







 Abstract
Abstract
错误信息和谣言可以通过在线社交网络迅速广泛传播,严重危害社会稳定。因此,社交网络上的谣言拦截已成为研究热点。在现有的研究中,当用户收到两种相反的意见时,他们倾向于相信第一个出现。在本文中,我们认为用户会辩证地相信基于自己观点的信息,而不是先到先听的规则。我们提出了一种基于置信度的意见采纳(CBOA)模型,该模型根据传统的线性阈值(LT)模型考虑意见和置信度。基于该模型,我们提出有向图卷积网络(DGCN)方法来选择k个最有影响力的正级联节点来抑制谣言的传播。最后,我们在四个真实网络数据集上验证了我们的方法。实验结果表明,我们的方法能够充分抑制谣言的传播,并且比基线算法获得更少数量的谣言节点。
索引术语——基于置信度的意见采纳(CBOA)、有向图卷积网络(DGCN)、谣言拦截、社交网络。
I. INTRODUCTION
随着社交网络的快速发展,Facebook、Twitter、微信、新浪微博等社交媒体近年来蓬勃发展,极大地改变了人们的生活方式[1],[2]。人们可以在社交网络上表达自己的观点、记录自己的生活、获取信息[3]、[4]。同时,一些社交媒体在传播过程中未能验证信息的真实性,尤其是谣言的传播,会对社会稳定造成严重破坏[5]、[6]。例如,在冠状病毒大流行初期,一些人认为Covid-19可以通过互联网传播。因此,一些信号塔被猛烈摧毁[7],[8]。综上所述,研究如何控制社交网络谣言的传播是至关重要的。
到目前为止,当前谣言拦截的研究工作大致可分为三类。
1)删除关键节点:根据既定规则,首先选择最有影响力的节点,然后从社交网络中删除关键节点。最终实现谣言拦截[9]-[11]。
2)删除关键边:根据特定规则,通常会删除一组在信息传播过程中起关键作用的边集[12]-[14]。
3)传播真实信息对抗谣言传播:选择网络中最具影响力的正级联种子集来传播真实信息对抗谣言传播[15]-[17]。
可见,阻塞节点或删除边是基于网络结构的变化来实现谣言阻塞的。目前的研究主要采用第三类方法来实现社交网络上的谣言拦截。也就是说,我们选择网络中最有影响力的k个正级联节点来抑制谣言的传播。目前,已经进行了一些研究。例如,童等人。 [16]通过基于社交网络上的反向元组的随机算法选择了k个最有影响力的正向种子节点。然而,作者认为,当收到两种相反的意见时,他们倾向于相信第一个出现的意见,这并不能很好地反映现实生活中的情况。然后,我们通过一个例子来展示谣言拦截的应用。例如,当我们想要阻止谣言的传播(例如,Covid-19可以通过互联网传播)时,我们通常会选择一些具有社会影响力的人(例如名人)来传播所需的观点(即真相)抵制谣言的传播,让更多的人相信、追随真相。
此外,一些传播模型[15]、[16]、[18]-[22]被设计来反映网络节点的激活或意见变化过程。尽管相关研究[23]也基于独立级联(IC)模型和线性阈值(LT)模型考虑了用户意见。然而,它只是简单地汇总了邻居节点对信息的意见,并没有充分考虑用户对信息来源的信任度。在这种情况下,我们提出了基于置信度的意见采纳(CBOA)模型。该模型在LT模型的基础上将意见与置信度相结合,在激活过程中采用选择性权重的方法采纳邻居节点的意见。因此,我们的模型考虑了用户对信息来源的信心,可以更真实地反映现实中的人类行为,使传播过程更具解释性。
我们用一个简单的例子来描述一下喝高支白葡萄酒能否抵抗新型冠状病毒的新闻传播过程。
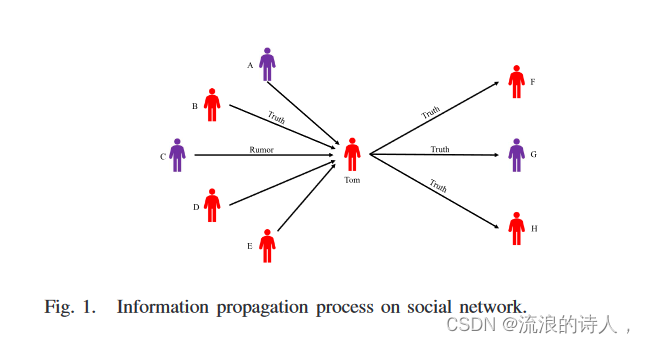
