








Abstract
Facebook、Twitter、微信等在线社交网络已成为主要的社交工具。用户不仅可以与家人和朋友保持联系,还可以发送和分享即时信息。但在一些实际场景中,我们需要采取有效措施来控制网络谣言等负面信息的传播。在本文中,我们首先提出了谣言影响最小化(MIR)问题,即选择具有 k 个节点的阻止者集 B,使得谣言源集 S 的用户总激活概率最小化。然后,我们采用经典的独立级联(IC)模型作为信息扩散模型。基于IC模型,我们证明了目标函数是单调递减且非子模的。为了有效解决 MIR 问题,我们提出了一种两阶段方法,为通用网络生成候选集并选择阻塞器。此外,我们还研究了树网络上的 MIR 问题,并提出了保证最优解的动态规划。最后,我们分别通过对合成和现实生活社交网络的模拟来评估所提出的算法。实验结果表明,我们的算法优于比较启发式方法,例如出度、介数中心性和 PageRank。
索引术语——社交网络、谣言拦截、子模块性、贪婪算法、动态规划。
I. INTRODUCTION
随着互联网和计算机技术的进步,一些重要的社交网络已广泛融入我们的日常生活,例如Facebook、Twitter、Google+和微信。社交网络通常可以表示为节点和边的复杂网络,其中节点表示用户(人、组织或其他社交实体),边表示用户之间的社交关系(友谊、协作或信息交互)。这些在线社交网络中的用户不仅可以传播积极的内容(想法、意见、创新、利益等),也包括谣言等负面信息。事实证明,谣言传播速度非常快,并造成严重后果[1]。例如,2017年10月加州发生毁灭性山火时,当警察疏散居民并在被烧毁的房屋废墟中寻找失踪人员时,他们仍然不得不应对假新闻。尽管该谣言随后被警方驳回,并被一些政府网站揭穿,但最初的故事被转发了 6 万次,类似的故事在 Facebook 上被转发了 7.5 万次。
为了提供优质的服务和准确的信息,制定有效的策略来阻止或限制此类谣言的负面影响至关重要。限制谣言在社交网络中的传播是一个热门但具有挑战性的研究课题[2]。目前,谣言拦截相关文献大致可分为以下三类:(1)有影响力的节点进行谣言拦截。该方法通常根据一定的标准选择网络中最有影响力的节点,并将这些有影响力的节点从原始网络中删除,从而限制谣言的传播,例如[3][7]; (二)抓住重点辟谣。该方法通常会删除一组在信息传播中起关键作用的边,从而尽可能减少谣言的传播[8]-[12]; (3)传播正面信息(如真相),澄清谣言。该方法基于这样的假设:用户一旦接受了肯定的事实就不会接受谣言。更具体地说,它识别节点的子集并传播正面信息,以使正面信息被尽可能多的用户采用[13]-[16]。
在本文中,我们研究了一种新颖的最小化谣言影响(MIR)问题来限制谣言传播,即,我们想要识别具有 k 个节点的集合 B 并从原始网络中删除该集合,使得节点的总激活概率修改网络上的谣言源集 S 被最小化。我们将节点 v 2Ba 拦截器称为“节点 v 2Ba 拦截器”。为了有效地解决 MIR 问题,我们提出了一种两阶段方法 GCSSB,包括生成候选集(GCS)和选择阻止者(SB)阶段。具体来说,在GCS阶段,我们对网络上的节点进行排序,找到传播谣言能力最强的前k个节点,其中a是阈值参数。我们通过这 k 个节点生成候选的阻塞者集 C。在SB阶段,我们设计了一个基本的贪心算法,根据最大边际增益从先前的候选集C中选择k个节点。不同的是在之前的研究中,我们在设计基本的贪心算法之前有一个预处理阶段。优点是可以有效减少贪心算法的时间消耗。换句话说,我们基于候选集C而不是原始网络从子图中识别阻塞集。此外,我们还探讨了树形网络等特殊结构中的 MIR 问题。
我们总结我们的主要贡献如下:
我们形式化了谣言影响最小化(MIR)问题,并证明目标函数在独立级联(IC)模型下不是子模的。
我们首次提出了一种名为 GCSSB 的两阶段策略来解决一般社交网络上的 MIR 问题。
我们还研究了树等特殊网络上的 MIR 问题,并提供了动态规划算法来保证最优解。 为了评估所提出的算法,我们在实验中使用了一个合成的和三个不同规模的现实生活社交网络。
此外,我们将所提出的方法与其他启发式方法进行比较。实验结果证明我们的方法优于其他方法。
