








ABSTRACT
最近线性预测模型的繁荣对基于 Transformer 的预测器的架构修改的持续热情提出了质疑。这些预测器利用 Transformer 对时间序列的时间标记的全局依赖性进行建模,每个标记由同一时间戳的多个变量形成。然而,由于性能下降和计算爆炸,Transformer 在预测具有较大回溯窗口的序列时面临挑战。此外,每个时间标记的统一嵌入融合了具有潜在未对齐时间戳和不同物理测量的多个变量,这可能无法学习以变量为中心的表示并导致无意义的注意力图。在这项工作中,我们反思了 Transformer 组件的职责,并在不对基本组件进行任何调整的情况下重新调整了 Transformer 架构的用途。我们提出 iTransformer,它简单地颠倒了注意力机制和前馈网络的职责。具体来说,各个系列的时间点被嵌入到变量标记中,注意力机制利用变量标记来捕获多元相关性;同时,前馈网络应用于每个变量标记来学习非线性表示。 iTransformer 模型在多个真实数据集上实现了一致的最新技术,这进一步增强了 Transformer 系列的性能、跨不同变量的泛化能力,以及更好地利用任意回溯窗口,使其成为一个不错的替代方案时间序列预测的基本支柱。
1 INTRODUCTION
Transformer (Vaswani et al., 2017) 在自然语言处理 (Brown et al., 2020) 和计算机视觉 (Dosovitskiy et al., 2021) 方面取得了巨大成功,成长为遵循缩放定律的基础模型 (Kaplan et al., 2021)等,2020)。受广泛领域巨大成功的启发,具有描述成对依赖关系和提取序列中多级表示的强大能力的 Transformer 在时间序列预测中正在兴起(Li et al., 2021; Wu et al., 2021; Nie et al. 2021)。 ,2023)。然而,研究人员最近开始质疑基于 Transformer 的预测器的有效性,这些预测器通常将同一时间戳的多个变量嵌入到不可区分的通道中,并关注这些时间标记以捕获时间依赖性。考虑到时间点之间的数字但较少的语义关系,研究人员发现简单的线性层(可以追溯到统计预测器(Box & Jenkins,1968))在性能和效率上都超过了复杂的 Transformer(Zeng 等人,2023) ;Das 等人,2023)。同时,保证变量的独立性最近的研究更加强调利用互信息,明确地模拟多元相关性以实现准确的预测(Zhang & Yan,2023;Ekambaram 等人,2023),但这个目标可以在不颠覆普通 Transformer 架构的情况下实现。
考虑到基于 Transformer 的预测器的争议,我们反思为什么 Transformer 在时间序列预测方面表现比线性模型更差,而在许多其他领域却占主导地位。我们注意到基于 Transformer 的预测器的现有结构可能不适合多元时间序列预测。如图 2 左侧所示,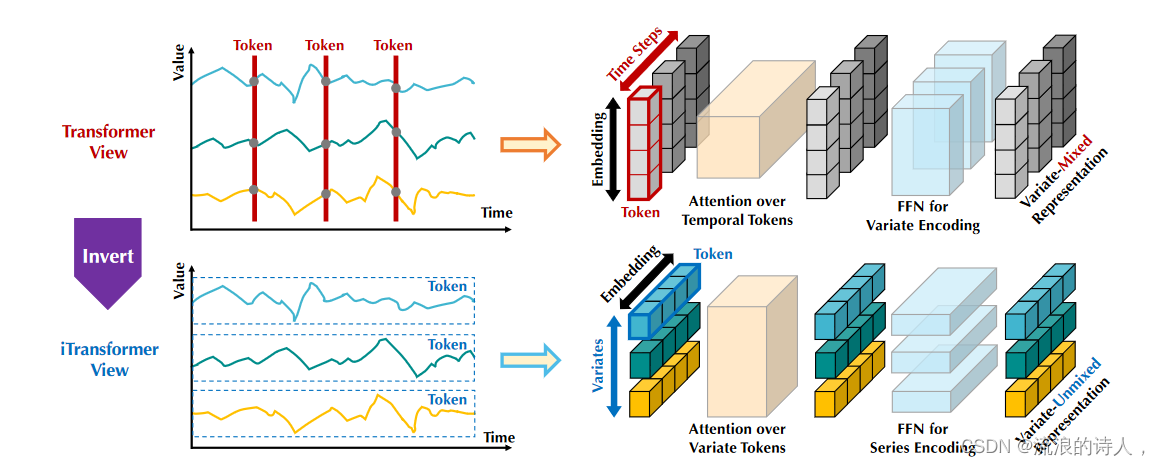
图 2:普通 Transformer(上)和提出的 iTransformer(下)之间的比较。与 Transformer 将每个时间步嵌入到时间标记中不同,iTransformer 将整个序列独立地嵌入到变量标记中,这样多元相关性可以通过注意力机制来描述,并且序列表示可以通过前馈网络进行编码。
