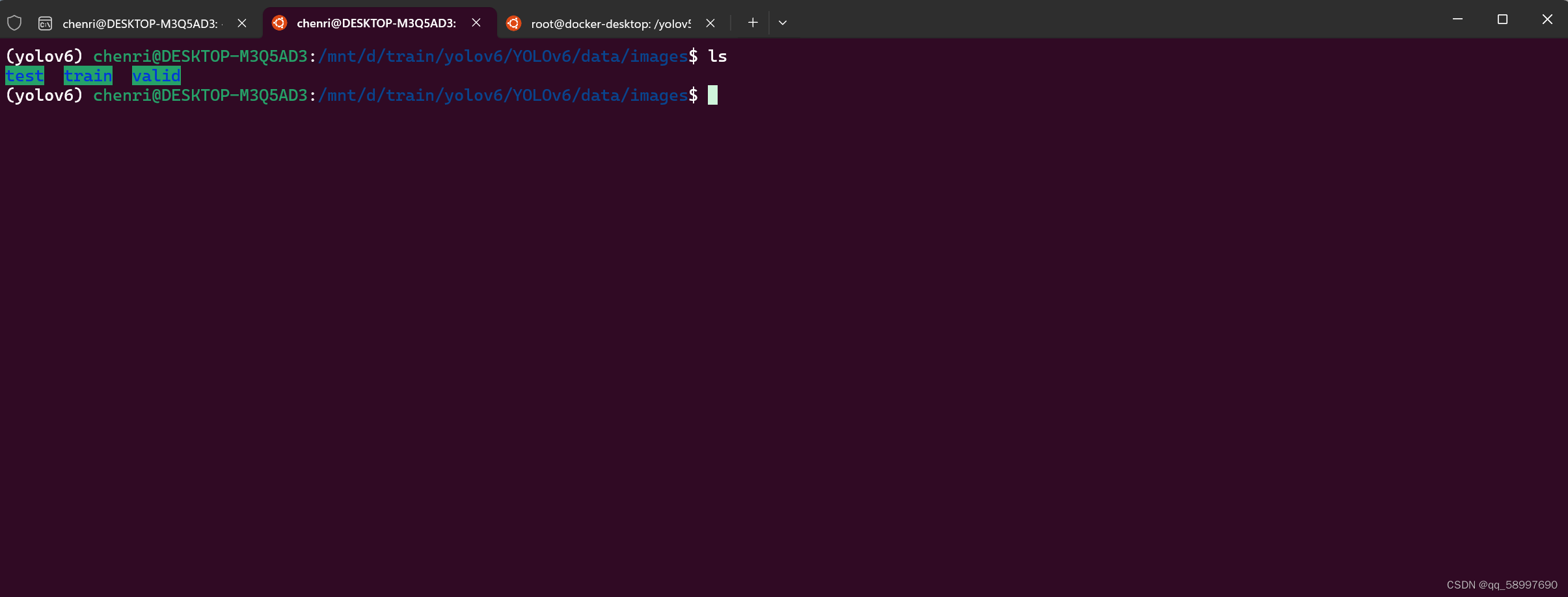
以上操作就完成了数据集和开发环境的准备
六、下载预权重
这里以yolov6n.pt为例,下载链接:https://github.com/meituan/YOLOv6/releases/download/0.3.0/yolov6n.pt![]() https://github