








本文选自爱斯维尔中的Expert Systems With Applications期刊
Keywords: Many-to-one LSTM ; Sequential training; Real-time forecasting ; Time series ; Financial markets
ABSTRACT
金融市场高度复杂且不稳定;因此,准确预测此类市场对于尽早发出崩盘警报和随后的复苏至关重要。人们一直在使用金融数学和机器学习等不同领域的学习工具来对此类市场做出可信的预测。然而,在使用长短期记忆(LSTM)等人工神经网络框架之前,此类技术的准确性还不够。此外,对金融时间序列进行准确的实时预测(也称为即时预测)对于所使用的 LSTM 架构及其训练过程来说具有很大的主观性。在这里,我们通过训练双版本的 LSTM 来实时预测金融市场,该版本在每次迭代中仅预测一个时间步,以便本次迭代的预测将作为下一次迭代的输入。半收敛是循环 LSTM 设置中的一个突出问题,因为误差可能通过迭代传播;然而,LSTM 的二元性有助于减少这个问题。特别是,我们使用一个 LSTM 来找到与最小损失相关的最佳 epoch 数量,并仅通过那么多 epoch 训练第二个 LSTM 来进行预测。我们将当前预测视为下一个预测训练集的一部分,并训练相同的 LSTM。虽然经典的训练方法在测试期间进行预测时会导致更多错误,但我们的方法提供了卓越的准确性,因为训练在测试期间进行时会增加。我们的方法的预测准确性使用来自三个不同金融市场(股票、加密货币和大宗商品)的三个时间序列进行了验证。将结果与单个 LSTM、扩展卡尔曼滤波器和自回归集成移动平均模型的结果进行比较。
1. Introduction
由于对偶性在每次迭代中揭示了最佳的历元数,因此这种实时双 LSTM 能够适应尖峰和突然变化的时间序列(例如金融时间序列)的预测。该模型能够将时间序列的每一个新的未来观察结果纳入正在进行的训练过程中以进行预测。由于我们使用一系列观察到的时间序列来预测仅提前一个时间步,因此预测精度显着提高。此外,这个双 LSTM 处理 t − 2 个先前的观测值以及当前的预测,以对下一个时间步进行预测;因此,与当前预测相关的预测误差不会传播到下一个预测,因为它是使用 t − 2 个先前观测值进行处理的。虽然训练 LSTM 的经典方法在测试期间进行更远的预测时会导致错误传播,但我们的方法能够在更远的情况下执行预测时保持较高的准确性。本文提出的顺序训练的多对一双 LSTM 方案对基于机器学习的金融市场预测文献做出了以下科学贡献:
• 主要贡献
这种双 LSTM 避免了半收敛状态,因为执行预测的 LSTM(即 LSTM2)仅使用 LSTM1 在每次迭代中显示的最佳历元数进行训练。因此,该框架适应了时间序列的自然特征,包括尖峰、突然波动等,这与金融市场预测相关。
较小的贡献
这种实时双 LSTM 能够将时间序列的每一次未来观察(随着时间的推移可用)纳入正在进行的训练过程中,以便每次迭代的计算成本保持不变,同时随着新数据的纳入而提高准确性时间。
对一系列数据输入仅提前一个时间步进行预测有助于了解数据与不久的将来的长期依赖性,从而显着提高预测准确性。
可以优化顺序输入的长度,以便双 LSTM 理解时间序列的基本模式以做出精确的预测。