图1显示了Tom在意见传播过程中接收邻居的信息。这里,Tom 的入度邻居包括节点 A、节点 B、节点 C、节点 D 和节点 E。Tom 的出度邻居包括节点 F、节点 G 和节点 H。有些人认为喝高热量白酒不能对抗新型冠状病毒(可靠消息),而另一些人则不同意这种观点(谣言)。我们假设汤姆认为喝高热量的白葡萄酒不能对抗新型冠状病毒(即汤姆相信真理)。为了选择正级联种子节点并阻止谣言的传播,我们提出了有向图卷积网络(DGCN),它具有强大的特征聚合能力。通过DGCN算法,节点在训练过程中可以自动聚合自身及其邻居的特征,可以合理地模拟网络中特征的更新。在这里,我们假设正级联种子节点(Tom)是由我们提出的 DGCN 算法选择的。然后,Tom 将通过我们提出的 CBOA 模型将真相传播给他的所有出度邻居(即节点 F、节点 G 和节点 H),使更多用户相信真相并进一步阻止谣言的传播。此外,我们还介绍了信息传播中网络节点的观点动态。例如,当节点F收到消息时,它会考虑其所有入度邻居对该主题的看法。然后,节点 F 通过使用 CBOA 模型与其所有入度邻居进行通信来形成自己的意见。
我们提出的 DGCN 具有以下优点。
1)DGCN可以对图结构进行卷积运算。卷积网络结构由谱图卷积的局部一阶近似确定,可以有效降低计算复杂度。
2)DGCN的模型规模与图中的边数呈线性正相关,并且DGCN可以用于局部图结构。
3)DGCN的训练输入采用邻接矩阵(即入度邻接矩阵和出度邻接矩阵)。同时,使用邻接矩阵作为输入可以显着改进特征聚合的过程。
在本文中,我们提出了一种有效的 DGCN 方法,用于根据用户的意见和信心来解决谣言阻止问题。首先,我们引入用户对信息传播的意见值和信心,并设计CBOA模型。该模型采用LT模型来激活网络用户,模拟谣言的传播过程,并在激活过程中选择性地对邻居节点的意见进行加权。然后,通过DGCN算法找到社交网络中k个最有影响力的正级联节点。最后,在四个真实数据集上的实验证明了我们提出的方法的有效性。综上所述,本文的贡献如下。
1)我们提出了一种将意见和置信度与LT模型相结合的CBOA模型,以在激活过程中选择性地权衡邻居节点的意见。该模型在信息传播时考虑了用户因素。而且,更加真实地还原了现实世界中人类的行为。
2)我们提出了DGCN算法,通过在图上定义傅立叶变换、利用谱图理论并提取网络拓扑中的空间特征来确定正级联节点。据我们所知,这是第一个使用 DGCN 算法解决谣言阻止问题的工作。
3)在四个真实数据集上进行实验。结果验证了我们的方法在减少谣言节点数量方面可以显着优于基线算法。
本文的其余部分组织如下。第二节介绍相关工作。我们在第三节中正式定义了谣言阻止问题和 CBOA 模型。我们在第四节中介绍了 DGCN 的框架。第五节显示了实验结果。最后,第六节总结了我们的研究。
II. RELATED WORK
A. Propagation Models
Domingo 和 Richardson [18] 首先研究了用户之间对社交网络的影响。在[19]中,Kemp 等人。对影响传播过程进行建模,提出了社交网络上的两种经典级联模型(即 IC 模型和 LT 模型)。基于 IC 和 LT 模型,已经开发了一些变体。在此背景下,错误信息遏制(MC)问题得到了深入研究。例如,布达克等人。 [15]研究了多样本IC模型下的MC问题,并证明该问题是NP-hard问题。他等人。 [20]证明了竞争LT模型下MC问题的子模性。
此外,Parimi和Rout[24]提出了一种基于优先级的竞争级联(PCC)模型,该模型首先计算基于信念的优先级值。在该模型下,作者设计了基于分解的多目标遗传(DMOG)算法来挑选出针对谣言的最小用户种子集。 Tripathi和Rao[25]使用点对点IC(PIC)模型和点对点LT(PLT)模型来实现社交网络上的信息传播。这两种模型都规定用户只能发送一条消息Li等人[23]提出了一种动态竞争扩散模型。选择一些可量化的参数(个人观点、用户的知识等)来显示个体的异质性。此外,该模型还考虑了用户对错误信息的吸引力。
B. Rumor Blocking Algorithms
谣言拦截的研究大致可分为三类:删除关键节点、删除关键边、传播真相对抗谣言传播。