.com/meituan/YOLOv6/releases/download/0.3.0/yolov6n.pt如下图所示:
https://github.com/meituan/YOLOv6/releases/download/0.3.0/yolov6n.pt如下图所示:

七、数据集和模型配置文件
数据集配置文件如图所示: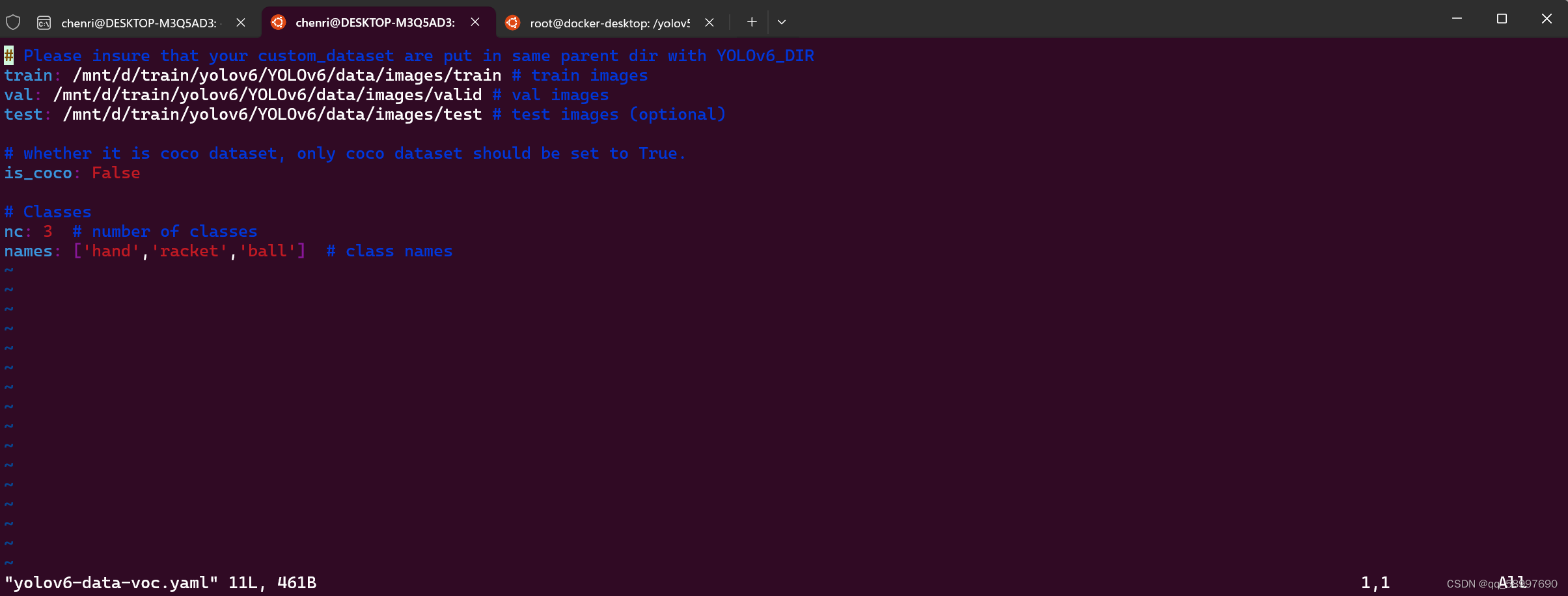