值得注意的是,同一时间步长的点基本上代表了由不一致的测量记录的完全不同的物理意义,这些点被嵌入到一个具有消除多元相关性的标记中。由于现实世界中多元时间点的过度局部感受野和未对齐的时间戳,由单个时间步形成的令牌可能难以揭示有益信息。此外,虽然序列变化会受到序列顺序的很大影响,但在时间维度上不正确地采用了排列不变注意机制(Zeng et al., 2023)。因此,Transformer 捕获基本序列表示和描绘多元相关性的能力被削弱,限制了其对不同时间序列数据的容量和泛化能力。
关于将每个时间步的多元点嵌入作为(时间)标记的不合理性,我们对时间序列采取倒置的观点,并将每个变量的整个时间序列独立地嵌入到(变量)标记中,这是 Patching 的极端情况(Nie et al., 2023)扩大了局部感受野。通过反转,嵌入的令牌聚合了系列的全局表示,这些表示可以更加以变量为中心,并通过蓬勃发展的多变量关联注意力机制更好地利用。同时,前馈网络可以足够熟练地学习从任意回溯序列编码并解码以预测未来序列的不同变量的通用表示。
基于以上动机,我们认为并不是Transformer对于时间序列预测无效,而是它使用不当。在本文中,我们重新审视 Transformer 的结构,并提倡 iTransformer 作为时间序列预测的基本支柱。从技术上讲,我们将每个时间序列嵌入为变量标记,采用多变量相关性的注意力,并采用前馈网络进行序列编码。通过实验,所提出的 iTransformer 在图 1 所示的现实世界预测基准上实现了最先进的性能,并且令人惊讶地解决了基于 Transformer 的预测器的痛点。我们的贡献体现在三个方面:
我们对 Transformer 的架构进行了反思,并细化了原生 Transformer 组件在时间序列上的能力还有待探索。
我们提出 iTransformer,将独立时间序列视为令牌,通过自注意力捕获多元相关性,并利用层归一化和前馈网络模块来学习更好的序列全局表示以进行时间序列预测。
通过实验,iTransformer 在现实世界的预测基准上实现了一致的最先进水平。我们广泛分析了倒置模块和架构选择,为基于 Transformer 的预测器的未来改进指明了一个有希望的方向。
2 RELATED WORK
随着自然语言处理和计算机视觉领域取得的逐步突破,精心设计的 Transformer 变体被提出来解决普遍存在的时间序列预测应用。超越同期 TCN(Bai 等人,2018;Liu 等人,2022a)和基于 RNN 的预测器(Zhao 等人,2017;Rangapuram 等人,2018;Salinas 等人,2020),Transformer 展示了强大的序列建模能力和有前途的模型可扩展性,导致了针对时间序列预测的热情修改的趋势。
通过对基于 Transformer 的预测器的系统回顾,我们得出结论,现有的修改可以根据是否修改组件和架构分为四类。如图3所示,第一类(Wu et al., 2021; Li et al., 2021; Zhou et al., 2022)是最常见的做法,主要涉及组件适应,特别是注意力模块长序列的时间依赖性建模和复杂性优化。然而,随着线性预测器的迅速出现(Oreshkin等,2019;Zeng等,2023;Das等,2023),令人印象深刻的性能和效率不断挑战着这个方向。