本文的其余部分安排如下。我们首先回顾一下第二节中现有的一些谣言拦截的相关工作。然后我们在第三节介绍信息扩散模型。我们在第四节中展示了问题描述和属性。第五节介绍了通用网络的算法。第六节提出了树形网络的动态规划算法。我们在第七节中分析和讨论实验结果。最后,我们在第八节中得出结论。
II. RELATED WORK
多明戈斯等人。 [17]首先研究了社交网络中用户之间对于营销的影响。肯佩等人。 [18]将病毒式营销建模为离散优化问题,称为影响力最大化(IM)。他们提出了一种具有 (1 1=e) 近似比的贪心算法,因为该函数在独立级联 (IC) 或线性阈值 (LT) 模型下是子模的。基于 Kempe 的贡献,近年来人们在信息传播建模方面做出了大量努力,例如[19]-[21]。
A. Blocking Nodes for Rumors
在[3]中,Fan 等人。研究一个问题,将最小的个人子集确定为初始保护者(节点用于限制谣言的不良影响。),以最大限度地减少两个扩散过程结束时邻近社区的感染人数。作者提出了机会主义一激活一和确定性一激活多模型下的算法,并详细展示了理论分析。在[4]中,王等人。解决谣言影响最小化问题。他们假设出现谣言并影响社交网络中的某些用户。和他们希望通过发现 k 个未受感染的用户来最大限度地减少最终受感染的用户规模。提出了一种简单的贪心方法。不幸的是,他们没有理论分析。在社交网络中,如何识别有影响力的传播者对于谣言至关重要。马等人。在[5]中提出了一个重力中心性指数来识别复杂网络中有影响力的传播者,并将它们与一些众所周知的中心性(例如程度、介数、接近度等)进行比较。
B. Blocking Links for Rumors
在[8]中,木村等人。提出一种方法(通过阻止有限数量的链接)来有效地找到谣言阻止的良好近似解决方案。在[9]中,Khalil 等人。将流感控制问题抽象为边缘删除问题。他们表明这个问题在 LT 模型下是超模块化的。基于这一特性,他们设计了一种具有近似保证的可扩展算法。在[10]中,Tong等人。提出有效且可扩展的算法来解决传播问题,并回答应该删除哪些边缘以遏制谣言。
C. Spreading Positive Truth for Rumors
在[13]中,Budak 等人。研究在网络中同时传播的两个相互竞争的活动(谣言和真相)。他们解决了限制谣言传播的问题。换句话说,他们希望识别一个个体子集来传播真相,以便网络中尽可能多的节点在两个传播过程结束时采用真相而不是谣言。他们证明这个问题是 NPhard 问题并提供了贪婪算法。在[14]中,Tong等人。研究谣言拦截问题,要求k个种子用户触发正向级联的传播,使得不受谣言影响的用户数量最大化。他们提出了一种随机近似算法,事实证明该算法在运行时间方面优于最先进的方法。
D. Studies in the Tree Network
基于树网络的社会影响问题也引起了人们的关注,如[22]、[23]。在[22]中,拉帕斯等人。考虑选择一组 k 个活动节点来解释给定信息传播模型下观察到的激活状态的问题。他们表明,在树中,这个问题可以通过动态规划在多项式时间内解决。巴拉蒂等人。在[23]中,研究了当多家公司使用病毒式营销营销竞争产品时,多重竞争创新扩散的博弈。他们给出了一个 FPTAS,用于解决当底层图是树时最大化单个玩家的影响力的问题。
在本文中,我们分别研究了一般网络(非树网络)和树网络上的 MIR 问题。我们发现MIR问题很难在一般网络上找到最优解,并提出了两阶段算法。另一方面,我们证明了 MIR 问题可以在树形网络上找到最优解并提出动态规划算法。
III. INFORMATION DIFFUSION MODEL
在本节中,我们简要介绍影响扩散模型:[18]首先提出的独立级联(IC)模型。给定一个有向社交网络,可以用图 G 1⁄4ðV 表示; E; pÞ,V表示用户(节点集),E V V表示用户之间的关系(边集),边的puv ðu; vÞ 表示节点 u 激活 v 的概率。如果一个节点采用了其他节点的信息(谣言),我们称该节点为活跃节点,否则为非活跃节点。影响传播过程展开离散时间步 ti,其中 i 1⁄4 0; 1; :::; n 和 n 是 G 中的节点数。
