








Abstract
影响力传播研究是社交网络信息传播的关键问题。由于影响力分析在营销、广告、个性化推荐、舆情监测等方面的现实意义,研究人员从不同角度研究了该问题并提出了解决方案。在本文中,我们回顾了社交网络中的影响力传播,并得出结论,现有研究使用三种主要方法:网络拓扑分析、贪婪算法和启发式算法。同时,根据研究目的,我们将现有文献分为三类:个体影响力分析、社区挖掘和影响力最大化。最后,基于最先进的研究,我们揭示了当前的弱点和未来的研究方向。
关键词——社交网络,影响力传播,个人影响力,社区挖掘,影响力最大化
I. INTRODUCTION
在过去的十年中,社交网络中的信息传播受到了研究者的广泛关注。这些研究人员主要关注信息如何传播、哪些因素影响信息传播以及哪些类型的信息会导致更快的传播[1] [2] [3]。当其他人在传播信息时影响一个人的观点、情绪或行为时,就会产生社会影响力[4]。随着研究的进一步深入,影响力传播已成为信息传播的一个关键领域,具有重要的实用价值[5]。该领域的主要关注点包括:谁影响谁、谁是最有影响力的用户、影响力如何传播等等。影响力分析在许多领域都有用,例如病毒式营销[6]、产品推荐或广告[7][8],而政府则可用于舆论分析[9]。
本文对近年来影响力传播的研究进行了综述和比较。主要采用网络拓扑分析、贪心算法和启发式算法作为问题解决方案。从我们的角度来看,这些研究大多可以分为三类:第一类是个体影响力分析。该领域关注的是如何找到最有影响力的节点。第二类是社区挖掘,主要研究如何挖掘在线社交网络中具有共同属性的一类节点。第三类是影响力最大化,基于特定的传播模型和节点集,选择节点的种子集,以影响尽可能多的不受影响的用户。
本文的其余部分安排如下。第二节介绍影响力传播常用的基本方法。在第三节中,我们提出了一些关于个人影响力的代表性研究。在第四节中,我们比较社区挖掘算法。然后,在第五节中,我们讨论影响力最大化的进展。在每个部分的末尾,我们提供对文献的评论。最后,我们总结本文并讨论影响分析的未来方向。表 I 给出了本文后续部分中使用的符号和符号。
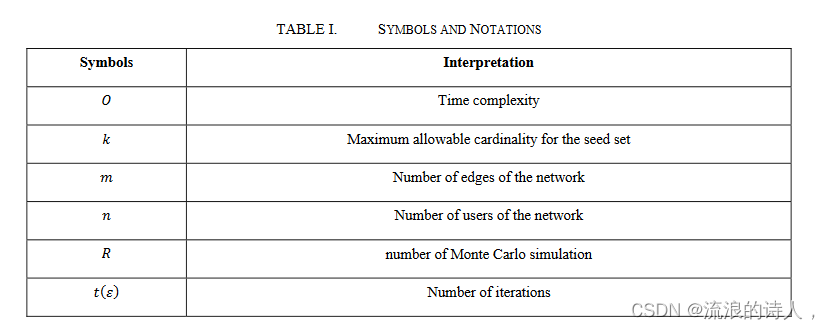
表 I. 符号和注释
II. BASIC METHODS OF INFLUENCE RESEARCH
在影响力传播研究领域,大多数研究者的研究基于三个方面,一是网络拓扑,二是贪心算法,三是启发式算法。这三个方面可以相互独立,也可以结合起来,进一步优化算法,提高可扩展性。
A. Network Topology
许多研究都考虑了网络拓扑。一般来说,具有更好连接性的节点(根据节点中心性等指标来衡量)通常有助于影响力的传播。然而,仅考虑网络的拓扑结构会导致大范围的重复影响传播。研究人员经常考虑结合其他算法或用户因素来避免这个问题。
B. Greedy Algorithms
贪心算法主要用于影响力最大化问题。贪心算法在每次迭代中选择对种子边际增益最大的节点。肯佩等人。文献[10]系统地讨论了影响力最大化问题是NP-hard问题,贪心算法可以在多项式时间内找到局部最优解。但对于真实的社交网络来说,计算成本太高。
因此,许多研究人员提出了一系列改进算法。莱斯科维奇等人。 [11]提出了CELF(Cost-Effective Lazy Forward)算法,该算法基于影响函数的子模型,有效降低了时间复杂度。戈亚尔等人。文献[12]在CELF算法的基础上提出了CELF++,进一步减少了蒙特卡罗模拟的次数[13],从而降低了时间复杂度。
此外,王等人。 [14]结合网络拓扑提出了CGA(Community-Based Greedy Algorithm)。他们首先检测社区,然后选择种子节点来限制节点在社区内的影响力。虽然影响力最大化阶段的时间复杂度有所降低,但检测社区非常耗时,同时全局影响力被忽略。这些算法的比较如表二所示。

表二。贪心算法及其变体的比较
虽然贪心算法的时间复杂度非常高,但由于其具有很强的可解释性,许多研究人员随后提出了改进的算法来降低时间复杂度,使贪心算法更加实用.