不久之后,第二类尝试充分利用 Transformer,更加关注时间序列的固有处理,例如平稳化(Liu et al., 2022b)、通道独立性和修补(Nie et al., 2023),这带来了关于持续改进的性能。而且,面对多个变量的独立性和相互交互的重要性日益增强,第三类对Transformer在组件和架构上都进行了翻新。代表(Zhang & Yan,2023)通过更新的注意力机制和架构明确地捕捉了跨时间和跨变量的依赖关系。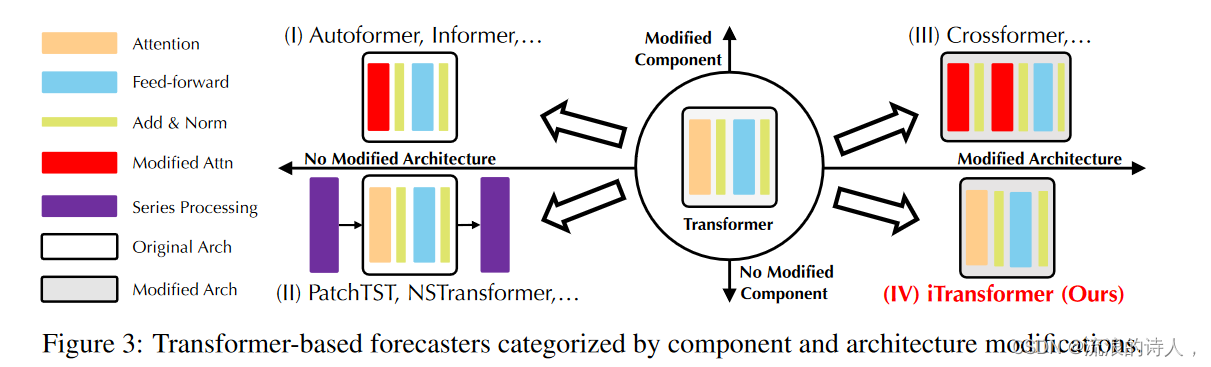
与之前的作品不同,我们提出的模型没有修改 Transformer 的任何原生组件。相比之下,组件的职责是完全颠倒的,据我们所知,这是唯一属于第四类的职责。我们相信原始模块的功能已经经受住了广泛领域的考验,事实是 Transformer 的架构采用不当。
3 ITRANSFORMER
在多元时间序列预测中,给定历史观测值 X = {x1, . 。 。 , xT } ∈ RT ×N 具有 T 个时间步长和 N 个变量,我们预测未来的 S 个时间步长 Y = {xT +1, . 。 。 , xT +S} ∈ RS×N 。为了方便起见,我们将 Xt,: 表示为在时间步 t 处同时记录的多变量,将 X:,n 表示为由 n 索引的每个变量的整个时间序列。值得注意的是,由于监视器的系统延迟和组织松散的数据集,Xt,: 在现实场景中可能不包含基本相同时间戳的时间点。 Xt,: 的元素在物理测量和统计分布方面可以彼此不同,而变量 X:,n 通常共享这些元素。
3.1 STRUCTURE OVERVIEW
我们提出的 iTransformer 如图 4 所示,利用 Transformer 的更简单的仅编码器架构(Vaswani 等人,2017),包括嵌入、投影和 Transformer 块。
将整个序列嵌入为令牌大多数基于 Transformer 的预测器通常将同一时间的多个变量视为(时间)令牌,并遵循预测任务的生成公式。然而,我们发现数值模态的方法对于以下方面的指导意义较小: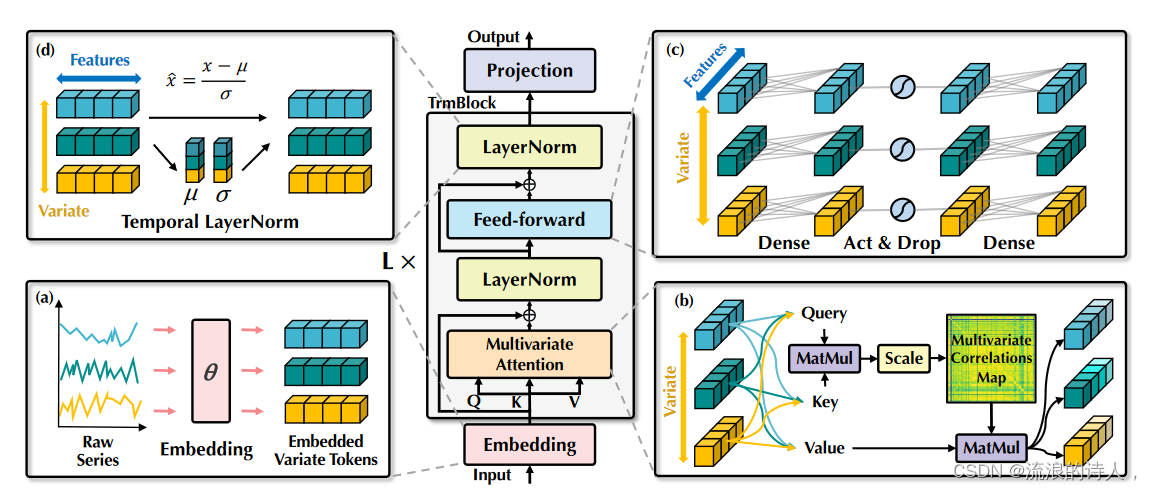
图 4:iTransformer 的整体结构,它与 Transformer 的编码器共享相同的模块化排列:(a) 不同变量的原始系列独立嵌入到令牌中。 (b) 将自注意力应用于嵌入式变量标记,增强可解释性,揭示多元相关性。 (c) 每个令牌的系列表示由共享前馈网络提取。 (d) 采用层归一化来减少变量之间的差异。
学习注意力图,这得到了补丁应用的支持(Dosovitskiy 等人,2021;Nie 等人,2023),拓宽了各自的领域。同时,线性预测器的胜利也挑战了采用重型编码器-解码器 Transformer 来生成令牌的必要性。相反,我们提出的仅编码器 iTransformer 专注于表示学习和多元序列的自适应关联。每个由底层复杂过程驱动的时间序列首先被标记化以描述变量的属性,通过自注意力应用进行相互交互,并由前馈网络单独处理以进行序列表示。值得注意的是,生成预测序列的任务本质上是交付给线性层,这已被之前的工作证明是有能力的(Das 等人,2023),我们在下一节中提供详细的分析。
基于以上考虑,在 iTransformer 中,基于回溯序列 X:,n 预测每个特定变量 ˆ Y:,n 的未来序列的过程简单表述如下: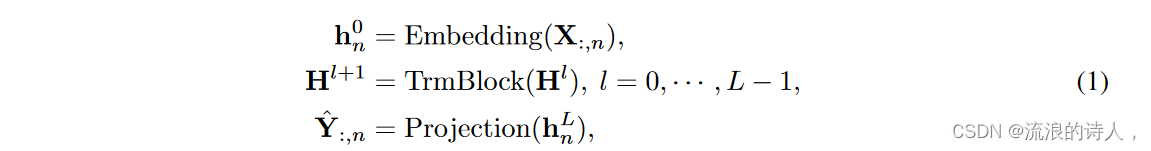