首先,一些研究通过封锁关键节点来抑制谣言的传播。例如,吴等人。 [22]提出了一种基于社区检测的算法来最小化动态谣言的影响。该算法首先将网络节点划分为不同的社区。然后,结合每个社区中每个节点的影响力和谣言的概率影响力来评估每个节点的影响力。最后,通过动态屏蔽各个社区的关键节点和桥梁节点,实现了谣言的屏蔽。 Cheng和Pan[21]基于基于社区的结构考虑了最小成本谣言社区阻塞优化(LCRCBO)问题,使用给定的影响力扩散模型作为谣言扩散模型。该问题的目标是选择网络的最小子集,并通过阻止子集中的节点来阻止谣言的传播。他们提出了一种基于最小顶点覆盖的贪心算法来解决LCRCBO问题。然而,上述研究[21]、[22]都面临着平衡谣言拦截的性能和预算的困难。丁等人。 [26]提出了动态谣言传播模型。然后,基于该模型,作者提出了一跳和两跳算法来选择网络中的关键节点集,并删除所有节点以及连接到节点的边以用于谣言目的。此外,他们提出了一种新颖的评估指标(即爆发阈值)。
第二类研究是通过切断关键边缘来阻止谣言的传播。例如,哈利勒等人。 [13]将谣言阻止问题表述为边删除问题。作者表明该问题在 LT 模型下是超模块化的,并设计了一种可扩展的算法来解决该问题。严等人。 [27]通过特定规则过滤和删除网络中的关键边缘集,研究了谣言传播的最小化。作者证明了谣言传播最小化问题的目标函数不是子模块。然后,作者提出了目标函数的子模上限和下界,并进一步开发了一种启发式算法来解决谣言传播最小化问题。江等人。 [28]定义了通用目标信息传播模型,并引入随机游走算法来对接收者的谣言传播路径进行采样。作者提出了一种基于启发式策略的谣言影响衰减机制,以快速有效地找到最佳保护者。 Tong和Du[29]提出了一种采用混合采样过程的采样算法,该算法可以为容易受到错误信息影响的用户分配高权重。 Zareie 和 Sakellariou [30]提出了一种被动边缘阻塞方法来抑制谣言传播。在该方法中,作者利用熵来权衡两种不同的边缘阻塞效率和扩散能力特征,然后在迭代过程中使用贪心算法确定最关键的边缘集。
此外,一些研究还探索了第三种谣言抑制方法(即通过传播真相来抑制谣言)。例如,Lin等人[31]提出了一种称为众包的谣言拦截框架,其中用户可以自主选择控制权Tong等人[32]提出了一种私人社交传播的PIC模型,分析了谣言主体非合作产生正向级联时的谣言阻止效果。纳什均衡的谣言阻止效果对于正级联非合作生成没有任意恶化Yan等人[33]基于IC模型证明了目标函数是单调递减和非子模的,从而有效地解决了谣言影响最小化问题。作者提出了一种两阶段候选集生成和分块选择方法 Manouchehri 等人 [4] 研究了影响分块最大化(IBM)问题。作者提出了时态 IBM 问题,并考虑了截止日期和延迟的影响。作者针对这个问题提出了一种理论上有保证且高效的抽样方法。 Srinivasan 和 LD [34] 提出了竞争级联模型,并考虑了用户的意见动态和谣言的严重性。他们的方法是通过识别网络中有影响力的积极级联种子集来抑制谣言的传播。
然而,上述研究很难实现谣言节点数量减少与算法效率之间的权衡。基于第一节中提到的 DGCN 的线性特征和高特征聚合,在本文中,我们提出了一种 DGCN 方法来有效地选择正级联种子集来抑制谣言的传播。
III. PROBLEM FORMATION
A. Preliminary Knowledge
社交网络表示为有向图 G = (V , E)。这里,V ={v1,v2,...,vn} 是节点集,E ={(vi ,vj ) : vi ,vj ∈ V }⊆V × V 是边集,表示节点之间的关系,其中(vi ,vj ) 表示从 vi 到 v j 的边。另外,邻接矩阵
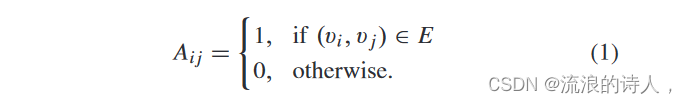
对于无向图,矩阵 A 是对称的,度矩阵 D 是对角矩阵,元素为 D[i, i ]= Σ i A[i ]=d(vi )。组合拉普拉斯矩阵 L 组合了度数和邻接矩阵:L = D − A。对称归一化拉普拉斯矩阵为 L = D−1/2 LD−1/2。对于有向图,A 通常是不对称的。我们构造二阶矩阵 Din 和 Dout,其中 Din[i, i ]=Σ j A[ j, i]Dout[i, i ]=Σ j A[i, j ] 分别计算图中每个顶点的入度和出度。
