







A B S T R A C T
大气污染物浓度预测是预防污染事件发生的有效方法,为空气中有害物质提供预警。准确预测大气污染物浓度可以更有效地控制和预防大气污染。本研究采用大数据关联原理和深度学习技术建立PM2.5浓度预测模型。该模型包括基于残差神经网络(ResNet)的深度学习网络模型和基于卷积长短期记忆(ConvLSTM)的深度学习网络模型。利用ResNet深度提取多个城市污染物浓度的空间分布特征和气象数据。将输出作为ConvLSTM的输入,进一步提取从ResNet中提取的初步空间分布特征,同时提取污染物浓度和气象数据的时空特征。该模型将这两个特征结合起来,实现特征序列的时空相关性,从而准确预测目标城市未来一段时间内的PM2.5浓度。与其他神经网络模型和传统模型相比,所提出的污染物浓度预测模型提高了污染物浓度预测的准确性。对于1 ~ 3小时的预测任务,所提出的污染物浓度预测模型表现良好,均方根误差(RMSE)在5.478 ~ 13.622之间。此外,我们在目标城市进行了多尺度预测,取得了令人满意的效果,即使在1- 15小时的预测任务中,平均RMSE值也能达到22.927。
1. Introduction
PM2.5浓度预测可以看作是一个时间序列处理问题,可以根据过去的历史相关数据进行预测,例如湿度和温度等气象因素,以及SO2和CO等其他污染物因素。因此,必须提取和学习这些复杂相互作用关系之间的特征,以便进一步进行大气污染物的预测。此外,大气污染是一个区域扩散问题,需要考虑空间维度。这意味着邻近城市之间存在空间相关性的空气污染影响。大多数数值预测模型包括基于假设理论和先验知识的确定性模型;只将投入和产出视为独立过程的经验模型;数理统计模型;或使用小样本数据的传统机器学习模型。这些模型的主要优点是计算复杂度低、计算速度快、易于实现。然而,传统的数值分析模型在处理多城市站点的海量时空数据进行空间相关性大气污染物浓度预测时,遇到了三个问题:(1)需要提取和学习气象数据与大气污染数据之间复杂的相关性特征,以便进一步预测和改进性能;(2)准确提取历史数据间的时间相关性特征进行预测。这意味着在预测中应该忽略过去较长时间间隔的冗余信息或特征,而在一定时间内考虑有用的信息或特征,以改进预测;(3)基于区域内相邻城市的海量气象数据和污染数据,利用时间序列标签提取城市间的空间相关特征。这些问题导致大多数传统的空气污染物预测模型表现不佳。
鉴于此,我们提出了两种人工神经网络来构建我们的预测模型:残差神经网络(ResNet)和卷积长短期记忆网络(ConvLSTM)。理由如下:
(1)深度网络,如卷积神经网络(CNN),可以提取和学习NLP和计算机视觉领域的空间相关特征。然而,随着网络层深度的增加,梯度消失和网络退化问题加剧。因此,我们引入ResNet框架来提取数据的空间相关特征,避免了这两个问题。随着层数的增加,网络的性能将会提高 。同样,本文提出的污染物预测方法充分考虑了多城市污染物和气象数据的预测问题,利用深度残差神经网络(ResNet)的优势提取多城市污染物和气象数据之间输入的空间特征。
(2)提出卷积LSTM (ConvLSTM),结合空间卷积运算提取时间序列特征,旨在从高维数据中学习时空关联特征。与递归神经网络(RNN)模型相比,ConvLSTM不仅可以避免梯度爆炸和消失问题,还可以解决高维数据的时空特征关联问题等。因此,我们可以利用卷积LSTM的优势,对ResNet提取的高维空间特征进行更深层次的时空相关特征提取。