本文由五个部分组成,即简介(第 1 节)、单 LSTM 与双 LSTM(第 2 节)、最新方法(第 3 节)、性能分析(第 4 节)和结论(第 5 节)。在第 2 节中,首先,我们提出使用单 LSTM 进行实时时间序列预测的概念,然后,我们提供用于顺序训练的多对一双 LSTM 架构的数学公式。第 3 节介绍了两种最先进的统计时间序列预测方法及其公式:首先是一种称为扩展卡尔曼滤波器 (EKF) 的非线性方法,然后是一种称为 ARIMA 的线性方法。第 4 节使用三种金融股票(苹果、微软、谷歌)、三种加密货币(比特币、以太坊、卡尔达诺)和三种货币,详细分析了我们的双 LSTM 架构与单 LSTM、EKF 和 ARIMA 的性能对比。商品(黄金、原油、天然气)。我们在第 5 节中提出了结论和讨论。表 1 和表 2 分别列出了本文中使用的符号及其描述和缩写及其描述。
2. Single-LSTMs versus dual-LSTMs
在本节中,首先,我们提供使用具有前向验证的多对一单 LSTM 方案进行实时时间序列预测的技术细节。然后,我们提出了双 LSTM 框架,它是单 LSTM 的前身,它通过避免历元损失的半收敛来改进实时时间序列预测。
2.1. Many-to-one single-LSTM architecture with walk-forward validation for real-time forecasting
在这里,首先,我们介绍多对一的 LSTM 架构;然后,我们制定了这个LSTM的优化框架;最后,我们介绍了使用该单 LSTM 进行时间序列的实时训练/验证/预测的过程以及与该单 LSTM 设置相关的问题。
2.1.1. Many-to-one LSTM
由于我们每次仅对输入时间序列提前一步进行预测,因此此处实现的 LSTM 架构是多对一类型(Goodfellow 等人,2016)。为了获得更好的预测精度,我们通过堆叠常规 LSTM 将深度学习概念强加到 ANN 中,如图 1(a) 所示为具有 K 堆叠 LSTM 的 ANN 架构。第一个 LSTM 之后的每个堆叠 LSTM 充当 ANN 的隐藏层,其中每个 LSTM 隐藏层提供一系列存储单元以提高学习精度。 LSTM 由一系列非线性循环模块组成,在图 1 中表示为 M(t) j,其中 t = 1, ... , T 和 j = 1, ... , N,其中每个模块处理与一步。 LSTM 引入了一个记忆单元,这是一种特殊类型的隐藏状态,它与隐藏状态具有相同的形状,旨在记录附加信息。 LSTM 中的每个循环模块通过四个隐藏层过滤信息,其中三个是门,即遗忘门、输入门和输出门,并且另一个称为维持和更新长期记忆的细胞状态,见图1(b)。
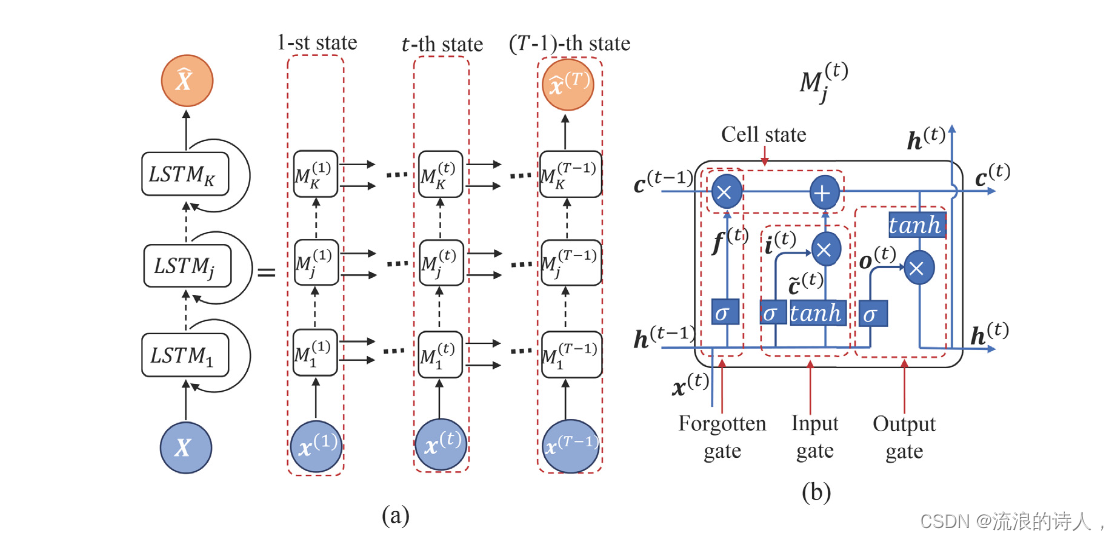
遗忘门通过决定应该忘记或保留哪些信息来重置存储单元的内容。该门产生一个介于 0 和 1 之间的值,其中 0 意味着完全忘记之前的隐藏状态,而 1 意味着完全保留该状态。来自先前隐藏状态的信息,即 h(t−1),以及来自当前输入的信息,即 x(t),通过 sigmoid 函数传递,表示为 σ,根据

其中 Wf 和 bf 分别是加权矩阵和偏置向量。由两个组件组成的输入门决定将哪些新信息存储在单元状态中。第一个组件是 sigmoid 层,它根据先前的隐藏状态和当前输入的信息来决定要更新哪些值,以便
其中 Wi 和 bi 分别是权重矩阵和偏置向量。下一个组件是 tanh 层,它根据先前的隐藏状态和当前输入的信息创建新候选值 ̃ c(t) 的向量:
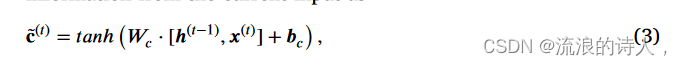
其中 Wc 和 bc 分别是权重矩阵和偏置向量。细胞状态用新的长期信息更新 LSTM 的记忆。为此,首先,它将旧细胞状态 c(t−1) 乘以遗忘状态 f (t),即 f (t) ⊙ c(t−1),以确保从旧细胞状态 c(t−1) 中保留的信息旧的细胞状态是遗忘状态所允许的。然后,我们将点积 i ⊙ ̃ c(t) 添加到 f (t) ⊙ c(t−1) 中,即

