







论文:https://arxiv.org/pdf/2406.13121
领域:长上下文模型测试基准
代码:GitHub - google-deepmind/loft: LOFT: A 1 Million+ Token Long-Context Benchmark
机构:Google DeepMind
发表/arxiv:arxiv 2024
论文的主要内容是探讨了长上下文语言模型(LCLMs)在处理传统任务上的潜力,这些任务通常需要依赖外部工具如检索系统或数据库。研究者们提出了一个新的基准测试LOFT(Long-Context Frontiers),它包含六种任务和35个数据集,覆盖了文本、视觉和音频模态,用以评估LCLMs在处理长达数百万token的上下文时的性能。研究发现,尽管LCLMs没有经过特定的检索任务训练,它们在某些任务上的表现却能与最先进系统相媲美。然而,LCLMs在需要组合推理的SQL类任务上仍存在挑战。此外,研究强调了提示策略在提升LCLMs性能中的重要性,并指出随着模型能力的提升,对于长上下文推理的进一步研究是必要的。论文的结论是,LCLMs有潜力改变现有的任务处理范式,并处理新任务,但同时也需要克服在复杂推理方面的局限性。
摘要(Abstract)
- LCLMs 潜力:长上下文语言模型有潜力通过原生处理整个信息语料库来革新我们处理任务的方式。
- 优势:使用 LCLMs 可以提高用户友好性,减少对专业工具知识的需要,提供健壮的端到端建模,减少复杂流程中的级联错误,并允许在整个系统中应用高级提示技术。
- LOFT 基准:引入了 LOFT(Long-Context Frontiers),一个针对需要长达数百万token上下文的现实世界任务的基准,用于评估 LCLMs 在上下文检索和推理方面的性能。
- 研究发现:尽管 LCLMs 从未明确训练过检索和 RAG(Retrieval-Augmented Generation)任务,但它们表现出与最先进系统相媲美的能力。然而,LCLMs 在 SQL 类任务所需的组合推理方面仍面临挑战。
- 提示策略:提示策略对性能有显著影响,强调了随着上下文长度增长,持续研究的必要性。
引言(Introduction)