在本研究中,我们提出了一种集成了ResNet和ConvLSTM的端到端深度学习模型——rcllearning。本工作的主要贡献如下:
(1)利用ResNet作为提出的RCL-Learning模型的基础,避免了梯度消失或梯度爆炸的问题,可以从多个城市的污染物和气象数据中提取空间相关特征,同时也消除了深度网络的退化问题。
(2)模型采用ConvLSTM作为输出预测层,既获得了ConvLSTM预测时间序列的性能优势,又避免了梯度消失的问题,从而从残差网络层提取出隐藏在高维数据输出中的高级相关特征,实现挖掘数据时空相关性的目标;
(3)提出的RCL-Learning模型可以同时应用多个城市的气象和污染数据进行大数据环境监测,考虑数据的时空分布变化和规律,实现目标城市大气污染物浓度预测。在数据集上的实验表明,我们的框架比其他最先进的方法取得了更好的结果。
2. Related work
根据相关研究中所采用的预测方法的特点,大气污染物浓度预测从根本上可分为两大研究方法:确定性方法和统计方法。
确定性方法可以应用于有限的历史数据集。然而,需要利用气象原理和统计方法来模拟基于大气物理和化学反应的污染物的实时排放、扩散、转化和去除过程。基于确定性方法的模型结构是在一定的理论假设和先验知识的基础上预先确定的。基于确定性方法的空气污染物浓度预测有几种常用方法:带扩展的综合空气质量模型(CAMs)、WRFChem模型、嵌套空气质量预测建模系统(NAQPMS)和社区多尺度空气质量模型(CMAQ)。
统计方法可以避免使用复杂的理论模型。与确定性方法相比,它们可以确定复杂污染物浓度数据之间的相关性,从而显示出较好的预测性能。在统计学的基础上,这两个分支可以扩展为传统的机器学习方法和新的深度学习方法。传统的机器学习方法包括支持向量机(SVM)、基于贝叶斯网络的多标签分类器、支持向量回归(SVR)方法、隐马尔可夫模型(HMM)等方法。
本文充分考虑预测模型对未来目标城市的PM2.5浓度进行更准确的预测,应实现以下目标:(1)有效利用多个城市的历史污染物浓度和气象大数据;(2)历史多城市污染物与气象数据时空相关性特征的深度挖掘。
3. Data description
3.1. Data collection
实验使用2014年5月13日至2018年5月30日收集的14个城市的历史污染物浓度和气象数据。本文的实验数据基于城市层面,即每个城市每小时的样本数据为一维特征向量,特征元素由污染物和气象因素组成。本文选取了以上海为中心的长三角地区经济快速发展的14个城市(上海、南京、苏州、南通、无锡、常州、镇江、杭州、宁波、绍兴、湖州、嘉兴、台州、舟山)作为城市选址。这些城市的地理位置离上海最近,污染物的扩散更容易相互影响。我们选取了空气质量指数(AQI)、PM2.5、PM10、SO2、NO2、O3、CO、温度、湿度、气压、风向、风速、云量、最高温度、最低温度和条件等16个污染物和气象因子。对于非数值气象因子,包括云和条件,我们执行一对一的数值映射。对于条件因子,我们将“mist”的值映射为1,“clear”的值映射为2,“cloudy”的值映射为3。空气污染物浓度和气象数据集的缺失值通过时空插值填充。图1显示了所有城市站点的位置。
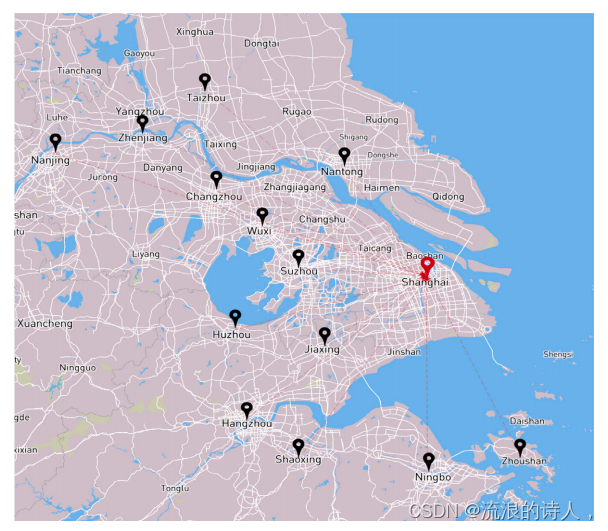
黑色圆圈表示周边城市,红色圆圈表示目标城市,箭头表示周边城市污染物对目标城市可能产生的影响。
3.2. Particulate matter (PM2.5) and air quality index (AQI)