C. Heuristic Algorithms
由于贪心算法的耗时性质,使用了一系列启发式算法来避免这个问题,例如PageRank [15]和LeaderRank [16]。这些算法用于发现网络中的高影响力节点。
陈等人。 [17][18]提出了PMIA方法和LDAG方法,分别基于IC(独立级联)模型[19]和LT(线性阈值)模型[20]。他们通过迭代来选择局部种子节点,虽然可以获得更好的解集,但时间复杂度仍然较高。 Goyal 等人基于 LDAG 算法。 [21]提出了Simpath算法。该算法通过搜索附近的简单路径来计算传播,使用参数 n 来控制运行时间和种子质量之间的平衡。随着研究的进展,一些用户因素也被考虑在内。例如用户交互[22]和心理学[23]。这些算法的比较如表 III 所示。

表三。启发式算法及其变体的比较
与贪心算法相比,启发式算法在时间复杂度上有了很大的提高,并且可扩展性也比贪心算法更好。启发式算法也存在一些缺点,如精度无法保证、缺乏统一完整的理论体系等。不过,这仍然不妨碍研究人员进一步扩展它。
III. INDIVIDUAL INFLUENCE
对个人影响力的研究侧重于识别社交网络中具有影响力的用户,他们在信息传播中发挥着至关重要的作用。一个代表性的研究领域是意见领袖挖掘。个体影响力的研究可以从不同的角度进行,例如网络拓扑、用户共享的信息[24]以及用户行为的影响[25]。接下来,我们回顾一下该领域的一些研究,然后进行比较。
$ùLPúHN[26]结合了几种中心性计算方法(Degree Centrality[27]、特征向量中心性[28]、Closeness Centrality[29]),提出了一种新的方法,称为词法排序中心性(LSC)。该方法的排序机制与词法排序类似。相比于单一的中心性度量,LSC能够更加快速、准确地区分节点的传播能力,识别出传播能力最强的节点。
G孙等人。 [30]提出了多子网组合的复杂模型。该模型从情绪或评论等多个角度从原始社交网络中提取子网络,通过多子网合成可以更准确地检测意见领袖。
L Jain 等人。 [31]提出了一种改进的算法,用于检测社区或社交网络中的本地或全球意见领袖。文章使用改进的鲁汶方法识别社交网络中的社区结构,然后应用Firefly算法识别意见领袖和全球意见领袖。与Betweenness Centrality [32]、Degree Centrality和PR(PageRank)算法等传统算法相比,该算法取得了更好的准确率、精确率、召回率和F1分数结果。
F·里克尔梅等人。 [33]提出了一种基于参数化影响力传播的中心性度量,用于检测社交网络中有影响力的用户,称为通用影响力传播等级(GISR)。 GISR 是一种广义且可参数化的中心性度量,基于两个著名的影响力传播模型:IC 和 LT 模型。该措施允许调整初始邻居激活的深度水平、概率和方向性,以研究这些参数如何影响参与者的中心性。实验验证了邻域深度水平的重要性,并揭示了其他连通性方面也与中心性问题相关。
U·伊什法克等人。 [34]提出了一种评估节点重要性的新方法,称为HCURank(Hybrid Centrality Users Rank),该方法基于现有的中心性度量,并使用熵权技术为每个标准分配客观权重。 TOPSIS方法对网络中节点的重要性进行排序。该研究使用四个现实世界的社交网络评估了所提出模型的有效性。结果表明,与单一中心性准则相比,该模型在对网络节点的重要性进行排序方面具有优越性和有效性。