- LCLMs 变革:LCLMs 通过整合复杂流程到统一模型中,改善了级联错误和繁琐优化问题,提供了一种简化的端到端模型开发方法。
LCLMs vs Special Model
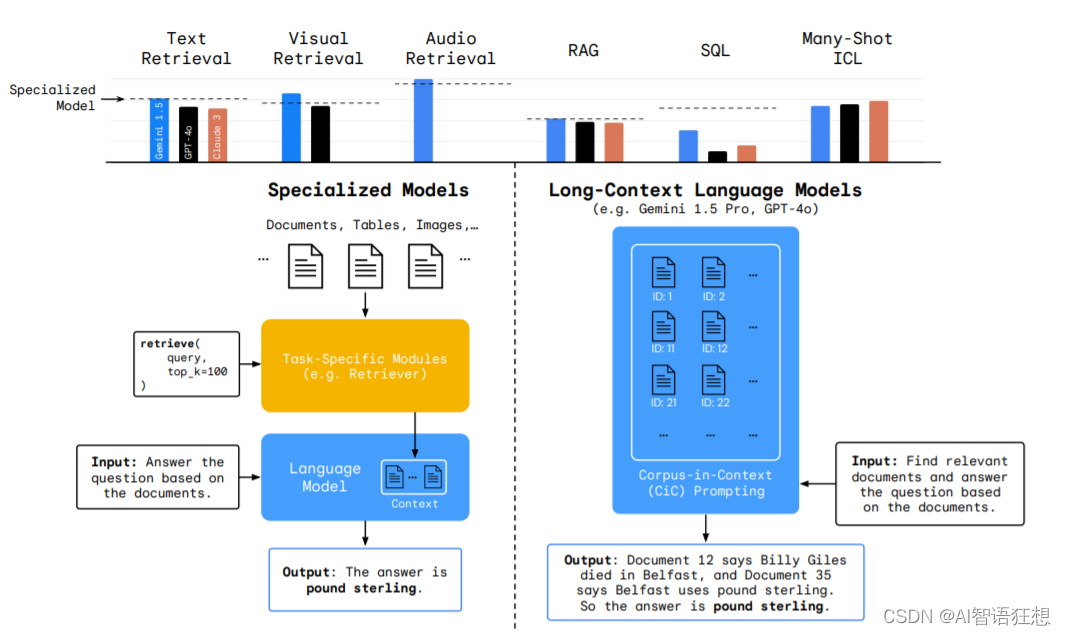
- 现有基准限制:现有的基准测试不足以充分测试 LCLMs 在范式转换任务上的性能。
LOFT 基准(LOFT: A 1 Million+ Token Long-Context Benchmark)
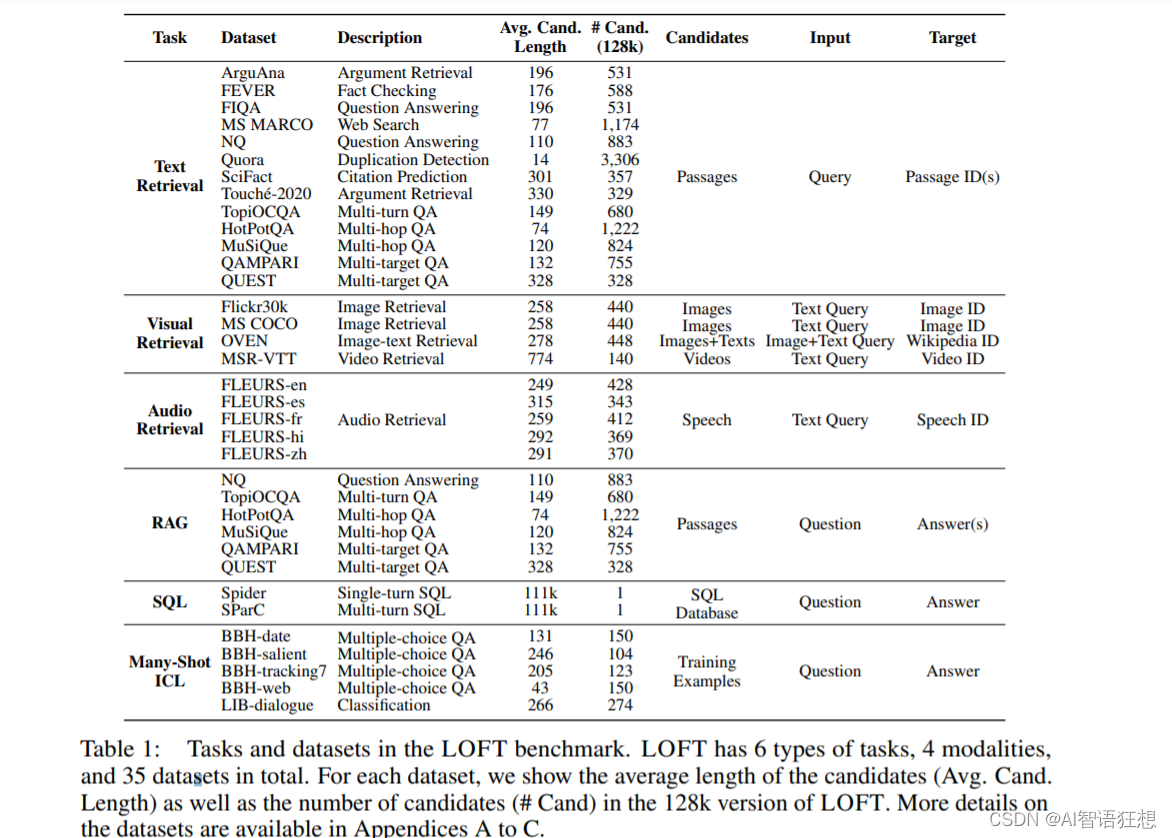
- 任务和数据集:LOFT 包括六种任务,涵盖文本、视觉和音频模态,包含 35 个数据集。
- 上下文长度:LOFT 支持不同的上下文长度限制,包括 32k、128k 和 1M token。
- Corpus-in-Context(CiC)提示:提出了一种新的基于提示的方法,利用 LCLMs 的能力直接摄取和处理整个语料库。
实验设计
实验的目的是评估LCLMs在不同类型的任务上的表现,包括文本检索、视觉检索、音频检索、检索增强生成(RAG)、SQL查询和多示例上下文学习(Many-Shot ICL)。实验使用了以下三个LCLMs:
- Google的Gemini 1.5 Pro
- OpenAI的GPT-4o
- Anthropic的Claude 3 Opus
实验使用了LOFT基准测试中的35个数据集,这些数据集覆盖了不同的上下文长度(32k、128k和1M token)。评估指标根据任务的不同而变化,例如文本、视觉和音频检索使用Recall@1,RAG使用子段精确匹配,SQL使用准确率,Many-Shot ICL使用分类准确率。
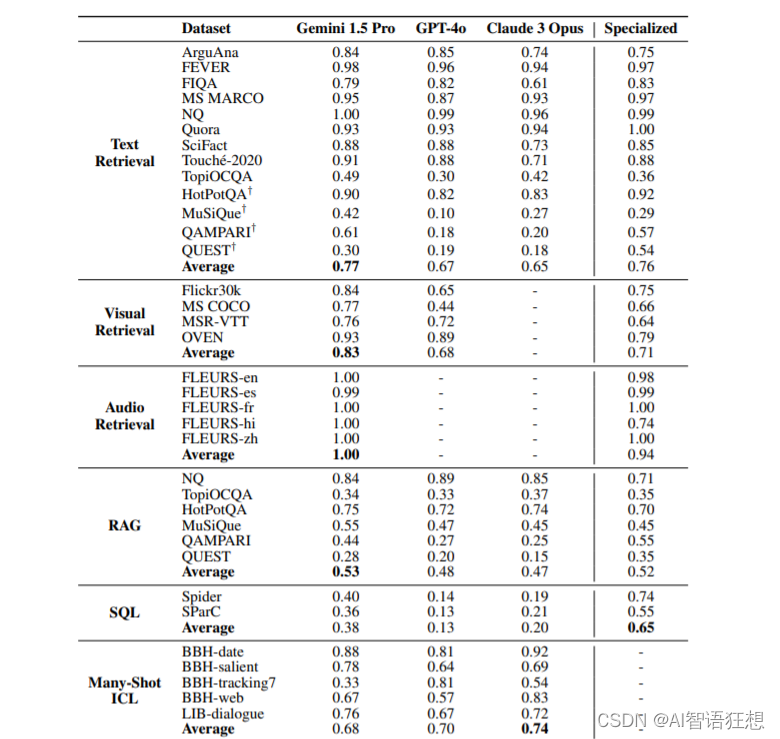
实验结果
实验结果显示,在128k token的上下文长度下,LCLMs在文本检索任务上的表现与专门的检索系统(如Gecko)相当。在视觉检索任务上,Gemini 1.5 Pro在所有视觉基准测试中都优于GPT-4o,并且在不同上下文长度下保持了对CLIP模型的优势。在音频检索任务上,Gemini 1.5 Pro显示出与PaLM 2 DE相当的性能。然而,在SQL查询和多跳组合推理任务上,LCLMs的表现明显落后于专门的模型。