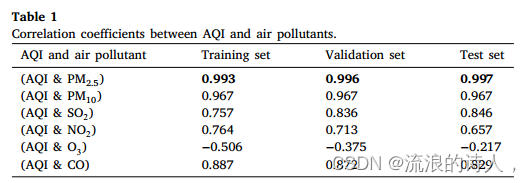
我们计算了训练集、验证集和测试集的AQI与空气污染物的相关系数,如表1所示。研究者提出PM2.5浓度可以用来评价空气质量。表1中,AQI与PM2.5的相关性最高,在训练集上相关系数值为0.993,在测试集上相关系数值高达0.997,这也印证了前人的研究结果。因此,本文选取与AQI相关性最高的PM2.5作为预测目标。
3.3. The distribution characteristics of data
3.3.1. Analysis of temporal dimension
为探究污染物浓度分布特征与气象数据,选取目标城市上海2016年全年数据作为研究对象。图2为各污染物浓度(含空气质量指数)的年数值变化。观察PM2.5等污染物浓度的变化可以发现,污染物浓度变化的趋势总体上是一致的,这也反映了污染物之间可能存在着隐藏的关系。经统计分析,49.4%的2016年,PM2.5浓度大于WHO第一次临时标准35 μg∕m3,对部分异常敏感人群的健康影响较弱;2016年有13.7%的时间PM2.5浓度大于75 μg / m3,这将直接影响人们的日常出行和身体健康。因此,对于PM2.5的预测,一方面需要考虑PM2.5与其他污染物之间的隐性关系;另一方面也反映了准确的预测可以提前预防PM2.5对人体健康的影响。
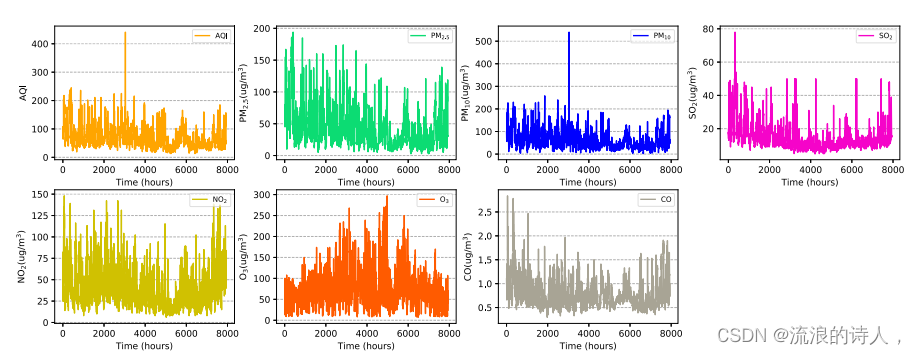
图2所示。空气污染物浓度数据时间序列图
图3为气象因子的年数值变化。从图3可以看出,首先,温度、最高温度和最低温度的变化相同,气压的数值变化与温度正好相反;二是气象要素的数值类型和区间差异较大,但变化趋势高度相似,说明气象要素之间可能存在相互影响。例如,如图3所示,温度高可能导致气压低,反之亦然;三是气象因子与PM2.5浓度变化一致,说明大气污染物与气象因子之间存在隐性相关性。例如,在5000-6000 h之间,观测值有不同幅度的波动。因此,结合已有的研究成果,在PM2.5浓度预测研究中,我们将气象因子作为模型输入的一部分,提取污染物与气象因子之间的隐藏特征。
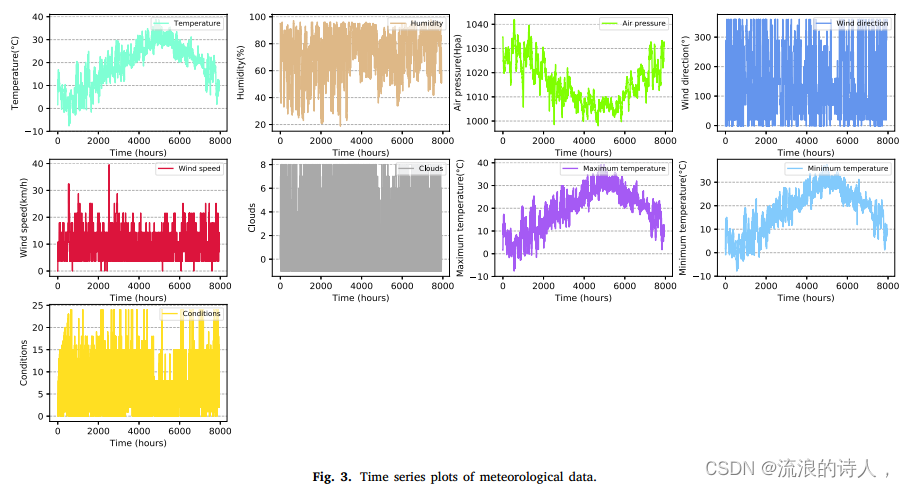
图3所示。气象资料的时间序列图。
3.3.2. Analysis of spatial dimension
图2和图3中污染物和气象因子的数值变化是在时间维度上,我们做了详细的分析。上海作为目标城市,其PM2.5浓度在空间维度上也可能具有一定的特征。类似的选取2016年各城市PM2.5浓度数据。我们计算了上海与周边城市大气污染物的相关系数,如表2所示。结合表2和图1,首先,我们观察到离上海越近的城市关联度越高,我们在表格中用粗体表示,PM2.5的相关系数普遍高于PM10;其次,随着距离的增加,上海与周边城市大气污染物的相关系数逐渐减小。距离的影响表明,对于任何一个城市区域,除了预防局部污染物外,还需要协调区域污染物的预防,反映了空气污染物的空间相关性。接下来,图4显示了上海及周边城市PM2.5浓度的变化情况。首先,从图3和图4可以发现,各城市PM2.5浓度的一般规律是温度高时浓度低,温度低时浓度高。其次,在时空维度上,我们发现各城市PM2.5的变化格局在图4中是相似的。第三,通过对比上海与周边城市PM2.5浓度的变化,我们发现上海PM2.5浓度波动较大,且较为复杂。根据污染物的空间关联特征和上海及周边城市污染物浓度特征,这反映了考虑空间相关性的重要性。