B. Propagation Model
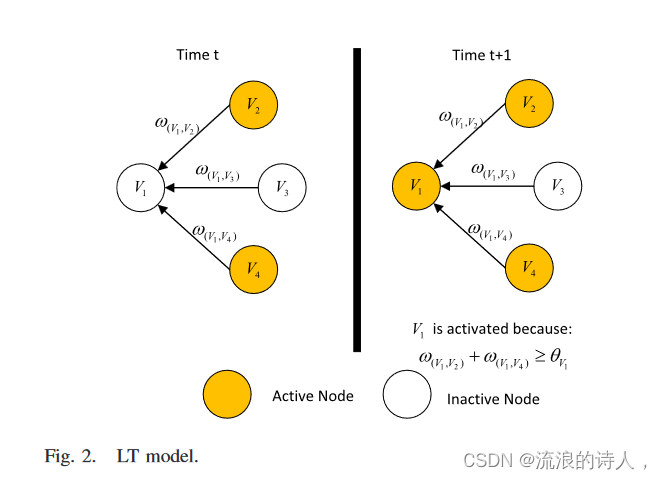
社交网络由有向图 G = (V, E) 表示,其中 V 表示用户集合,E 表示用户之间的关系集合,用户 v 是 u 的邻居,(u,v) ∈ E。让n和m分别是节点和边的数量。我们用 v 中的 N 来表示 v 的一组内邻居。ForanetworkG,令 V (G) 和 E(G) 分别为 G 的节点集和边集。为了在社交网络中传播新闻或推广产品,通常会选择一些种子节点来激活整个网络,从而触发新闻或产品的传播。本文采用典型的LT模型。在LT模型中,每条有向边(u,v) ε E都有一个权重ω(u,v) ε[0, 1],其中ω(u,v)反映了节点u对其所有邻居v的权重,并且每个节点 v 也有一个受影响的阈值 θv ∈[0, 1],其范围在 0 到 1 之间。在每次 t ≥ 1 时,每个不活动节点 v ∈ V \S(t−1) 利用其激活传入的邻居以确定激活状态。如果非活动节点被激活,则节点 v 在时间 t (v ∈ St ) 处被激活。否则,节点 v 保持不活动状态。当某个时刻没有新节点被激活时,我们将停止传播过程。如图2所示,在时间t,v2和v4被激活,而v1和v3未被激活。在时间 t + 1 时,由于 w(v1,v2) + w(v1,v4)>= θv1 ,因此 t+1 时刻的 v1 被 v2 和 v4 激活。
C. Confidence-Based Opinion Adoption Model
基于LT模型,社交网络表示为有向图G=(V,E,ω,θ,O),其中V表示用户节点集,E表示用于描述每对之间的社交联系的边集用户数。每个节点有两个参数:激活阈值θv ∈[0, 1],表示LT模型激活过程中节点的激活阈值和节点意见Ov。每个节点的初始意见值为 Ov ∈[−1, 1],Ov 表示用户 v 对每条信息都有自己的看法,Ov ≥ 0 表示用户 v 对该信息有积极的看法,记为 O+ v , Ov < 0 表示用户 v 有负数信息意见,表示为 O− v 。此外,Nin v和N out v表示用户v的内邻居和外邻居的集合。
CBOA模型的动态描述如下:当用户v被周围邻居激活时,用户v对信息的看法会受到周围邻居的影响,即更新自己对信息的看法。更新规则如下:
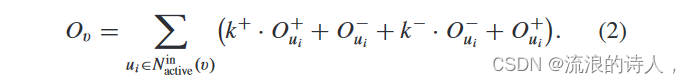
我们假设所有用户的邻居最初同时存在,节点v按照先来先听的规则逐一采用邻居。具体来说,我们的排序标准是基于权重的。如图3所示,
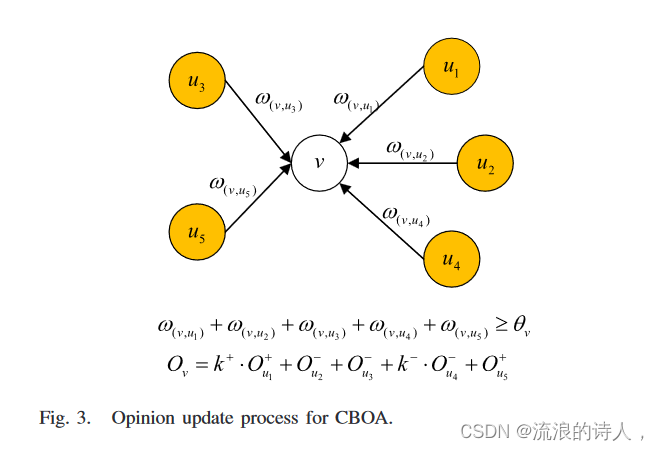
我们假设用户v的初始意见是积极的,v的入度邻居分别为u1、u2、u3、u4和u5。此外,我们假设 u1、u2、u3、u4 和 u5 的权重下降(即 ω(u1,v) > ω(u2,v) > ω(u3,v) > ω(u4,v) > ω(u5,v) 对应信息的意见为 O+ u1, O− u2 , O− u3, O− u4 ,O+ u5 。当 v 采用邻居 u1 的意见且 u1 持肯定意见时,Ov = O+ v + k+ · O+ u1 其中 v 采用 u1 的意见 O+ u1,权重为 k+(k+ ≥ 1)。当 v 采用邻居 u2 的意见,而 u2 持有否定意见(v 和 u2 的意见不一致)时,Ov = O+ v + O− u2 . 假设采用u2的意见后Ov仍然大于0,与u2的过程相同,即Ov = O+ v + O− u3 。在采纳 u3 的意见后,v 持有否定意见 O− v。当采纳邻居 u4 的意见(其中 u4 也持有否定意见)时,Ov = O− v + k− · O− u4,其中 v 采纳类似地,当采用邻居 u5 的意见(其中 u5 持有肯定意见)时,Ov = O− v + O+ u5 。
D. Problem Formation
意见更新后,每个节点最终都会获得自己的意见值。我们定义
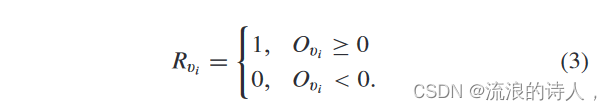