更具体地说,令 St0 为谣言的初始源节点,即种子集。令 Sti 表示时间步 ti 中的活动节点,并且 Sti 中的每个节点 u 有一次机会通过其出边 ðu 激活每个不活动邻居 v; vÞ 的概率为 puv,时间步 tiþ1。重复此过程,直到不再有新的节点可以被激活。请注意,节点只能从非活动状态切换到活动状态,而不能从相反方向切换。
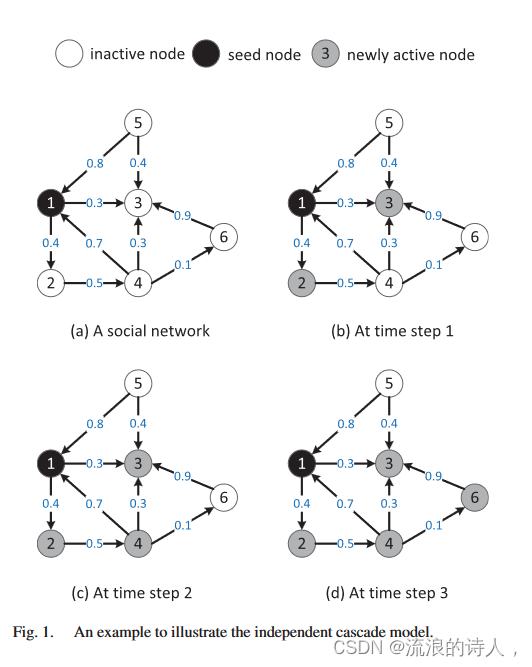
图1中有一个例子详细说明了独立级联模型。图中的节点有三种状态:不活动、活动和新活动。每条边上嵌入的数字 ðu; vÞ 表示传播概率,例如,边 (4,6) 上的 0.1 表示节点 4 激活节点 6 的概率。特别是,在时间步 0 时,只有种子节点处于活动状态,其他节点处于不活动状态。 1(a) 显示了一个简单的社交网络,其种子节点为 1。tep 0。此时,活动种子节点 1 尝试激活其不活动邻居(节点 2 和节点 3)。在时间步 1,我们可以观察到节点 2 和节点 3 在图 1(b) 中重新变为活动状态 1。此时,新的活动节点2和节点3分别激活自己的不活动邻居。然后节点4在图1(c)中变得活跃。类似地,在时间步长 2,新的活动节点 4 尝试激活其不活动的邻居,即节点 6。最后,节点 6 在时间步长 3 变得活动。此外,信息传播过程停止,因为不再有节点可以被激活。活性。
IV. PROBLEM DESCRIPTION AND PROPERTIES
A. Problem Description
给定一个有向社交网络 G 1⁄4ðV; E; pÞ,信息扩散模型M和谣言源集合S,V表示用户集合,E V V表示用户之间的关系,边ðu的puv; vÞ 表示 u 成功激活 v 的概率。我们定义模型M下种子集S对节点v 2 V的激活概率如下等式。
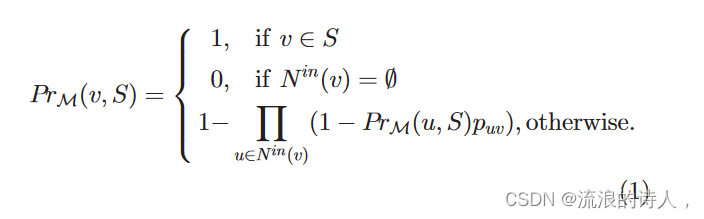
其中 NinðvÞ 是 v 和 PrMðu 的内邻居集合; SÞpuv表示在扩散模型M(这里,M是IC模型)下u成功激活v的概率。我们可以清楚地看到,节点 v 的激活概率取决于其邻居 u。这里以节点1激活节点4为例来说明如何计算图1中的激活概率,即PrMð4; f1gÞ。
根据式(1),我们有

其中 Ninð4Þ1⁄4f2g 和方程 (2) 可以转换为以下方程

其中 PrMð1; f1gÞ 1⁄4 1,因为节点 1 是种子节点,p12 1⁄4 0:4。因此,PrMð2; f1gÞ 1⁄4 0:4。添加PrMð2; f1gÞ 1⁄4 0:4 代入式(3),得 PrMð4; f1gÞ 1⁄4 1 ð1 0:4 0:5Þ1⁄40:2
现将问题描述如下。
定义 1:最小化谣言影响 (MIR)。给定一个有向社交网络 G 1⁄4ðV; E; pÞ、谣言源集 S、正整数预算 k 和 IC 模型 M,MIR 旨在找到具有 k 个节点的阻止者集 B,使得
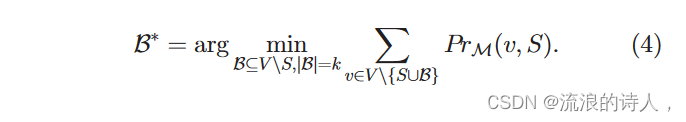
图2展示了在独立级联模型下,如果我们只选择一个节点(k 1⁄4 1)作为阻塞者,如何计算目标函数值。为了便于说明,我们让节点 7 为谣言种子,网络中每条边的传播概率为 12。更具体地说,图 2(a) 显示了一个简单的社交网络。我们计算以下两种情况:(1)选择节点1作为阻塞集合B(见图2(b)); (2)选择节点3作为阻塞集合B(见图2(c))。

图 2. 计算 k 1⁄4 1 时目标函数值的示例。(a) 显示了一个简单的社交网络,其中黑色实心节点表示谣言源 S 1⁄4f7g。 (b) 显示选择节点 1 作为阻塞者。 (c) 显示选择节点 3 作为阻塞者。
在第一种情况下,图2(d)-(f)显示了当我们选择节点1作为阻塞者时的信息传播过程。请注意,一旦节点成为阻止者,它将不会被激活。在时间步 0,节点 7 尝试激活其不活动的邻居。在时间步 1,节点 4 变得活跃,因为传播概率为 1。并且节点 4 准备好激活其不活跃的邻居。在时间步骤2,节点6变得活跃并且信息传播过程停止。结果,我们观察到除了种子节点之外,还有两个节点(节点 4 和节点 6)成为新的活动节点。因此总激活概率 P v2V nfS[Bg PrMðv; SÞ1⁄42。