模型配置文件:yolov6n.yaml
以上就完成了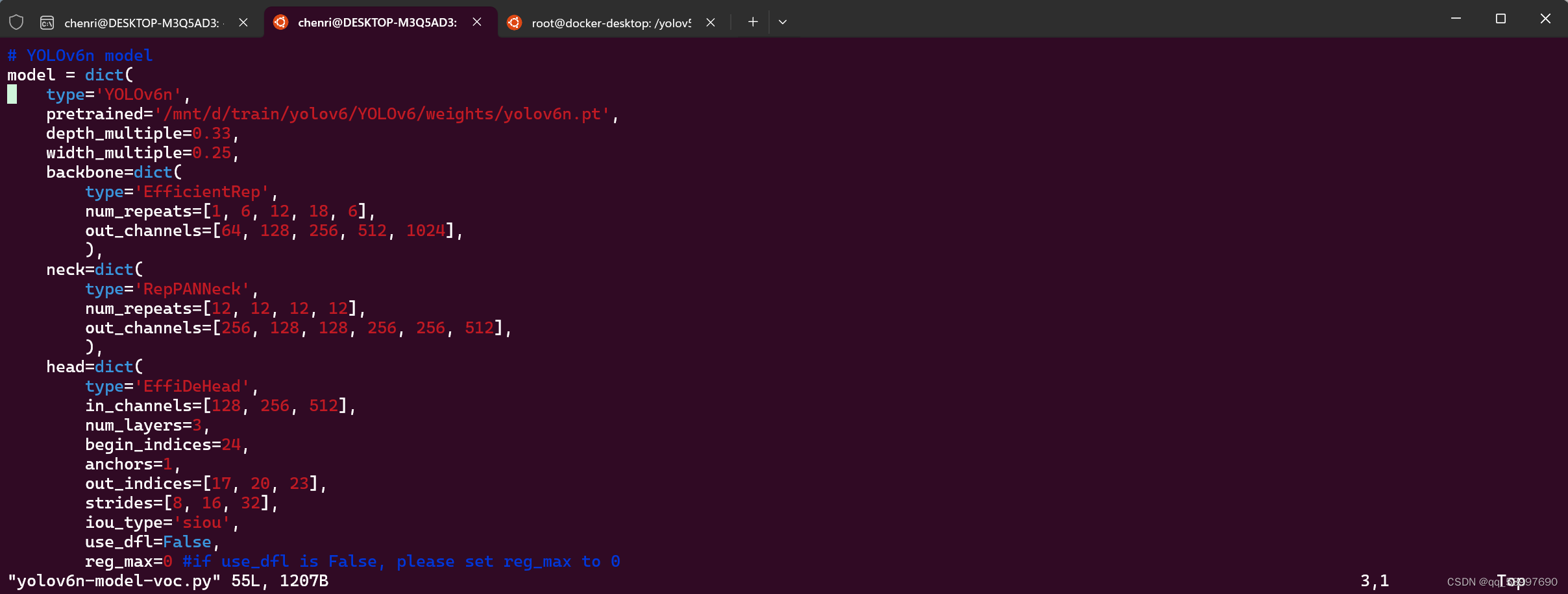
备注:修改预测权重位置
以上就完成所有前期的准备工作
八、编辑训练脚本:vim train.py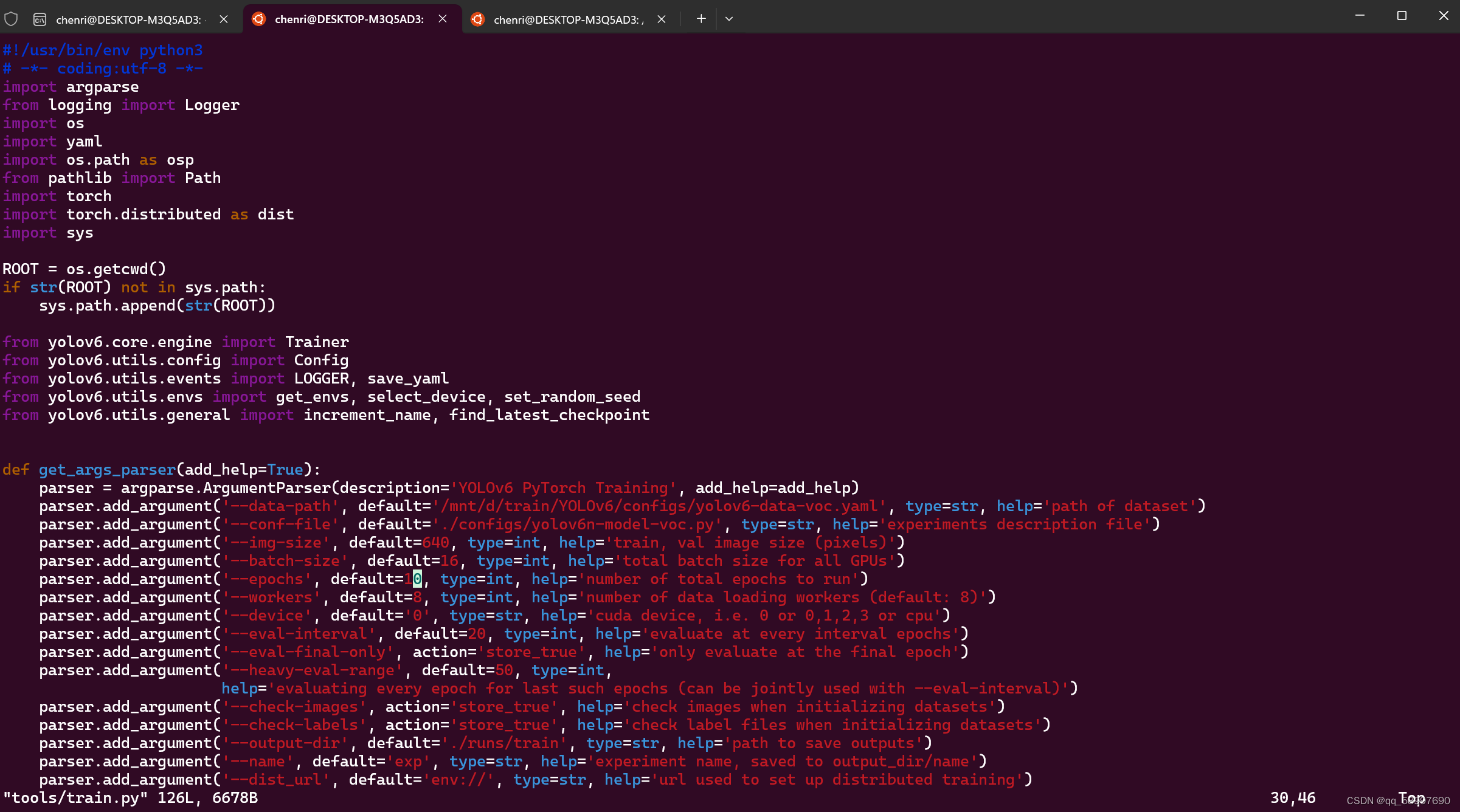
