







论文:https://arxiv.org/pdf/2405.16546v1
代码:https://github.com/KID-22/Cocktail
人大高瓴联合华为诺亚和中科院计算所提出了一个全新的信息检索(IR)基准测试——Cocktail,它特别针对大型语言模型(LLM)生成的内容(AIGC)对IR系统的影响进行了评估。
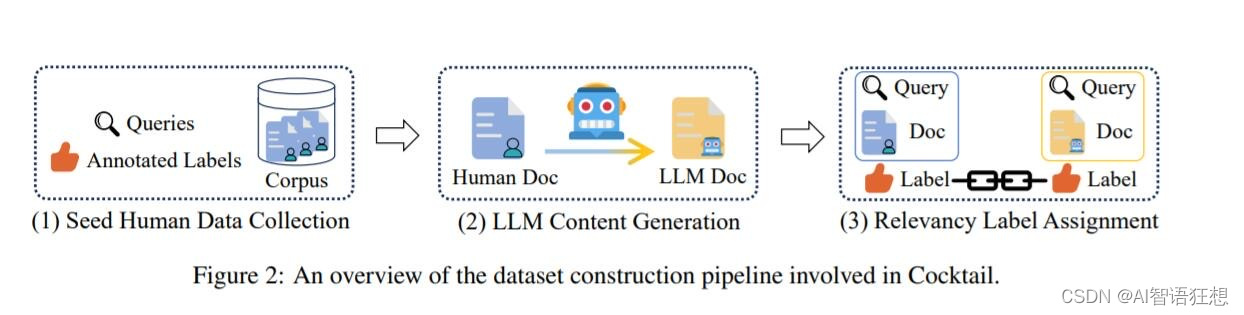
1. 研究背景与动机
-
LLM的兴起:随着大型语言模型的发展,AI生成内容在互联网上日益增多,这对传统的以人类编写内容为主的IR系统构成了挑战。
-
现有基准的局限性:现有的IR基准测试未能充分反映LLM时代的特点,即缺乏对人类编写和LLM生成内容混合的评估。
2. Cocktail基准测试
-
数据集多样性:Cocktail包含16个不同的数据集,覆盖多个领域和任务,既有领域内(in-domain)也有领域外(out-of-domain)的评估设置。
-
混合数据源:数据集结合了人类编写和LLM生成的文本,以模拟现实世界中IR系统可能遇到的混合数据环境。
-
NQUTD数据集:特别引入了一个新的数据集,包含最近事件的查询,以评估IR系统对最新信息的处理能力。
3. 实验设计与评估
-
模型评估:对超过十个最先进的检索模型进行了评估,包括基于Transformer的神经检索模型和基于BM25的词汇检索模型。
-
评估指标:主要使用归一化折扣累积增益(NDCG@K)作为主要的评估指标,同时考虑了源偏差(source bias)。
4. 主要发现
-
源偏差问题:研究发现神经检索模型普遍存在对LLM生成内容的偏好,这种偏差在不同数据集和任务中普遍存在。
-
性能与偏差的权衡:在追求高排名性能的同时,模型可能会不自觉地增加对LLM生成内容的偏好,这表明在设计新一代IR模型时需要在性能提升和偏差减轻之间找到平衡。
5. 贡献与资源
-
Cocktail基准:作为首个综合基准,为LLM时代的IR研究提供了基础资源。
-
开源工具:提供了开源的评估工具和代码,便于其他研究者评估新模型和数据集。
-
实证研究:通过广泛的实验揭示了神经检索模型在性能和偏差之间的权衡。
6. 未来工作与限制
-
基准的扩展性:随着IR领域的不断发展,Cocktail基准也需要不断更新,包括更多领域的数据集。
-
数据集规模:NQUTD数据集的规模有限,未来的工作可以扩大这一数据集,以支持更广泛的评估。
-
模型多样性:目前基准中的LLM生成内容主要由Llama2生成,未来的研究可以考虑使用多种LLMs生成的内容。
本文首发于公众号:AI智语狂想,欢迎关注。

















 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