在第二种情况下,图2(g)-(i)显示了当我们选择节点3作为阻塞者时的信息传播过程。在时间步 0,节点 7 尝试激活其不活动的邻居。在时间步 1,节点 1 和节点 4 变得活跃,因为传播概率为 1。节点 1 和节点 4 尝试激活其不活跃的邻居。在时间步 2,节点 2 和节点 6 变为活动状态,信息传播过程停止。因此,有四个节点变为活动状态(节点 1、节点 2、节点 4 和节点 6)。因此总激活概率 P v2V nfS[Bg PrM ðv; SÞ1⁄44。综上所述,对于 MIR 问题,选择节点 1 作为阻塞者而不是节点 3 更为合适。
B. Properties of Objective Function
定理1:目标函数(4)在IC模型下是单调递减的并且不是子模的。证明:如果每当 A B 时 fðAÞ fðBÞ ,则集合函数 f 是单调递减的。很明显,在我们的 MIR 问题中,目标函数是单调递减的,因为我们选择的阻塞器越多,目标函数就越小。我们省略它的证明。
然后我们证明目标函数不是子模的。如果 V 是有限集,则子模函数是集合函数 f :2V !<,其中 2V 表示 V 的幂集,满足以下条件:对于每个 A B V 和 x 2 V nB,fðA [fxgÞ fðAÞ fðB [fxgÞ fðBÞ。回到图 2 中提到的例子,我们让谣言种子 S 1⁄4f7g, f 1⁄4P v2V nfS[Bg PrMðv; SÞ,A 1⁄4f4g,B 1⁄4f3; 4g 和 x 1⁄4 f1g。ThefðAÞ 意味着我们选择节点 4 作为阻塞集合 B。在这种情况下,我们分析信息传播过程。在时间步 0,节点 7 激活节点 1。在时间步 1,节点 1 变为活动状态并尝试激活其不活动的邻居。在时间步 2,节点 2 和节点 3 变为活动状态,并且它们尝试激活其不活动的邻居。在时间步 3,节点 5 变为活动状态并尝试激活其不活动邻居。在时间步骤4,节点6变得活跃并且信息传播过程停止。最后,我们可以看到有五个节点变得活跃,即 fðAÞ1⁄45。类似地,我们计算 fðA [fxgÞ 1⁄4 0、fðBÞ1⁄42 和 fðB [fxgÞ 1⁄4 0]。因此 fðA [fxgÞ fðAÞ <fðB [fxgÞ fðBÞ 表示 MIR 的非子模性。
V. ALGORITHM FOR THE GENERAL NETWORK
在本节中,我们提出了一种两阶段方法 GCSSB,其中包括生成候选集和选择阻塞阶段。我们分别在第 V-A 节和第 V-B 节中介绍它们。
A. Generating Candidate Set

图 3. 传播概率 p 1⁄4 0:5 的示例。 (a) 显示相邻矩阵,其中 Aij 1⁄4 0:5 表示存在从 i 到 j 的有向边。 (b) 显示如何计算 s。
给定一个有向社交网络 G 1⁄4ðV; E; pÞ 和谣言源集 S,我们首先对网络上的节点进行排序。排序的目的是确定候选阻塞者集合,减少第二阶段贪心算法的耗时。直观上,我们会选择传播能力强的节点作为阻塞者,而不是那些传播能力弱的节点。因此,如何衡量节点的传播能力成为一个关键问题。这里,我们定义一个向量 s 1⁄4 I × AI × :::ArI,其中 A 表示网络的邻接矩阵,I 表示单位列向量,1 r jV j 。众所周知,Airj表示i通过长度为r的路径激活j的近似概率。因此 s 表示其总概率。例如,图 3(a) 显示了当网络中每条边的传播概率 p 1⁄4 0:5 时图 2 中网络的邻接矩阵。图 3(b) 显示 s 1⁄4 I × AI × :::ArI 1⁄4 ð3:938; 3:531; 2:5; 1:5; 1:5; 1; 3:656ÞT 其中 r 1⁄4 5。我们按降序对 s 进行排序。然后我们得到排列 P 1⁄4ð3:938; 3:656; 3:531; 2:5; 1:5; 1:5; 1ÞT 并选择前 k 个节点作为阻塞者 C 的候选集,其中 a 是阈值参数(在实验部分,我们将参数 a 设置为 1 到 10)。与前面提到的例子一致,我们应该选择节点 1 作为阻塞者而不是节点 3,因为当预算 k 1⁄4 1 时,s1 1⁄4 3:938 > s3 1⁄4 2:5。