备注:--weights:预权重目录
--cfg:模型配置文件
--data:数据集配置文件
--epoch:迭代次数
--batch-size:批量大小(主要与内存有关,一般取32、64、96)
--device:gpu数据量(一般默认选择0,即单gpu训练)
设置完成以上参数就可以开始训练了,训练完成如下图所示: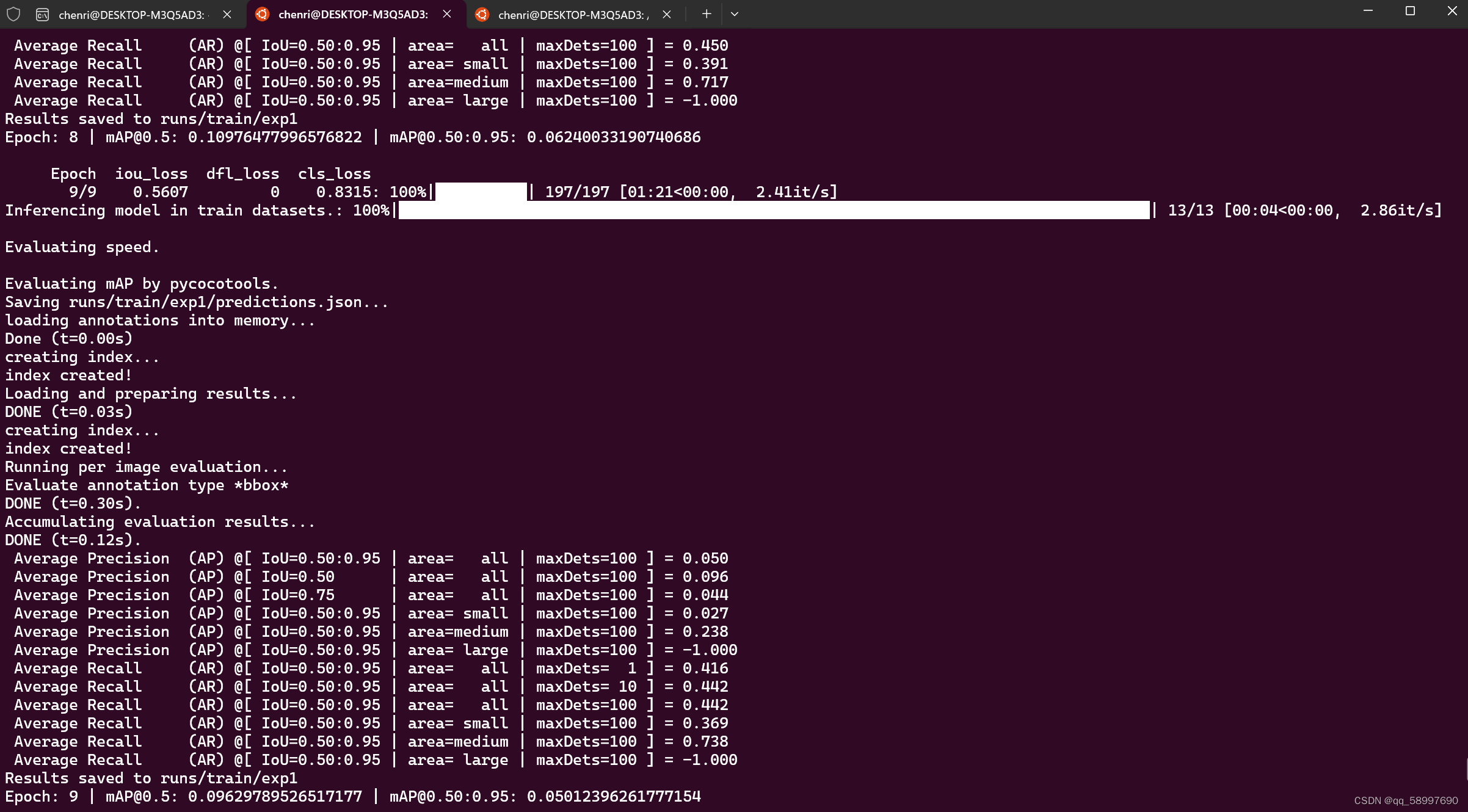