作为 ANN 发现相关的当前输入状态的信息。输出门根据当前单元状态、当前输入状态和先前隐藏状态的信息确定下一个隐藏状态的值。首先,sigmoid 层决定如何当前输入和之前的隐藏状态的大部分将被输出。然后,当前细胞状态通过 tanh 层以在 -1 和 1 之间缩放细胞状态值。因此,输出 h(t) 为
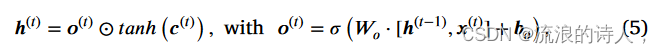
其中 Wo 和 bo 分别是加权矩阵和偏置向量。基于h(t),网络决定当前隐藏状态中的哪些信息应该被执行到下一个隐藏状态,其中下一个隐藏状态用于预测。总而言之,遗忘门确定需要先前步骤中的哪些相关信息。输入门决定可以从当前单元状态添加哪些相关信息,输出门最终确定下一个隐藏状态的输入。
2.1.2. Optimization of LSTM
训练 LSTM 是最小化相关重建误差函数(也称为损失函数)的过程,涉及方程的权重和偏差向量。 (1)、(2)、(3)、(4) 和(5)。这样的最小化问题分四步实现:首先,输入数据通过ANN前向传播得到输出;其次,计算预测输出与真实输出之间的损失;第三,使用时间反向传播(BTT)计算损失函数相对于 LSTM 权重和偏差向量的导数(Werbos,1990);第四,通过梯度下降法调整权重和偏差向量(Gruslys et al., 2016)。
BTT 将输出的所有依赖项向后展开到 ANN 权重上(Manneschi & Vasilaki,2020),如图 1(a)中从左侧到右侧所示。在每次迭代中,假设 t ∈ [1, N + 1],我们仅通过输入标签的一个实例来训练 LSTM,其中输入为 X(t) = [ x(t), ... , x(T ) , ̂ x(T +1), ... , ̂ x(T +t−2)] ,标签为 ̂ x(T +t−1)。由于这个过程,在第 t 次迭代时,人工神经网络使用第 t 个输入标签实例进行训练,并预测第 (T + t − 1) 个时间步长。因此,我们将 LSTM 第 t 次迭代时的损失函数表示为相对均方误差,

其中 F 表示 Frobenius 范数,̂ x(T +t−1) 是输入 X(t−1) 的 LSTM 的输出。我们使用 BTT 来计算方程的导数。 (6)关于权重和偏差向量。我们使用基于梯度下降的方法更新权重,称为自适应矩估计(ADAM)(Kingma&Ba,2015)。 ADAM 是一种迭代优化算法,用于最近的机器学习算法中,以最小化损失函数,它使用梯度的一阶矩和二阶矩的平均值进行计算。具体来说,梯度下降利用目标函数的梯度在搜索空间上进行导航;而 ADAM 使用偏导数的衰减平均值,通过每个输入变量的自适应步长自动更新梯度下降。它通常比标准梯度下降方法收敛得更快,并且通过不累积中间权重来节省内存(Indolia 等人,
2.1.3. Real-time time series forecasting
我们采用顺序方法利用时间序列数据有效训练 LSTM 并预测未来。对于固定长度的顺序数据输入,LSTM 模型的一种实现是在一次迭代中仅预测一个未来时间步,其中该过程运行直到执行所需的预测长度。这种实时预测方法能够将时间序列的每个新数据点合并到正在进行的训练过程中,以预测下一个时间步骤。令,对于某些 T , N ∈ N 使得 N < T ,时间序列的可观察部分是 [x(1), ... , x(T )] ,不可观察部分,即时间的未来级数为 [x(T +1), ... , x(T +N)]。