这里,Rvi=1表示节点vi最终为正,Rvi=0表示vi最终为谣言节点。然后,我们将谣言节点数量最小化的问题定义如下:给定一个有向图 G = (V, E, ω, θ, O) 和一个正整数 k,每个节点都与一个观点相关联,可以表示为积极或消极。因此,我们将f(S)定义为特定时间后谣言节点的数量。
给定有限的预算 k (1 ≤ i ≤ k),最小化谣言节点数量的问题是选择正级联节点集 S = OPTk (S ⊆ V ),传播针对谣言的正面意见,最终最小化谣言节点数量谣言节点。因此,问题定义为
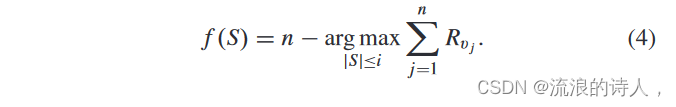
IV. PROPOSED DGCN
在本节中,我们介绍DGCN算法,其主要目的是有效地找到网络中k个最有影响力的正级联种子节点。我们利用这些种子节点来传播针对谣言信息的正面信息,以最大程度地减少受谣言影响的用户数量。

A. Framework of Graph Convolutional Networks
1)Embedding Layer:Embedding层的伪代码总结如算法1,主要包括以下三个部分。
1)通过社交网络数据集自动建模和构建节点集和边集。通过构建社交图来完成节点特征的提取和边缘特征的提取。其中,节点的特征包括用户的意见值 Ov 和用户的激活阈值 θv ,边的特征包括有向边的权重 ω(u,v)(Ov ,θv ,ω(u,v )在第 III 节中描述)。
1)通过社交网络数据集自动建模和构建节点集和边集。通过构建社交图来完成节点特征的提取和边缘特征的提取。其中,节点的特征包括用户的意见值 Ov 和用户的激活阈值 θv ,边的特征包括有向边的权重 ω(u,v)(Ov ,θv ,ω(u,v )在第 III 节中描述)。
2)得到每个节点的意见特征后,如果Ov≥0,则该节点为正级联节点;如果 Ov < 0,则该节点是谣言节点。然后根据上述规则得到初始的正级联节点集和谣言节点集。
3)我们从初始谣言节点集中随机选择r个谣言节点作为谣言种子集。

2)归一化:如算法2所示,这一步主要是对上一层输入图的每条边的权重进行归一化。如图 4 所示,对于每个用户 vi ,在从嵌入层检索到她所有的入度邻居后,指向它的所有边的权重都被归一化,由下式给出

2)归一化:如算法2所示,这一步主要是对上一层输入图的每条边的权重进行归一化。
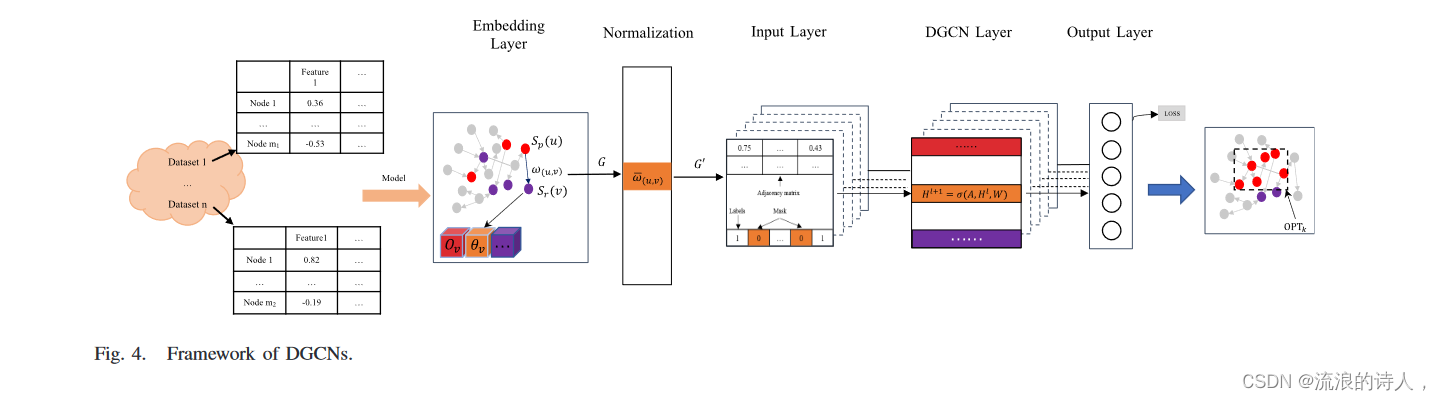 如图 4 所示,对于每个用户 vi ,在从嵌入层检索到她所有的入度邻居后,指向它的所有边的权重都被归一化,由下式给出
如图 4 所示,对于每个用户 vi ,在从嵌入层检索到她所有的入度邻居后,指向它的所有边的权重都被归一化,由下式给出
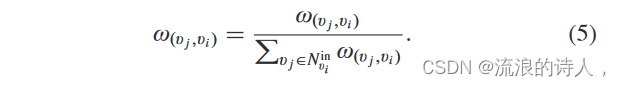
这里,(v j ,vi )表示v j 指向vi 的有向边。 ω(v j ,vi ) 是有向边 (v j ,vi ) 的权重。直观上,每个节点的入度邻居的归一化权重满足LT模型的传播规则。

3)输入层:如算法3所概括,输入层的主要任务是:1)通过嵌入层建模的图结构——节点类型,构造节点的特征向量; 2) 嵌入层将掩码添加到谣言节点集合中。主要作用是使谣言种子节点在训练过程中丢弃,以提高准确率; 3)通过归一化边的权重构造有向图的邻接矩阵A,为GCN层训练做准备。此外,输入层涵盖了所有其他自定义顶点特征,例如结构特征、阈值特征和意见特征。
4)DGCN层:GCN是一种基于深度学习的方法,利用图中的数据矩阵来构造处理后的结构数据。 GCN 被提出作为局部谱滤波器网络的一阶近似、谱网络的局部近似。谱网络使用图傅立叶变换在图的频域中执行图卷积,例如卷积定理。
使用切比雪夫多项式逼近图形的局部谱滤波器网络。然而,传统的GCN算法集中在无向图上[35]。由于我们将真实的社交网络建模为有向图结构,因此我们利用 DGCN 算法来确定正级联种子节点集。 DGCN是针对图结构数据的半监督学习算法,由多个DGCN层堆叠而成。每个DGCN层的输入是一个顶点特征矩阵,H ∈ R(n×F),其中n是顶点数量,F是特征数量。总的来说,DGCN层的本质是非线性变换。对于有向图,层与层之间的传播如下:
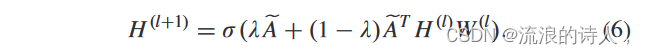
这里,̃ A = A + IN 是具有自环的入度邻接矩阵,̃ AT 是入度邻接矩阵的转置,即出度邻接矩阵。 IN是单位矩阵,这样在进行信息传播时可以保留顶点特征的信息。参数 λ 平衡沿图边向前传递信息和沿图边向后传递信息的重要性。 W (l) 是特定于层的可训练权重矩阵。权重矩阵的维度为 Fi × Fi+1。也就是说,权重矩阵第二维的大小决定了下一层的特征数量。 σ(·)激活函数如Sigmod、Relu等。 H (l) ∈ RN×D 是第一层的激活矩阵,其中H (0) = X 。式(6)实现了空间信息的聚合。第零层的输入是原始特征,以后的每个附加层都会聚合一阶邻居的信息
5)输出层:求解完上述核心公式后,DGCN最终得到的结果是每个节点的特征向量,经过l层特征增强后得到的Z=H(l)。即经过几层DGCN,每个节点的特征从X变为Z N×C ,其中C为分类类别数。这里,DGCN使用softmax函数进行分类,softmax函数如下:
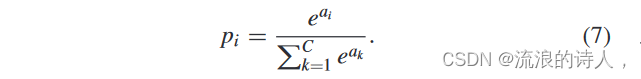
其中,a1,a2,…,aC为Z中某个节点的特征(Z中的行数代表节点的数量,即Z中某行的数据代表该节点对应的特征)到行); pi 是节点属于 i 的类别的概率。上式可以保证ΣC k=1 yi = 1,即节点划分到每个类别的概率之和为1。通过上式,我们可以得到每个标签下节点的概率。我们定义 ˆ A = λ ̃ A + (1 − λ) ̃ AT ,我们的前向计算可以转化为
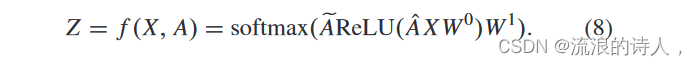
这里,W 0 ∈ RC×H 是输入层到隐藏层的权重矩阵,隐藏层有H个特征。 W 1 ∈ RH×F 是隐藏层到输出层的权重矩阵。 Softmax应用于每一行,对于半监督多类分类,我们评估所有标记标签的交叉熵(交叉熵反映了实际输出与预测输出之间的相似度)

其中 pki 是节点 k 属于类别 i 的概率(真实值),qki 是模型预测节点 k 属于类别 i 的概率(预测值)。

DGCN 的伪代码总结在算法 4 中。这里,OPTk 是 k 个正级联种子节点的集合。算法4的核心组件包括如下。
1)我们首先利用算法1通过数据集上的数据实现图结构,并选择r个节点作为谣言种子节点集。
2)通过算法2对图中所有边的权重进行归一化。
3)我们获得用于训练的有向图结构。然后,我们使用算法3从该图结构形成有向图的邻接矩阵,并构造该图的特征矩阵。
4)我们将初始化的参数、邻接矩阵、特征矩阵和节点标签矩阵输入到DGCN中进行训练。
5)我们获得正级联种子集OPTk
V. E XPERIMENTAL EVALUATIONS
为了评估我们提出的方法的性能,我们选择了四个网络数据集和四个基线算法。所有实验均在配备 Intel(R) Core(TM) i7-7700U CPU 处理器和 16.00G RAM 的计算机上进行。
A. Dataset Description
我们使用信息传播过程中广泛使用的四个真实世界网络数据集,表一总结了它们的基本信息。
1)Facebook [36]:该网络分析社交网络上用户行为和交互的模式和动态。该数据集包括在网络中发送或接收至少一条消息的 1899 个用户。这些用户之间有 20 296 个有向边,并且用户之间传递了 59 835 条消息。
2) OpenFlights (Opsahl) [37]:这一目标网络包含全球机场之间的航班,有向边代表从一个机场到另一个机场的航班。
3)Fb-Pages-Government [38]:该数据集是关于 2017 年 11 月收集的 Facebook 页面。这些数据集表示不同类别的蓝色验证 Facebook 页面的网络,其中节点表示页面,边缘表示节点之间的相互喜欢。
