






 本文介绍了散点图、气泡图、直方图、核密度曲线、箱线图和热力图等在数据分析中的应用,强调了这些图表在揭示变量间关系、比较数据分布和异常检测等方面的作用,适用于电商分析、统计分析和空间属性可视化。
本文介绍了散点图、气泡图、直方图、核密度曲线、箱线图和热力图等在数据分析中的应用,强调了这些图表在揭示变量间关系、比较数据分布和异常检测等方面的作用,适用于电商分析、统计分析和空间属性可视化。
说明:本文仅做个人笔记记录,如有疑问欢迎戳我~
1、散点图
散点图在报表中不常用到,但是数据分析中比较常见。散点图通过坐标轴来揭示数据间的关系,发掘变量与变量之间的关联,主要特点如下:
A:将所有的数据以点的形式展现在平面直角坐标系上
B:散点图通常用于显示和比较数值,例如科学数据、统计数据和工程数据
C:在不考虑时间的情况下比较大量数据时使用
D:散点图中包含的数据越多,比较的结果更精准,比如回归分析。当数据量小的时候会比较混乱
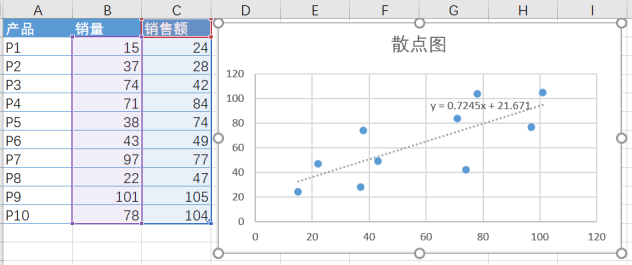
示例:
1:选中数据区域 - 插入 - 推荐的图表 - 散点图
2:美化图表,添加趋势线(默认为线性,可以从设置中进行修改,也可以添加公式)
2、气泡图
气泡图是散点图的变种,通常用于展示和比较数据之间的关系和分布,它使用气泡代替散点图的数值点,面积大小代表数值大小,进而分析数据维度之间的相关性。
也可以用作研究两个变量与时间变量的关系。如果再多一维变量,还可以使用颜色区分。
示例:
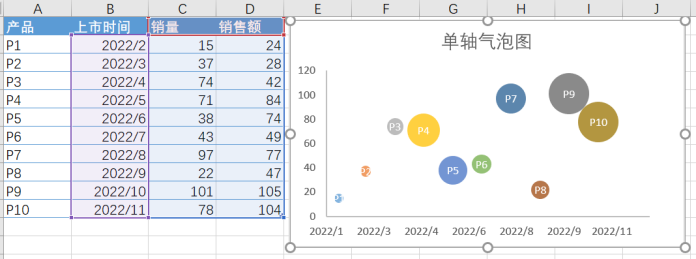
单轴气泡图
1:选中数据区域【只选上市时间、销量和销售额】 - 插入 - 推荐的图表 - XY散点图 - 气泡图
2:设置数据系列格式 - 填充 - 依据数据点着色
3:系列选项 - 气泡宽度 - 气泡大小缩放键入合适的百分比可以整体缩放气泡大小
4:添加数据标签 - 设置数据标签格式 - 单元格中的值 - 选中产品一列的值
5:美化图表,去掉图例、网格线,坐标轴调整
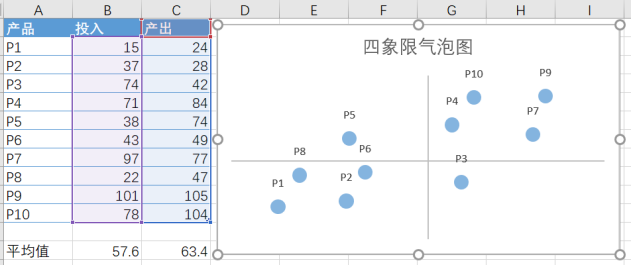
四象限气泡图
1:选中数据区域【只选投入和产出】 - 插入 - 推荐的图表 - XY散点图 - 气泡图
2:系列选项 - 气泡宽度 - 气泡大小缩放键入合适的百分比可以整体缩放气泡大小
3:添加数据标签 - 设置数据标签格式 - 单元格中的值 - 选中产品一列的值
4:美化图表,去掉图例、网格线
5:选中XY坐标轴 - 设置坐标轴格式 - 横纵坐标交叉的坐标轴值改为投入/产出的平均值 - 刻度线和标签显示为无
3、直方图
统计图表,用于表示数据的分布情况。直方图与柱状图看似相像,实则完全不同。 前者反映数据分布情况,后者则不具备此功能,只能对数值进行比较。 从数据结构来说,柱状图需要1个分类变量,是离散的,柱子间有空隙。但直方图的数据均为连续的数值变量,因此柱子间是没有空隙的。 直方图一般用于单个变量,如果是多个变量可以使用多变量直方图。
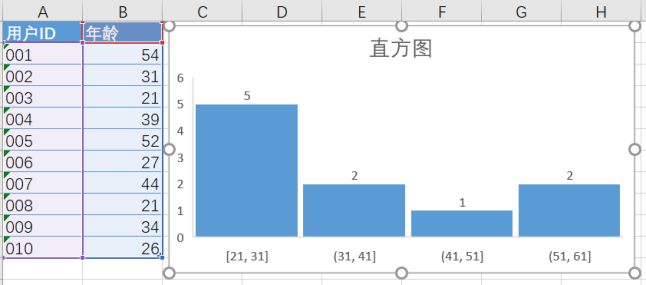
示例:
1:选中数据区域 - 插入图表 - 直方图
2:点选x轴 - 设置坐标轴格式 - 坐标轴选项 - 箱宽度设置为10(即两个区间的年龄跨度为10)
3:美化图表,添加数据标签,去掉网格线,间隙宽度适当调大