B. Selecting Blockers
在第V-A小节中,我们首先确定阻塞者C的候选集。在本小节中,我们介绍如何根据候选集C中的最大边际增益准确地选择k个阻塞者。具体来说,我们提出了一种基于最大边际增益的贪心算法边际收益。我们给出边际收益的定义如下。定义 2:(边际收益)。给定一个有向社交网络 G 1⁄4ðV; E; pÞ,谣言源集 S 和信息扩散模型 M,对于任意节点 x 2 V nS,令
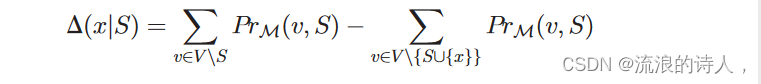
是 S 相对于 x 的边际增益。显然,我们的算法关注的是候选C中节点的最大边际增益。我们定义了以下定义3:(最大边际增益)。对于任何节点 x 2C,令是 S 相对于 x 的最大边际增益。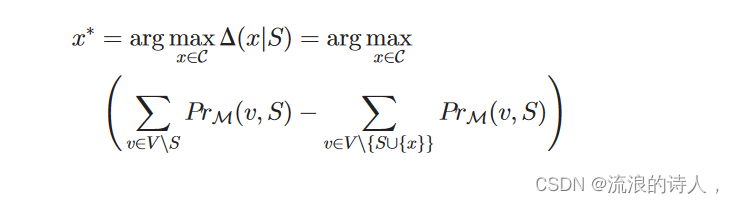
基于上述定义,我们提出了贪心算法。我们首先从空集开始,即 B1⁄4;。然后,在第 t 次迭代中,我们将边际增益最大的节点 xt 添加到当前 B 中。算法执行 k 次,直到选择 k 个阻塞者。贪心算法如算法1所示。

我们来分析一下算法1的复杂度。第2行到第9行的循环最多运行k次。在每次迭代中,内部循环最多运行 jCj 次,并且最多花费 OðjEjÞ 时间来计算 DðxjSÞ。因此,最坏情况下的总时间复杂度为 OðkjCjjEjÞ。
VI. ALGORITHM FOR THE TREE NETWORK
在本节中,我们考虑特殊网络(例如树)上的 MIR 问题。原因如下: (1) 在树形网络中计算节点的激活概率非常容易; (2) 我们还表明,在树中,可以使用有效的动态规划方法来解决 MIR 问题。我们相信在树中找到阻碍者可以提高对信息传播过程的理解。
A. Calculating Activation Probability
在这一部分中,我们将展示当输入图是树时如何通过谣言种子集 S 计算节点 v 的激活概率。请注意,我们在上一节中给出了一般图上节点的激活概率计算公式,即方程(1)。我们将式(1)修改如下。定义4:给定一棵有向树T 1⁄4ðV; E; pÞ,谣言种子集 S V 和 IC 模型 M,对于任何节点 v 2 T ,设 PrMðv; SÞ 是节点 v 被种子集 S 激活的激活概率。那么我们有
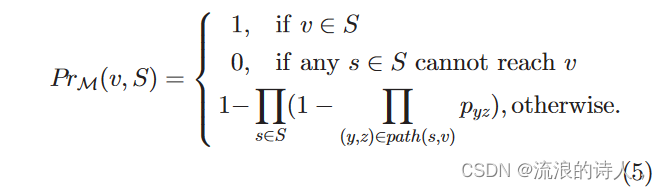
哪里路径; vÞ 表示从节点 s 到节点 v 的路径。
树上的节点v根据是否存在有向路径pathðs而被激活; vÞ 从种子集中的节点 s 到节点 v。术语 Q s2Sð1 Q ðy;zÞ2pathðs;vÞ pyzÞ 表示种子集中的所有节点都无法激活节点 v 的概率。因此节点 v 可以被激活的概率激活值等于 1 减去此项。
B. Dynamic Programming Algorithm
在本小节中,我们将探讨有向树 T 1⁄4ðV 上的 MIR 问题; E; pÞ 当给定谣言种子集 S 时。关键问题是:如何在以根节点为种子节点的子树上选取阻塞节点。为了解决这个问题,我们提出了一种动态规划算法,包括两个步骤:(1)将普通树转换为二叉树; (2)实现动态规划。
将普通树转换为二叉树。让 Tv 成为一棵子树。 Tv 的根是节点 v,v 有 u 个子节点。在该子树上指定最多 k0 (k0 k) 个阻塞器的最佳方法是在此子树上分配 k0 个阻塞器,以最小化总激活概率。然而,当 u 为 2 时,计算所有可能的分配是昂贵的。为了解决这个问题,我们将以 v 为根的原始三个 Tv 转换为以 v 为根的二叉树 BTv。此外,我们将证明这种转换有利于制定动态编程。

图 4. 从普通树到二叉树的转换。 (a)显示了通用树Tv0,(b)显示了变换后对应的二叉树BTv0。
在图4中,我们给出了一个例子来展示转换过程。图4(a)显示了以v0为根的通用树Tv0,图4(b)显示了变换后以v0为根的相应二叉树BTv0,其中虚线箭头和虚线节点表示新添加的有向边和节点。我们做一个简单的改造如下:
通用树Tv0的根节点v0仍然是二叉树BTv0上的根节点v0;