佩里卡尼等人。 [35]提出了一个名为 SAIRUS 的新系统,用于自动识别社交网络上的高风险用户。该系统通过结合三个角度来解决社交网络中的节点分类任务:用户生成文本内容的语义、用户关系网络和空间用户邻近度。与现有方法不同,SAIRUS 学习三个独立的模型,每个模型都利用每种数据类型的特征,然后使用堆栈泛化方法来学习模型以合并它们的贡献。对两个真实世界 Twitter 数据集的变体进行的广泛实验评估表明,基于单一或组合视角,所提出的方法相对于 15 个竞争对手的优越性。当专门关注边缘用户时,SAIRUS 对可能受到噪声数据影响的现实世界社交网络的适用性也很明显。
大多数关于个人影响力的研究都集中在最有影响力的用户,例如意见领袖。文献表明,研究人员从三个角度研究这个主题:网络拓扑[26][30][31][33][34][35]、用户交互[30][31][33][34][35] (例如内容共享和转发)和用户属性[30][33][35](例如兴趣和情感)。在网络拓扑分析中,中心性分析是一种有效的方法。通过考虑用户交互和属性,研究人员可以更准确地识别社交网络中一组有影响力的用户。然而,根据网络结构筛选用户的影响力是一个不错的选择。近年来,人们越来越关注个人影响力的研究。当有影响力的用户被识别出来后,公司或政府可以利用这个群体快速向大多数用户传播信息[36]。文献比较如表IV所示。
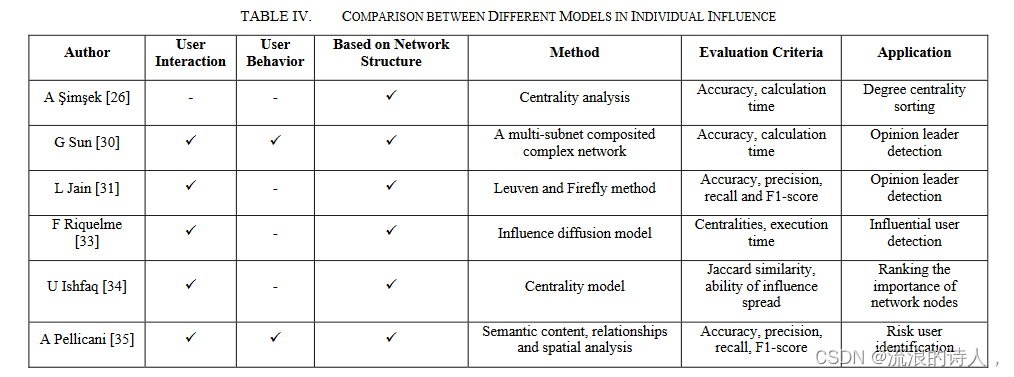
表四。不同模型个体影响力的比较
IV. COMMUNITY MINING
作为一种社会影响力的现象,具有共同价值观的人形成社区。社区结构在社交网络中很常见。整个网络可以根据用户行为、属性等因素划分为不同的社区[37]。这些社区内的节点之间的联系相对密集,而社区外的节点之间的联系则稀疏。检测现实世界社交网络中的社区可以帮助我们更好地理解社会结构。基于社区的影响力研究有多种应用,例如各种产品的病毒式营销和有针对性的推荐系统。社交网络中社区的有效划分是社区影响力扩散的一个关键研究问题。我们在下面介绍其中的一些。
J J Whang 等人。 [38]提出了一种重叠社区检测方法,称为NISE(Neighborhood-Inflated Seed Expansion)。该算法分为四个阶段:过滤、播种、扩展和传播。该算法首先对重叠图区域进行过滤,在过滤后的图中找到双连通核心图中的种子,并利用PageRank聚类将种子扩展为种子簇。然后将社区扩展到过滤阶段删除的区域。该算法可以有效地检测重叠社区并处理大规模数据集。
I Koc [39] 使用 Coot Bird 元启发式优化器来检测社区。文章还比较了六种元启发式方法,并提出了一种 CommunityID 方法来加速 Modularity 计算。因此,Coot Bird 和 CommunityID 的结合可以在更短的时间内检测社区。
X李等人。 [40]提出了一种基于网络拓扑和用户行为的社会影响力的社区检测算法SICD(基于社会影响力的社区检测)。该算法应用于基于事件的社交网络,利用权重函数将两种类型的社交影响力结合起来,以实现统一的社交影响力。然后使用k-means算法进行社区检测。该算法考虑了网络拓扑和用户行为,以更好地衡量用户关系。它还证明了其在真实数据集上的有效性。
Y王等人。 [41]使用邻近群体形成博弈模型来检测社交网络中的社区。该方法构建概率生成模型来重建给定图的拓扑,保留顶点对之间的一阶和二阶邻近性。然后,利用博弈论描述社区结构的演化。最后,利用社区交互概率矩阵来检测社区。