九、预测图片和视频检验效果:vim detect.py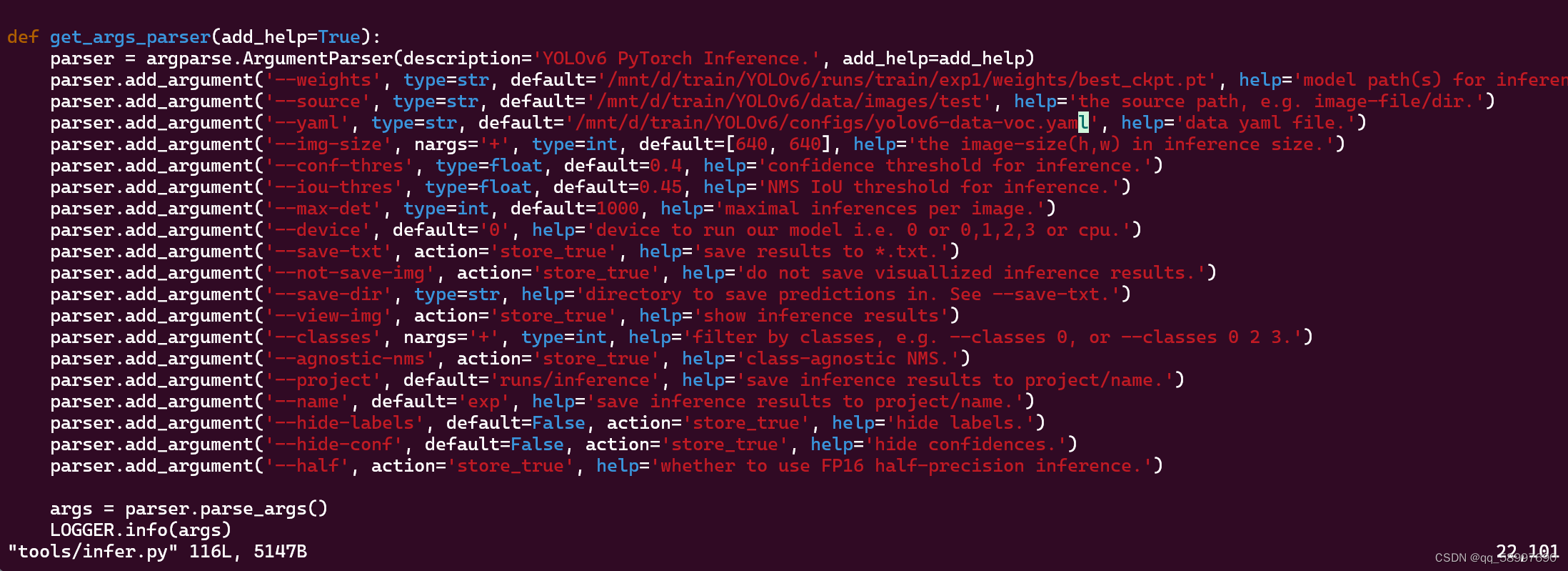
备注:--weight:修改为训练出来的权重文件
--source:需要预测的图片、数据集、视频、实时视频
--data:数据集配置文件