其中 H = {h1, · · · , hN } ∈ RN×D 包含 N 个维度为 D 的嵌入标记,上标表示层索引。嵌入:RT 7→ RD 和投影:RD 7→ RS 均由多层感知器(MLP)实现。获得的变量 token 通过 self-attention 相互交互,并由每个 TrmBlock 中的共享前馈网络独立处理。具体来说,由于序列的顺序隐式存储在前馈网络的神经元排列中,因此这里不再需要普通 Transformer 中的位置嵌入。
iTransformers 除了注意机制应适用于多元相关建模之外,所提出的架构本质上预设了对 Transformer 变体没有更多具体要求。因此,一系列有效的注意力机制(Li et al., 2021; Wu et al., 2022; Dao et al., 2022)可以作为插件,降低变量数变大时关联的复杂性。所提出的架构配备的 Transformer 变体(我们将其命名为 iTransformers)在第 4.2 节的实验中进行了广泛评估,并在时间序列预测方面展示了卓越的优势。
3.2 INVERTED TRANSFORMER COMPONENTS
我们组织了由本机层归一化、前馈网络和自注意力模块组成的 L 个块的堆栈。但他们在倒转维度上的职责应该仔细重新考虑。
Layer normalization Layer normalization(Ba et al., 2016)最初是为了提高深度网络的收敛性和训练稳定性而提出的。在典型的基于 Transformer 的预测器中,该模块对同一时间戳的变量表示进行标准化,逐渐使每个变量彼此无法区分。一旦收集到的时间点没有按时间对齐,操作也会在非因果或延迟过程之间引入交互噪声。在我们的反演版本中,归一化应用于个体变量的序列表示,如方程 2,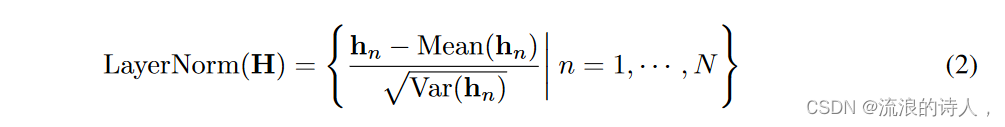
它已被研究并证明在解决非平稳问题方面是有效的(Kim 等人,2021;Liu 等人,2022b)。此外,由于所有系列(变量)标记都标准化为正态分布,因此可以减少由不一致的测量引起的差异。相反,在以前的架构中,不同的时间步标记将被标准化,导致序列过于平滑。
Feed-forward network
Transformer 利用前馈网络作为编码令牌表示的基本构建块,并且它同样应用于每个令牌。如上所述,在普通 Transformer 中,形成令牌的同一时间戳的多个变量可能会被错误定位,并且过于本地化,无法揭示足够的信息进行预测。在反向版本中,前馈网络在变量令牌的通道上发挥作用。通过通用逼近定理(Hornik,1991),他们可以提取复杂的表示来描述时间序列。通过倒置块的堆叠,它们致力于对观察到的时间序列进行编码,并使用密集的非线性连接对未来序列的表示进行解码,其工作原理与最近完全基于 MLP 构建的工作相同(Tolstikhin 等人,2021; Das 等人,2023)。更有趣的是,对独立时间序列的相同线性操作,作为最近的线性预测器(Zeng et al., 2023)和通道独立策略(Nie et al., 2023)的结合,可以帮助我们理解系列表示。最近对线性预测器的重新审视(Li et al., 2023)强调,由 MLP 提取的时间特征应该在不同的时间序列中共享。我们提出了一个合理的解释,即 MLP 的神经元被教导描绘任何时间序列的内在属性,例如幅度、周期性,甚至频谱(神经元作为滤波器),作为比 MLP 更有利的预测表示学习器在时间点上应用自注意力。通过实验,我们验证了分工有助于享受第 4.3 节中线性层的好处,例如如果提供扩大的回溯序列则可以提升性能,以及对未见变量的泛化能力。