3.4. Data division
在我们的实验中,我们选择了70%的数据作为训练集,15%作为验证集,剩下的15%作为测试集。本研究中对数据进行划分的具体方法如下:首先,我们按照给定的窗口长度𝐿和移动步长𝑆统一划分数据集,最后得到的样本总数为:(𝐷−𝐷∗0.15)−𝐿)∕𝑆;然后,我们对这些样本进行排序,选择82%的样本作为训练集,18%的样本作为验证集。另外,使用𝐷的15%作为测试集,这意味着我们从原始数据集中提取15%的数据作为测试集,而不对其进行干扰;最后,我们将除法定义为广义随机方法。其中,窗口长度𝐿为输入模型的时间序列长度与目标预测序列长度之和,𝐷为原始数据集的大小。
4. Methodology
4.1. Framework overview
本研究结合了ResNet和ConvLSTM网络的优势,为RCLLearning设计了一个三层架构。该库由ResNet组成,利用多个卷积层从污染物和气象数据中提取深层空间特征。最底的这一层,ResNet提取高层空间语义特征。第二层是ConvLSTM层,将数据的时空特征结合起来,实现时空特征的同时提取。第三层由全连通层组成,接收ConvLSTM的输出,完成对最终预测结果的时间序列预测,并对最终的预测结果进行预测,预测结果的时间序列预测。
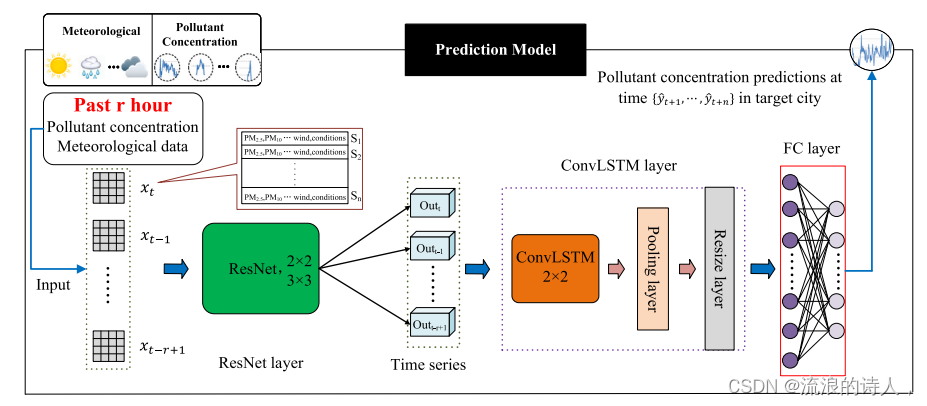
PM2.5浓度预测的RCL-Learning模型框架。𝑥𝑡−𝑖是制定污染物浓度和气象数据输入到模型在每一时刻,𝑆𝑘𝑘代表城市。
4.2. ResNet
本研究利用ResNet的固有优势,提取多个城市污染物浓度与气象数据的空间相关特征。首先,空气污染物和气象数据输入时间序列顺序ResNet𝑥={𝑥𝑡,…,𝑥𝑡−𝑖,…,𝑥𝑡−𝑟+ 1}的空间相关特征提取。然后,ResNet中的每个卷积层使用不同的卷积核对输入数据进行特征提取。最后,ResNet特征提取的输出时间序列顺序𝑜𝑢𝑡={𝑜𝑢𝑡𝑡,…,𝑜𝑢𝑡𝑡−𝑖,…,𝑜𝑢𝑡𝑡−𝑟+ 1}。本研究构建的ResNet是在RCL-Learning模型的基础上,以重构单元为单元重构传统CNN。每组重构单元表示在图6的左侧,它由多个卷积层(一般不少于两层)和一个使用多层卷积层渐近残差函数的捷径组成。
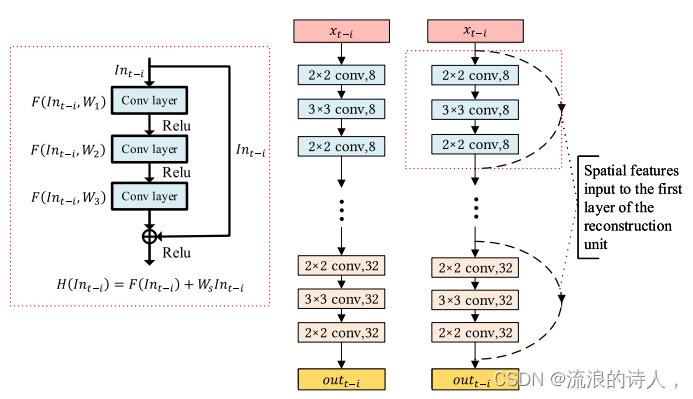
图6所示。左:改造单元。中:传统的CNN。右:残余网络。2 × 2和3 × 3表示过滤器尺寸;8和32表示通道数。
4.3. ConvLSTM
对ResNet部分进行空间特征提取后,得到高维空间特征序列。本研究利用ConvLSTM的优势,对时间序列数据𝑜𝑢𝑡={𝑜𝑢𝑡𝑡,…,𝑜𝑢𝑡𝑡-,…,𝑜𝑢𝑡𝑡−𝑟+1}进行时空关联特征提取,分为时空特征提取和PM2.5浓度预测两个阶段。在时空特征提取阶段,ConvLSTM进行时空相关特征提取在输入数据提取𝑜𝑢𝑡={𝑜𝑢𝑡𝑡,…,𝑜𝑢𝑡𝑡−𝑖,…,𝑜𝑢𝑡𝑡−𝑟+ 1}准备预测。在预测阶段,ConvLSTM将每一时刻的输出状态𝑡+𝑗输入到全连通层,根据提取的时空相关特征𝑡生成PM2.5预测值。在ConvLSTM的训练过程中,采用了单层结构的ConvLSTM。如图7所示,我们展示了ConvLSTM完整的时空特征提取的详细过程,其中(𝑐𝑡−离别,𝑡−离别)表示单元状态。设,分别表示输入门、锻造门和输出门𝑊。表示卷积核,𝑏表示偏置,'◦'表示Hadamard积。ConvLSTM在每个时间序列上的时空特征提取过程可以用以下公式表示:(1)ConvLSTM选择性地忘记时间𝑡−+ 1的细胞状态特征信息;
