







识别分为单实例和类别识别,前者特殊性,后者有普遍性。
算法包括:对图和视频的分类,检测定位物品,估计语义和几何属性,分类人类活动与事件

深度学习解决“形变”,局部特征可以帮助解决“遮挡”,还有些问题,“背景”
图像识别系统包括:表达(表达,分类)——学习(学习分类器,给训练数据集)——识别(分类器运用在新数据中)
表达
整图表达成小区域、考虑区域联系→词袋
达到:invariance——图像变化(光照、遮挡、尺度)后提取特征仍然是同一个;covariance——图像变化后提取特征“经过转换”仍然是同一个
产生式:画出张三(圈起来),p(a,b)——似然、先验 p(b|a)p(a)
算法:朴素贝叶斯、LDA、2d part based models、3d part based models
判别式:知道张三李四差异,区分开(线分开)p(b|a)——后验

算法:近邻、神经网络、支持向量机、boosting
混合式
图像变成向量——BoW词袋模型
最早起源于纹理

用直方图判别每张图各种纹理出现的次数
把图变成袋子里的小块,词典写向量(长度单词个数)
提取特征——学习视觉词典——用词典频率表示图像
提取特征
网格、SIFT提取(归一化、描述符)
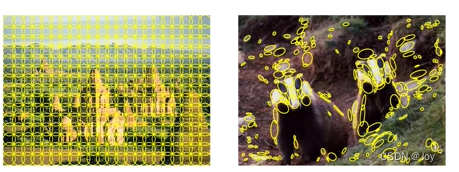
视觉词典 codebook
将单词聚类,想要几个聚成几个,每个取中心
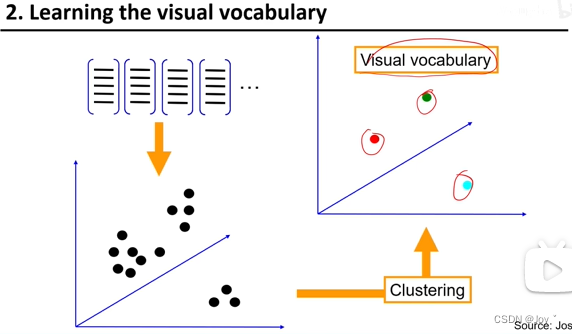
kmeans聚类
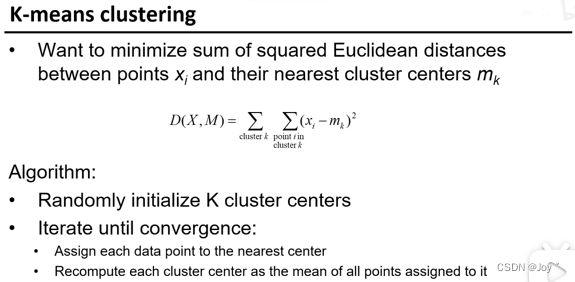
之后将图向量化后投影到空间中,看距离哪个单词中心最近
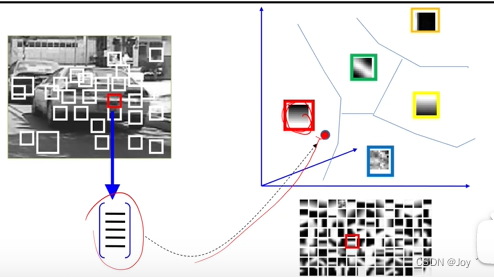
近邻、KD树搜索
下图左边为中心单词

问题:对聚类类别的设置(太大、太小,影响泛化)、计算效率(kmeans慢)
词典成型
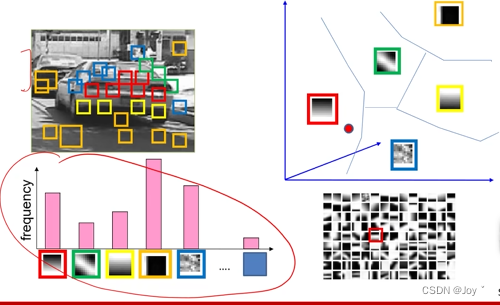
但是词袋模型存在对特征顺序不一样的无法判断准确,如我爱AB,和爱我AB,其实是不太一样,特别是涉及语义理解、我们可以将整图分成多个区域,每个区域去对应比较
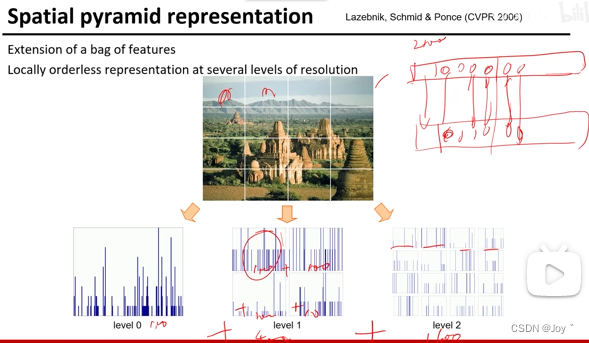
学习
最优化:在训练集和验证集上找目标函数的最优参数
监督级别:标签强弱
样本:能拿到多少
先验定义
过拟合(精度太过了)、欠拟合(需要泛化强,不能欠)
“非”类数据的收集——选不好,线条分不准
识别
给我图——做分类、检测(画框挑出,框中是不是)x,y,S,θ,N类、分割(像素级别)
对同一个对象输出太多框——要非最大值抑制















 5148
5148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