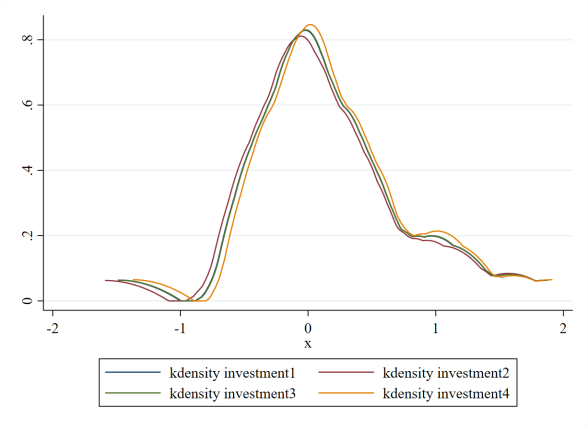
4、核密度曲线
统计图表,用于表示数据的分布情况。KDE图不是使用离散分箱,而是使用高斯核平滑产生连续密度估计,可以查看并对训练数据集和测试数据集中特征变量的分布情况。
它也很像普通的曲线图,但是要记住它一条线是一个变量,曲线图是两个变量。如果要表达多个变量可以使用等高线图或者峰峦图。等高线图是二元变量,峰峦图是多元变量,但是变量数最好不要超过八个,图会很难看。
示例:(来源于网络)
5、箱线图
又称为盒须图、盒式图或箱线图,一种用作显示一组数据分布情况,它能显示一组数据中的最小值、第一四分位数、中位数、第三四分位数和最大值来反映数据分布的中心位置和散布范围,可以粗略地看出数据是否具有对称性。
通过将多组数据的箱线图画在同一坐标上,则可以清晰地显示各组数据的分布差异,为发现问题、改进流程提供线索。
从箱子延伸出去的线条展现出了上下四分位数以外的数据,这代表离群值,也可称之为异常值。框的不同部分之间的间距表示数据中的分散程度(扩散)和偏斜,并显示离群值。
假如你是一位互联网电商分析师,你想知道某商品每天的卖出情况:该商品被用户最多购买了几个,大部分用户购买了几个,用户最少购买了几个。箱线图就能很清晰的表示出上面的几个指标以及变化。
另外企业产品质量管理、人事测评、探索性数据分析等统计分析活动也经常会被应用到,如图,可以发现,华北地区出现超出范围的异常值,可通过结合业务场景分析异常原因。
示例:
1:选中数学和语文列 - 插入 - 推荐的图表 - 箱线图
2:选择纵坐标轴 - 设置坐标轴格式,适当调小Y坐标的范围
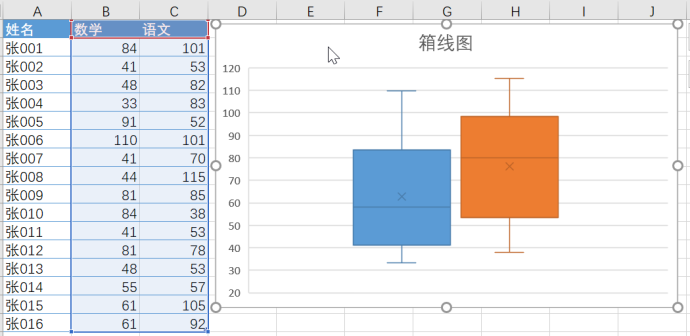
中间最大的区域中,最下面的线是1/4分位数
中间的是2/4分位数
最上面的是3/4分位数
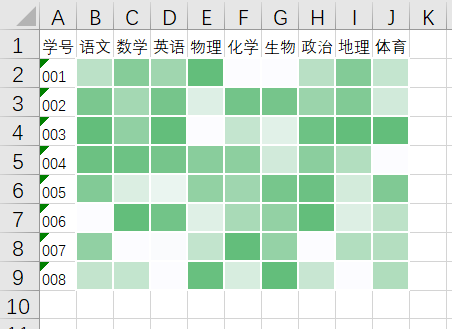
6、热力图
热力图主要通过颜色深浅表现数值的大小(两个维度),一般用于活跃程度的体现,可以直观清楚地看到数据密集情况。
适合用于查看总体的情况、发现异常值、显示多个变量之间的差异,以及检测它们之间是否存在任何相关性。
绘图时,需指定颜色映射的规则。例如,较大的值由较深的颜色表示,较小的值由较浅的颜色表示;较大的值由偏暖的颜色表示,较小的值由较冷的颜色表示。
热力图在网页分析、业务数据分析等其他领域也有较为广泛的应用。如图展示了不同区域在不同时间的订单数量。
示例:
1:选中第一列数据区域 - 开始 - 样式 - 条件格式 - 色阶(配置合适颜色)
2:使用格式刷一列一列覆盖条件格式(这样做是因为不同数据的总分是不一样的,如果一起做比较,就很难体现出同科目的高低情况了)
3:将数字显示去掉,在单元格格式 - 自定义 - 类型输入【;;;】
4:给单元格添加白色框线
5:视图 - 显示 - 隐藏单元格网格线
6:增加标题等细节设置
7、地图
一切和空间属性有关的分析都可以用到地理图。比如各地区销量,或者某商业区域店铺密集度等。一般用颜色深浅或气泡大小来展示区域范围的数值大小。比如人口密度、各地区销量,或者某商业区域店铺密集度等。

















 5794
5794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