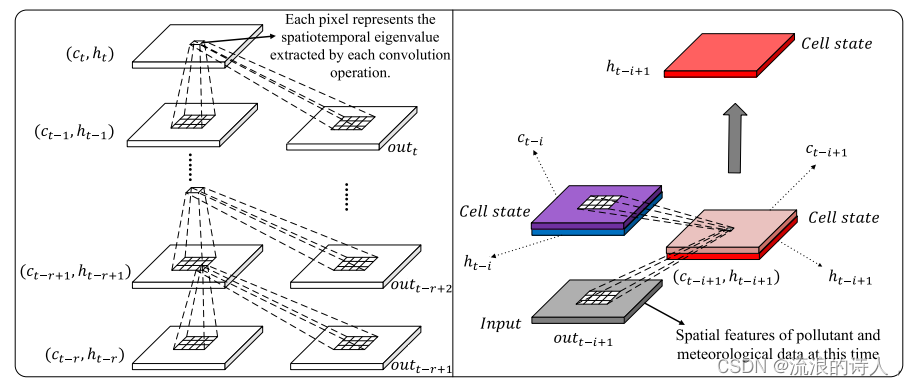
图7所示。ConvLSTM的实现。左图:ConvLSTM的时空特征提取过程。右:一次提取和生成时空特征的过程。
4.4. Loss function
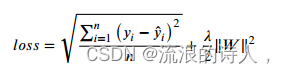
𝑛为预测序列的长度,小数部分为PM2.5浓度的观测值,小数部分为PM2.5浓度的预测值,其中,为正则化参数,𝑊为网络的权值参数。
4.5. Metrics
将本研究提出的RCL-Learning模型与同一数据集上的其他预测模型进行了比较。以均方根误差(RMSE)、平均绝对误差(MAE)和相关系数(Corr)作为衡量方法有效性的指标。实验指标计算公式如下:
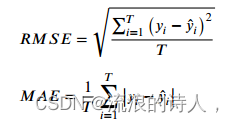
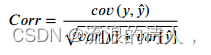
5. Results
5.1. Parameter setting
本研究使用的验证集与训练阶段密切相关,在每个历元之后,计算预测模型在验证集上的RMSE和MAE。因此,根据验证集上计算的模型误差选择最优模型。具体流程如下:每个实验选取100个epoch。在训练一个epoch之后,我们在验证集上测试训练好的模型。如果验证集上预测模型的RMSE和MAE变小,则更新并保存模型参数。经过多次参数调整和实验,当预测模型对验证集的预测效果达到最优时,训练结束。在实验中,dropout被用作避免模型过拟合的一般技巧。实验结束后,用于模型检验的参数如表3所示。
5.2. Single-step prediction
在单步预测实验中,输入模型数据时间序列长度𝑟~ 3,预测长度𝑛~ 1。我们的预测变量是上海每小时的PM2.5浓度,这个任务的目标是预测下一个小时的PM2.5浓度。例如,我们使用历史三小时多城市污染物浓度和6:00-9:00的气象数据来预测上海下一个小时10:00的PM2.5浓度。
5.2.1. The impact of related factors on PM2.5 concentration prediction
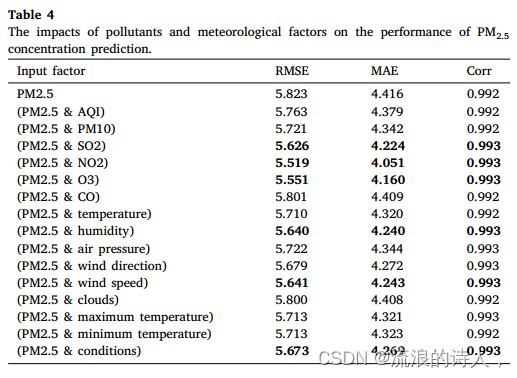
在PM2.5浓度预测研究中,不同的输入变量可能对RCL-Learning模型的预测结果产生不同的影响。表4列出了PM2.5浓度预测在不同变量对下的表现,即PM2.5与其他变量的组合,但值得注意的是,我们的输入仍然包括14个城市。从表4可以看出,这些不同的输入变量对PM2.5浓度预测有正向影响。其中,NO2、O3、SO2、湿度、风速、条件影响最为显著。该结果与3.3.1节的分析结果相对应;即数据变量之间的隐性相关性影响了我们的PM2.5浓度预测研究。
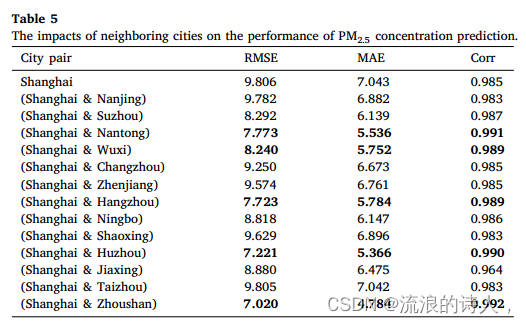
同样,不同城市对RCL-Learning模型的预测结果也可能有不同的影响。表5列出了不同城市对(即上海与周边其他城市的组合)下PM2.5浓度预测的表现,但值得注意的是,我们的输入仍然包含16个变量。从表5可以看出,相邻城市对上海PM2.5浓度预测的正向影响。影响的显著性与距离有关,其中南通、无锡、杭州、湖州和舟山的影响最为显著。这一结果与3.3.2节的分析结果相对应,体现了重要性空间特征。由表4和表5的实验结果可知,PM2.5浓度预测受污染物和气象因素以及周边城市的影响。因此,我们在接下来的实验中使用了来自14个城市的16种污染物和气象因子。