H 法尼等人。 [42]提出了一种多模态特征学习方法,结合内容和网络结构分析,从时间演化的角度识别用户社区。该算法的主要策略是线性插值,例如基于用户时间内容相似性的神经嵌入和社交链接中的时间内容嵌入。这种方法比单独的社交链接和内容分析可以实现更准确的社区识别。
上述文献表明,有效的社区发现是研究影响力扩散的第一步。早期的研究主要集中在网络拓扑[38],但仅考虑节点之间的连接并不能准确反映真实的社区,并且可能会受到用户属性或内容的干扰。因此,最近的研究考虑了这些因素以提高准确性[40][42]。社区检测是一个NP难题,一些研究人员选择了非传统方法来解决它。例如,I Koc [40] 使用元启发式进行社区检测,而 H Fani [42] 采用多模态嵌入,创新性地考虑了时间维度。随着考虑因素数量的增加,计算复杂度也随之增加;这些研究还提出了降低时间复杂度的方法。上述文献的比较如表 V 所示。

表 V. 社区检测方法的比较
V. INFLUENCE MAXIMIZATION RESEARCH
影响力最大化是社交网络分析研究的热点话题,引起了学术界和企业界的关注。对于企业来说,社交网络不仅仅是传播信息的工具,更是一个营销平台[43],[44]。一些研究表明,朋友推荐受到更多关注[45]。在预算有限的情况下,企业希望在社交平台上选择尽可能少的人作为种子节点[46],这样他们的产品就能得到更多的关注和推广,从而鼓励购买。因此,影响力最大化的关键问题是确定最合适的节点以最大化其他节点对社交网络的影响力[47]。下面讨论了有关该主题的一些最新文献。
W李等人。 [48]研究了群体情绪对信息传递的影响,并提出了相应的影响最大化算法。基于情感力量和群体可信度的定义,提出了两种算法:基于情感聚合的PUEA(Potential User Discovery based on Emotion Aggregation)和TFIP(双因素信息传播模型)。 PUEA算法用于识别有影响力的用户,而TFIP算法则根据情感和结构特征来识别有影响力的用户。该算法的时间性能优于贪心算法,性能优于PageRank等启发式算法。
J 丁等人。 [49]基于RIC(Realistic Independent Cascade)模型并考虑节点接收概率,提出了一种新的种子选择策略Rgreedy。他们还提出了M-贪婪算法来降低R-贪婪的时间复杂度。最后,结合两种算法的优点,提出了D-贪心算法。这些算法在不同数据集上与 CELF-Greedy、Static Greedy 和 BKRIS 算法进行了比较。实验结果表明,所提出的算法(Rgreedy、M-greedy、D-greedy)优于这些最先进的算法。
S库马尔等人。 [50]提出了基于图嵌入和图神经网络的SGNN(Struc2vec图神经网络)来识别复杂网络中有影响力的用户。本研究将影响力最大化问题转化为回归问题。首先,使用 struc2vec 节点嵌入为网络中的每个节点生成特征向量,然后将这些特征向量输入到基于图神经网络 (GNN) 的回归器中进行处理。根据预测影响力对种子节点进行排序,选取排名靠前的 K 个节点作为最终的种子节点。此外,该方法可以捕获节点的结构身份和网络的拓扑特征。
Z梁等人。 [51]在贪婪算法的基础上提出了RRT(Reachable set-based Greedy)算法。算法在构建模型时将目标节点和竞争关系纳入独立级联模型。它使用贪心算法选择尽可能多的节点来覆盖反向可达集。并且还设计了剪枝策略来提高算法的性能.