假设 v 是一般树 Tv0 的任意节点,有 u 个子节点 y1,y2,...,yu。我们将节点 v 替换为高度不超过 log 2u 的二叉树,该二叉树的叶子节点为 y1, y2,..., yu。对于出度大于2的节点,在普通树上进行上述替换过程。
图4(a)中,普通树Tv0的根节点v0仍然是图4(b)中二叉树BTv0上的根节点。我们观察到节点 v1 有四个子节点 v2、v3、v4 和 v5。(例如,u 1⁄4 4 大于 2)。因此,我们将节点 v1 替换为高度不超过 log 2 4 1⁄4 2 的二叉树,该二叉树的叶子节点为 v2、v3、v4 和 v53。在本例中,我们添加两个虚线节点 x1 和 x2。我们还添加两个虚线有向边 ðv1;x1Þ 和 ðv1;x2Þ。我们让从节点 v1 到 x1 的传播概率为 1。此外,应保留实体有向边,例如有向边 ðv1;x1Þ 替换为有向边 ðx1;v2Þ。类似的操作可以应用于其他边,例如 ðv1;v3Þ、ðv1;v4Þ 和 ðv1;v5Þ。此外,我们对节点 v3 进行类似的转换,因为它有三个子节点。最后,二叉树如图4(b)所示。
引理 1:给定一般树 T 1⁄4ðV; E; pÞ,对于任何节点 v 2 V 且有 u 个子节点 y1, y2,..., yu,则替换节点 v 的二叉树 BTv 的高度不超过 log 2 u。证明:我们假设v是二叉树BTv的第0层,那么第1层最多有2个叶子节点,第2层最多有4个叶子节点,以此类推。因此,log 2 u层有u个叶子节点。 & 引理2:令jV j 为一般树T 1⁄4ðV 上的节点数; E; pÞ 和 jV 0j 分别为相应二叉树 BT 1⁄4ðV 0;E0;p0Þ 上所有节点的数量。那么我们有 jV 0j 3jV j。
证明:为了便于阐述,我们将通树T 1⁄4ðV中的节点进行划分; E; pÞ 分为两类: (1) 集合D,即子节点数小于或等于2的节点; (2) 集合VD,即子节点数量大于2的节点。对于第一类,我们让jDj表示集合D的大小。并且我们不需要替换操作,所以数量这些节点的数量是相同的。对于第二类,我们让jV Dj 表示集合V D 的大小。但是,我们需要替换操作。基于以上分析,我们有
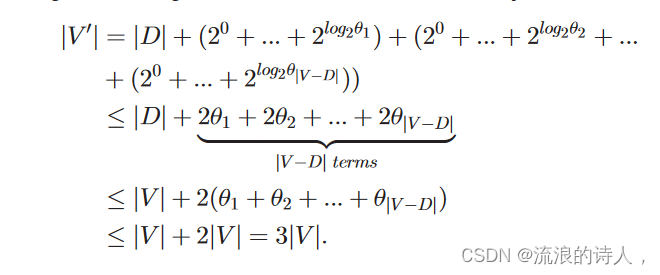
我们假设 V D 中的节点分别有 u1、u2、...、ujV Dj 子节点。
实施动态规划。回想一下,我们有一个阻碍性预算 k。我们动态规划算法的本质是研究如何在二叉树上选择阻塞器以最小化目标函数(总激活概率)。令 lðvÞ 或 rðvÞ 为 v 的左子或右子,其中 v 2 BT 。让 OPT ðv; B;kÞ 以节点 v 为根的子树中具有 k 个阻碍者且 B 将阻碍者保留在当前解决方案中的概率。从该子树中选择k个阻塞者的最佳方式必须属于以下两种模式之一: (1)选择该子树的根节点和子节点(包括根节点)中的k 1 个节点; (2)选取子节点中的k个节点(不包括根节点)。基于上述分析,当谣言种子集为S时,我们对节点v 2 BT提出如下动态规划。

在等式(6)中,术语 mink k01⁄40f g 表示我们不选择根节点,而是从根节点的子节点中选择 k 个阻塞者。还有 Prðv 一词; S; BÞ 表示节点 v 被种子集 S 激活的概率。我们将指示变量 I1 v 定义为
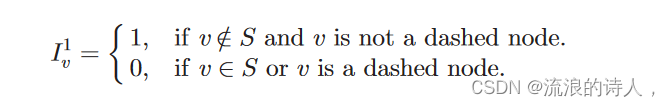
术语 mink 1 k01⁄40f g 表示我们选择根节点并从子节点中选择 k 1 个阻塞者。为了保证新添加的虚线节点不能被选中,我们将指示变量I2 v定义为

从上面的动态规划,我们有以下推论。推论1:动态规划可以找到MIR问题的最优解,二叉树上的最优解与普通树上的最优解等价。
C. Case Study
在本小节中,我们提供预算 k 1⁄4 2 时的案例研究。在图 4 中,不失一般性,我们让节点 v3 为谣言种子节点,即 S 1⁄4fv3g。让我们首先分析原始e上的最优解,然后使用动态编程方法来分析二叉树上的最优解。
在原始树上,种子节点 v3 能够以 0.2、0.5、0.8 和 0.12 的概率激活节点 v6、v7、v8 和 v9。因此,我们应该选择节点 v7 和节点 v8,使得总概率 P v2V nfS[Bg PrCðv; SÞ1⁄40:2þ 0:12 1⁄4 0:32 被最小化。换句话说,MIR问题的最优解是B1⁄4fv7;v8g。