Self-attention
虽然以前的预测器通常采用注意力机制来促进时间依赖性建模,但逆模型将一个变量的整个系列视为一个单独的过程。具体来说,通过全面提取每个时间序列的表示 H = {h0, . 。 。 , hN } ∈ RN×D,自注意力模块采用线性投影来获取查询、键和值 Q、K、V ∈ RN×dk ,其中 dk 是投影维度。将 qi, kj ∈ Rdk 表示为特定查询和一个(变量)标记的键,我们注意到前 Softmax 分数的每个条目都被公式化为 Ai,j = (QK⊤/√dk)i,j ∝ q⊤i kj。由于每个标记之前都在其特征维度上进行了标准化,因此条目可以在一定程度上揭示变量之间的相关性,并且整个得分图 A ∈ RN×N 展示了成对变量标记之间的多元相关性。因此,高度相关的变量将在下一次与值 V 的表示交互中获得更大的权重。基于这种直觉,所提出的机制被认为对于多元序列预测来说更加自然和可解释。我们在4.3节中进一步提供了得分图的可视化分析。
4 EXPERIMENTS
我们在各种时间序列预测应用程序上彻底评估了所提出的 iTransformer,验证了所提出框架的通用性,并进一步深入研究了特定时间序列维度上 Transformer 组件职责反转的影响
Datasets
我们在实验中广泛包含 6 个真实世界数据集,包括 Autoformer 使用的 ETT、天气、电力、交通(Wu 等人,2021)、LST 中提出的太阳能数据集并在 SCINet 中评估了 PEMS(Liu 等人,2022a)。我们还在附录E.2中提供了Market(6个子集)的补充实验,其中记录了支付宝在线交易应用程序的分钟采样服务器负载,具有数百个变量。数据集的详细描述参见附录 A.1。
4.1 FORECASTING RESULTS
在本节中,我们进行了大量的实验,以评估我们提出的模型以及高级基线的预测性能。
Baselines
我们精心选择了 10 个公认的预测模型作为基准,包括 (1) 基于 Transformer 的方法:Informer (Li et al., 2021)、Autoformer (Wu et al., 2021)、FEDformer (Zhou et al., 2022) )、Stationary (Liu et al., 2022b)、Crossformer (Zhang & Yan, 2023)、PatchTST (Nie et al., 2023); (2)基于线性的方法:DLinear(Zeng et al., 2023)、TiDE(Das et al., 2023); (3) 基于 TCN 的方法:SCINet (Liu et al., 2022a)、TimesNet (Wu et al., 2023)。
Main results
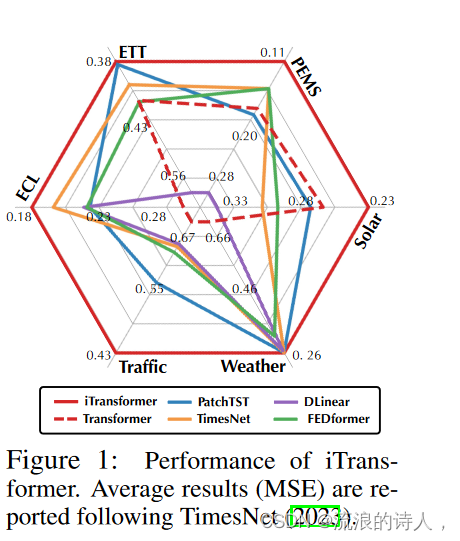