4) FOLDOC [16]:该数据集是 www.foldoc.org 上免费在线计算词典中条目之间的交叉引用。节点代表条目,从术语A到术语B的有向边表示术语B用于定义术语A。网络中存在多条边,代表同一个术语的多种使用。
B. Parameter Settings
对于实验过程,我们使用以下两种方法来生成边权重:1)随机方法,其中每条边的权重在[0, 1]范围内随机生成;2)对于每个节点v,权重为其入度边缘设置为 1/Nin v 。我们通过以下两种方式设置意见采纳的权重值:a)k+=k−=C(C是大于1的常数)和b)由于谣言的置信度会随着时间的推移逐渐降低,k+=1.2, k− =[1.2, 1, −0.01),其中 k− 每轮减少 0.01。

在DGCN训练中,我们通过在Facebook和Fb-pages-government数据集上进行实验来确定λ和迭代次数(Epochs)。如图5(a)和(b)所示,当λ≥0.2时,谣言节点的数量保持相对稳定。在此实验中,λ设置为0.65。此外,根据图5(c)和(d),本实验中参数Epochs设置为1000。
C. Baseline Algorithms
在实验中,我们利用以下四种基线算法。
1)随机:随机选择网络节点作为谣言种子集。为了克服结果的随机性,我们的实验随机选择100个谣言种子集并获得平均结果。 2)CELF[39]:该算法优化了原来的贪心算法,利用了目标函数的子模性,从而显着减少了不必要的计算。
3)ProxMinGreedy[40]:当谣言种子集固定时,选择意见增益最大的k个节点。正级联节点集的选择范围为: SP = arg maxu∈Nout SR | *R(SR, SP ∪{u})|(SP为谣言节点集,SR为正级联节点集)。
4)GCN[41]:我们介绍了GCN算法,该算法主要利用在无向图上。我们分别使用出度邻接矩阵和入度邻接矩阵作为GCN层的输入。为了避免算法训练的随机性,我们在每个数据集上训练 100 次并取平均结果。
5)DGCN:这是本文提出的方法。为了避免算法训练的随机性,我们对每个数据集训练 100 次,取结果的平均值。
此外,我们还介绍了 DGCN 的性能验证过程。我们通过 DGCN 的算法 1 和 4 以及四种比较算法(即 Random、CELF、ProMinGreedy 和 GCN)获得谣言种子集和正级联种子集。需要说明的是,种子节点集包括两部分:谣言节点集和正级联种子节点集。随后,每个算法选择初始正级联种子节点。算法1选择相同的初始谣言种子节点。然后我们利用我们提出的 CBOA 模型来启动意见传播过程。在传播过程之后,我们将网络中的谣言节点的数量作为性能指标来评估我们提出的方法。因此,谣言节点数量越少代表性能越好。
D. Experimental Results
在本节中,我们主要展示不同方法的谣言节点数量和运行时间。

图 6 显示了 Epoch 上的谣言节点数量。这里,每条边的权重是随机生成的,意见的权重设置为k+ = k− = 1.2。结果表明,四种方法的谣言节点数量随着种子节点数量的增加而不断减少。特别是,我们的 DGCN 获得的谣言节点数量比 Random、CELF、ProxMinGreedy 和 GCN 少。例如,在图6(d)中可以看出,当网络中种子节点数量较多时,GCN、CELF和ProxMinGreedy无法有效选择正级联种子节点。然而,我们的 DGCN 可以有效地选择对网络数据集有重大影响的正级联种子节点。