图 2. 使用单 LSTM 架构的实时时间序列预测方案,其中当前时间序列的观测部分 [x(1), ... , x(T )] 对于某个 T 而言迭代以蓝色显示。时间序列的初始未观测部分 [x(T +1), ... , x(T +N)] 对于某些 N < T ,即未来,以白色显示,而对未来的预测为每次迭代都以红色显示。对于第一次迭代,我们使用输入 X(1) = [x(1), ... , x(T −2)] 和标签 x(T −1) 训练这个单 LSTM。使用输入 X(2) = [x(2), ... , x(T −2)] 和标签 x(T ) 执行前向验证步骤,以确定训练的最佳历元数这给出了最小的预测损失。我们用那么多的 epoch 重新初始化并重新训练这个 LSTM,并使用训练后的 LSTM 来预测时间步 (T + 1),我们用 ̂ x(T +1) 表示,这样 ̂ x(T +1) = LSTM (X(1))。在第二次迭代中,我们使用输入 X(2) = [x(2), ... , x(T −1)] 和标签 ̂ x(T ) 重新训练 LSTM。迭代 2 中的验证集包括第一次迭代的预测 ̂ x(T +1) 作为观测值。与迭代 1 类似,我们基于具有最佳 epoch 数的重新训练的 LSTM 进行新的预测 ̂ x(T +2)。我们迭代地执行这个过程,直到整个未观察到的部分的预测可用。
对于第一次迭代,我们使用输入 X(1) = [x(1), ... , x(T −2)] 和标签 x(T −1) 在固定数量的历元上训练这个 LSTM,说L,它是由用户给出的。在每个时期,通过计算输出 ̂ x(T ) = LSTM (X(1)) 和观测值 x(T ) 之间的损失来执行前向验证步骤。我们揭示了在此验证步骤中损失最小的时期的最佳数量。此验证步骤可确保损失函数更好地收敛,因为选择最佳历元数对于非凸或半收敛损失函数来说具有挑战性。现在,我们重新初始化这个 LSTM,并用那么多的 epoch 重新训练 LSTM。我们将 X(1) 通过这个经过训练的 LSTM 并预测第 (T + 1) 个时间步,即 ̂ x(T +1) = LSTM (X(1)),参见图 2 的训练/验证/这个多对一实时单 LSTM 的测试过程。在第二次迭代中,我们使用输入 X(2) 和标签 x(T ) 在相同的固定周期数上重新初始化并重新训练该 LSTM。与迭代 1 类似,验证步骤是通过计算当前输出 ̂̂ x(T +1) = LSTM (X(2)) 和当前观测值 ̂ x(T +1) 之间的损失来执行的。时代。请注意,̂ x(T +1) 是迭代 1 期间第 (T +1) 个时间步的预测,我们将其用作迭代 2 中验证步骤的观察点。与迭代 1 类似,我们执行预测对于第 (T + 2) 个时间步,即,在使用与最小验证损失相关的最佳历元数训练 LSTM 后, ̂ x(T +2) = LSTM (X(3))。我们继续执行此过程,直到对所有 N 个时间步执行了预测。
我们使用苹果股票的收盘价运行这个实时单 LSTM 模型,以分析验证损失 (Ll) 相对于时期数 (l) 的变化。在这里,我们将 1227 天的价格序列输入到这个单 LSTM 中,并生成第 1228 天的价格,其中损失计算为第 1228 天的预测价格与观测价格之间的相对均方误差。我们继续进行 60 个时期的单日训练,如图 3 所示,
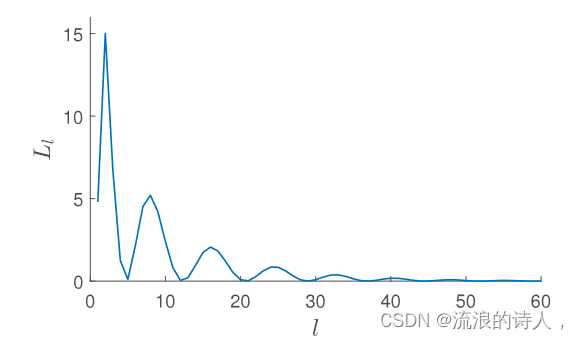
图 3. 损失函数相对于历元数的非凸特征。我们应用实时训练方案来训练具有苹果股票收盘价的多对一单 LSTM。我们将 1227 天的价格序列输入 LSTM 并生成第 1228 天的价格。损失在验证步骤期间计算为预测价格与第 1228 天观测价格之间的相对均方误差。我们继续进行 60 个时期的单日训练,并在每个时期执行验证步骤,其中第 l 个时期的验证损失表示为 Ll。