综合预测结果如表1所示,其中最好的为红色,次之为下划线。 MSE/MAE越低,表明预测结果越准确。所提出的 iTransformer 实现了一致的最先进性能。值得注意的是,PatchTST 作为之前电力和天气数据集上的最佳模型,在 PEMS 的许多情况下都失败了,这可以归因于数据集的剧烈波动序列,并且 PatchTST 的修补机制可能会失去对特定局部性的关注以应对快速波动。相比之下,我们提出的聚合系列表示的整个系列变化的方法可以更好地应对这种情况。此外,作为显式捕获多元相关性的代表,Crossformer 的性能仍然低于 iTransformer,这表明来自不同多元变量的时间未对齐补丁的交互会给预测带来不必要的噪声。因此,原生 Transformer 组件能够胜任时间建模和多元关联,并且所提出的倒置架构可以有效地处理现实世界的时间序列预测场景。
表 1:多元预测结果,PEMS 的预测长度为 S ∈ {12, 24, 36, 48},其他预测长度为 S ∈ {96, 192, 336, 720}。我们固定回溯长度 T = 96。所有结果都是所有预测长度的平均值。所有预测长度的结果在附录 E.2 中提供。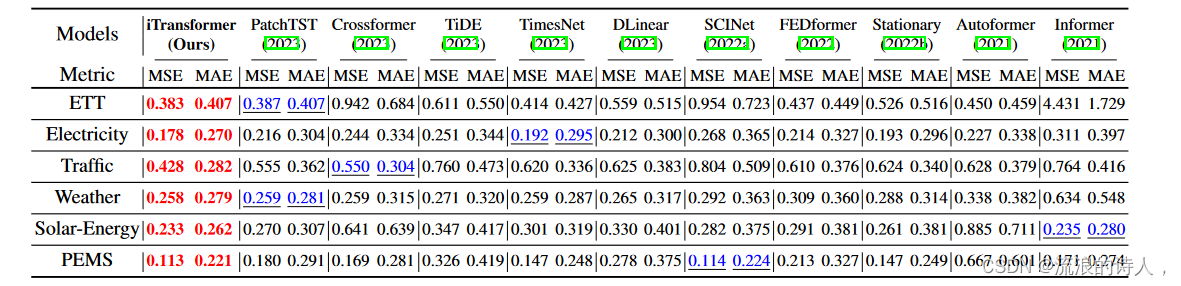
4.2 ITRANSFORMERS GENERALITY
在本节中,我们通过将我们的框架应用于 Transformer 及其变体来评估 iTransformers,这些变体通常解决自注意力机制的二次复杂性,包括 Reformer (Kitaev et al., 2020)、Informer (Li et al., 2021) 、Flowformer(Wu 等人,2022)和 FlashAttention(Dao 等人,2022)。展示了令人惊讶和有希望的发现,表明简单的倒置视角可以增强基于 Transformer 的预测器,提高性能、效率、对未见变量的概括以及更好地利用历史观测结果。
Performance promotion
我们根据表 2 中报告的性能提升来评估 Transformers 和相应的 iTransformers。值得注意的是,该框架持续改进了各种 Transformers。总体而言,它在 Transformer 上平均提升了 38.9%,在 Reformer 上平均提升了 36.1%,在 Informer 上提升了 28.5%,在 Flowformer 上提升了 16.8%,在 Flashformer 上提升了 32.2%,揭示了之前 Transformer 架构在时间序列预测上的不当使用。此外,由于在我们的倒置结构中的变量维度上采用了注意力机制,因此引入具有线性复杂度的高效注意力本质上解决了由于以下原因导致的效率问题:多种变量,这在现实应用程序中很普遍,但对于独立通道来说可能会消耗资源(Nie et al., 2023)。因此,iTransformer 的思想可以在基于 Transformer 的预测器上广泛实践,以利用蓬勃发展的高效注意力机制。
表 2:我们的倒置框架获得的性能提升。 Flashformer 是指配备了硬件加速 FlashAttention 的 Transformer(Dao 等人,2022)。我们报告平均性能和相对 MSE 降低(促销)。完整结果可在附录 E.2 中找到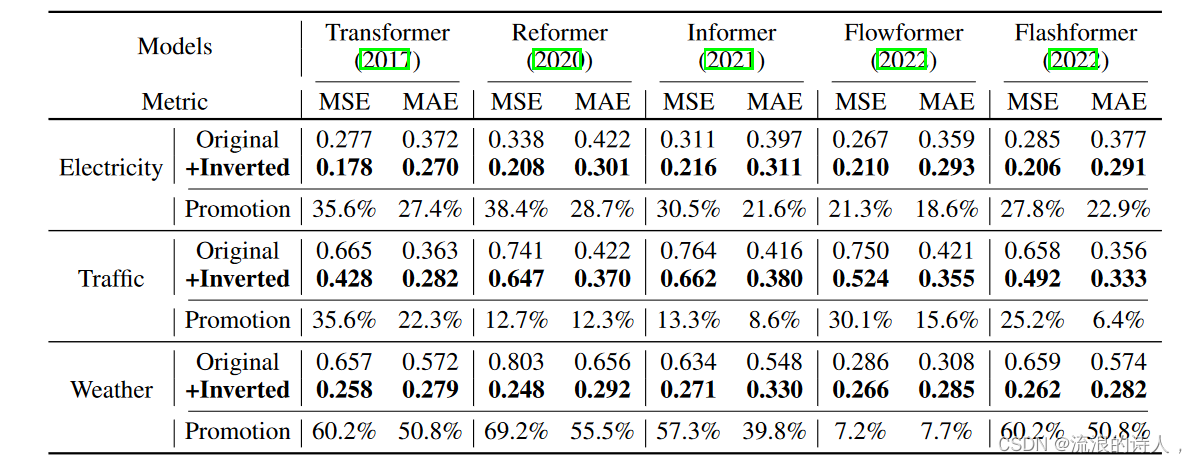
Variate generalization
通过反转普通 Transformer,值得注意的是,模型被赋予了对不可见变量的泛化能力。首先,受益于输入标记数量的灵活性,变量通道的数量不再受到限制,因此可以根据训练和推理进行变化。此外,前馈网络同样应用于 iTransformer 中的独立变量标记。如上所述,作为过滤器的神经元学习任何时间序列的内在模式,这些模式倾向于在不同变量之间共享。