根据动态规划,我们的目标是
由于 v3 是谣言种子节点,因此节点 v3 无法被选入阻止者集合 B。因此我们有

在案例 1 中,一方面,OPT ðlðv3Þ; B; 0Þ1⁄40:2þ 0:12 1⁄4 0:32 因为我们没有选择任何节点作为左子树上的阻塞点。另一方面,
在方程(8)中,Prðx3;S;BÞ I1 x3 1⁄4 0 因为节点x3 是虚线节点,我们在最优解中不选择该节点。因此我们有
类似地,我们递归地寻求方程(9)的最优解并考虑以下三个子情况:

然而,子情况(i)和(iii)不存在,因为x3的右子树或左子树上可供选择的节点数量小于k。因此(9)的最优解是OPT ðlðx3Þ; B; 1ÞþOPT ðrðx3; B; 1Þ1⁄40 þ 0 1⁄4 0。这表明阻塞集 B1⁄4fv7;v8g。综上所述,在案例 1 中,fOPT ðlðv3Þ; B; 0þOPT ðrðv3Þ; B; 2Þ1⁄40:32 × 0 1⁄4 0:32 和阻滞剂组 B1⁄4fv7;v8g。
类似地,我们分别分析案例2和案例3。这里,我们省略详细的计算过程,直接给出结果。在案例 2 中,OPT ðlðv3Þ; B; 1ÞþOPT ðrðv3Þ; B; 1Þ1⁄40 þ 0:5 1⁄4 0:5 和阻滞剂组 B1⁄4 fv6;v8g.InCase 3, OPT ðlðv3Þ; B; 2ÞþOPT ðrðv3Þ;B;0Þ1⁄4 0 × 0:5 × 0:8 1⁄4 1:3 和阻滞剂组 B1⁄4fv6;v9g。最后,比较案例 1、案例 2 和案例 3,我们发现 MIR 问题的最优解为 B1⁄4fv7;v8g,因为总激活概率最小化。此外,我们还发现二叉树中的动态规划算法的结果与一般树中的最优解相同。
VII. EXPERIMENT
在本节中,我们在合成网络和现实网络上评估所提出的算法。首先,我们描述数据集和实验设置。其次,我们从不同角度对实验结果进行分析和讨论。最后,我们与其他启发式方法进行比较。
A. Data Sets
实验数据集分为两类:合成网络和现实网络。更具体地说,对于随机网络,我们生成一个通用网络 SYN 和一个树网络 SYN-T。对于现实网络,我们分别从斯坦福大型网络数据集(SNAP)4和科布伦茨网络集(KONECT)5收集了三个不同规模的数据集。表一提供了这些数据集的详细信息。表中“CC”代表聚类系数,“MD”代表最大度
合成(SYN)。我们使用 Erdos-Renyi 模型 [24] 随机生成一个图,该模型为
 所有节点分配相等的概率 h。分配的概率越高,图越密集。在实验中,我们让 h 1⁄4 0:5。
所有节点分配相等的概率 h。分配的概率越高,图越密集。在实验中,我们让 h 1⁄4 0:5。
合成树(SYN-T)。我们随机生成一个包含 1000 个节点和 999 个有向边的树网络。请注意,每个有向边都是从父节点到子节点。
维基投票(西弗吉尼亚州)。该网络包含从维基百科成立到 2008 年 1 月的所有维基百科投票数据。网络中的节点代表维基百科用户,从节点 u 到节点 v 的有向边代表用户 u 对用户 v 进行了投票。
Twitter 列表 (TL)。该定向网络包含 Twitter 用户-用户关注信息。一个节点代表一个用户。边缘 ðu; vÞ 表示用户u关注用户v。
谷歌+(G+)。该定向网络包含 Google+ 用户与用户之间的链接。节点代表用户,有向边表示一个用户的圈子中有另一个用户。
B. Experiment Setup
我们对谣言传播过程进行以下设置:给定一个有向社交网络 G 1⁄4ðV; E; pÞ,从V中随机均匀地选择1%的节点作为谣言源集S。在我们所有的实验中,我们采用独立级联(IC)模型作为信息扩散模型。特别是,我们以两种方式分配 p,因为数据集缺乏传播概率 p。为网络上的每条边分配统一的概率 p 1⁄4 0:5。另一种方法为每条边分配一个三价模型 p 1⁄4 TRI,即我们从 {0.1,0.01,0.001} 中随机随机选择一个值,该值对应于高、中、低传播概率。请注意,所有网络都是简单网络6