5.2.2. Comparison with state-of-the-art methods
表6列出了我们提出的RCL-Learning模型和基线模型在整个测试集上的[3-1 h] PM2.5浓度预测性能。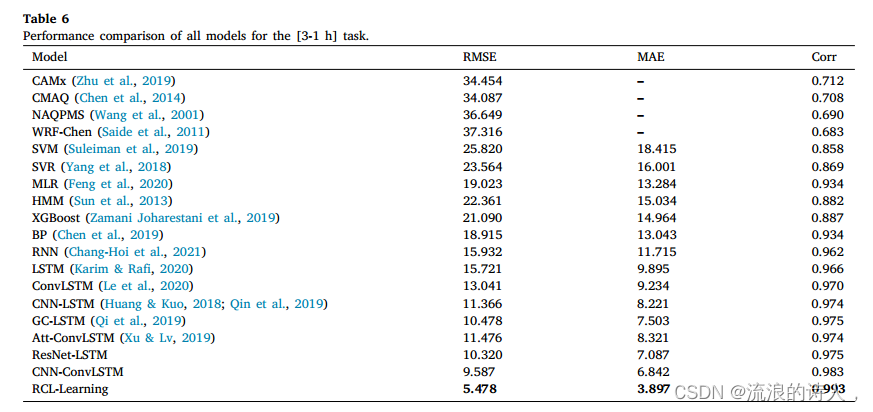
图8为[3-1 h]任务中不同模型在同一测试集上的泛化能力。图8中𝑥-axis的长度为4000 h,表示在测试集中随机抽取了连续4000个小时来测试该时间段内预测模型的性能。该验证方法基于先前研究论文,主要目的是将模型的预测效果可视化,突出模型的预测性能和拟合能力。将污染物的预测与空气质量指数的变化相结合,通过空气质量指数更科学地描述突变点的位置。当AQI值剧烈波动时,出现突变点。因此,我们将测试结果与突变点结合起来,进一步验证我们的RCL-Learning模型的优越性。其中蓝色曲线代表观测值,红色曲线代表预测值和黄色曲线表示AQI值。由于本文空间的考虑,图8仅展示了四种最先进的预测模型的实验结果,代表了在整个测试集上ConvLSTM、at -ConvLSTM、GC-LSTM和RCL-Learning模型的拟合趋势进行了测试。
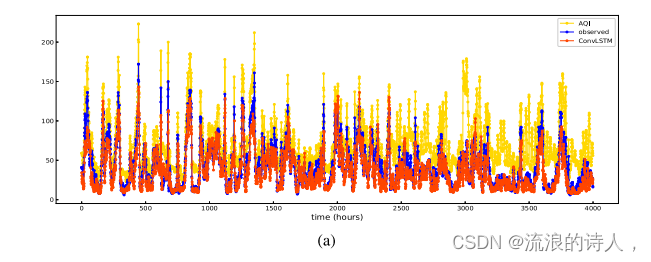
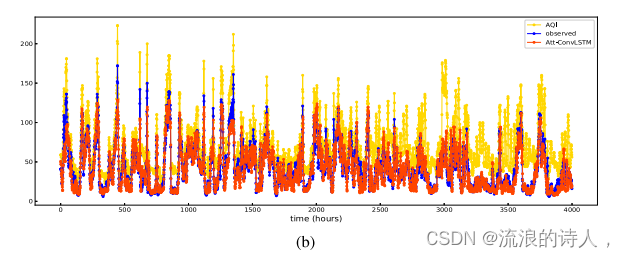
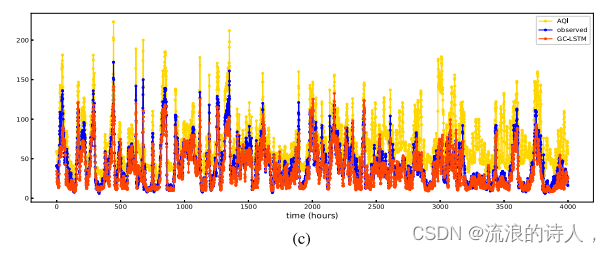
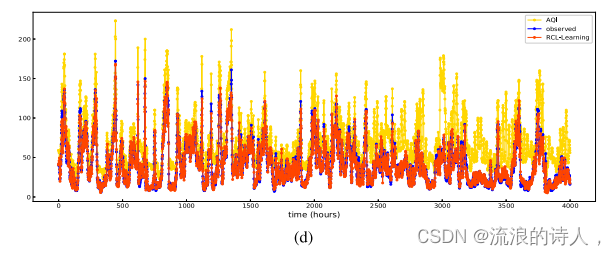
图9为[3-1 h]任务中不同预测模型在测试集上的预测性能。𝑥-axis为PM2.5的实测值,𝑦-axis为PM2.5的预测值。黑线表示的是综综函数,黑点表示的是实测值与预测值之间的偏差程度。在离散度比较中,当PM2.5浓度大于100 μg∕m3时,ConvLSTM的离散度最大,RCL-Learning模型的离散度最小,预测效果最好。当PM2.5值在0 ~ 100 μg / m3之间时,RCL-Learning模型的离散度最小。从图9可以看出,RCL-Learning的预测值与实测值基本一致。在相关性比较中,在整个测试集中,ConvLSTM、at -ConvLSTM、GC-LSTM、RCL-Learning的相关系数分别为0.970、0.975、0.974、0.993,说明RCL-Learning的预测值与实测值的相关性最大。
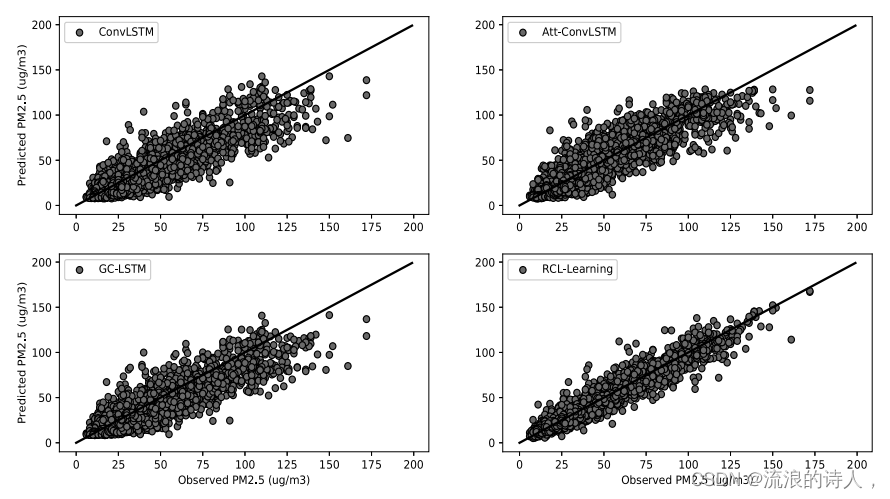
图9所示。[3-1 h]任务中测试集上的观测值与预测值之间的拟合程度。
5.3. Multi-step prediction
现有的PM2.5预测研究主要集中在对下一次的单步预测,可能不足以满足实际应用场景的需求。因此,多步PM2.5浓度预测的意义不言而喻。我们将未来1 - 15小时分为6个多步骤预测任务(1 - 1、1 - 2、1 - 3、1 - 6、1 - 8和1 - 15小时),并训练单独的模型来预测每个任务的PM2.5浓度。在每个任务中,我们使用多个城市的历史污染物浓度和气象数据,实现对目标城市未来PM2.5浓度的多步预测,如图10所示。表7列出了RCLLearning模型在6个多步骤预测任务中的表现。