它表现出验证损失的非凸特征。虽然损失函数相对于历元的波动可能有多种原因,但主要原因是 LSTM 使用梯度下降技术的变体进行优化,特别是在我们的例子中是 Adam,它在下降过程中导致振荡损失函数(Goodfellow 等人,2016)。这个单 LSTM 的验证步骤能够揭示与最小损失相关的最佳时期数。然而,这single-LSTM 在执行训练、验证和预测的每次迭代之前进行初始化。由于初始化的原因,这个单 LSTM 无法学习长度为 T − 2 的当前输入数据序列之外的数据。为了克服学习过程的这一限制,我们想出了一种独特的方法来训练双LSTM 以及前向验证步骤可确定每次迭代的最佳迭代次数。
2.2. Dual-LSTM for real-time time series forecasting
在这种双重方法中,我们维护两个 LSTM,分别表示为 LSTM1 和 LSTM2,它们在每次迭代中都经过独特的训练,见图 4,了解这种多对一实时双 LSTM 的架构。对于固定长度的输入数据序列,这种实时双 LSTM 模型在每次迭代时仅预测一个未来时间步,以便该模型能够将时间序列的每个新数据点合并到正在进行的训练过程中,从而使下一个时间步骤的预测。与单 LSTM 类似,对于某个 T,当前观察到的时间序列为 [x(1), ... , x(T )],时间序列的未来未观察到的部分为 [x(T +1) , ... , x(T +N)] 对于某些 N < T ,请参见图 4。对于第一次迭代,我们使用输入 X(1) = [x(1), ... , x 训练 LSTM1 (T -2)] 和标签 x(T -1) 在固定数量的历元(例如由用户给出的 L)上。在每个时期,通过计算输出 ̂ x(T ) = LSTM1 (X(2)) 和标签 x(T ) 之间的损失来执行验证步骤。在 LSTM1 的验证步骤中,我们确定损失最小的最佳 epoch 数量,并使用输入 X(2) 和标签 x(T ) 训练 LSTM2 多个 epoch。我们通过经过训练的 LSTM2 传递 X(3),并执行第 (T + 1) 个时间步的预测,即 ̂ x(T +1) = LSTM2 (X(3))。在第二次迭代中,我们将 LSTM1 初始化为 LSTM2,这涉及为 LSTM1 分配与 LSTM2 相同的权重和偏置向量。现在,我们使用输入 X(2) 和标签 x(T ) 在相同的固定周期数上训练 LSTM1。与迭代 1 类似,在每个时期,通过计算输出 ̂̂ x(T +1) = LSTM1 (X(3)) 与上一次迭代的预测之间的损失来执行验证步骤,即 ̂ x( T+1)。请注意,(1) 第 1 次迭代中的预测 ̂ x(T +1) 用作第 2 次迭代中验证步骤的观测点,(2) 对于第 (T + 1) 个时间步骤,我们使用 ̂̂ x(T +1) 表示迭代 2 中 LSTM1 的输出,因为 ̂ x(T +1) 已用于表示迭代 1 中 LSTM2 的输出。我们对第 (T + 2) 个进行预测时间步长,即 ̂ x(T +2) = LSTM2 (X(4)) 在训练 LSTM2 后,使用输入 X(3) 和标签 ̂ x(T +1),通过与最小的验证损失。我们继续执行此过程,直到对所有 N 个时间步执行了预测。算法 1 总结了我们的实时多对一双 LSTM 方案的训练、验证和预测过程。
3. State-of-the-art methods