为了验证这一假设,我们将 iTransformer 与另一种泛化策略进行比较:Channel Independent,它强制采用一个共享 Transformer 来学习所有变量的模式。我们仅使用每个数据集中 20% 的变量来训练模型,并直接在所有变量上测试训练后的模型,无需进行微调。如图 5 所示,虽然 Channel Independent (CI-Transformers) 的泛化误差可能会大幅增加,但 iTransformers 的预测误差增加要小得多。区别在于,在普通 Transformer 的注意力下进行的时间交互(被公认为数据依赖模块)对于未见的序列变化的可转移性较小,而前馈网络可以更熟练地进行这些变化
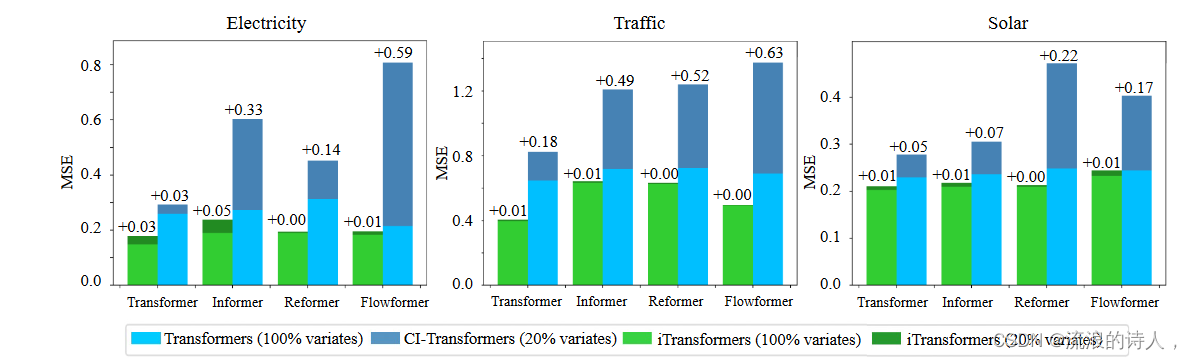
图 5:对未见变量的泛化性能。 iTransformers 可以自然地用 20% 的变量进行训练,并在几乎不增加误差的情况下完成对所有变量的预测,而具有通道独立性的 Transformers 会导致误差显着增加。
Increasing lookback length
之前的一些工作已经观察到 Transformers 的预测性能并不一定会随着回溯长度的增加而提高的现象(Nie et al., 2023; Zeng et al., 2023),这可以归因于对不断增长的回溯长度的注意力分散。输入。然而,期望的性能改进通常基于线性预测,理论上得到统计方法(Box & Jenkins,1968)的支持,并扩大了历史数据要利用的信息。由于注意力网络和前馈网络的职责是相反的,我们评估了图 6 中 Transformer 和 iTransformer 的性能,增加了回溯长度。结果令人惊讶地验证了在时间维度上利用 MLP 的合理性,使得 Transformer 可以从扩展的回溯窗口中受益,以实现更精确的预测。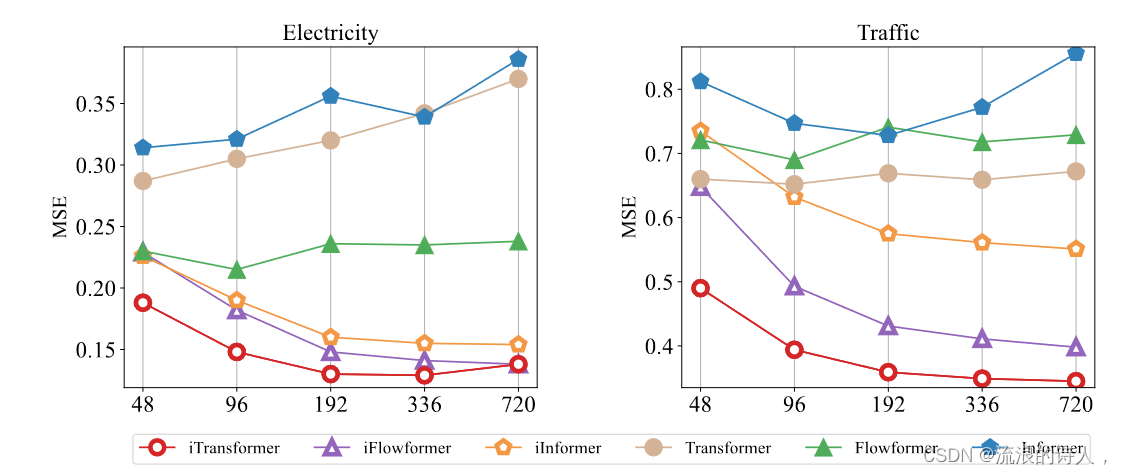
图 6:回溯长度 T ∈ {48, 96, 192, 336, 720} 和固定预测长度 S = 96 的预测性能。虽然基于 Transformer 的预测器的性能不一定会受益于回溯长度的增加,但我们的反演框架使普通 Transformer 及其变体在扩大的回溯窗口上具有改进的性能。
4.3 MODEL ANALYSIS
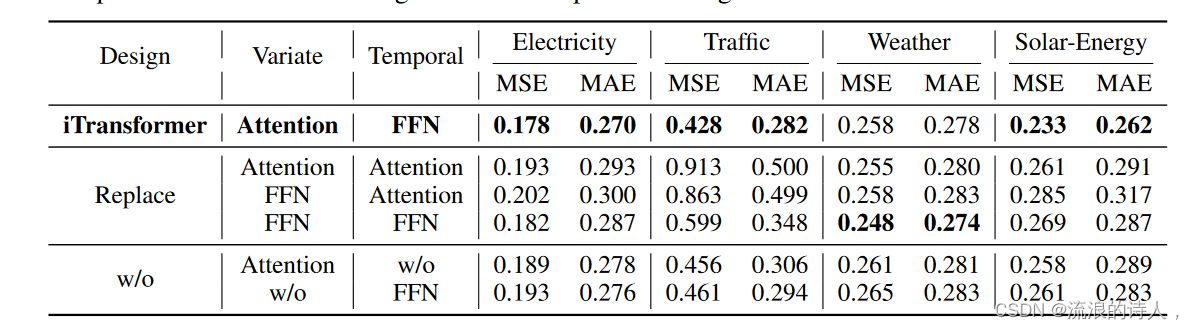
Ablation study 为了验证 Transformer 组件的合理性,我们提供了详细的消融,涵盖替换组件(Replace)和移除组件(w/o)实验。结果列于表 3 中。利用变量维度的注意力和时间维度的前馈的 iTransformer 通常可以获得最佳性能。值得注意的是,vanilla Transformer(第三行)的性能在这些设计中表现最差,这表明采用传统架构进行时间序列预测时责任不一致。
表 3:iTransformer 上的消融。除了组件删除之外,我们还替换各个维度上的不同组件以学习多元相关性(变量)和序列表示(时间)。此处列出了所有预测长度的平均结果。