AK 辛格等人。 [52]提出了一种新的基于链接预测的影响节点跟踪框架(LPINT),该框架考虑了社交网络随时间演变的因素。使用贪婪算法,该算法首先识别快照中的种子集,然后使用链接预测来预测接下来的图快照。接下来,使用启发式算法在预测快照中查找种子集,最后使用预测结果来评估影响力传播。与其他算法(例如 PageRank 和 DegreeDiscount)相比,LPINT 在网络影响覆盖范围和影响传播时间方面取得了更好的性能。
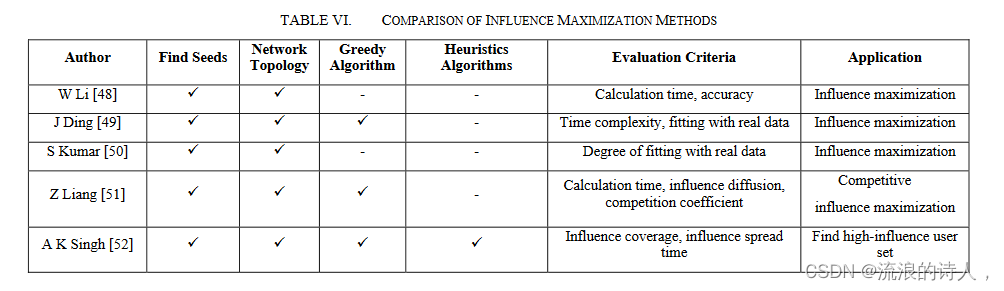
上述研究表明,影响力最大化的研究主要基于网络拓扑、贪婪算法[49][51]和启发式算法[52]。
 表六。影响力最大化方法的比较
表六。影响力最大化方法的比较
表六列出了上述文献的比较。早期的研究主要集中在网络拓扑上,根据节点中心性等指标识别高影响力节点。然而,仅根据节点拓扑选择种子节点可能会导致节点影响范围出现较大重叠。由于基于拓扑的研究的局限性,研究人员使用贪心算法来获得比基于拓扑的算法更好的解集。然而,贪心算法的时间复杂度很高,限制了其可扩展性。随后,研究人员提出了一系列启发式算法,例如PageRank和LeaderRank,来解决时间复杂度问题。同时,研究人员还考虑了影响沟通的其他因素,例如用户情绪[48]、网络的动态变化[52]以及其他特征。包含这些因素可以提高传播模型的准确性。
VI. CONCLUSIONS
本文阐述了影响社交网络传播的常用基本方法。然后,我们介绍了社交网络中关于个人影响力、社区挖掘和影响力最大化的影响力研究的最新状态。我们比较所提出的方法。同时,一些方向的影响力传播研究还需要进一步加强。
在个体影响力方面,现阶段的研究始终集中在寻找最具影响力的节点,这些节点主动影响邻近节点。然而,我们忽略了容易受影响的节点。我们可以评估哪些节点容易受到网络拓扑、用户特征等的影响。如果我们对这些节点有足够的了解,我们相信这将有助于改进推荐系统、广告和营销
在社区挖掘中,当前的研究主要集中在准确寻找潜在社区或识别重叠社区以使检测更加准确。然而,社区结构是否随着网络拓扑的变化以及社区间竞争的演变而变化,还有待深入研究。也就是说,现阶段的大部分研究都是基于静态网络的。因此,群落的动态演化是未来研究的重点。
在影响力最大化问题中,当前的研究假设网络中只有一个群体具有影响力。然而,现实生活中可能存在多个群体之间的竞争,不同的利益相关者都希望最大化自己的影响力。所以目前阶段的大部分研究并不适用于真实的社交网络。因此,需要深入研究如何最大化多个竞争方的影响力。
大规模计算。迭代模拟计算不能满足真实社交网络的需求。基于贪心算法的研究无法避免时间复杂度。基于启发式算法的研究并不能保证算法的准确性和稳定性。现阶段的研究总是决定网络规模和节点数量,与实际的大规模动态网络相差甚远。因此,对真实动态社交网络的研究是未来的一个重要方向。
目前的研究重点是离线静态计算。如何将模型和算法放入实时变化的社交网络中,以及这些模型和算法如何适应动态变化的网络。研究这些问题可以使传播模型更加实用。因此,动态在线计算是未来研究的一个重要方向。















 3411
3411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