在这里,我们提出了两种最先进的时间序列预测方法,即扩展卡尔曼滤波器(EKF)和自回归积分移动平均(ARIMA),我们用它们来验证双 LSTM 方案的性能。在这里,我们利用与 LSTM 相同的顺序训练来对同一金融时间序列进行实时预测。
3.1. Extended Kalman Filter (EKF)
3.2. Autoregressive integrated moving average (ARIMA) model
4. Performance analysis
5. Conclusions
求解时间混沌系统的经典方法要么是线性的,要么是基于模型的,模型假设系统先前输出之间的平稳时间序列之间的线性关系;要么是非线性的和基于模型的,模型假设这种关系中的非线性。因此,虽然经典的线性模型无法捕获数据中的非线性和非平稳关系,但非线性模型可能无法处理某些非线性和非平稳信号,因为基础模型与数据不拟合。由于金融时间序列通常是非平稳、非线性且包含噪声的(Bontempi et al., 2013),传统的基于统计模型的技术在高精度预测时间序列时遇到一些限制。然而,基于 ANN 的方法(例如 LSTM)不仅是非线性的,而且是无模型的,因此神经网络可以在训练过程中学习模仿允许的数据。在本文中,我们提出了一种使用顺序训练的多对一双 LSTM 的金融市场实时预测技术。我们将这种技术应用于从股票市场、加密货币市场和商品市场获得的一些时间序列;然后,将双 LSTM 与三种最先进的方法(即 EKF、ARIMA 和单 LSTM)的预测性能进行了比较。
在这里,我们使用移动窗口方法使用采样的顺序数据来训练多对一的双 LSTM,以便后续窗口从前一个窗口向前移动一个数据实例。这种顺序窗口训练在时间序列预测中发挥着重要作用,因为它:(1)有助于从给定的有限时间序列中生成更多数据,然后对人工神经网络进行彻底的训练; (2)使数据异构化,从而减少ANN的过拟合问题; (3) 不仅有助于学习整个时间序列的数据模式,还有助于学习短片段的连续数据。顺序窗口训练最大限度地提高了 DualLSTM 的性能,因为它加速了 LSTM 的学习能力,并提高了 LSTM 对新数据的鲁棒性。
文献提出了一些基于偏自相关函数 (PAF)、信息标准 (IC) 和验证的技术,以确定 ARIMA 中的滞后参数 p 和平滑参数 q (Hastie et al., 2009)。在 PAF 方法中,最佳的 p 和 q 是根据应用于 PAF 的某个阈值来选择的。此类方法能够基于阈值指定的显着偏自相关来确定上述参数;然而,可能还有一些其他参数值可以获得更好的自相关性,即使它们基于阈值并不显着(Hastie 等人,2009)。 IC包括两种著名的技术,即贝叶斯信息准则(BIC)和赤池信息准则(AIC),每种技术都是滞后长度p的估计。这两个标准的基本思想是,处理残差平方和的第一项随着滞后的增加而减少,而加权滞后的第二项则随着滞后的增加而增加。然而,由于 BIC 和 AIC 是基于模型的框架,它们不仅依赖于数据服从分布、观测值独立、数据不存在不确定性等假设,而且它们需要比模型参数更多的观测值(Hastie等人,2009)。事实证明,验证不存在上述与其他技术相关的问题,除了小样本量的问题(Varoquaux,2018)。然而,我们所有的九个时间序列数据集都有足够的数据量。因此,为了在本研究中提供竞争性比较,三种最先进的方法 EKF 和 ARIMA 中的每一种都使用验证方案确定的最佳参数组合来实施。其中,我们分离了一个验证训练集中 10% 的最新数据,然后在验证集中尝试不同的参数组合,以确定提供最佳预测性能的组合。这种验证方法为这些预测框架提供了卓越的性能,因为我们不根据用户输入阈值确定最佳参数值。