--conf-thres:置信度阙值;--iou-thres:iou阙值
数据集预测结果如图所示: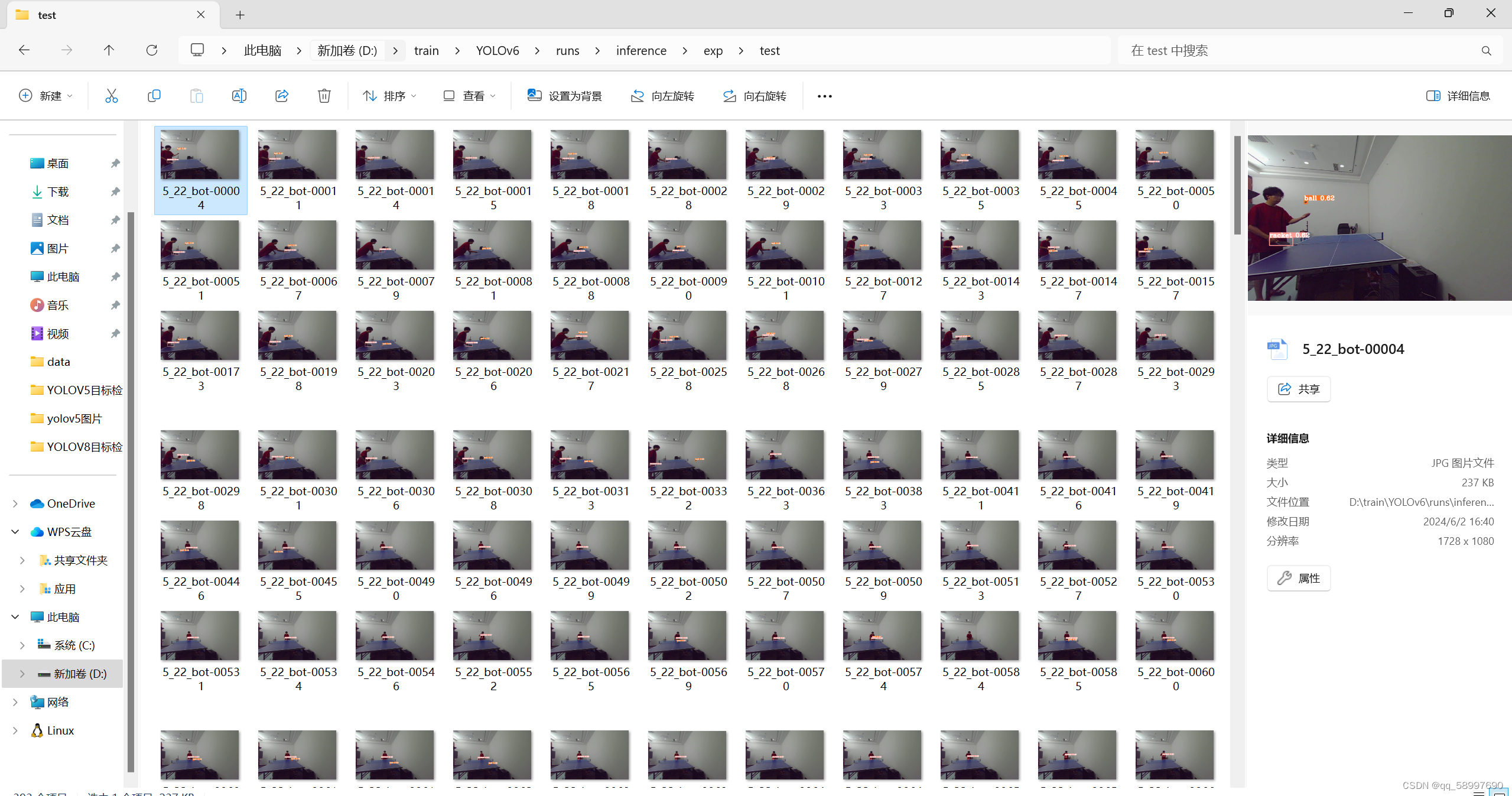
下一步计划是采用opencv部署模型。















 630
630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