消融实验
消融实验旨在通过移除或修改CiC提示中的某些组件来分析它们对模型性能的影响。以下是一些关键的消融实验:
-
任务特定指令 vs 通用指令:通过将任务特定的指令替换为通用指令,研究者评估了指令的具体性对性能的影响。
-
文档ID的格式:实验考察了文档ID的格式(如数字ID、字母数字ID)对检索性能的影响。
-
上下文中的文档位置:通过改变测试和少量示例中gold标准文档(gold documents)在上下文中的位置,研究者分析了位置对检索性能的影响。
-
链式推理(Chain-of-Thought):在少量示例中添加或移除链式推理步骤,以评估其对模型性能的影响。
-
查询的位置:实验改变了查询在提示中的位置,以测试其对性能的影响。
-
文档内容的呈现:通过仅使用文档标题或完全去除文档内容,研究者评估了文档内容对性能的影响。分析
- 任务特定指令对于LCLMs的性能至关重要,因为它们为模型提供了明确的任务目标。
- 文档ID的格式对性能有显著影响,其中单调的数字ID表现更好,可能是因为它们在模型的标记化过程中更为高效。
- 文档在上下文中的位置对检索性能有显著影响,当gold标准文档位于上下文的末尾时性能下降,这表明模型对上下文的注意力分布可能存在偏差。
- 链式推理对于需要复杂推理的任务尤其重要,有助于提高模型的准确性。
- 查询的位置通常在提示的末尾更为有效,这与自动回归语言模型的前缀缓存机制相符。
- 提示策略:不同的提示策略对性能有显著影响。
讨论与结论(Discussion and Conclusion)
- LCLMs 潜力:LCLMs 显示出在检索任务中与特定任务模型相媲美的潜力。
- 改进空间:在长上下文推理方面,尤其是在 SQL 类任务中,LCLMs 需要进一步改进。
- LOFT 的贡献:LOFT 提供了一个严格的测试平台,用于衡量 LCLMs 在长上下文建模方面的进展。
限制(Limitations)
- 计算资源和成本:使用 LCLMs 进行实验受到计算资源和财务成本的限制。
本文首发于公众号:AI智语狂想,欢迎关注!


















 932
932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