本研究的性能分析涵盖了双 LSTM 应用于从三个金融市场、股票(苹果、微软、谷歌)、加密货币(比特币、以太坊、卡尔达诺)和商品(黄金、原油、天然气)获得的九个时间序列)。我们观察到,对于 EKF 性能明显较弱的所有 9 个数据集,双 LSTM 的性能明显优于其他三种方法。我们在表 4 中看到,平均而言,双 LSTM 的性能比 EKF 好 17 倍,比 ARIMA 好 4 倍,比单 LSTM 好 3 倍。双 LSTM 对股票、加密货币和商品的平均预测误差分别为 0.05、0.22 和 0.14。原因是,虽然对股票市场等波动性较小的时间序列进行预测很容易,但对加密货币市场等高波动性时间序列的预测却具有挑战性。
在未来的工作中,我们计划扩展这种顺序训练的多对一双 LSTM,以用作工业生产过程中的实时故障检测技术。这种实时故障检测方案将能够产生早期警报,以提醒生产过程中的变化,以便质量控制团队可以采取必要的行动。此外,集体移动主体的轨迹可以可以用高维数据云下的低维流形来表示(Gajamannage et al., 2015; Gajamannage & Paffenroth, 2021; Gajamannage et al., 2019)。然而,由于遮挡等自然现象,多目标跟踪方法无法跟踪这些轨迹的某些片段。因此,我们计划利用双 LSTM 架构来对轨迹的碎片部分进行预测。作为未来的另一个方向,我们计划利用这种双 LSTM 架构进行水流预测。由于其高波动性和频繁的峰值,径流建模和预测是水文学领域的一项复杂任务(Jayathilake & Smith,2021)。我们在 Gajamanage 等人中使用了 RNN。 (2023),用滑动窗口方法建模和预测水流。滑动窗口方法能够从给定的时间序列生成大量同质数据。然而,我们将利用这种双 LSTM 来了解水文流域的行为,然后生成全年的每日预期水流。
我们凭经验验证,我们的实时双 LSTM 的性能优于 EKF 和 ARIMA。未来,我们计划将实时双 LSTM 的性能与其他著名的基于 ANN 的方法的性能进行比较,例如 Facebook 开发的 Prophet (Taylor & Letham, 2018)、Amazon 开发的 DeepAR (Salinas 等人,2018)。 ,2020),Google 开发了 Temporal Fusion Transformer(Lim 等人,2021),Element AI 开发了 N-BEATS(Oreshkin 等人,2019)。 Prophet 旨在自动预测单变量时间序列数据。 DeepAR 是一种基于循环神经网络的概率预测模型。 Temporal Fusion Transformer 是一种新颖的基于注意力的架构,它将高性能多水平预测与对时间动态的可解释洞察相结合。 N-BEATS 是一种定制的深度学习算法,基于后向和前向残差链接,用于单变量时间序列点预测。此外,由于我们的双 LSTM 在本文中预测的是股票价格而不是回报,因此我们计划分析我们的框架对回报的预测性能。虽然股票价格不稳定,但回报却是固定的;因此,未来的分析将有助于理解我们的双 LSTM 框架的广泛适用性
我们提出了金融时间序列的非线性和实时预测技术,该技术由多对一的双 LSTM 制成,并使用数据窗口进行顺序训练。顺序窗口训练方法显着提高了 LSTM 的学习能力,同时大大减少了 LSTM 的过拟合问题。我们凭经验证明,即使对于加密货币和商品等高度波动的时间序列,我们的双 LSTM 也具有卓越的性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