Analysis of series representations 为了进一步验证前馈网络更适合提取序列表示的说法。我们基于中心核对齐(CKA)相似性进行表示分析(Kornblith 等人,2019)。 CKA 越高表示相似的表示越多。对于 Transformer 变体和 iTransformers,我们计算第一个块和最后一个块的输出特征之间的 CKA。值得注意的是,之前的工作已经证明,时间序列预测作为一种低级生成任务,更喜欢较高的 CKA 相似度(Wu et al., 2023;Dong et al., 2023)以获得更好的性能。如图7所示,显示出清晰的划分线,这意味着iTransformers通过反转维度学习了更合适的序列表示,从而实现了更准确的预测。结果还表明 Inverting Transformer 值得对预测主干进行根本性革新。
Analysis of multivariate correlations
通过将多元相关性的任务分配给注意力机制,学习到的地图能够增强可解释性。我们在图 7 中展示了 Soloar-Energy 系列的案例可视化,它在回顾窗口和未来窗口中具有明显的相关性。可以清楚地观察到,在浅层注意力层中,学习到的图与原始输入序列的相关性有很多相似之处。随着深入到更深的层次,学习到的图逐渐变得与未来序列的相关性相似,这验证了反转操作赋予了可解释的关联注意力,并且编码过去和解码未来的过程本质上是在序列表示中进行的。前馈。
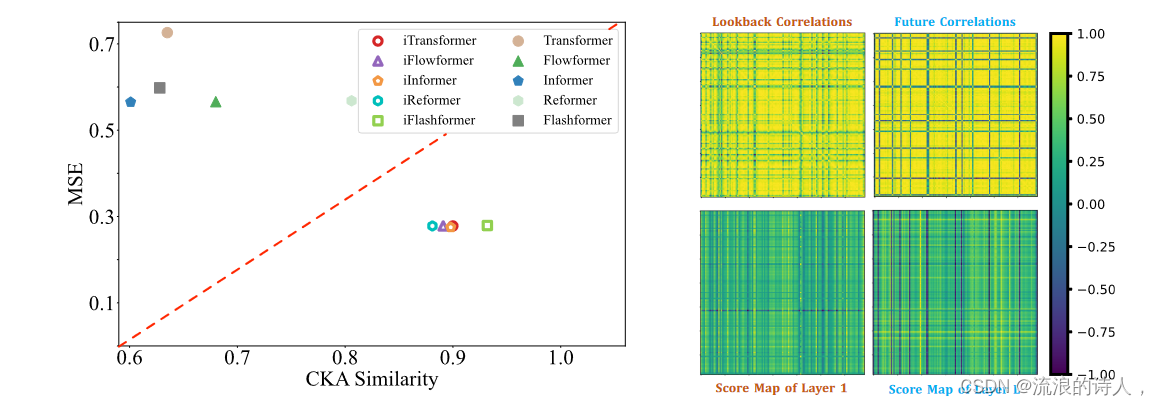
图 7:系列表示和多元相关性分析。左:Transformers 和 iTransformers 之间表示的 MSE 和 CKA 相似性比较。 CKA 相似度越高,表示越有利于准确预测。右:原始时间序列和通过反向自注意力学习的分数图的多元相关性的案例可视化。
Efficient training strategy
在所提出的 iTransformer 中,由于自注意力的二次复杂性,当变量增长众多时,训练可能会变得难以承受。除了有效的注意力机制之外,我们还利用先前演示的变量生成能力,提出了一种新的高维多元序列训练策略。具体来说,我们在每批中随机选择部分变量,并仅使用选定的变量来训练模型。由于我们的反转,变量通道的数量是灵活的,因此模型可以预测所有变量进行预测。如图 8 所示,我们提出的策略的性能仍然与全变量训练相当,同时内存占用可以显着减少。
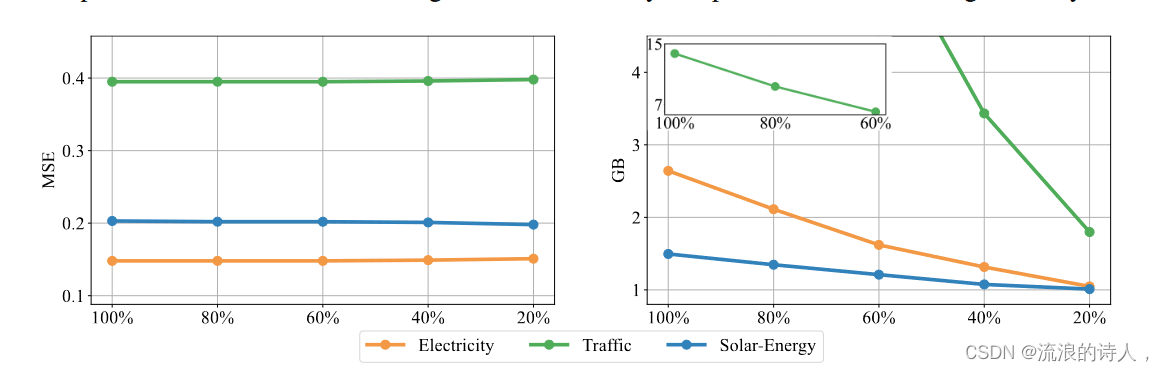
图 8:对所提出的培训策略的分析。虽然采样比例为 {20%, 40%, 60%, 80%, 100%} 的每个批次的部分训练变量的性能(左)保持稳定,但训练过程的内存占用(右)可以减少显着关闭。
5 CONCLUSION AND FUTURE WORK
在本文中,我们指出 Transformer 的普通架构不适合发现时间序列预测的基本序列表示和多元相关性。因此,我们建议 iTransformer 作为最低限度适应时间序列的基本骨干,其原生组件自然地解决倒维问题。在实验上,iTransformer 实现了最先进的性能,并在有前景的分析的支持下展现了卓越的框架通用性。未来,我们将探索 iTransformers 来完成广泛的时间序列分析任务。

















 1114
1114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