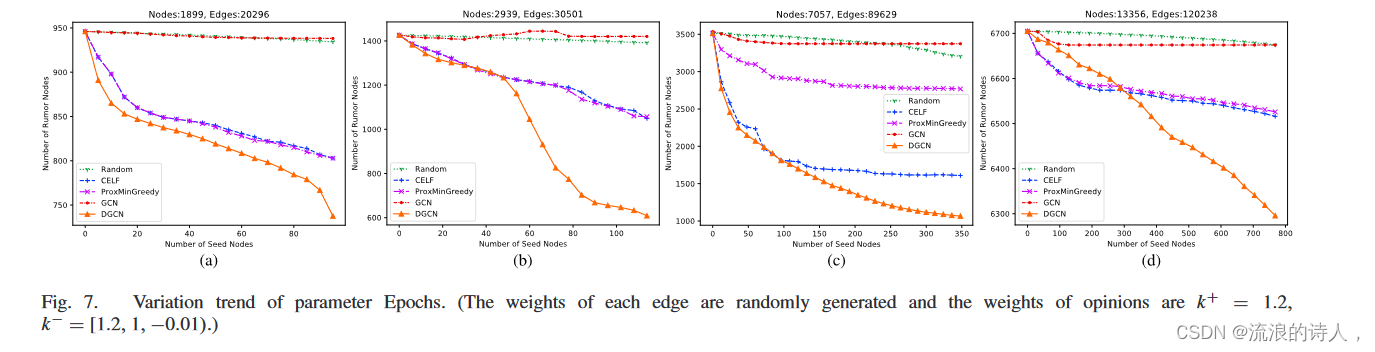 图 7 显示了 Epoch 上的谣言节点数量。这里,每条边的权重是随机生成的,意见的权重为k+ = 1.2, k− =[1.2, 1, -0.01)。我们可以观察到,这五种方法的谣言节点数量比种子节点数量减少。例如,在图7(b)中,当种子节点数量为[0, 50]时,DGCN的性能与CELF和ProxMinGreegy相似。当种子节点数量为[50, 90]时,可以看出DGCN曲线下降速度明显快于其他基线算法。在图7(c)中,在[0, 100]范围内, DGCN 与 CELF 类似,并且比随机、GCN 和 ProxMinGreedy 更好。在[100, 360]范围内,DGCN的性能比CELF算法下降得更明显。在图 7(d) 中,在 [0, 300] 范围内,DGCN 的性能优于 CELF 和 ProxMinGreedy,但大于 Random 和 GCN。在[300, 800]范围内,DGCN 获得的谣言节点数量比其他算法少。
图 7 显示了 Epoch 上的谣言节点数量。这里,每条边的权重是随机生成的,意见的权重为k+ = 1.2, k− =[1.2, 1, -0.01)。我们可以观察到,这五种方法的谣言节点数量比种子节点数量减少。例如,在图7(b)中,当种子节点数量为[0, 50]时,DGCN的性能与CELF和ProxMinGreegy相似。当种子节点数量为[50, 90]时,可以看出DGCN曲线下降速度明显快于其他基线算法。在图7(c)中,在[0, 100]范围内, DGCN 与 CELF 类似,并且比随机、GCN 和 ProxMinGreedy 更好。在[100, 360]范围内,DGCN的性能比CELF算法下降得更明显。在图 7(d) 中,在 [0, 300] 范围内,DGCN 的性能优于 CELF 和 ProxMinGreedy,但大于 Random 和 GCN。在[300, 800]范围内,DGCN 获得的谣言节点数量比其他算法少。

图 8 显示了四种方法在种子节点上的四个数据集上的性能。这里,每一个的权重dge 设置为 v 中的 ω(u,v) = 1/N,意见权重设置为 k+ = 1.2, k− =[1.2, 1, −0.01)。可以看出,谣言节点的数量随着边权重的变化而变化。图8(a)和(b)显示了DGCN算法与三种基线算法相比的优势。图8(c)和(d)表明,当种子节点数量较少时,DGCN和CELF的性能相似甚至略低。当k达到特定值时,DGCN的性能明显高于其他算法。从上面的实验结果我们可以观察到GCN的性能表现并不好。主要原因是传统的GCN是针对无向图设计的,忽略了图中边的方向性。因此,该节点失去了邻居特征聚合的准确性。上述实验如图所示。图 6-8 说明了 DGCN 在不同网络数据集中的有效性。
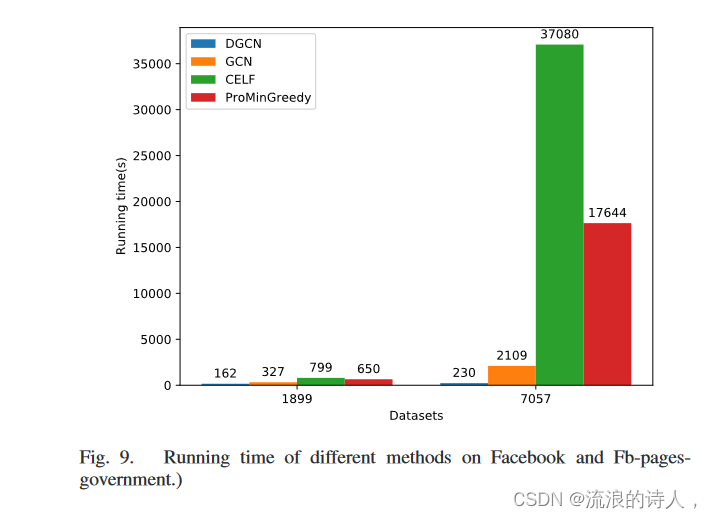
为了进一步证明我们提出的方法的效率,我们在图 9 中提供了四种方法(DGCN、GCN、CELF 和 ProxMinGreegy)在 Facebook 和 Fb-pages-government 数据集上的运行时间。由于随机算法随机选择 k由于存在正级联节点且运行时间比四种方法短,因此我们不考虑图 9 中 Random 的运行时间。这里,我们设置意见权重值 k+ = k− = 1.2。结果表明,与其他三种算法相比,CELF算法在两个数据集上消耗的运行时间最大。此外,结果还表明,DGCN 的运行时间比 GCN、CELF 和 ProxMinGreegy 更短,尤其是在 Fb-pages-government 上。综上所述,实验验证了我们提出的 DGCN 可以快速找到理想的正级联种子集,显示了我们提出的方法的优越性。
VI. CONCLUSION、
在本文中,我们研究社交网络上的谣言拦截问题。我们将用户对消息的意见和信心与 LT 模型结合起来。我们提出了CBOA模型,使得模拟广播过程更加接近现实。基于该模型,提出DGCN算法来选择k个正级联种子集来对抗谣言的传播。最后,在四个真实数据集上进行实验以评估所提出方法的性能。实验结果表明,我们的方法在减少谣言节点数量方面优于其他比较方法(Random、CELF、ProMinGreedy 和 GCN)。此外,我们的方法还获得了比 CELF、ProMinGreedy 和 GCN 更短的运行时间。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