在涉及多步预测的实验中,我们在所有任务中都使用了固定网络结构的RCL-Learning预测模型。预测结果如表7所示,随着预测时间间隔的增加,所需的历史输入时间序列也会增加。RCL-Learning模型的预测性能随着预测步长的增加而逐渐降低,RMSE从5.449增加到40.376. 在表7中,对于接下来1小时的PM2.5浓度预测,将历史输入时间序列的长度𝑟从3小时增加到5小时,确实可以提高预测的精度,但预测RMSE的精度只提高了0.029。考虑到预测精度和预测计算成本的提高,对于任意时刻污染物的预测,经过多次实验,我们选择了一个最优的历史输入时间序列长度𝑟。
5.4. Trend prediction
为了进一步证实所提出的预测模型的有效性,我们使用多城市污染物和气象数据的历史20 h作为输入,预测污染物PM2.5浓度在不同时期(1-10、11-20、21-30和31-40 h)的趋势。我们将RCL-Learning模型与最先进的PM2.5预测模型:ConvLSTM、at -ConvLSTM和GC-LSTM 。表8给出了不同时期PM2.5浓度预测值的平均误差。为了进一步证明RCL-Learning在测试集上的拟合性能,我们预测了未来1 - 20 h和1 - 40 h的污染物浓度。图11显示了不同时期PM2.5的预测和观测变化(在测试集上随机选择不同时期的样本)。

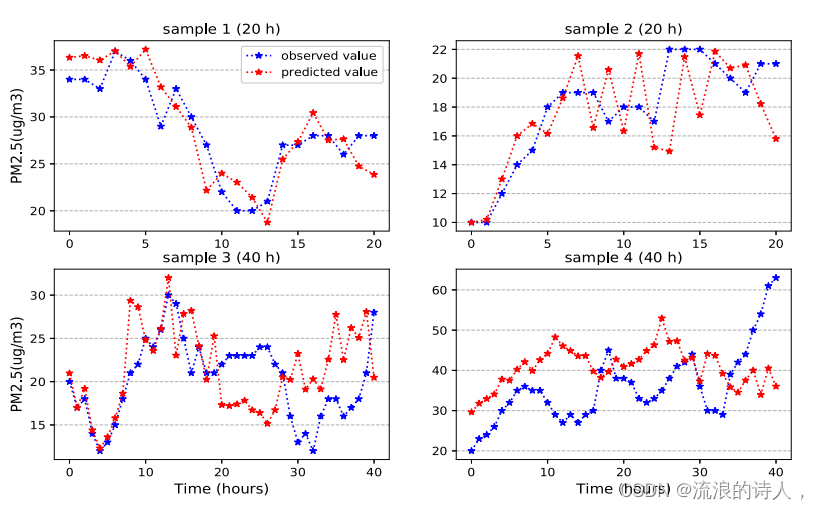
不同时期目标城市污染物浓度变化趋势预测。蓝色曲线代表观测值,红色曲线代表预测值。
6. Discussion
6.1. Comparison with previous prediction models
结合图8和图9中各模型的拟合能力,我们可以得出以下结论:(1)对于图8,我们可以得到RCL-Learning模型的预测性能优于对比模型,适用于污染物浓度突变的预测任务;(2)对于图9,我们可以得到,与对比模型相比,RCL-Learning模型能够准确预测PM2.5的高浓度,使得预测值与实测值高度一致;(3)结合图8和图9的实验结果,我们可以直观地看到,对于突变点来说,PM2.5浓度普遍较高,突变点的数量相对较少。这主要反映在一般数据集中,突变点的样本数量较少,导致数据分布不均匀的问题。
这种现象造成了预测模型学习不足的问题,即难以学习到突发变化下污染物浓度的变化规律。因此,这也是一些模型在污染物浓度突变情况下难以拟合的原因。
基于以上实验结果,我们的分析结果是本文提出的RCL-Learning模型较好地把握了污染物的时空特征。在数据方面,我们在污染物浓度预测任务中考虑了多个城市污染物和气象因素对目标城市的影响;在模型方面,我们利用残差网络和ConvLSTM作为时空特征提取器,充分利用了两种网络在特征提取方面的优势。因此,我们的预测模型的特点是:一方面,在污染物浓度振动幅值较小的大样本𝐷1(污染物浓度小于100 μg / m3的样本数量𝐷1占训练样本总数的94.3%)中,可以充分了解历史数据中污染物浓度的变化规律;另一方面,在污染物浓度波动较大的小样本𝐷2(污染物浓度大于100 μg / m3的样本数量𝐷2占训练样本总数的5.7%)中,我们利用RCL-Learning模型的优势,学习目标城市及邻近城市污染物浓度的变化规律,解决了难以准确预测目标城市污染物突变的问题。本实验验证了RCL-Learning模型预测PM2.5浓度的能力