1)比较方法:为了与现有方法进行比较,选择了Out-Degree、Betweenness Centrality、PageRank等其他启发式方法作为比较方法。我们的两阶段方法缩写为 GCSSB。
出度(OD)[18]。节点 v 的出度是节点 v 的出边数。 Kempe 等人。表明高度节点在有影响力的识别方面可能优于其他基于中心性的启发式方法。
介数中心性(BC)[25]。节点的介数等于从所有节点到经过该节点的所有其他节点的最短路径的数量。近年来,介数中心性已成为社交网络中重要的中心性度量。
PageRank(PR)[26]。这是众所周知的 Google 页面排名衡量标准。 pagerank 分数表示节点的重要性。有一个阻尼因子参数,我们在所有实验中将其设置为 0.9。
2)评价标准:实验评价从以下几个方面进行: (1)参数a研究。在我们的 GCSSB 方法中,我们需要生成具有 k 个节点的候选集 C。 (2)参数k研究。我们研究了阻塞集的大小与目标函数值之间的关系。 (3)与其他方法比较。我们将 GCSSB 与其他启发式方法(例如 Out-Degree、Betweenness Centrality 和 PageRank)进行比较。我们的评价标准是目标函数值(总激活概率)。函数值越小说明算法越好。 (4)最后,我们在合成树数据集上评估所提出的动态规划算法。
C. Results

参数a研究:我们研究候选集大小(参数a)对目标函数值(总激活概率)的影响。实验结果如图5所示。图5(a)和(b)分别显示了传播概率p 1⁄4 0:5和p 1⁄4 TRI。每个网络的结果在两个子图中都显示出相同的趋势。以图5(a)为例,横轴和纵轴分别表示参数a和总激活概率。总激活概率随着参数 a 的增大而减小。特别是,当 a 为 6 时,总接受概率基本保持不变。因此,我们在后面的实验中设 1⁄4 6。

参数k研究:我们研究阻塞集的大小和总激活概率之间的关系。实验结果如图6所示。在子图中,横轴和纵轴分别表示参数k和总激活概率。通过实验,我们观察到总激活概率随着 k 的增加而降低。特别是,当每个网络上的 k>300 时,它会急剧减少。
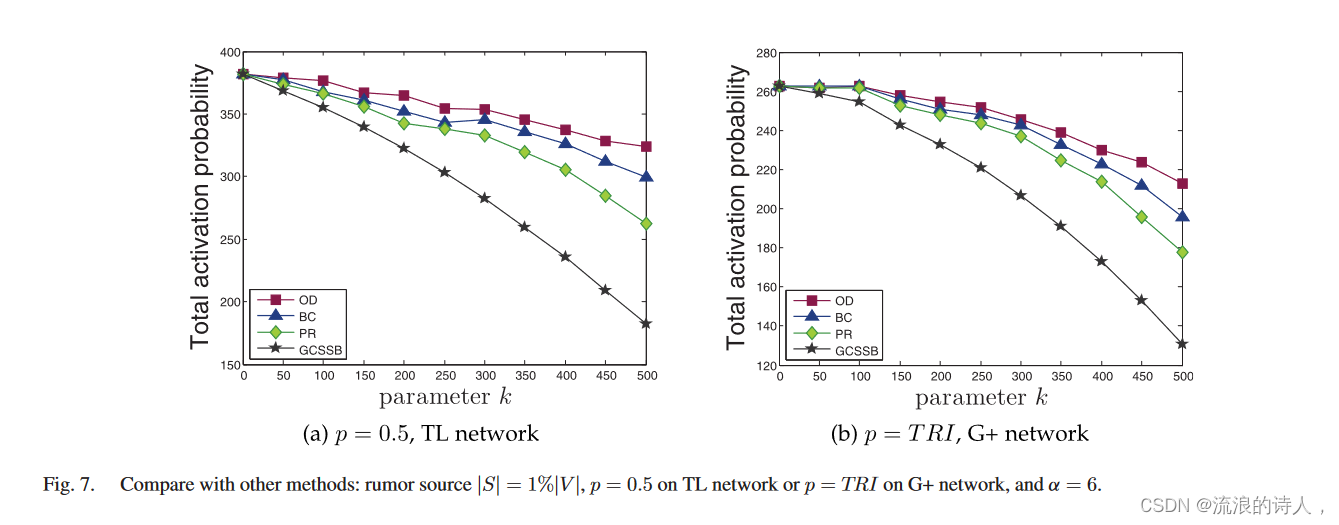
与其他方法比较:我们将 GCSSB 与其他方法(OD、BC 和 PR)进行比较。实验结果如图7所示。横轴和纵轴分别表示参数k和总激活概率。在两个子图中,总激活概率随着 k 的增加而降低。我们观察到所提出的方法是最好的,因为总激活概率是最小的。而且,在比较方法中,PR的性能最好,而OD最差。
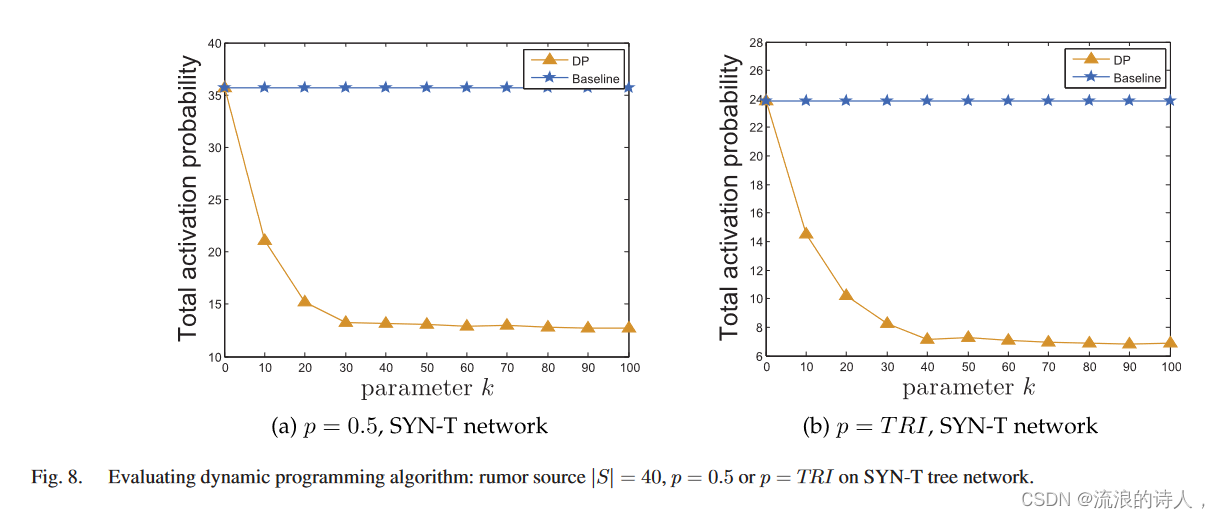
评估树中的动态规划算法。我们评估所提出的动态规划算法树形网络SYN-T。我们首先在树形网络SYN-T上随机均匀地选择40个节点作为谣言种子节点。然后我们采用独立级联模型作为信息传播模型,并通过动态规划以两种传播概率方式选择阻塞集合。结果如图8所示。图中,横轴表示参数k从0到100变化,纵轴表示总激活概率。在这两个子图中,我们将动态规划(DP)返回的激活概率与没有任何阻塞的激活概率(基线)进行比较。我们有以下观察结果:(1)总激活概率随着参数 k 增加。这一现象再次证明目标是单调递减的。换句话说,我们选择的阻塞者越多,总激活概率应该越小; (2)当k<40时,总激活概率急剧降低。然而,当k>40时,总激活概率稳步降低。我们的动态编程自动选择最佳节点作为阻塞者。
VIII. CONCLUSIONS
在本文中,我们研究了一个称为最小化谣言影响(MIR)问题的新问题,该问题找到一个小规模的阻止者集,从而最小化网络上用户的激活概率。基于IC模型,我们证明了目标函数满足非子模性。我们开发了一种两阶段方法 GCSSB 来快速识别通用网络中的阻塞集。此外,我们在树网络中提出了一种动态规划算法,并发现它可以提供最优解。最后,为了评估我们提出的方法,进行了广泛的实验。实验结果表明我们的方法优于比较方法。















 1623
1623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