6.2. Long-term series prediction and model comparison
进行长期预测需要输入历史污染物浓度和气象数据,相关性非常高,且输入序列的长度难以确定。
因此,在保证预测准确性的同时又不过度耗时是很困难的。然而,本研究提出RCLLearning模型可以同时实现这两个目标。因此,输入数据的时间序列长度主要取决于训练模型所花费的时间和预测精度的提高。随着预测时间段的增加,我们逐渐增加输入序列的长度,我们设置的最长阈值为20。因为当模型的输入时间序列长度大于20时,训练模型所花费的时间将急剧增加。因此,数据序列长度是一个经验值,是根据每个研究者的经验设定的。
RCL-Learning模型可以预测目标城市近期污染物浓度,如表7所示。在预测未来3小时目标城市污染物浓度时,RMSE值可维持在5.449 ~ 13.622之间。对于较长期的序列预测任务,如预测目标城市未来1 ~ 15 h的污染物浓度,RCL-Learning预测模型也表现出令人满意的性能。平均RMSE值达到22.927,平均Corr值达到0.800。
如表8所示,当我们比较不同预测时间段下ConvLSTM、at -ConvLSTM、GC-LSTM和RCL-Learning模型的平均预测误差时,ConvLSTM、at -ConvLSTM和GC-LSTM的预测误差均大于RCLLearning模型,说明RCL-Learning模型的预测精度最高。图11显示了RCL-Learning模型预测20小时和40小时时间段污染物趋势的性能,即从测试集中随机抽取4个测试样本作为实验结果分析的参考依据。从图11可以看出,蓝色观测曲线和红色预测曲线所表示的趋势是一致的。实验证明,对于污染物浓度的长期预测,RCL-Learning模型的趋势预测具有广泛的应用价值。
因此,考虑将RCL-Learning模型预测的污染物浓度趋势与目前最先进的预测方法相结合,可以提高污染物预测的准确性。
7. Conclusions
基于深度学习和大数据关联原理的结合,本文提出了一种基于ResNet和ConvLSTM的RCL-Learning预测模型。该模型主要用于预测目标城市的污染物浓度。ResNet主要用于提取多个城市污染物和气象数据的空间特征。ConvLSTM用于提取ResNet层输出的高维数据的时空特征。该方法的优点总结如下。
(1)与传统的CNN、GC、Att网络相比,ResNet可以更好地提取相同深度的网络情况下的空间特征。
(2)由于大气污染物的时空相关性,与传统的LSTM相比,本文提出的预测模型在ResNet的基础上增加了ConvLSTM层。ConvLSTM能更有效地提取数据的时空相关特征。
实验表明,与其他模型相比,RCL-Learning模型充分提取了污染物与气象数据的相关性,预测更加准确,并解决了长期依赖等问题。同时,充分考虑了污染物与气象的时空相关性数据。根据累积物质(PM2.5)与空气质量指数(AQI)的相关性,准确预测PM2.5在污染物危害预警中具有重要意义。
与传统的机器学习方法和单一的经典网络相比,RCL-Learning已成为区域和国家层面大气污染监测和预测任务中实用的辅助模型之一。
本研究的局限性在于没有考虑多个城市的位置信息对目标城市污染物的预测贡献不显著。因此,在未来的工作中,将位置信息作为输入特征添加到预测模型中

















 6467
6467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









